totaal modsim
1/114
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai | Chat |
|---|
No analytics yet
Send a link to your students to track their progress
115 Terms
Onderscheid een systeem van iets dat geen systeem is en leg het verschil uit.
= een verzameling elementen, onderdelen of componenten die op een samenhangende manier zijn georganiseerd en met elkaar zijn verbonden tot een patroon of structuur die een kenmerkende reeks gedragingen voortbrengt die een ‘functie’ of ‘doel’ wordt genoemd.
Let op de drie aspecten in deze definitie:
• een systeem bestaat uit componenten;
• deze componenten staan op een of andere manier met elkaar in wisselwerking;
• deze wisselwerkingen leiden tot gedrag op systeemniveau.
Voorbeelden van systemen zijn:
• Een zenuwcel bestaat uit veel verschillende soorten moleculen en organellen die op elkaar inwerken, zodat de cel informatie van andere neuronen kan verzamelen, verwerken en doorgeven.
• Een aquatisch ecosysteem bestaat uit verschillende soorten en niet-levende componenten die samenwerken om voedingsstoffen te recyclen en biomassa te produceren.
→ Een systeem is meer dan de som der delen — alleen het systeem als geheel vertoont adaptief, doelgericht, zelfbehoudend en soms evolutionair gedrag.
Niet alles is een systeem; een verzameling niet-op elkaar inwerkende componenten gedraagt zich niet als één geheel. Een hoop zand is bijvoorbeeld geen systeem. Het toevoegen of verwijderen van zand leidt niet tot kwalitatief ander gedrag. Aan de andere kant leidt het verwijderen van spelers uit een team tot het verlies van de werking ervan.
Systemen kunnen natuurlijk, kunstmatig of een combinatie daarvan zijn.
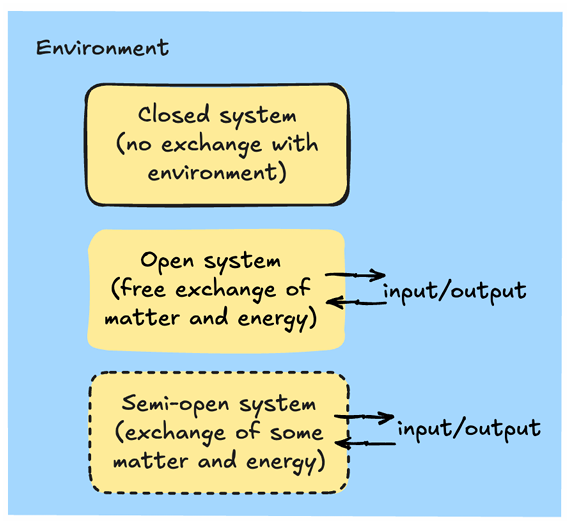
Leg het verschil uit tussen een open, gesloten en half-open systeem. Geef een voorbeeld van elk.
Systemen maken deel uit van hun omgeving. Afhankelijk van het feit of ze materie, energie of informatie met de omgeving kunnen uitwisselen, spreken we van een open, gesloten of semi-open systeem (afb. 1.2). De systeemgrenzen (het celmembraan, de wanden van een reactor, enz.) scheiden het systeem van zijn omgeving. Een systeem kan met de omgeving in wisselwerking staan via inputs (die het systeem binnenkomen) en outputs (die het systeem verlaten). De meeste systemen die we in deze cursus tegenkomen, zijn dynamisch, wat betekent dat de functie, outputs of interne toestanden in de loop van de tijd zullen veranderen.
vb.
gesloten systeem: afgesloten thermofles
open systeem: een plant
semi-open systeem: ?
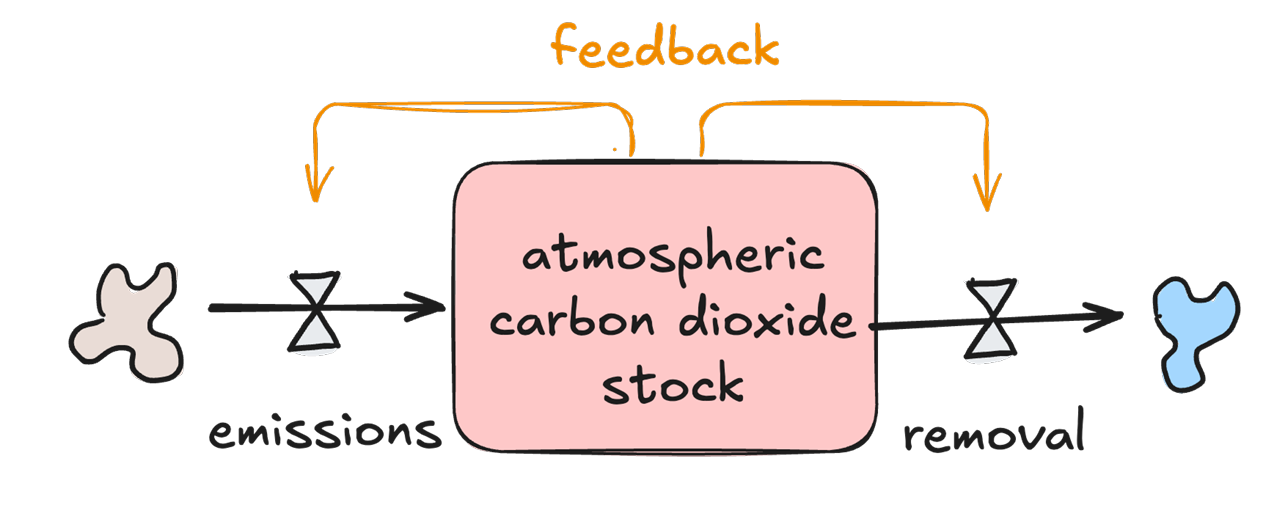
Leg stocks, flows en feedback uit adhv een tekening. Gebruik een voorbeeld.
Stocks of stakes zijn de elementen die op verschillende tijdstippen worden gemeten. In een diagram worden ze weergegeven door vakjes. Stocks worden opgebouwd en fungeren als buffers. Stocks zijn hulpbronnen of materialen die tastbaar (water, stikstof, biomassa, ...) of ontastbaar (geld, informatie, geluk, ...) zijn. Stakes zijn algemener en omvatten zowel fysische variabelen, zoals temperatuur, druk, ....
Flows vertegenwoordigen de momenten waarop hulpbronnen een systeem binnenkomen, verlaten of zich daarbinnen bevinden. Flows, weergegeven als pijlen, kunnen positief of negatief zijn en de voorraad veranderen door deze te vullen, leeg te maken, te laten groeien, te produceren, te laten vergaan, te evalueren, te verliezen, af te scheiden of te transformeren.
Feedback is een gesloten keten van causale verbanden waarbij een verandering in een voorraad een stroom beïnvloedt, die op zijn beurt weer de voorraad beïnvloedt. Het is het mechanisme waarmee een systeem zichzelf kan reguleren, hetzij door verandering te versterken, hetzij door deze te dempen.
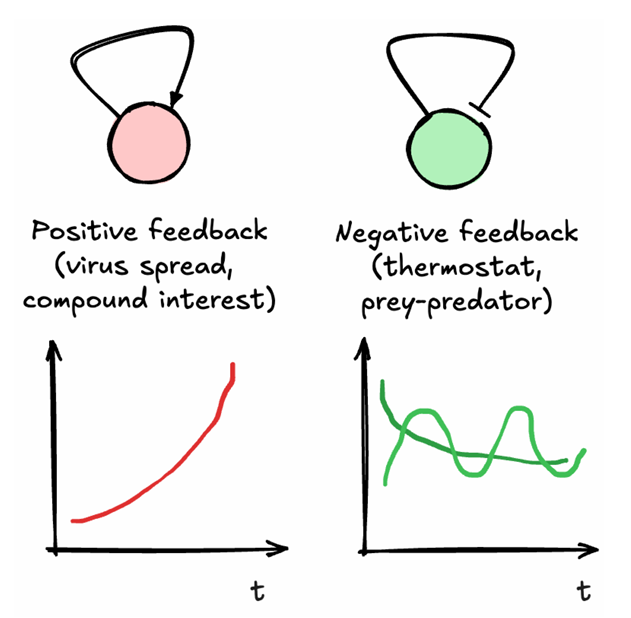
Wat is het verschil tussen positieve en negatieve feedback? Schets een grafiek van hun gedrag.
Positieve terugkoppeling houdt in dat hoe hoger de waarde van de voorraad is, hoe sneller deze stijgt, d.w.z. hoe groter de instroom is. Bevolkingsgroei is een goed voorbeeld van positieve terugkoppeling. Als er meer individuen zijn, kunnen ze meer nakomelingen krijgen, zolang niets hen tegenhoudt. Positieve terugkoppeling werkt vaak destabiliserend.
Negatieve terugkoppeling werkt de oorspronkelijke verandering tegen, d.w.z. ze remt haar eigen activiteit af. Het is meestal een stabiliserende kracht. Veel biologische processen worden gemedieerd door negatieve terugkoppeling; denk bijvoorbeeld aan de verschillende hormonale processen die de fysiologie van een persoon in evenwicht houden. Hoewel negatieve terugkoppeling het systeem vaak stabiliseert, kan het ook leiden tot oscillaties wanneer de terugkoppeling vertraagd is. De klassieke Lotka-Volterra-modellen van prooi en roofdier vertonen bijvoorbeeld oscillerend gedrag omdat de roofdieren hun populatiegrootte beperken via hun prooi.
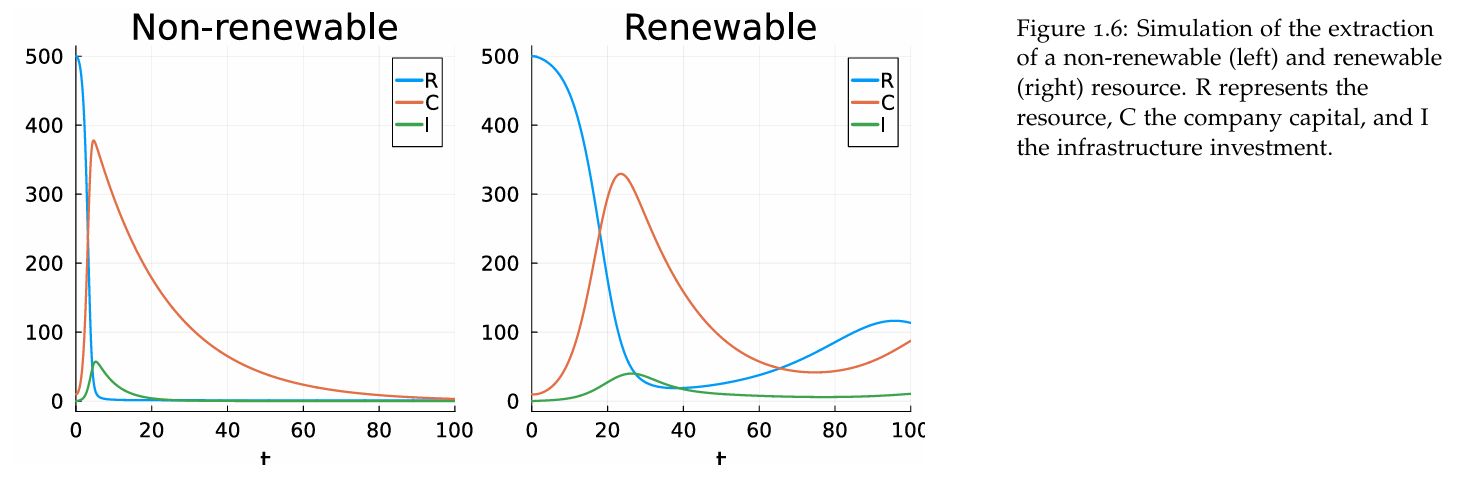
Hernieuwbare grondstoffen zijn flow gelimiteerd, niet-hernieuwbare stockgelimiteerd. Leg uit.
→ Niet-hernieuwbare grondstoffen zijn stock-gelimiteerd omdat de totale hoeveelheid (stock) eindig is. Wat betekent dat? De grondstof zit opgeslagen als een vaste voorraad in de natuur.
Er komt geen of bijna geen nieuwe aanvoer bij op menselijke tijdschalen.
→ Hernieuwbare grondstoffen zijn flow-gelimiteerd omdat ze opnieuw aangroeien. Er bestaat dus:
een stock (bijvoorbeeld een vispopulatie)
maar er is ook een natuurlijke instroom (flow)
De beperking zit niet zozeer in de totale voorraad, maar in hoe snel de resource kan worden aangevuld.
Wat zijn de belangrijkste gelijkenissen en verschillen tussen een wiskundig en een niet-wiskundig model? Geef daarbij een voorbeeld van beiden.
Een wiskundig model is een vereenvoudigde weergave van een systeem of verschijnsel uit de werkelijkheid, waarbij wiskundige vergelijkingen, verbanden en logica worden gebruikt om het gedrag ervan te begrijpen, te voorspellen of te sturen. De belangrijkste punten hierbij zijn:
• een model heeft betrekking op een specifiek systeem (een klein deel van de werkelijkheid);
• het is een vereenvoudiging; de mate van realisme hangt af van de doelstellingen van de modelleerder;
• het moet kwantitatief zijn: de uitkomst moet numeriek zijn in plaats van kwalitatief.
Een wiskundig model stelt iemand dus in staat om kwantitatief over het betreffende systeem te redeneren. Niet alle modellen zijn wiskundige modellen. Sommige zijn fysisch of conceptueel. Biologen werken bijvoorbeeld graag met Arabidopsis thaliana als een veelgebruikt modelsysteem in de plantbiologie. Omdat de plant klein is en een bekend genoom heeft, is het een vereenvoudigd model in vergelijking met landbouwkundig belangrijkere, maar complexere gewassen zoals broccoli of kool. Op dezelfde manier maken architecten maquettes van hun ontwerpen, en onze faculteit beschikt over een windtunnel om bodemerosie te modelleren.
Herken en benoem de variabelen, inputs, parameters en constanten van een model.
Een wiskundig model bestaat doorgaans uit vergelijkingen, computercode en numerieke grootheden die het gedrag bepalen. Deze grootheden kunnen worden onderverdeeld in
1. Toestanden of variabelen: de fundamentele grootheden die het systeem op elk willekeurig moment beschrijven (bijv. de voorraden in het systeem). Dit zijn de zaken die veranderen naarmate het systeem zich ontwikkelt. Voorbeelden van toestanden zijn het waterpeil, de temperatuur van een object, de concentratie van een chemische stof, enz. Bij het modelleren willen we de toestanden bijhouden.
(a) Onafhankelijke variabelen, zoals tijd t of ruimtelijke coördinaten, zijn bekend of worden vastgesteld door de modelleerders (bijvoorbeeld inputs die aan het systeem worden gegeven). Ze veranderen onafhankelijk van andere modelcomponenten, vandaar de naam.
(b) Afhankelijke variabelen veranderen afhankelijk van de andere toestandsvariabelen. We modelleren bijvoorbeeld een concentratie of een druk als een functie van de onafhankelijke variabele tijd.
2. Constanten zijn grootheden in het systeem die bekend zijn en vastliggen. Dit kunnen wiskundige constanten zijn, zoals of e, of fysische constanten, zoals de zwaartekrachtconstante, ...
3. Parameters zijn waarden die van experiment tot experiment kunnen variëren en vaak experimenteel moeten worden bepaald. Groeisnelheden, reactiesnelheden of diffusiecoëfficiënten zijn bijvoorbeeld typische parameters waarmee de bio-ingenieur te maken kan krijgen. Belangrijk is dat, net als bij constanten, parameters binnen een bepaalde run in een model vastliggen. Anders zijn het variabelen!
Leg uit wat de voor- en nadelen zijn van een complex model (tov een eenvoudig model)
pos:
zijn realistischer en leveren specifiekere voorspellingen op
kunnen gedetailleerdere informatie over het systeem weergeven
neg:
vereisen meer gegevens om te kalibreren en te valideren
zijn moeilijker te begrijpen
zijn rekenkundig gezien duurder
Modellen kunnen in complexiteit variëren van zeer eenvoudig (een paar vergelijkingen en variabelen) tot uiterst complex (duizenden vergelijkingen en variabelen). Hoewel complexe modellen een systeem veel gedetailleerder kunnen weergeven, zijn ze ook veel moeilijker te bouwen, te parametriseren en te valideren. Bovendien leidt een grotere complexiteit slechts soms tot een grotere nauwkeurigheid of bruikbaarheid. Een eenvoudiger model dat de essentiële dynamiek van een systeem weergeeft, kan meer inzicht bieden en gemakkelijker te interpreteren zijn dan een zeer gedetailleerd maar ondoorzichtig model. De keuze voor de complexiteit van een model houdt vaak een afweging in tussen nauwkeurigheid, interpreteerbaarheid en rekenkracht. Eenvoudige modellen offeren mogelijk enige nauwkeurigheid op ten gunste van duidelijkheid en gebruiksgemak, terwijl complexe modellen mogelijk uitgebreide gegevens en rekenkracht vereisen om effectief te zijn. Het juiste niveau van complexiteit hangt af van de specifieke doelstellingen van de modellering, de beschikbare gegevens en het gewenste niveau van inzicht in het systeem. In deze cursus richten we ons op kleine modellen die de essentie van een systeem kunnen weergeven, met als hoofddoel het verkrijgen van inzicht.
Geef de vier belangrijke doelen van een wiskundig model. Geef bij elk een voorbeeld.
Als biowetenschappelijke ingenieurs zijn er verschillende redenen waarom we geïnteresseerd zouden zijn in het opstellen van een wiskundig model:
1. voor het voorspellen van toekomstige toestanden;
2. voor het ontwerpen en optimaliseren van het systeem;
3. voor het schatten en regelen, met behulp van feedback en metingen;
4. voor de interpreteerbaarheid en het fysisch inzicht.
Een bioreactormodel kan bijvoorbeeld:
1. Het groeitraject van het ferment voorspellen.
2. Worden gebruikt om de reactor te dimensioneren (beluchtingshoeveelheid enz.).
3. Productconcentraties (niet waargenomen) schatten op basis van sensormetingen (waargenomen).
4. Helpen begrijpen hoe de processen met elkaar samenhangen.
Herken of een model lineair is. Geef de voor- en nadelen van een lineair model tegenover een niet-lineair model.
Een model is lineair als een verandering in de invoer overeenkomt met een evenredige verandering in de uitvoer. L(ax+by) = aL(x) + bL(y)
Niet-lineaire modellen hebben complexere relaties tussen variabelen. Kenmerken:
veranderingen zijn niet proportioneel
grafieken zijn vaak curves
interacties tussen variabelen komen vaak voor
voordelen:
wiskundig eenvoudiger
makkelijker te analyseren
sneller te berekenen
goede benadering voor kleine veranderingen
nadelen:
minder realistisch: veel echte systemen zijn niet-lineair
geen complexe dynamiek: bevatten meestal geen chaos, oscillaties, …
beperkte toepassingsgebied
Leg het verschil uit tussen een dynamisch en statisch model.
Statisch model = beschrijft een systeem op één specifiek moment in de tijd
→ momentopname
tijd speelt geen rol
variabelen veranderen niet in de tijd
het systeem wordt als constant beschouw
Het model beschrijft enkel de relatie tussen variabelen op dat moment.
Dynamisch model = beschrijft hoe een systeem verandert in de tijd
—> bevat expliciet tijdsafhaneklijke variabelen
tijd is een belangrijke variabele
variabelen veranderen continu
het model beschrijft processen en evolutie
Op welke manieren kan een model “discreet” zijn? Waarom zijn computermodellen altijd in zekere mate discreet?
Discrete modellen:
• Systemen worden weergegeven als een verzameling afzonderlijke, losstaande elementen of toestanden.
• Variabelen veranderen in vastomlijnde stappen of sprongen.
• Voorbeelden: bordspellen, wachtrijsystemen, bevolkingsmodellen met afzonderlijke generaties.
Continue modellen:
• Systemen worden weergegeven met vloeiende, ononderbroken veranderingen.
• Variabelen kunnen elke waarde binnen een bepaald bereik aannemen.
• Voorbeelden: vloeistofstroming, temperatuurveranderingen, de beweging van planeten.
Computermodellen zijn altijd in zekere mate discreet, omdat computers zelf digitale machines zijn. Zij kunnen geen volledig continue grootheden exact representeren.
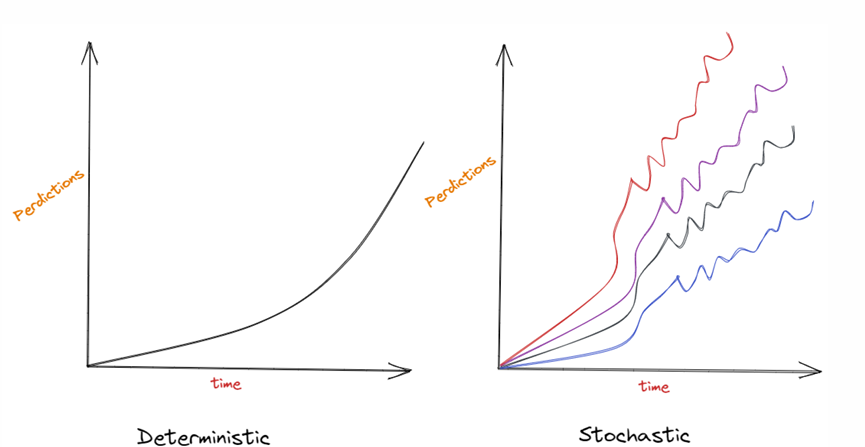
Geef een voorbeeld van een deterministisch en stochastisch model. Leg daarbij het verschil tussen de twee uit.
Deterministische modellen gaan ervan uit dat alle variabelen en parameters met zekerheid bekend zijn. Op basis van de beginvoorwaarden en de vergelijkingen van het model kan het toekomstige gedrag van het systeem nauwkeurig worden voorspeld, als een uurwerk. Er is geen sprake van willekeur, en dezelfde invoer levert altijd dezelfde uitvoer op. Deterministische modellen worden vaak gebruikt wanneer de onderliggende processen goed begrepen worden en de bronnen van variabiliteit minimaal zijn of verwaarloosbaar. De bewegingswetten van Newton beschrijven de deterministische relatie tussen kracht, massa en versnelling. Gegeven de beginspositie en -snelheid van een object kan de toekomstige baan ervan nauwkeurig worden berekend.
vb.: predicting the trajectory of a projectile in a vacuum
Stochastische modellen daarentegen nemen willekeur of onzekerheid expliciet op in het model. Ze erkennen dat sommige variabelen of parameters mogelijk niet met zekerheid bekend zijn en dat er inherente variabiliteit kan zitten in het gedrag van het systeem. Stochastische modellen maken doorgaans gebruik van kansverdelingen die het bereik van mogelijke uitkomsten en hun waarschijnlijkheden weergeven. Deze modellen zijn essentieel bij het omgaan met complexe systemen waarin onzekerheid een belangrijke rol speelt, zoals weersvoorspellingen, financiële markten of biologische processen. Een stochastisch model van aandelenkoersen zou bijvoorbeeld willekeurige schommelingen kunnen opnemen om de onvoorspelbare aard van marktbewegingen weer te geven. Het model zou een reeks mogelijke toekomstige koersen en hun waarschijnlijkheden opleveren.
vb.:predicting the spread of a disease, where individuel interactions are unpredictable
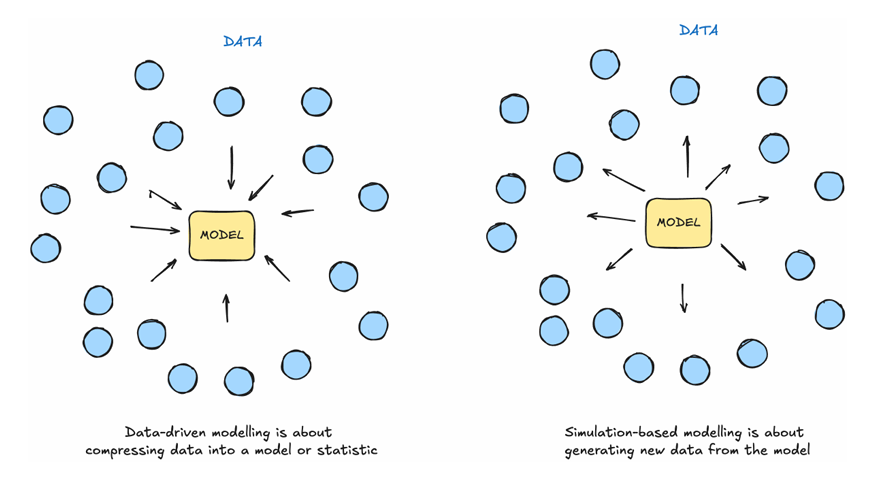
Bespreek het verschil tussen data-gedreven en mechanistisch modelleren. Gegeven een voorbeeld, leg uit wrm of wnr je het een of het ander zou prefereren.
Een datagestuurd model is voornamelijk gebaseerd op waargenomen gegevens.
+ Legt elk patroon vast bij voldoende gegevens
+ Geschikt voor voorspellingen
- Is mogelijk niet generaliseerbaar
- Lagere verklaringskracht
Een mechanistisch model is voornamelijk gebaseerd op kennis van onderliggende processen en natuurkundige wetten.
+ Kan worden toegepast op nieuwe scenario’s
+ Inzicht in onderliggende processen
- Vereist gedetailleerde kennis
- Soms rekenintensief
Gegeven een onderzoeksvraag, leg uit of je een spatiaal expliciet of impliciet model zou gebruiken. Zorg daarbij dat het verschil tussen de twee duidelijk is.
Ruimtelijk expliciet:
• Houdt rekening met de locatie en de ruimtelijke indeling van componenten.
• Geeft interacties en processen weer die afhankelijk zijn van de locatie.
• Voorbeeld: de verspreiding van een ziekte in een stad, waarbij rekening wordt gehouden met hoe mensen zich verplaatsen en met elkaar omgaan.
Ruimtelijk impliciet:
• Negeert ruimtelijke locaties en gaat ervan uit dat alle componenten „goed gemengd” zijn.
• Eenvoudiger, maar legt mogelijk geen belangrijke ruimtelijke dynamieken vast.
• Voorbeeld: Een eenvoudig bevolkingsgroeimodel zonder rekening te houden met waar individuen wonen.
Wat zijn “lumped” modellen?
“Lumped” modellen (geconcentreerde modellen) zijn modellen waarbij men aanneemt dat grootheden zoals temperatuur, concentratie of druk niet variëren in de ruimte, maar overal in het systeem dezelfde waarde hebben. Het systeem wordt dus voorgesteld als één homogeen geheel. Hierdoor hangen de variabelen enkel af van de tijd en niet van de plaats, en wordt het model beschreven met gewone differentiaalvergelijkingen (DVG’s) in plaats van partiële differentiaalvergelijkingen.
Daartegenover staan gedistribueerde modellen, waarbij grootheden wél variëren in de ruimte. In dat geval zijn de variabelen functies van zowel plaats als tijd en worden ze beschreven met partiële differentiaalvergelijkingen (PDV’s).
Leg uit hoe je een PDV zou benaderen door een stelsel van gewone DVG.
Om een PDV om te zetten naar een stelsel van gewone differentiaalvergelijkingen, ga je
het systeem discretiseren in de ruimte.
Dit betekent dat je het ruimtelijke domein (bijvoorbeeld een staaf of een buis) opdeelt in een eindig aantal kleine stukjes of knooppunten.
Vervolgens
neem je aan dat binnen elk klein stukje de grootheden ongeveer constant zijn
(dus lokaal “lumped”). In plaats van een continue functie van de ruimte, werk je dan met een eindig aantal variabelen, bijvoorbeeld de temperatuur op elk knooppunt.
Daarna
vervang je de ruimtelijke afgeleiden in de PDV door benaderingen met eindige verschillen tussen naburige punten.
Hierdoor verdwijnt de ruimtelijke afgeleide en krijg je voor elk knooppunt een vergelijking die enkel nog afhangt van de tijd.
Op die manier ontstaat een stelsel van gekoppelde gewone differentiaalvergelijkingen, waarbij elke vergelijking de evolutie in de tijd beschrijft van één punt in de ruimte, en gekoppeld is aan de naburige punten.
Wat is het verschil tussen een simulatie en een emulatie?
Het verschil tussen een simulatie en een emulatie ligt vooral in hoe nauwkeurig het oorspronkelijke systeem wordt nagebootst en met welk doel.
Een simulatie is een vereenvoudigde nabootsing van een reëel systeem. Men bouwt een model dat enkel de belangrijkste eigenschappen en gedragingen van het systeem bevat, en voert dat model uit om te bestuderen hoe het systeem zich gedraagt onder verschillende omstandigheden. Een simulatie abstraheert dus van details die niet relevant zijn voor de onderzoeksvraag. Het doel is meestal inzicht verkrijgen, voorspellingen doen of hypothesen testen.
Een emulatie daarentegen probeert een systeem zo exact mogelijk te reproduceren, inclusief alle functies en eigenschappen. Het doel is dat het nagebootste systeem zich identiek gedraagt als het originele systeem. Een typisch voorbeeld is een computeremulator die ervoor zorgt dat software van een ander systeem exact hetzelfde werkt.
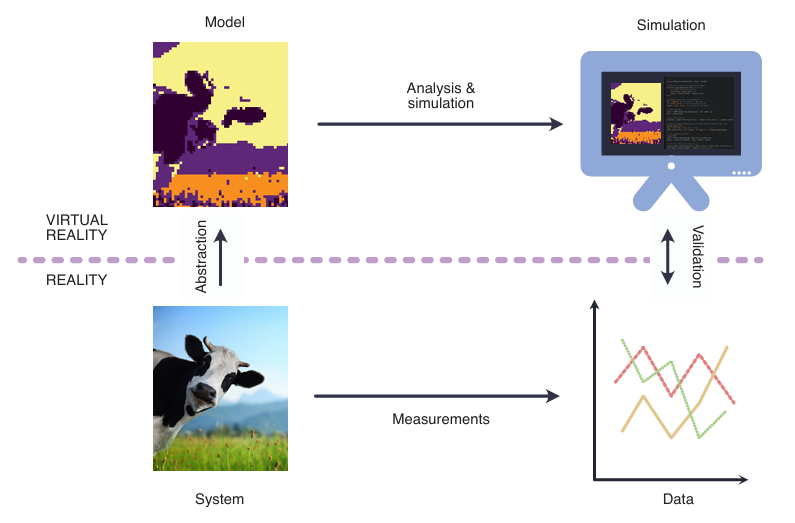
Maak een diagram van de simulatiecyclus en leg uit.
De cyclische relatie tussen de virtuele en de reële wereld in
de context van modellering en simulatie. Het model fungeert als het centrale element dat deze twee werelden met elkaar verbindt. Het proces begint in de virtuele wereld met analyse en simulatie, waarbij het model aan verschillende scenario’s wordt onderworpen en het gedrag ervan wordt geobserveerd. De inzichten die uit deze simulaties worden verkregen, worden vervolgens via metingen en systeemgegevens vertaald naar de reële wereld. Gegevens uit de echte wereld worden gebruikt om het model te valideren, waardoor de nauwkeurigheid en effectiviteit ervan worden gewaarborgd. De cyclus keert terug naar de virtuele wereld met abstractie, waarbij de gegevens uit de echte wereld in het model worden verwerkt, waardoor het wordt verfijnd en verbeterd.
Wat is een conservatiewet?
Behoudswetten stellen dat bepaalde grootheden in geïsoleerde systemen behouden blijven. Sommige van deze wetten zijn fundamentele natuurkundige wetten: de wet van behoud van energie, de wet van behoud van impuls of de wet van behoud van lading. Andere gevallen zijn meer toepassingsspecifiek, zoals de wet van behoud van massa.
change = input - output+production - consumption.
Beschrijf de 5 stappen van massabalans modellering
Bij het opstellen van balansmodellen moet men altijd dezelfde vijf stappen volgen:
1. Bepaal de systeemgrenzen: Bepaal wat je modelleert en wat daarop inwerkt.
2. Bepaal de relevante grootheden: Kies de variabelen die je wilt volgen (bijv. massa, energie, concentratie, enz.).
3. Stel balansvergelijkingen op: Schrijf vergelijkingen op basis van het bovenstaande principe, waarin wordt weergegeven hoe elke grootheid in de tijd verandert.
4. Druk snelheden wiskundig uit: beschrijf de input-, output-, generatie- en verbruiksnelheden in termen van de door u gekozen variabelen, vaak met behulp van relaties of natuurkundige wetten.
5. Verkrijg differentiaalvergelijkingen: vul de snelheidsuitdrukkingen in de balansvergelijkingen in, wat doorgaans een stelsel van differentiaalvergelijkingen oplevert.
Geef de wet van Massa-Actie Kinetiek. Leg uit hoe die intuïtief tot stand komt.
De wet van massa-actie kinetiek stelt dat de reactiesnelheid evenredig is met het product van de concentraties van de reagentia, elk verheven tot hun stoichiometrische coëfficiënt. Voor een reactie van de vorm
aA+bB→cC+dD
wordt dit geschreven als:
v=k[A]^a[B]^b
Hierin is v de reactiesnelheid en k de reactieconstante.
Intuïtieve verklaring
De wet van massa-actie kan intuïtief begrepen worden vanuit het idee van botsingen tussen moleculen. Een reactie kan enkel plaatsvinden wanneer de juiste moleculen elkaar ontmoeten en op de juiste manier botsen. Hoe hoger de concentratie van stof A en B, hoe groter het aantal moleculen per volume en dus hoe groter de kans dat ze elkaar tegenkomen.
Voor een reactie waarbij bijvoorbeeld twee moleculen van A en één van B nodig zijn, moet er een gelijktijdige botsing plaatsvinden tussen die drie moleculen. De kans daarop is evenredig met het product van hun concentraties, wat leidt tot de vorm [A]^a[B]^b. De constante k bundelt alle andere factoren die de kans op een succesvolle reactie bepalen, zoals temperatuur en botsingsoriëntatie.
Leg het verschil uit tussen de reactieconstante en de reactiesnelheid.
De reactieconstante k is een parameter die eigen is aan de specifieke reactie en omstandigheden (zoals temperatuur). Ze geeft aan hoe snel een reactie verloopt wanneer de concentraties gegeven zijn, en verandert niet tijdens de reactie zelf (bij constante omstandigheden).
De reactiesnelheid v daarentegen is de werkelijke snelheid waarmee de concentraties veranderen in de tijd. Deze hangt af van zowel de reactieconstante als de actuele concentraties van de reagentia. Omdat de concentraties tijdens de reactie veranderen, zal ook de reactiesnelheid meestal veranderen in de tijd.
Herken, geef voorbeelden van en beschrijf de kinetiek met DVG van nulde-orde processen
Nulordeprocessen of nulordereacties zijn processen waarbij de kinetiek onafhankelijk is van de concentratie of dichtheid van de stof:
dy/dt = r
waarbij ( r ) positief kan zijn (y wordt geproduceerd) of negatief (y wordt verbruikt of verwijderd). Het oplossen van deze vergelijking met beginvoorwaarde ( y(t) = y_0 ) geeft:
y(t) = y_0 + rt
Nulordereacties komen voor in vrijwel elk toepassingsgebied:
(hydraulica) Water wordt met een constante debiet aan een tank toegevoegd of eruit verwijderd.
(chemie) Een chemische stof wordt met een constante snelheid aan een reactor toegevoegd.
(biochemie) Enzymatische reacties waarbij de enzymconcentratie veel lager is dan die van het reagens zijn bij benadering nulorde: extra reagentia toevoegen verhoogt de reactiesnelheid niet omdat alle actieve plaatsen van het enzym bezet zijn.
(thermische systemen) Rechtstreeks warmte toevoegen aan een systeem via een verwarmingselement.
(ecologie) Migratie van een soort naar of uit een ecosysteem.
(economie) Het ontvangen van een constant loon of het hebben van vaste maandelijkse kosten.
Herken, geef voorbeelden van en beschrijf de kinetiek met DVG van eerste-orde processen
Eerste-ordeprocessen zijn evenredig met ( y ):
dy/dt = ry
wat de volgende oplossing heeft met de eerder vermelde beginvoorwaarde:
y(t) = y_0 e^rt
Het klassieke voorbeeld van een eerste-ordeproces is exponentiële groei (( r > 0 )) of exponentieel verval (( r < 0 )). Andere voorbeelden zijn:
(hydraulica) Een tank lekt water met een snelheid die evenredig is met de druk onderaan, die op zijn beurt evenredig is met de waterhoogte en het volume (bij een cilindrische tank).
(biochemie) De vroege groei van bacteriën.
(fysiologie) Het afbreken van cafeïne (of alcohol) in het lichaam.
(thermische systemen) Afkoeling volgens de wet van Newton: de snelheid van afkoeling of opwarming is evenredig met het temperatuurverschil met de omgeving.
(ecologie) Groei van bacteriën in een vroege fase zonder beperkingen.
(economie) Vermogen dat groeit door een vaste rente of in waarde daalt door inflatie.
Hoe meer er aanwezig is, hoe sneller het proces verloopt.
Veel processen kunnen goed benaderd worden met eerste-orde kinetiek; het kan immers gezien worden als een eerste-orde Taylorbenadering. Op lange termijn is dit model echter niet volledig realistisch:
Eerste-orde groeiprocessen kunnen niet onbeperkt doorgaan. Bacteriën blijven zich vermenigvuldigen tot hun voedingsstoffen uitgeput raken of afvalstoffen hun groei remmen. Ook economische groei die afhankelijk is van natuurlijke hulpbronnen zal grenzen bereiken. Eerste-orde groei is dus niet duurzaam.
Eerste-orde verval (exponentieel verval) nadert nul, maar bereikt het niet in eindige tijd. In de praktijk zijn veel grootheden discreet en kunnen ze wel volledig verdwijnen. Dit kan tot foutieve voorspellingen leiden, bijvoorbeeld wanneer een model suggereert dat een schadelijke soort nog in zeer kleine hoeveelheden aanwezig blijft en later opnieuw kan groeien. Discrete stochastische modellen kunnen dit probleem beter aanpakken.
Herken, geef voorbeelden van en beschrijf de kinetiek met DVG van tweede-orde processen
Tweede-ordeprocessen voor één soort hebben de volgende dynamiek:
dy/dt=ry²
Dit is een niet-lineaire differentiaalvergelijking, die kan voorkomen in autocatalytische reacties, waarbij de gevormde stof haar eigen vorming katalyseert. Het oplossen van deze vergelijking geeft:
y(t) = y_0/(1-ry_0t)
wat leidt tot een superexponentiële groei en een asymptoot heeft bij t = (r y_0)^-1.
Tweede-ordereacties van deze vorm zijn relatief zeldzaam, maar reacties zoals:
A+B→C
hebben een reactiesnelheid die evenredig is met zowel A als B, of in het geval dat twee moleculen van A reageren:
A+A→C
is de snelheid evenredig met A^2 .
Tweede-ordeprocessen in deze vorm komen voor in verschillende domeinen:
(chemie) Ontleding van stikstofdioxide: NO₂ + NO₂ → 2NO + O₂.
(biochemie) DNA-hybridisatie, die afhangt van de concentratie van beide strengen.
(ecologie) Seksuele voortplanting, waarbij twee geslachten aanwezig moeten zijn.
(ecologie) Predatie, die afhangt van zowel de prooi als de predator.
(economie) Technologische innovatie: volgens optimisten helpen uitvindingen (zoals AI) bij het creëren van nieuwe uitvindingen, wat leidt tot superexponentiële groei.
Tweede-ordeprocessen ontstaan wanneer twee soorten elkaar ontmoeten en met elkaar interageren. De kans op een ontmoeting wordt verondersteld evenredig te zijn met het product van hun dichtheden. Dit is een goede benadering voor veel systemen, maar blijft een benadering. Vooral levende organismen gaan actief op zoek naar elkaar (zoals predatoren die op prooien jagen), waardoor de werkelijke reactiesnelheid kan afwijken van die volgens de wet van massa-actie.
Herken, geef voorbeelden van en beschrijf de kinetiek met DVG van hogere-orde processen
Hogere-ordeprocessen, bijvoorbeeld wanneer drie soorten met elkaar interageren, zijn analoog en kunnen eveneens verwerkt worden door Catalyst.jl. Zoals bekend uit de chemie, weerspiegelt de globale reactievergelijking niet altijd het werkelijke mechanisme. Zo wordt fotosynthese vaak voorgesteld door de vergelijking:
6CO2 + 6H2O →licht→C6H12O6 + 6O2
In werkelijkheid verloopt fotosynthese niet in één (twaalfde-orde) stap, maar via honderden complexe reacties die interageren met metabolieten en celstructuren in de plantencel. Het opsplitsen van een complex biologisch proces in essentiële deelprocessen en het maken van geschikte benaderingen vormt de uitdaging voor een goede modelleur.
Herken en beschrijf wnr je de Michaelis-Menten kinetiek zou gebruiken
Wanneer herken je dat je Michaelis-Menten moet gebruiken?
Je kiest dit model wanneer:
De reactie gekatalyseerd wordt door een enzym (E + S → ES → E + P).
De reactiesnelheid niet lineair blijft toenemen met de substraatconcentratie.
Er een maximale reactiesnelheid optreedt (het enzym raakt verzadigd).
Bij lage concentraties van het substraat de snelheid ongeveer evenredig is met S (eerste orde), maar bij hoge concentraties onafhankelijk wordt van S (nulde orde).
Beschrijving van de kinetiek
De Michaelis-Menten vergelijking luidt:
v=vmax*S/K_S+S
Hierin:
v = reactiesnelheid
S = substraatconcentratie
vmaxv = maximale reactiesnelheid (alle enzymen zijn bezet)
K_S = Michaelis-constante (maat voor hoe snel verzadiging optreedt; bij S=K is v=vmax/2
Intuïtieve uitleg
Bij lage substraatconcentratie zijn er weinig enzym-substraatcomplexen (ES), dus bepaalt de beschikbaarheid van S de snelheid → eerste orde gedrag.
Bij hoge substraatconcentratie zijn bijna alle enzymen bezet (verzadigd), waardoor extra substraat geen effect meer heeft → de snelheid bereikt een maximum → nulde orde gedrag.
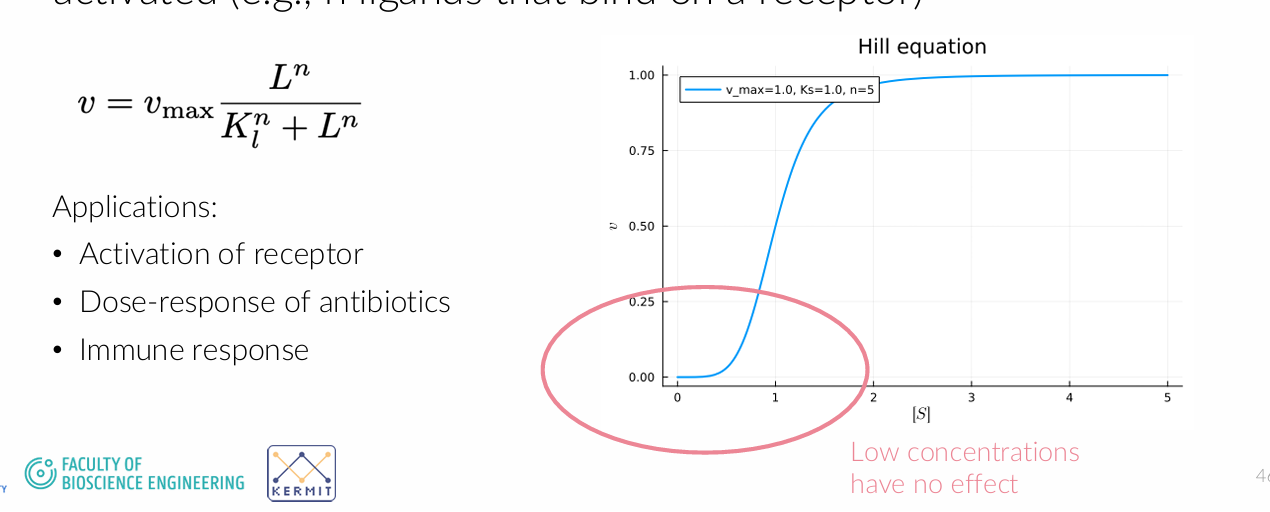
Herken en beschrijf wnr je de Hill vergelijking zou gebruiken.
Hill-vergelijking
Je gebruikt de Hill-vergelijking wanneer je een proces wilt modelleren waarbij er sprake is van coöperativiteit of een drempelachtig (“switch”-achtig) gedrag.
Herkenning:
Een ligand (bijv. een molecuul of hormoon) bindt aan een receptor of enzym met meerdere bindingsplaatsen.
Het systeem wordt pas echt actief wanneer (bijna) alle bindingsplaatsen bezet zijn.
De respons vertoont een sterke, niet-lineaire overgang: onder een bepaalde concentratie gebeurt er weinig, daarboven stijgt de activiteit snel.
Beschrijving:
De Hill-vergelijking heeft de vorm:
v=vmax*L^n/Kl^n+L^n
Voor lage L: v≈0
Voor hoge L: v≈vmax
De parameter n bepaalt hoe scherp de overgang is (grotere n → meer “alles-of-niets”).
Typische toepassingen:
Genregulatie (activatie of repressie van genexpressie)
Binding van zuurstof aan hemoglobine
Effect van medicijnen of hormonen (dosis-respons)
👉 Intuïtief: je gebruikt de Hill-vergelijking wanneer een systeem zich gedraagt als een schakelaar in plaats van een geleidelijke respons.
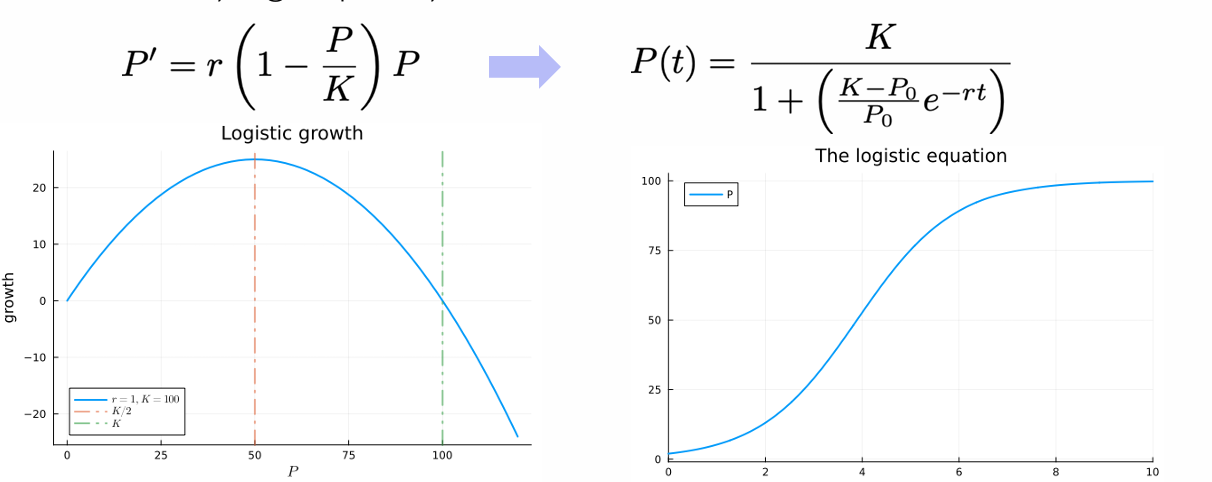
Herken en beschrijf wnr je logistische groei zou gebruiken.
Logistische groei
Je gebruikt logistische groei wanneer je een populatie modelleert die groeit maar beperkt wordt door middelen of ruimte.
Herkenning:
Er is in het begin snelle (bijna exponentiële) groei.
De groei vertraagt naarmate de populatie groter wordt.
Er bestaat een maximale populatiegrootte (carrying capacity KKK).
Beschrijving:
De logistische groeivergelijking is:
dP/dt = r(1-P/K)*P
Voor kleine P: bijna exponentiële groei
Voor P≈K: groei stopt
Voor P>K: populatie neemt af
Typische toepassingen:
Populatiegroei van dieren of bacteriën met beperkte resources
Groei van ecosystemen
Verspreiding van soorten met competitie
Soms ook in economie (groei met limieten)
👉 Intuïtief: je gebruikt logistische groei wanneer een systeem eerst vrij groeit, maar afgeremd wordt door beperkingen.
Herken en beschrijf wnr je compartimentsmodel zou gebruiken.
Wanneer gebruik je een compartimentsmodel?
Je gebruikt een compartimentsmodel wanneer je een complex systeem wilt opsplitsen in duidelijk afgebakende delen (compartimenten) tussen welke er uitwisseling plaatsvindt. Dit is typisch wanneer:
Er stromen of transfers zijn tussen verschillende delen (bv. organen, populaties, reactorzones).
Je stocks/hoeveelheden wil opvolgen (bv. aantal individuen, concentraties).
Ruimtelijke details minder belangrijk zijn, maar je wel structuur nodig hebt.
Het systeem redelijk goed voldoet aan de homogeniteitsaanname (elk compartiment is goed gemengd).
Voorbeelden: epidemiologie (SIR), farmacokinetiek, ecologie, chemische reactoren.
Leg kort het verschil tussen voorwaarts en achterwaarts automatisch afleiden uit en wnr je de ene of de andere zou gebruiken. Voorwaartse automatische differentiatie:
Voorwaartse automatische differentiatie (forward mode)
Bij voorwaartse differentiatie wordt de computational graph van de invoer naar de uitvoer doorlopen, dus in dezelfde volgorde als de oorspronkelijke berekening. Bij elke stap berekent men zowel de functiewaarde als de afgeleide ten opzichte van een gekozen invoervariabele. De afgeleiden worden stap voor stap opgebouwd via de kettingregel.
Kenmerk: één doorloop van het algoritme geeft de afgeleide met betrekking tot één invoervariabele.
Wanneer gebruiken?
Forward mode is het meest efficiënt wanneer een functie weinig invoervariabelen maar veel outputs heeft.
Bijvoorbeeld: een model met enkele parameters waarvan we de oplossing op veel tijdstappen evalueren.
Leg kort het verschil tussen voorwaarts en achterwaarts automatisch afleiden uit en wnr je de ene of de andere zou gebruiken. Achterwaartse automatische differentiatie:
Achterwaartse automatische differentiatie (reverse mode)
Bij achterwaartse differentiatie wordt de computational graph in omgekeerde richting doorlopen: van de uitvoer naar de invoer. Men start met de afgeleide van de output naar zichzelf (die gelijk is aan 1) en gebruikt vervolgens de kettingregel om de afgeleiden naar alle invoervariabelen terug te propageren.
Kenmerk: één achterwaartse doorloop berekent de afgeleiden van de output naar alle invoervariabelen tegelijk.
Wanneer gebruiken?
Reverse mode is het meest efficiënt wanneer een functie veel invoervariabelen maar slechts één output heeft.
Dit komt bijvoorbeeld vaak voor in machine learning, waar een model miljoenen parameters heeft maar slechts één verliesfunctie (loss).
Wat zijn stijve (stiff) differentiaalvgl?
Een stijve differentiaalvergelijking is een differentiaalvergelijking waarvan de oplossing op meerdere zeer verschillende tijdschalen verandert. Dat betekent dat sommige processen in het systeem heel snel verlopen, terwijl andere veel trager evolueren.
Met andere woorden: het systeem bevat snelle en trage dynamica tegelijk.
Een eenvoudig voorbeeld is de vergelijking uit het verbrandingsmodel:
u’(t) = u²-u³
Hier groeit het systeem eerst snel en evolueert daarna trager naar een stabiel evenwicht.
Wnr zou je die stijve DVN kunnen tegenkomen?
Stijve ODE’s komen vaak voor in systemen waar processen met verschillende tijdschalen tegelijk optreden. Typische voorbeelden zijn:
Biologische systemen
Bijvoorbeeld: fotosynthese reageert in microseconden terwijl biomassa-opbouw dagen duurt.Chemische reacties
Sommige reacties (zoals radicalenreacties) gebeuren extreem snel, terwijl andere veel trager verlopen.Verbrandingsprocessen
Ecologische of farmacokinetische modellen
Elektrische circuits met snelle en trage componenten
In zulke systemen veranderen sommige variabelen dus veel sneller dan andere.
Wat is het probleem met stijve DVG? Hoe ga je hier mee om?
Het probleem ontstaat bij de numerieke oplossing van de differentiaalvergelijkingen.
Veel standaardmethoden voor ODE’s, zoals:
Euler methode
klassieke Runge–Kutta methoden
zijn expliciete methoden. Deze methoden zijn instabiel bij stijve problemen tenzij men een zeer kleine tijdstap gebruikt.
Dit leidt tot twee grote problemen:
Extreem kleine tijdstappen nodig om stabiliteit te garanderen.
Zeer lange rekentijd, zelfs wanneer men eigenlijk enkel geïnteresseerd is in de trage dynamiek van het systeem.
Dus zelfs wanneer het snelle gedrag fysisch niet zo belangrijk is op lange termijn, dwingt het de numerieke solver toch om heel kleine stappen te nemen.
→ Hoe ga je om met stijve differentiaalvergelijkingen?
Voor stijve systemen gebruikt men speciale numerieke methoden, namelijk impliciete solvers. Deze zijn stabieler bij stijve problemen en laten grotere tijdstappen toe.
Voorbeelden van zulke methoden zijn:
Rosenbrock-methoden
Backward Euler
BDF-methoden (Backward Differentiation Formulas)
Deze methoden lossen bij elke stap een vergelijking impliciet op, waardoor ze veel stabieler zijn voor systemen met snelle dynamica.
Wat is het verschil tssn een expliciete en impliciete numerieke methode om DVGn op te lossen?
Expliciete methoden:
Deze methoden gebruiken uitsluitend informatie van de huidige tijdstap t_n en de bijbehorende oplossingswaarde y(t_n). Ze gebruiken een eindige-differentieschema om de afgeleide y′ in t_n te benaderen. Deze benaderde afgeleide wordt vervolgens samen met y(t_n) ingevuld in een expliciete formule om rechtstreeks de oplossing in de volgende tijdstap te berekenen, y(t_n+1). Voorbeelden van expliciete methoden zijn de methode van Euler en veel Runge–Kutta-methoden.
Impliciete methoden:
In tegenstelling tot expliciete methoden gebruiken impliciete methoden informatie van zowel de huidige als de toekomstige tijdstap. Ze bevatten een vergelijking waarin zowel y(t_n) als y(t_(n+1)) voorkomt (de oplossingswaarde die we juist willen bepalen). Deze vergelijking moet vaak iteratief opgelost worden, bijvoorbeeld met de methode van Newton. Impliciete methoden kunnen betere stabiliteit bieden voor bepaalde soorten differentiaalvergelijkingen, vooral voor stijve problemen (zie Sectie 3.2.4). Toch kunnen ze rekenkundig gezien meer rekenkracht vergen, omdat bij elke stap een impliciete vergelijking moet worden opgelost. Voorbeelden hiervan zijn de achterwaartse Euler-methode en sommige impliciete Runge-Kutta-methoden.
Wat is het verschil tussen “continuous” en “discrete callbacks”? Geef een mogelijke toepassing van elk.
Continuous callbacks worden geactiveerd wanneer een continue conditiefunctie een bepaalde waarde (meestal nul) kruist. De solver detecteert dit punt nauwkeurig door extra berekeningen rond dat moment uit te voeren. Ze worden vaak gebruikt wanneer een toestand een grens bereikt of wanneer een parameter plots verandert afhankelijk van de systeemtoestand.
Toepassing: een stuiterende bal. Wanneer de positie van de bal y=0 bereikt (de vloer), wordt de snelheid omgekeerd en eventueel verkleind om energieverlies te modelleren.
Discrete callbacks worden geactiveerd op vaste tijdstippen of na een bepaald aantal stappen. Ze hangen dus niet af van een continue conditie in de oplossing, maar van vooraf bepaalde momenten.
Toepassing: een bioreactor waarin periodiek substraat wordt toegevoegd, bijvoorbeeld elke vijf uur extra glucose toevoegen om bacteriegroei te stimuleren.
Is het beter om plotse wijzigingen van input/ parameters in je ODE systeem te incorporeren of via een callback af te handelenen? Waarom?
Het is beter om plotse wijzigingen van input of parameters via callbacks af te handelen in plaats van ze rechtstreeks in het ODE-systeem te incorporeren. Dit komt omdat differentiaalvergelijkingen in principe bedoeld zijn om continue en gladde veranderingen te beschrijven, terwijl plotse sprongen juist discontinu zijn en daarom moeilijk correct in de vergelijkingen zelf te verwerken zijn.
Wanneer je dergelijke sprongen toch in het ODE-systeem opneemt, bijvoorbeeld met voorwaarden zoals if-statements, kan dit leiden tot numerieke problemen en onnauwkeurigheden. De solver weet dan namelijk niet exact wanneer de verandering plaatsvindt, wat de betrouwbaarheid van de oplossing vermindert.
Callbacks bieden hiervoor een betere oplossing, omdat de solver specifiek ontworpen is om gebeurtenissen op het juiste moment te detecteren. Bij een continue callback kan de solver bijvoorbeeld nauwkeurig bepalen wanneer een bepaalde toestand een grenswaarde bereikt, en op dat exacte moment de nodige aanpassing uitvoeren. Bij discrete callbacks kunnen veranderingen op vooraf bepaalde tijdstippen worden toegepast.
Daarnaast zorgen callbacks voor een duidelijke scheiding tussen het continue model en de discrete gebeurtenissen, wat het model overzichtelijker en gemakkelijker te begrijpen maakt. Daarom hebben callbacks de voorkeur voor het modelleren van plotse veranderingen in systemen die verder continu gedrag vertonen
Leg in je eigenwoorden uit wat een Wiener proces is. Welke fysische proces modelleert dit? Is dit een “gladde” functie?
Een Wienerproces is een wiskundig model voor een willekeurig proces dat continu in de tijd evolueert, maar waarbij de veranderingen volledig bepaald worden door toeval. In elk klein tijdsinterval wordt er een kleine, normaal verdeelde willekeurige stap toegevoegd, met gemiddelde nul en een variantie die afhangt van de grootte van het tijdsinterval. Bovendien zijn deze stappen onafhankelijk van elkaar, wat betekent dat de toekomstige evolutie niet afhangt van het verleden.
Fysisch modelleert een Wienerproces de Brownse beweging, dat is de grillige, willekeurige beweging van kleine deeltjes in een vloeistof of gas. Deze beweging ontstaat doordat de deeltjes voortdurend botsen met moleculen uit hun omgeving, wat leidt tot onvoorspelbare veranderingen in hun snelheid en richting.
Hoewel een Wienerproces continu is (er zijn geen sprongen), is het geen gladde functie. Dat betekent dat het nergens differentieerbaar is: als je inzoomt op de grafiek, blijft die er altijd “ruw” en grillig uitzien. Daardoor kun je er geen gewone afgeleide van nemen, wat een belangrijk verschil is met klassieke functies in gewone differentiaalvergelijkingen.
Geef de algemene vorm van een SDE. Wat moet je specifieren? Wnr zou je een SDE gebruiken?
De algemene vorm van een stochastische differentiaalvergelijking (SDE) is:
dY(t)=μ(Y(t),t)dt+σ(Y(t),t)dW
Hierbij moet je twee dingen specificeren: de driftterm μ(Y(t),t), die het deterministische gedrag beschrijft, en de diffusieterm σ(Y(t),t), die de sterkte van de ruis bepaalt. Daarnaast moet je ook een beginvoorwaarde geven en het type ruis (meestal een Wienerproces).
Je gebruikt een SDE wanneer je een systeem wil modelleren dat niet volledig deterministisch is, maar onderhevig is aan continue willekeurige fluctuaties, zoals in biologische systemen, financiële markten of chemische processen met ruis.
Geef de algemene vorm van een SDE. Welke belangrijke stochastisch proces is hier relevant? Leg het uit in je eigenwoorden.
De algemene vorm van een SDE is opnieuw:
dY(t)=μ(Y(t),t)dt+σ(Y(t),t)dW
Het belangrijkste stochastische proces hierin is het Wienerproces. Dit is een continu proces dat willekeurige beweging beschrijft waarbij op elk klein tijdsinterval een kleine, normaal verdeelde verstoring wordt toegevoegd. In mijn eigen woorden: het is een model voor een pad dat voortdurend willekeurig “wiebelig” beweegt, zonder vaste richting, zoals een dronken persoon die willekeurig rondwandelt. Dit proces wordt vaak gebruikt om Brownse beweging te modelleren.
Wat is een jump proces/stochastic simulation algorithm (cfr. het Gillespie algoritme)?
Wat is het verschil met SDEs?
Een jump proces, zoals gesimuleerd met het Gillespie-algoritme, is een stochastisch proces waarbij de toestand in discrete sprongen verandert. In plaats van continue evolutie, veranderen de variabelen plots met gehele stappen (bijvoorbeeld +1 of −1 molecuul) op willekeurige tijdstippen.
Het verschil met SDE’s is dat SDE’s continue variabelen en continue ruis gebruiken, terwijl jump processen werken met discrete aantallen en discrete gebeurtenissen.
Wanneer zou je een jump process gebruiken ipv een SDE? Wanneer een SDE? Wanneer een ODE?
Je gebruikt een jump proces wanneer:
de aantallen klein zijn (bijvoorbeeld tientallen moleculen),
en individuele gebeurtenissen belangrijk zijn (zoals één reactie of sterfte).
Je gebruikt een SDE wanneer:
de aantallen groot zijn,
en ruis als een continue fluctuatie kan worden benaderd.
Je gebruikt een ODE wanneer:
het systeem deterministisch is,
en ruis verwaarloosbaar is of niet relevant.
Gegeven een reactie met een kinetiek, geef de distributie en bereken de verwachte tijd tot een reactie-event adhv de propensiteit.
Voor een reactie met propensiteit a(x)a(x)a(x) volgt de tijd tot het volgende reactie-event een exponentiële verdeling met parameter a(x).
De distributie is dus: T∼Exp(a(x)).
De verwachte tijd tot een reactie-event is: E[T]=a(x)1.
Dit betekent dat hoe groter de propensiteit (dus hoe groter de kans op reactie), hoe korter de gemiddelde wachttijd tot het volgende event.
Leg in je eigen woorden het principe van het Gillespie algoritme uit.
Het Gillespie-algoritme is een methode om een stochastisch systeem met discrete gebeurtenissen exact te simuleren in de tijd. Het principe is dat je telkens bepaalt wanneer de volgende reactie gebeurt en welke reactie dat is.
In mijn eigen woorden werkt het als volgt: je start met een beginsituatie en berekent voor elke mogelijke reactie hoe waarschijnlijk die is (de propensiteit). Vervolgens bepaal je willekeurig hoe lang het duurt tot de volgende reactie, op basis van een exponentiële verdeling met de totale propensiteit. Daarna kies je willekeurig welke reactie plaatsvindt, waarbij reacties met een hogere propensiteit meer kans hebben. Je past het systeem aan volgens die reactie en herhaalt dit proces.
Op die manier bouw je stap voor stap een traject op waarin de toestand van het systeem verandert door afzonderlijke, willekeurige gebeurtenissen.
Geef het principe van de Monte Carlo methode. Leg uit hoe je Monte Carlo kan gebruiken om numerieke problemen op te lossen (integraal uitrekenen, probabiliteiten schatten) . Bespreek voor en nadelen tov andere (deterministische) numerieke methodes.
Het principe van de Monte Carlo methode is dat men willekeurige steekproeven neemt uit een kansverdeling om numerieke resultaten te benaderen. In plaats van een probleem analytisch op te lossen, gebruikt men herhaaldelijk random sampling en statistische analyse om een benadering te verkrijgen. Om bijvoorbeeld een integraal te berekenen, kan men willekeurige punten trekken en het gemiddelde van een functie over deze punten nemen, wat volgens de wet van de grote aantallen convergeert naar de echte waarde. Probabiliteiten kunnen geschat worden door het aandeel van de steekproeven te tellen dat aan een bepaalde eigenschap voldoet. Voor- en nadelen:
• Monte Carlo-methoden (d.w.z. steekproefmethoden) zijn relatief eenvoudig te implementeren, maar zijn geschikt voor zeer complexe problemen
• Afzonderlijke simulaties kunnen onafhankelijk van elkaar worden uitgevoerd, waardoor deze methode zeer goed paralleliseerbaar is!
• Geeft de verdeling van de uitkomsten weer => onzekerheid!
• Gemakkelijk om een benaderend antwoord te krijgen, maar erg moeilijk (grote steekproefomvang!) om een precies antwoord te krijgen
• Er zijn bijna altijd deterministische methoden die in alle opzichten beter zijn...
→ Moeten we die dan voor al onze problemen gebruiken?
• Voor numerieke problemen (bijv. integreren) in een relatief laag aantal dimensies zijn er vaak deterministische methoden die qua nauwkeurigheid en efficiëntie veruit superieur zijn!
• Aan de andere kant kan voor complexe, hoogdimensionale problemen een bescheiden aantal steekproeven al een zeer goed beeld geven van de “vorm” en “locatie” van de verdeling, vooral wanneer ons model onvolmaakt is en onzekerheden bevat!
De vergelijking voor de verwachtingswaarde van de functie van een toevalsveranderlijke is gekend als de Wet van de Onbewuste Statisticus. Geef deze en leg de link uit met MC.
De Wet van de Onbewuste Statisticus stelt dat de verwachtingswaarde van een functie van een toevalsvariabele gegeven wordt door
E[g(X)]=∫g(x)fX(x)dx.
Deze wet betekent dat je de functie gewoon toepast op de waarden van de variabele en daarna het gemiddelde neemt volgens de kansverdeling. De link met Monte Carlo is dat deze integraal vaak moeilijk analytisch te berekenen is, maar eenvoudig kan benaderd worden door sampling. Door veel steekproeven van X te nemen, de functie g toe te passen op elke steekproef en daarna het gemiddelde te nemen, krijg je een benadering van deze verwachtingswaarde. Dit is precies wat Monte Carlo methodes doen in de praktijk.
Gegeven een sample van X, leg uit hoe je P(A), E(X) en E(X|A) schat, waar A een event is.
P(A) schatten door het aantal observaties dat in event A valt te delen door het totaal aantal observaties.
E[X] wordt geschat door het gemiddelde van alle steekproefwaarden te nemen.
E[X∣A] wordt berekend door enkel de steekproeven te nemen waarvoor event A geldt en daarvan het gemiddelde te berekenen. Dit komt overeen met het “filteren” van de data op basis van de voorwaarde en daarna middelen. Deze aanpak volgt rechtstreeks uit de wet van de grote aantallen, die stelt dat steekproefgemiddelden naar de echte waarden convergeren.
Wat is een “seed” in de context van random number generation? Waarom zou je die gebruiken/ vastzetten?
Een “seed” is de beginwaarde van een pseudorandom number generator. Omdat computers deterministisch zijn, worden random getallen gegenereerd via algoritmes die starten vanuit deze seed. Door dezelfde seed te gebruiken, krijg je exact dezelfde reeks “toevallige” getallen. Dit is nuttig om simulaties reproduceerbaar te maken, bijvoorbeeld voor debugging of wetenschappelijk onderzoek. Daarom wordt de seed vaak vastgezet zodat resultaten consistent blijven.
Wat zijn pseudorandom nummers? Welk algoritme wordt vaak gebruikt om deze te genereren?
Pseudorandom nummers zijn getallen die gegenereerd worden door een algoritme en slechts schijnbaar willekeurig zijn. Ze vertonen geen duidelijke patronen, maar zijn in principe volledig voorspelbaar als men het algoritme en de seed kent. Een veelgebruikt algoritme om deze te genereren is de Mersenne Twister. Dit algoritme produceert lange reeksen getallen met goede statistische eigenschappen en wordt vaak gebruikt in simulaties.
Wat is de efficiënte methode om normaal-verdeelde getallen te genereren?
Een efficiënte methode om normaal verdeelde getallen te genereren is de Box-Muller methode. Deze methode transformeert twee uniforme random variabelen naar twee normaal verdeelde variabelen. Het is een klassieke en vaak gebruikte techniek in simulaties. Moderne bibliotheken gebruiken soms nog snellere varianten, maar het principe blijft gebaseerd op dergelijke transformaties.
Wat zijn quasi-random getallen? Waarvoor gebruik je ze? Welke eigenschappen hebben ze? Wat is een methode om ze te genereren?
Quasi-random getallen zijn getallen die niet volledig willekeurig zijn, maar zo gekozen worden dat ze de ruimte zo gelijkmatig mogelijk opvullen, minimaliseren clustering. Is geschikt voor numerieke integratie, optimalisatie en simulaties waarbij uniformiteit van cruciaal belang is. Ze worden gebruikt in Monte Carlo methodes om sneller te convergeren, bijvoorbeeld bij het schatten van integralen of volumes. Hun belangrijkste eigenschap is een lage discrepantie, wat betekent dat ze homogener verdeeld zijn dan pseudorandom getallen. Een bekende methode om ze te genereren is de Sobol-sequentie. Hierdoor kunnen ze efficiënter zijn dan gewone random sampling in bepaalde toepassingen.
Wat zijn “true random numbers”?
“True random numbers” zijn getallen die afkomstig zijn van een fysisch willekeurig proces, zoals thermische ruis of quantumprocessen. Ze worden gebruikt wanneer echte willekeurigheid essentieel is, bijvoorbeeld in cryptografie. Deze getallen worden gegenereerd met speciale hardware die fysieke ruis meet. Hun nadeel is dat ze traag en duur zijn om te genereren. Daarom worden ze meestal niet gebruikt in gewone simulaties, waar pseudorandom nummers voldoende zijn.
Bespreek de convergentie van het gemiddelde ifv de steekproefgrootte en de implicatie voor Monte Carlo.
De convergentie van het gemiddelde hangt af van de steekproefgrootte volgens de wet van de grote aantallen. Het gemiddelde van de steekproef nadert de echte verwachtingswaarde naarmate het aantal observaties toeneemt. De variantie van het gemiddelde daalt als 1/n, en de standaardfout als 1/sqrt(n). Dit betekent dat de nauwkeurigheid traag verbetert. Voor Monte Carlo impliceert dit dat men zeer veel samples nodig heeft om een kleine fout te bereiken.
Herken wnr je volgende distributies zou gebruiken en geef een toepassing.
a. De Bernoulli-verdeling gebruik je voor een ja/nee experiment, zoals een muntworp.
b. De binomiale verdeling gebruik je voor het aantal successen in meerdere onafhankelijke proeven, zoals aantal koppen in meerdere worpen.
c. De geometrische verdeling gebruik je voor het aantal pogingen tot de eerste succes.
d. De Poisson-verdeling gebruik je voor het aantal gebeurtenissen in een tijdsinterval, zoals aantal aankomsten.
e. De normale verdeling gebruik je voor continue variabelen met een klokvormige spreiding rond een gemiddelde.
f. De Laplace-verdeling gebruik je voor data met een piek en zwaardere staarten dan normaal.
g. De triangulaire verdeling gebruik je wanneer je enkel een minimum, maximum en meest waarschijnlijke waarde kent.
h. De uniforme verdeling gebruik je wanneer alle waarden even waarschijnlijk zijn.
i. De Beta-verdeling gebruik je voor kansen tussen 0 en 1.
j. De log-normale verdeling gebruik je voor positieve variabelen met multiplicatieve effecten.
k. De exponentiële verdeling gebruik je voor wachttijden tussen events.
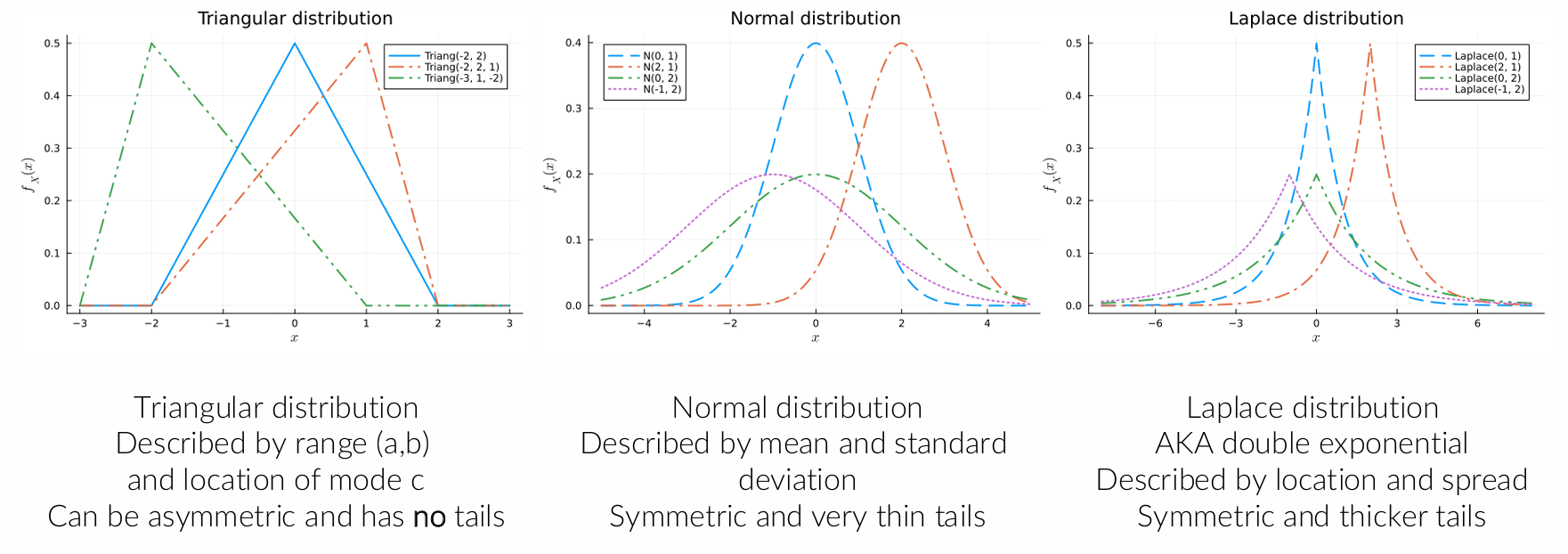
Bespreek de gelijkenissen en verschillen tussen de normale verdeling, de triangulaire distributie en de Laplace verdeling.
De normale, triangulaire en Laplace verdelingen zijn allemaal continue verdelingen met een centrale piek. De normale verdeling is glad en symmetrisch met dunne staarten, waardoor extreme waarden zeldzaam zijn. De Laplace verdeling is ook symmetrisch maar heeft dikkere staarten, waardoor extreme waarden vaker voorkomen. De triangulaire verdeling heeft een lineaire vorm zonder staarten en is begrensd tussen twee waarden. Het grootste verschil zit dus in de staarten en de vorm van de piek.
Geef drie distributies om een prior distributie op een kans (een getal tssn 0 en 1) te plakken.
Drie distributies om een prior op een kans te modelleren zijn de Beta-verdeling, de uniforme verdeling en eventueel een discrete verdeling zoals Bernoulli (in eenvoudige gevallen).
→ De Beta-verdeling is het meest geschikt omdat ze flexibel is en enkel waarden tussen 0 en 1 aanneemt.
→ De uniforme verdeling kan gebruikt worden wanneer men geen voorkennis heeft. Deze distributies laten toe onzekerheid over kansen te modelleren.
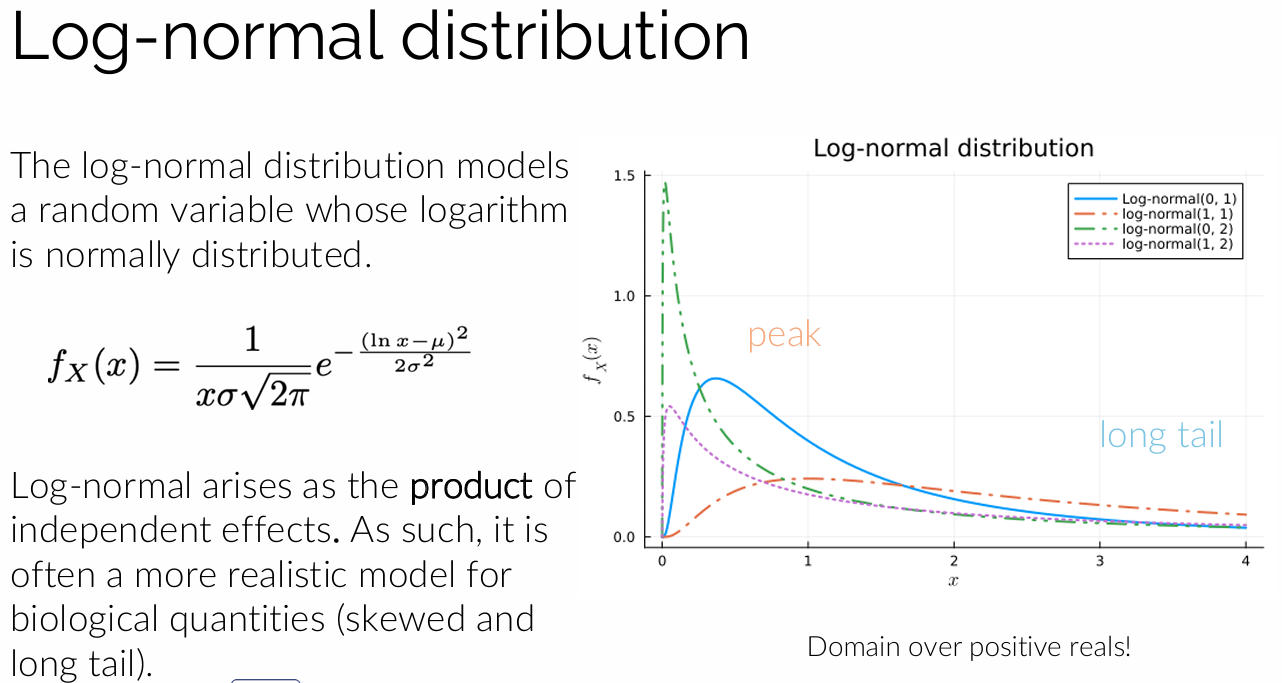
Geef een distributie voor positieve reële getallen met een lange staart. Geef een voorbeeld van iets dat je kan voorstellen met deze distributie.
Een distributie voor positieve reële getallen met een lange staart is de log-normale verdeling. Deze verdeling heeft een piek maar ook een lange staart naar rechts. Ze is geschikt om processen te modelleren die ontstaan uit multiplicatieve effecten. Een voorbeeld is de grootte van deeltjes of inkomensverdelingen. Hierbij komen soms zeer grote waarden voor, wat goed door de lange staart wordt beschreven.

Geef twee methoden om twee probabiliteitsdistributies te combineren in één complexere, gezamelijke (joint) PDF. Bespreek het verschil tussen de 2.
Twee methoden om distributies te combineren zijn productdistributies en mengverdelingen (mixtures).
→ Bij productdistributies worden onafhankelijke variabelen gecombineerd door hun kansdichtheden te vermenigvuldigen. Dit leidt tot een joint distributie zonder afhankelijkheden tussen variabelen.
→ Bij mengverdelingen kiest men eerst willekeurig een component en genereert daarna een waarde uit die distributie. Dit laat toe om complexere en multimodale verdelingen te modelleren.
! Het verschil is dus dat productdistributies onafhankelijkheid veronderstellen, terwijl mixtures juist variatie en heterogeniteit tussen componenten modelleren.
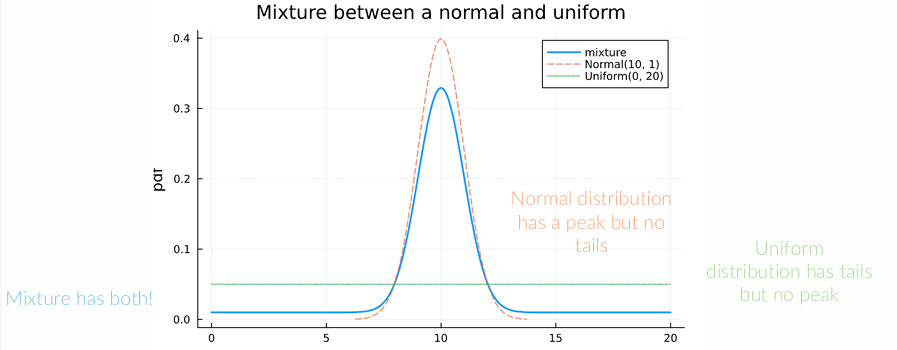
Hoe genereer je een observatie van X wnr je de distributie fX(x) kent en je random nummers in [0, 1] kan genereren?
inverse transform sampling

Leg de Bayesiaanse denkwijze uit om een parameter te schatten. Wat zijn de vier distributies die hier een rol in spelen? Beschrijf ze elk aan de hand van een voorbeeld.
De Bayesiaanse denkwijze vertrekt van het idee dat we onzekerheid over parameters modelleren met kansverdelingen en deze updaten op basis van data. We starten met een prior die onze initiële overtuiging over een parameter weergeeft. Vervolgens gebruiken we de likelihood, die aangeeft hoe waarschijnlijk de geobserveerde data is gegeven een parameterwaarde. Door deze te combineren via de regel van Bayes krijgen we de posterior, die onze geüpdatete overtuiging weergeeft. Ten slotte is er ook de evidence, die dient als normalisatieconstante. Bijvoorbeeld: bij zaadkieming kan de prior een Beta-verdeling zijn voor de kans op kieming, de likelihood een binomiale verdeling van observaties, en de posterior een combinatie van beide die een meer realistische schatting geeft.
Leg het verschil uit tussen MLE en MAP.
Het zijn beide point estimators. Het verschil tussen MLE en MAP is dat MLE enkel de likelihood maximaliseert, terwijl MAP zowel de likelihood als de prior meeneemt. De MLE-schatter kiest de parameterwaarde die de data het meest waarschijnlijk maakt. De MAP-schatter zoekt de parameter die het product van likelihood en prior maximaliseert. Daardoor ligt de MAP vaak tussen de prior en de MLE in. Dit maakt MAP robuuster wanneer er weinig data is. Alleen de MAP-methode maakt gebruik van a priori-aannames over theta! De MLE-methode gebruikt alleen de gegevens!
Wat is een prior distributie? Geef een voorbeeld
Een prior distributie is een kansverdeling die onze kennis of overtuiging over een parameter beschrijft vóórdat we data observeren. Deze kan gebaseerd zijn op eerdere experimenten of domeinkennis. Bijvoorbeeld, bij kiemkansen kan men een Beta-verdeling gebruiken met een piek rond een verwachte waarde. De prior beïnvloedt de posterior, vooral wanneer er weinig data beschikbaar is. Het is dus een essentieel onderdeel van Bayesiaanse inferentie.
Leg het verschil uit tussen een informatieve, zwak informatie en niet-informatieve/diffuse prior.
Een informatieve prior bevat sterke voorkennis en duwt de posterior richting bepaalde waarden, mogelijk bais.
Een zwak informatieve prior bevat beperkte kennis en laat de data meer invloed hebben, minder bais.
Een niet-informatieve of diffuse prior bevat vrijwel geen voorkennis en is vaak uniform, data-gedreven. Het verschil zit dus in hoeveel invloed de prior heeft op de uiteindelijke schatting. In de praktijk vervaagt de impact van de prior wanneer de dataset groot wordt.
Bespreek voor een gegeven probleem of een Bayesiaanse aanpak aangewezen is of niet.
Een Bayesiaanse aanpak is aangewezen wanneer er onzekerheid is over parameters en wanneer men voorkennis wil integreren. Het is vooral nuttig bij kleine datasets, waar de prior helpt om stabielere schattingen te verkrijgen. Ook wanneer men volledige distributies wil kennen in plaats van puntschattingen, is Bayesiaanse inferentie nuttig. Het nadeel is dat het computationeel zwaar kan zijn. Voor eenvoudige problemen met veel data kan een klassieke methode volstaan.
In Bayesiaanse statistiek werken we vaak met ongenormalizeerde distributies. Waarom? Wat is de interpretatie van de normalizatie cte?
In Bayesiaanse statistiek werken we vaak met ongenormaliseerde distributies omdat de normalisatieconstante moeilijk te berekenen is. Deze constante vereist integratie over alle mogelijke parameterwaarden, wat vaak niet haalbaar is. Daarom werken we met proportionele relaties zoals P(θ∣D)∝P(D∣θ)P(θ). De normalisatieconstante zorgt ervoor dat de totale kans 1 is. In samplingmethodes is deze constante vaak niet nodig.
Leg uit hoe rejection sampling werkt aan de hand van een schets. Waarom schaalt dit niet naar hoog-dimensionele problemen?
Bij afwijzingssteekproeven gebruiken we een voorstelverdeling q(x) (waaruit gemakkelijk steekproeven kunnen worden getrokken) om steekproeven te genereren uit de (niet-genormaliseerde) doelverdeling
: p(x) = 1/Z*~p(x)
Deze voorstelverdeling is:
• Gemakkelijk om steekproeven uit te trekken (normaal, uniform…)
• Kan de doelverdeling omvatten (na herschaling): Mq(x) >= ~p(x)
Algoritme voor afwijzingssteekproeven:
1. Genereer een steekproef uit de voorstelverdeling x ~ q(x)
2. Bereken de acceptatiekans: alfa = ~p(x) / Mq(x)
3. Genereer een uniform getal in [0,1]: u ~ Unif(0,1)
• Als u ≤ α, accepteer dan x als een steekproef van p(x)
• Als u > α, verwerp dan x als een steekproef van p(x)
P(steekproef accepteren) = Z/M (maakt het mogelijk de normalisatieconstante te schatten!)
Rejection sampling werkt door een eenvoudige proposal distributie te gebruiken die boven de target distributie ligt. Men genereert een sample uit de proposal en accepteert deze met een bepaalde kans. Als het sample niet wordt geaccepteerd, wordt het verworpen. Dit proces herhaalt zich totdat een sample wordt geaccepteerd. In hoge dimensies wordt dit inefficiënt omdat de kans op acceptatie zeer klein wordt.
![<p>Bij afwijzingssteekproeven gebruiken we een voorstelverdeling q(x) (waaruit gemakkelijk steekproeven kunnen worden getrokken) om steekproeven te genereren uit de (niet-genormaliseerde) doelverdeling </p><p>: p(x) = 1/Z*~p(x)</p><p>Deze voorstelverdeling is:</p><p>• Gemakkelijk om steekproeven uit te trekken (normaal, uniform…)</p><p>• Kan de doelverdeling omvatten (na herschaling): Mq(x) >= ~p(x)</p><p>Algoritme voor afwijzingssteekproeven:</p><p>1. Genereer een steekproef uit de voorstelverdeling x ~ q(x)</p><p>2. Bereken de acceptatiekans: alfa = ~p(x) / Mq(x)</p><p>3. Genereer een uniform getal in [0,1]: u ~ Unif(0,1)</p><p>• Als u ≤ α, accepteer dan x als een steekproef van p(x)</p><p>• Als u > α, verwerp dan x als een steekproef van p(x)</p><p>P(steekproef accepteren) = Z/M (maakt het mogelijk de normalisatieconstante te schatten!)</p><p>Rejection sampling werkt door een eenvoudige proposal distributie te gebruiken die boven de target distributie ligt. Men genereert een sample uit de proposal en accepteert deze met een bepaalde kans. Als het sample niet wordt geaccepteerd, wordt het verworpen. Dit proces herhaalt zich totdat een sample wordt geaccepteerd. In hoge dimensies wordt dit inefficiënt omdat de kans op acceptatie zeer klein wordt.</p>](https://assets.knowt.com/user-attachments/6352ef15-cc53-430d-b1f3-7e011fd8f1fd.png)
Leg uit: de mixing time van een Markov chain.
De mixing time van een Markov chain is de tijd die nodig is om de stationaire verdeling te bereiken. In het begin hangt de keten sterk af van de startwaarde. Na verloop van tijd verdwijnt deze afhankelijkheid. Een korte mixing time betekent snelle convergentie. Dit is belangrijk voor efficiënte MCMC sampling.
Wat zijn pseudosamples? Hoe bekom je die en wat is het verschil met gewone samples van een distributie?
Pseudosamples zijn samples uit een MCMC-keten die niet onafhankelijk zijn, maar als er voldoende tijd tussen zit, worden ze ongeveer onafhankelijk en identiek verdeeld. Ze worden verkregen door een Markov chain te simuleren. In tegenstelling tot echte i.i.d. samples, hebben deze samples correlatie met vorige waarden. Hierdoor bevatten ze minder informatie per sample. Daarom spreekt men van een lagere effectieve sample size.
Leg in je eigen woorden het principe van Metropolis-Hastings sampling uit. Welk deel moet je zelf kiezen/ontwerpen voor je probleem?
Metropolis-Hastings sampling werkt door een voorstel te genereren op basis van de huidige toestand. Dit voorstel wordt geaccepteerd of verworpen op basis van een acceptatiekans. Als het wordt geaccepteerd, gaat de keten naar de nieuwe toestand, anders blijft ze waar ze is. Op lange termijn volgt de keten de doelverdeling. Het belangrijkste dat je zelf moet kiezen is de proposal distributie.

Gegeven een grafiek van een distributie, leg uit wrm Metropolis- Hastings sampling al dan niet goed zal werken.
Metropolis-Hastings werkt goed wanneer de distributie niet te complex is en goed benaderd kan worden met lokale stappen. Bij sterk multimodale distributies kan de keten vastzitten in één piek. Ook bij smalle pieken kan de acceptatiekans laag zijn. In zulke gevallen werkt MH minder goed. Een goede proposal distributie is cruciaal.
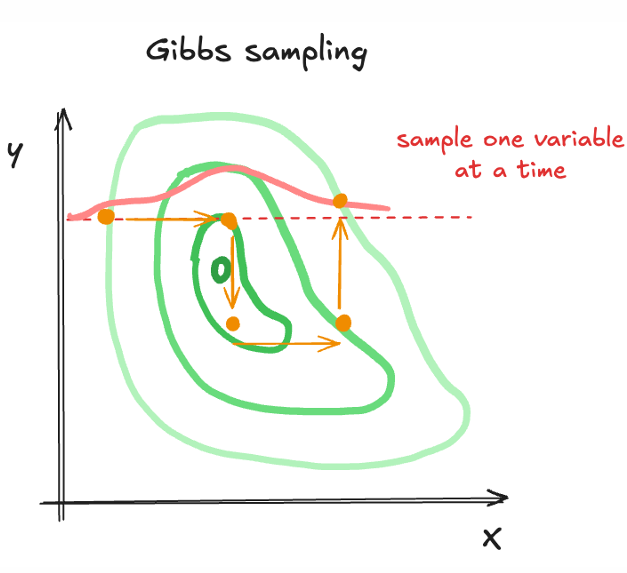
Leg in je eigen woorden Gibbs sampling uit.
Gibbs-sampling is een speciaal geval van de MH-algoritmen, waarbij men telkens één variabele doorloopt terwijl de andere vast blijft. Dit gebeurt cyclisch voor alle variabelen. Elke stap wordt altijd geaccepteerd. Het is eenvoudig te implementeren wanneer conditionele distributies bekend zijn. Het werkt goed bij modellen met duidelijke conditionele structuren.
Wat is er bijzonder aan Hamiltonian Monte Carlo? Hoe verschilt de kwaliteit van de pseudosamples tegenover simpelere MCMC samplers? Wat zijn de nadelen van HMC?
Hamiltonian Monte Carlo (HMC) is een variant van MCMC die gebruikmaakt van Hamiltoniaanse dynamica om efficiënte toestandsveranderingen voor te stellen, waardoor de doelverdeling effectiever kan worden verkend dan met traditionele methoden op basis van de willekeurige wandeling. Hamiltonian Monte Carlo gebruikt gradiënten van de log-distributie om efficiënter door de ruimte te bewegen. In plaats van een random walk maakt het grote, gerichte stappen. Hierdoor zijn de samples minder gecorreleerd en van hogere kwaliteit. Het nadeel is dat het complexer en computationeel zwaarder is. Ook moet men de gradiënt kunnen berekenen.
Wat is de “effective sample size” bij MCMC? Waarom is dit lager dan de lengte van je keten (aantal genomen samples)?
De effective sample size (ESS) is het aantal onafhankelijke samples dat overeenkomt met de MCMC-keten. Omdat samples gecorreleerd zijn, is ESS lager dan het totaal aantal samples. Dit betekent dat niet elke sample volledig nieuwe informatie bevat. Hoe sterker de correlatie, hoe lager de ESS. Daarom is ESS een betere maat voor kwaliteit dan het aantal samples.
Herken/ beschrijf wnr je MCMC zich goed gedraagt gegeven een diagnostische plot.
Een goed werkende MCMC-keten vertoont een trace plot dat lijkt op een “harige rups”. Dit betekent dat de keten rond een stabiel gemiddelde fluctueert zonder trends. Slecht gedrag toont zich in pieken, vlakke stukken of trends. Dit wijst op slechte mixing of convergentieproblemen. Diagnostische plots zijn essentieel om dit te beoordelen.
Wat is een mogelijke oorzaak van een zich slecht-gedragende keten in MCMC? Hoe kan je dit oplossen?
Een slecht-gedragende keten kan veroorzaakt worden door een slecht model of een slechte prior. Ook een slechte keuze van proposal distributie kan problemen geven. De keten kan dan vastlopen of traag bewegen. Dit kan opgelost worden door betere priors toe te voegen of het model te verbeteren. Soms helpt het ook om een ander sampling algoritme te gebruiken.
Hoe maak je van een maximalisatie probleem een minimalisatie probleem?
Een maximalisatieprobleem kan eenvoudig omgezet worden naar een minimalisatieprobleem door de doelfunctie te negateren. Dit betekent dat men in plaats van max f(x) te zoeken, men min f(x) oplost. De oplossing blijft dezelfde, omdat het punt dat f(x) maximaliseert ook het punt is dat −f(x) minimaliseert. Dit is handig omdat veel optimalisatie-algoritmes standaard geformuleerd zijn als minimalisatieproblemen. Op die manier kan men dezelfde algoritmes gebruiken voor beide types problemen. Het is dus een eenvoudige maar krachtige transformatie.
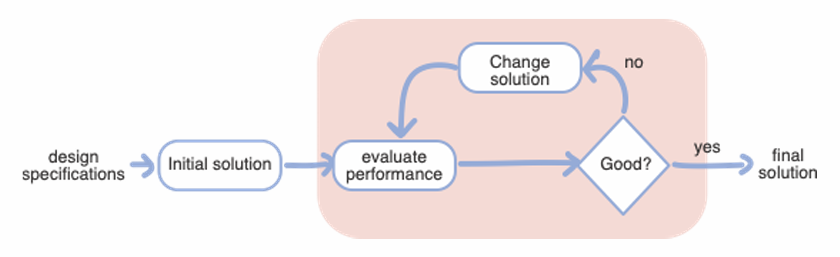
Teken de algemene optimalisatie cyclus uit.
Bespreek het verschil tussen grid search en random search/Monte Carlo optimalisatie? Wat zijn hun respectievelijke voor- en nadelen? Grind search:
Gris search
• Bij het optimaliseren over een interval [a, b] verdeelt de rasterzoekmethode het interval in (gelijkmatig verdeelde) punten, die allemaal worden geëvalueerd.
• Raster met logaritmische tussenafstanden bij toepassing op grote schaal, bijvoorbeeld van 0,001 tot 107
• Rasterzoek over meerdere parameters is mogelijk
• Eenvoudig te implementeren!
Bespreek het verschil tussen grid search en random search/Monte Carlo optimalisatie? Wat zijn hun respectievelijke voor- en nadelen? Random search/Monte Carlo optimalisatie:
Random search (ook bekend als Monte Carlo-optimalisatie)
• Neem waarden uit het interval [a, b], bijvoorbeeld uniform.
• Eenvoudig te implementeren en eenvoudig te parallelliseren
• Kan door toeval gebieden missen (hoge variantie!)
• Gebruik een andere steekproefverdeling als er voorafgaande kennis over de minimizer beschikbaar is
Geef de algemene update regel voor gradiënt gebaseerde optimalisatie methoden en bespreek de delen.
De algemene update-regel voor gradiëntgebaseerde methoden is:
xk+1=xk−η∇f(xk).
Hierbij is xk de huidige oplossing, ∇f(xk) de gradiënt van de functie en η de stapgrootte (learning rate).
→ De gradiënt geeft de richting van de grootste stijging, dus men beweegt in de tegenovergestelde richting om te minimaliseren.
→De stapgrootte bepaalt hoe ver men in die richting gaat. Als deze te groot is, kan men overshooting krijgen; als ze te klein is, convergeert het proces traag. Het correct kiezen van deze parameters is cruciaal voor goede prestaties.
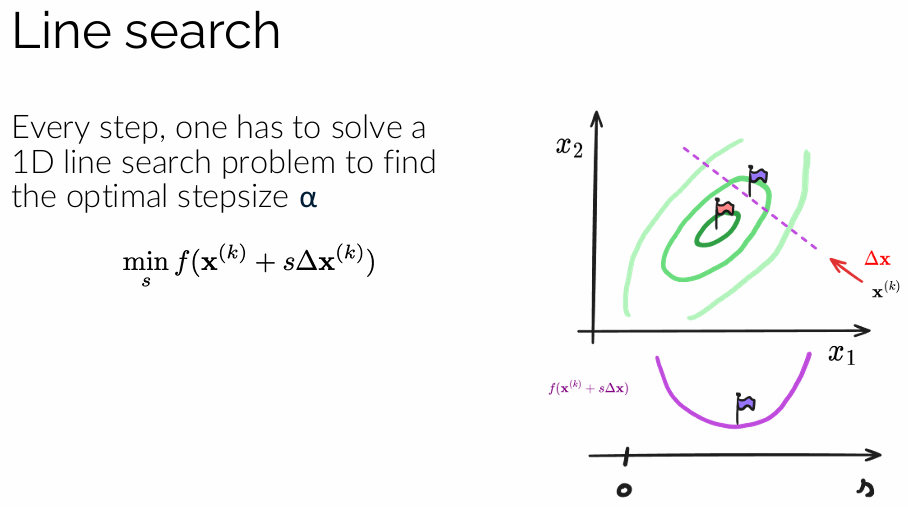
Wat is een “line-search” probleem bij optimalisatie? Schets een grafiek van het probleem.
Een line-search probleem bestaat uit het bepalen van de optimale stapgrootte langs een gegeven richting. Men kiest eerst een richting (bijvoorbeeld de negatieve gradiënt) en zoekt vervolgens hoeveel men langs die richting moet bewegen. Grafisch komt dit neer op het minimaliseren van de functie langs een lijn. Dit kan voorgesteld worden als een snede van de functie in één dimensie. Het probleem is dus het vinden van het minimum van deze ééndimensionale functie. Een slechte keuze van stapgrootte kan leiden tot trage of instabiele convergentie.
Strategieën:
• Exacte (voor sommige functies)
• Benaderende algoritmen
• Afnemende, bijv. αk = 1/(c+k)
• Constante stapgrootte!
Afweging: een betere lijnzoekmethode betekent meer rekenwerk per stap, maar je hebt waarschijnlijk minder stappen nodi
Geef de Newton stap, bespreek de convergentie. Wat is het (computationeel) nadeel van deze methode?
De Newton-stap is gegeven door:
xk+1=xk−H^−1(xk)∇f(xk),
waar H de Hessiaanmatrix is. Deze methode gebruikt zowel de eerste als tweede afgeleiden om sneller naar het optimum te gaan. De convergentie is meestal zeer snel (kwadratisch) wanneer men dicht bij het optimum zit.
Het nadeel is dat het berekenen en inverteren van de Hessiaan computationeel duur is. Vooral in hoge dimensies wordt dit onpraktisch. Daarom wordt deze methode niet altijd gebruikt in grote problemen.
Convergentie in twee regimes:
1. Gedempte Newton-fase: lineaire convergentie, α < 1
2. Zuivere Newton-fase: kwadratische convergentie, α = 1
Leg in één zin uit welk probleem quasi-Newton algoritmes oplossen tegenover de originale Newton methode?
Quasi-Newton methoden proberen de Hessiaanmatrix te benaderen zodat men de Newton-methode kan gebruiken zonder de exacte Hessiaan te moeten berekenen.
Wat zijn direct-search/nulde orde optimalisatiemethoden?
Direct-search of nulde-orde optimalisatiemethoden zijn methoden die geen gebruik maken van afgeleiden. Ze evalueren enkel de functiewaarden om te bepalen waar het minimum ligt. Dit maakt ze geschikt voor problemen waar de gradiënt niet beschikbaar of niet betrouwbaar is. Ze zijn vaak robuust maar minder efficiënt dan gradiëntgebaseerde methoden. Voorbeelden zijn Nelder-Mead en andere simplex-methoden. Ze worden vaak gebruikt bij ruwe of niet-gladde functies. Hun nadeel is dat ze traag kunnen zijn in hoge dimensies.
Bespreek bondig hoe de Nelder-Mead methode werkt en wnr je het wel of niet zou gebruiken.
Het Nelder-Mead-algoritme
• Populaire directe (nulde-orde) optimalisatiemethode.
• Werkt zonder gradiëntinformatie, ideaal voor complexe/onbekende functies.
• Werkt op een “simplex”: een geometrische vorm met n+1 hoekpunten in n dimensies.
• Er wordt een initiële simplex gevormd, waarbij de functiewaarden bij elk hoekpunt worden berekend.
Vier hoofdbewerkingen op de simplex:
• Reflectie: het slechtste punt wordt gespiegeld ten opzichte van het zwaartepunt.
• Uitbreiding: de reflectie wordt uitgebreid om verder te verkennen.
• Inkrimping: de simplex wordt ingekrompen in de richting van het zwaartepunt.
• Inkrimping: de gehele simplex wordt ingekrompen in de richting van het beste punt.
Het slechtste punt wordt altijd vervangen door een potentieel beter punt. De grootte en vorm van de simplex passen zich aan de vorm van de te minimaliseren functie aan.
De Nelder-Mead methode werkt met een simplex, een verzameling van punten in de zoekruimte. Deze simplex wordt iteratief aangepast door operaties zoals reflectie, expansie en contractie. Op basis van de functiewaarden wordt bepaald welke punten behouden blijven. De methode beweegt zo richting lagere functiewaarden zonder gradiënten te gebruiken. Ze is nuttig voor kleine, niet-gladde problemen. Ze werkt echter slecht in hoge dimensies en heeft geen garantie op globale optimaliteit. Daarom moet ze voorzichtig gebruikt worden.
Hoe verschillen populatie-gebaseerde optimalisatiemethoden van andere methoden die hun oplossing iteratief verbeteren?
Op populaties gebaseerde methoden
• Deze methoden werken met een groep (populatie) van mogelijke oplossingen tegelijk, in plaats van met één enkele oplossing.
• Ze maken gebruik van de collectieve intelligentie van de populatie om de zoekruimte te verkennen.
• Vermindert het risico om vast te lopen in lokale optima.
• Gebruikt een zekere mate van willekeur om de zoekruimte te verkennen
• Voorbeelden (vaak bio-geïnspireerd):
• Genetische algoritmen (GA)
• Particle Swarm Optimization (PSO)
• Ant Colony Optimization (ACO)
Populatie-gebaseerde optimalisatiemethoden werken met meerdere oplossingen tegelijk in plaats van één iteratief pad. In plaats van één oplossing te verbeteren, evolueert een hele populatie van kandidaten. Dit maakt het mogelijk om meerdere regio’s van de zoekruimte tegelijk te verkennen. Hierdoor is de kans kleiner dat men vast komt te zitten in lokale minima. Het nadeel is dat ze vaak meer berekeningen vereisen. Ze worden vaak gebruikt voor complexe, niet-convexe problemen.
Geef het idee achter particle-swarm optimization. Geef de drie termen die de beweging van een individu beïnvloeden.
Particle swarm optimization is geïnspireerd door het gedrag van zwermen, zoals vogels of vissen. Elke “particle” stelt een mogelijke oplossing voor en beweegt door de zoekruimte. De beweging wordt beïnvloed door drie termen: de eigen snelheid (inertie), de beste positie die het individu zelf heeft gevonden (cognitieve component) en de beste positie die de groep heeft gevonden (sociale component). Door deze combinatie zoeken de particles gezamenlijk naar een optimum. Dit leidt vaak tot snelle en robuuste optimalisatie. Het is vooral nuttig voor complexe en niet-gladde problemen.

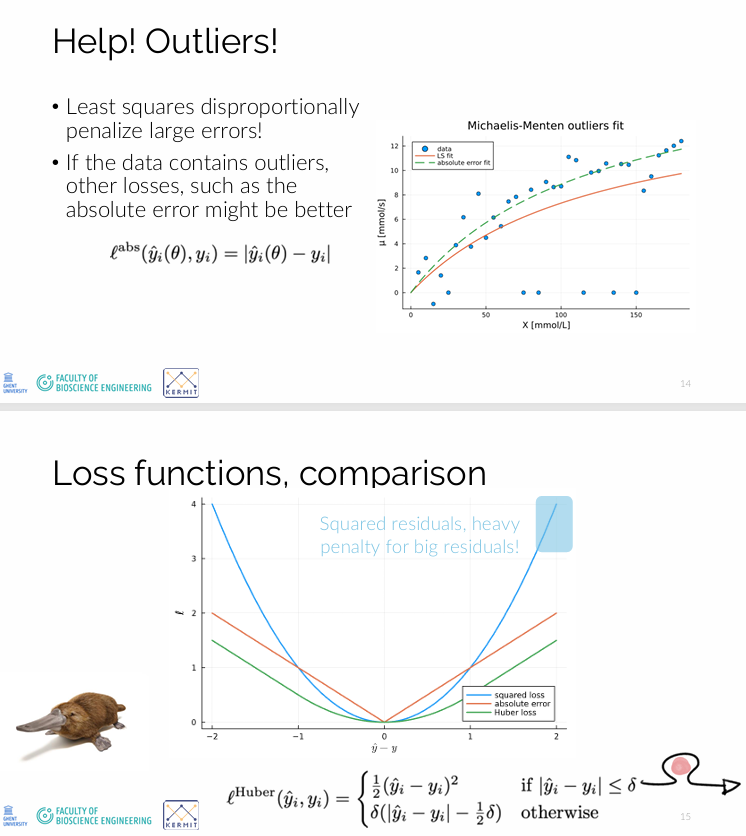
Wnr zou je de absolute error als loss functie gebruiken ipv de kwadratische fout (squared error)?
Je gebruikt de absolute error wanneer de data outliers bevat of wanneer grote fouten niet disproportioneel zwaar mogen doorwegen.
Bij squared error worden grote afwijkingen kwadratisch bestraft, waardoor outliers de fit sterk domineren.
Bij absolute error is de straf lineair, waardoor outliers minder invloed hebben.
→ Dus: absolute error is robuuster tegen grote fouten en volgt beter de “typische” data.
Hoe kan je een loss functie aanpassen om om te gaan met heteroskedasticiteit?
Bij heteroskedasticiteit hebben observaties verschillende varianties. Dit los je op door een gewogen loss functie te gebruiken:
L(θ) = i∑wi ϖ (y^i(θ),yi)
waarbij de gewichten typisch gekozen worden als:
wi∝1/σi²
→ Observaties met kleinere variantie (meer betrouwbare metingen) krijgen meer gewicht.
Geef een reden om wegingsfactoren in je loss functie in te bouwen. Hoe kies je de gewichten?
Reden: niet alle observaties zijn even belangrijk of even betrouwbaar.
Bijvoorbeeld:
verschillende variabelen met andere schalen of meetfouten
sommige regio’s hebben nauwkeurigere metingen
bepaalde outputs zijn belangrijker om correct te modelleren
Keuze van gewichten:
gebaseerd op meetfout/variantie → wi∝1/σi²
of op belang/prioriteit van data
enkel de relatieve grootte van gewichten is belangrijk
Bespreek de verschillen tussen Maximum Likelihood Estimation (MLE), Maximum a posteriori estimation (MAP) en een volledige Bayesiaanse parameterkalibratie. Wat zijn de respectievelijke voor- en nadelen? MLE
MLE (Maximum Likelihood Estimation)
Maximaliseert P(Y∣θ)
Geen priorinformatie
Voordelen: eenvoudig, vaak efficiënt
Nadelen:
kan slecht werken bij ill-posed problemen
geen onzekerheidsinformatie (puntschatting)
Bespreek de verschillen tussen Maximum Likelihood Estimation (MLE), Maximum a posteriori estimation (MAP) en een volledige Bayesiaanse parameterkalibratie. Wat zijn de respectievelijke voor- en nadelen? MAP
MAP (Maximum A Posteriori)
Maximaliseert P(θ∣Y)∝P(Y∣θ)P(θ)
Gebruikt prior + likelihood: P(θ| Y=y)∝P(Y=y|θ)P(θ),
Voordelen:
stabiliseert problemen (regularisatie via prior)
nog steeds relatief→eenvoudig (optimalisatie)
Nadelen:
nog steeds slechts één punt (modus)
afhankelijk van gekozen prior
Bespreek de verschillen tussen Maximum Likelihood Estimation (MLE), Maximum a posteriori estimation (MAP) en een volledige Bayesiaanse parameterkalibratie. Wat zijn de respectievelijke voor- en nadelen? Bayesiaanse
Volledig Bayesiaans
Berekent de volledige posterior distributie P(θ∣Y) (bv. via MCMC)
Voordelen:
volledige onzekerheidsanalyse
inzicht in afhankelijkheden tussen parameters
credible intervals, probabilistische uitspraken
Nadelen:
computationeel duur
complexer
→ Samengevat:
MLE = snel, geen prior
MAP = MLE + regularisatie via prior
Bayesiaans = volledig probabilistisch beeld (maar duur)
Wat houdt “regularisatie” in bij parameterkalibratie? Hoe wordt dit gedaan in het Bayesiaanse geval?
Regularisatie = extra term toevoegen om oplossingen te stabiliseren en ill-posed problemen beter te maken (bv. parameters klein houden).
Voorbeeld (Tikhonov):
(A^TA+λI)^(−1)*A^Ty
→ beperkt de grootte van parameters.
In Bayesiaanse context:
regularisatie komt automatisch via de prior P(θ)
bv. een normale prior θ∼N(0,λ^(−1)I) leidt tot:
logP(θ)∝−λ∥θ∥²
→ dit is equivalent aan L2-regularisatie
Dus:
klassiek: expliciete penalty term
Bayesiaans: impliciet via prior distributie
→ Regularisatie helpt om een ill-posed probleem well-posed te maken.
Geef wiskundig en intuïtief wat de Fisher informatie zegt over een loss functie (eventueel met een schets). Waarvoor wordt dit gebruikt bij parameterkalibratie?
Intuïtief:
Het meet hoe “scherp” of “vlak” het minimum van de loss functie is.
Grote kromming (steile vallei) → kleine veranderingen in θ\thetaθ geven grote toename in loss → parameter goed bepaald (lage onzekerheid)
Kleine kromming (vlakke vallei) → veel waarden geven bijna dezelfde loss → hoge onzekerheid
Gebruik bij parameterkalibratie:
Schatting van de variantie / onzekerheid van parameters:
Var(θ hoedje)≈I(θ hoedje)^(−1)
Dus standaardfout:
SE(θ hoedje)≈I(θ hoedje)^(−1/2)
In meerdere dimensies: inverse Hessiaan = covariantiematrix
→ Wordt gebruikt voor confidence intervals, z-scores, statistische tests

Waarvoor gebruik je een Laplace benadering bij parameterkalibratie? Leg uit hoe het werkt.
Waarvoor:
Om een posterior distributie te benaderen wanneer exacte berekening of sampling (MCMC) te duur is
Geeft een snelle schatting van onzekerheid rond MLE of MAP
Alternatief voor volledige Bayesiaanse sampling
Waarvoor gebruik je een Laplace benadering bij parameterkalibratie? Leg uit hoe het werkt.
Hoe werkt het:
Neem de (log-)posterior logf(θ)\log f(\theta)logf(θ)
Zoek het maximum (MAP): θ^\hat{\theta}θ^
Maak een tweede-orde Taylor benadering rond θ^\hat{\theta}θ^
Dit resulteert in een kwadratische vorm → komt overeen met een normale verdeling
→ Resultaat:
Posterior ≈ normaal verdeeld rond θ^\hat{\theta}θ^
Covariantie bepaald door de kromming (Fisher informatie)
Intuïtief:
Je vervangt een complexe verdeling door een “beste lokale parabool”, en die komt overeen met een Gaussische klokvorm rond de top.
Gegeven een ongenormaliseerde posterior distributie, geef de lokale normale benadering a.d.h.v. de Laplace benadering.
