Lecture 2 - Perception
1/76
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced |
|---|
No study sessions yet.
77 Terms
Define perception.
The study of how the external world gets represented in our brain/mind so that we can understand and act upon what’s going on around us.
ie. getting the physical things from the world into our mind
Define agnosia.
A deficit in recognition despite the fact that normal vision is still completely fine.
How do patients with agnosia help us understand the processing required for vision?
Since people with agnosia still have working vision, it tells us that there are a lot more processes required for us to recognise things/make sense of visual stimuli in the world.
Define apperceptive agnosia.
People who are unable to name, match or distinguish visually presented objects (ie. their brain can’t form a complete percept from the visual pattern).
Can people with apperceptive agnosia copy things down?
Not really.
People with apperceptive agnosia cannot combine visual information into a complete visual percept of an object. Hence, they show deficits when it comes to copying down things because their brain just can’t make sense of what they are seeing.
The image is an example of how they tend to see things.

Define associative agnosia.
People who cannot associate a visual pattern with its meaning (ie. they cannot recognise what they see).
Can people with associative agnosia copy things down?
Yes.
People with associative agnosia can create a visual percept of the object they are seeing. Hence, they are able to copy it down when they see it. However, the problem lies where they are unable to link the percept they form to its stored meaning.
Therefore, the person can copy the object down but will not understand what it is (they just guess the meaning).

What is the difference between apperceptive agnosia and associative agnosia?
Apperceptive Agnosia:
cannot copy things down
cannot form a visual percept of an object
can understand what something is because they have no issues linking an object to its stored meaning in their mind once they can distinguish what they see (ie. red, round, stem at the top = apple)
Associative Agnosia:
can copy things down
can form a visual percept of an object
cannot understand what something is because they have a problem linking an object to their memory of its meaning (ie. red, round, stem at the top = orange? they have to guess)
Is associative agnosia for people too?
No.
What are the steps to visual perception?
input/sensation
basic visual component assembly
a connection between the meaning of the visual input is made
What step are people with apperceptive agnosia missing?
They are missing step 2 so no basic visual component assembly occurs.
What step are people with associative agnosia missing?
They are missing step 3 so no connection between the meaning of the visual input is made.
Explain the experience error.
It is the false assumption that the world is exactly how we see it. This is because our sense of reality is filtered through our perception system, meaning we don’t always perceive everything that is happening in the world.
What is a real-life example that illustrates the experience error? Why?
Visual Illusions.
This is because although the visual stimulus does not change, if we change the way we view the stimulus, all of a sudden our perception of it can change.
When we look around, we think that we see a continuous image, but what are our eyes really going through (what’s the name of it)?
Fixation-saccade cycles.
Explain fixation-saccade cycles.
When we are looking at something, our eyes go through a series of cycles in order to give us a continuous image on what’s going on in the world.
Saccade
this occurs when our eyes hop from one place to another (hence, from an outside pov our eyes are moving in a jerking motion)
Smooth Pursuit
this is when our eyes are looking at something that is moving (hence, from an outside pov our eyes are moving slowly and smoothly)
Fixation
this happens when we are looking at something that is not moving (hence, our eyes are still)
Do we receive visual input during a saccade?
No.
When we are scanning a room bit by bit (ie. white board to the chair to the table etc…) we do not receive additional visual input other than the thing we are looking at. This is because, if that didn’t happen we would see a blur of things happening (like when you move your camera around and it creates a swoosh).
How come we don’t see a swoosh during a saccade when we move our eyes from one point to another?
This is an example of the experience error occurring as we are filling in the blanks of what don’t take in with a memory of what we saw before.
Hence, clearly we don’t see everything in the world as it is, we filter accordingly so that we can make sense of it in our minds.
When do we receive conscious visual input?
During fixation.
What are the 3 approaches to studying perception?
Computational approach
Gestalt approach
perception/action approach
Define the computational approach.
It is the approach that is concerned about discovering how the brain represents and interprets a distal stimulus.
(ie. how the brain processes information from a distal stimulus)
Define distal stimulus.
The physical stimulus in the environment that we don’t have access to.
Define the gestalt approach.
It’s about using organisational principles to create a meaningful perception of the environment.
Define the perception/action approach.
It assumes that the goals of our actions help determine our perception of the environment.
What are the goals of each approach to studying perception?
Computational approach
recognition
Gestalt approach
action
Perception/action approach
action
Define proximal stimulus.
What we do have access to in the environment (representation). But this is only the sensation, this does not include the understanding portion.
Define bottom-up processing.
When we recognise patterns by analysing sensory input step-by-step.
Define top-down processing.
When our perception of a stimulus is influenced by our prior knowledge, memories and experiences.
How does top-down processing affect bottom-up processing?
Top-down processing can speed up bottom-up processing.
Explain template theory.
The idea that we have a mental ‘stencil’ for a variety of different patterns that we may see in the world.
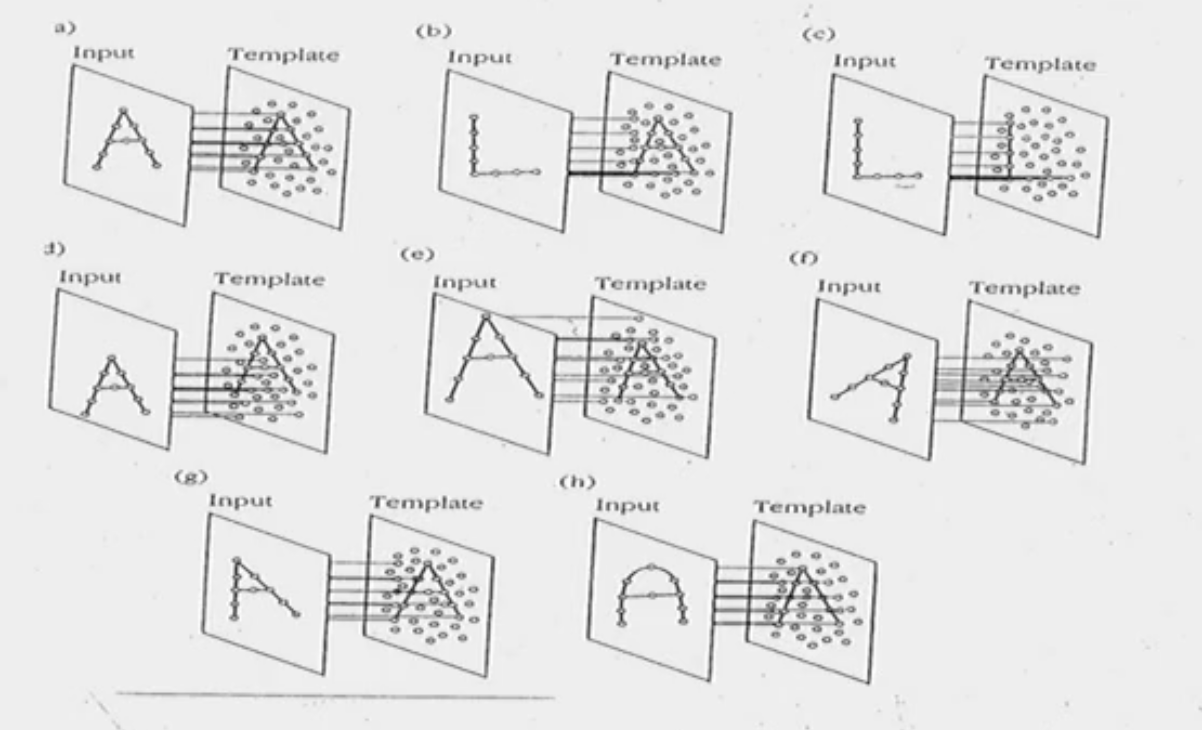
Why is template theory not a good explanation of our cognitive process?
Because there is no way we could have a template for every single thing in the world (ie. so many different fonts in the world but yet we can still read the different letters).
How is template theory helpful then?
We can use template theory in order to match for common visual features in a stimuli (ie. the long vertical line and 2 separate lines in the letter “k” regardless of the font).
Explain feature matching.
The internal system we use to analyse each distinct feature of a visual system.
What is a distinct feature?
A cue used to identify its corresponding concept.
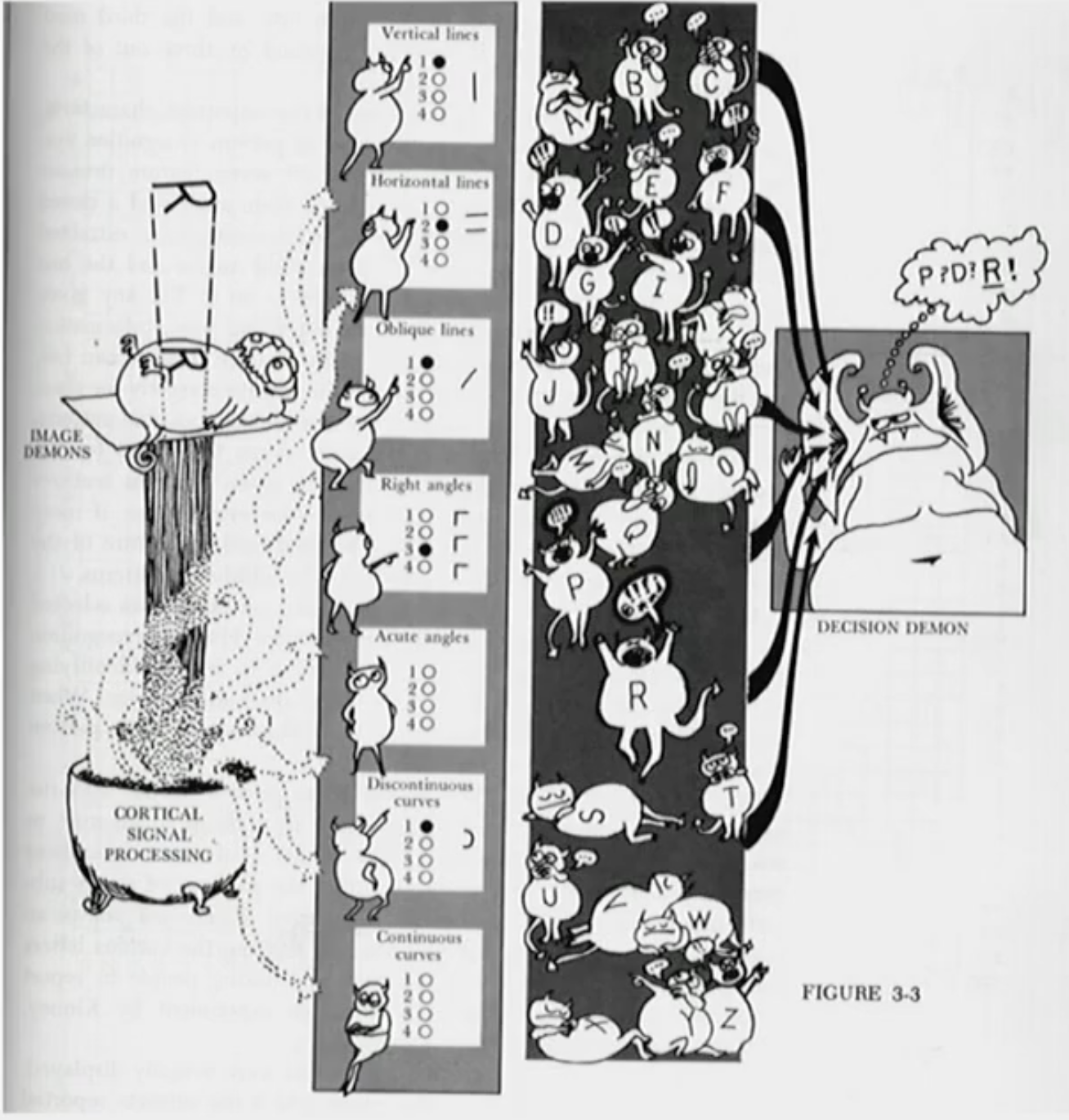
Explain the Pandemonium Model by Selfridge, 1959.
Receive and Break Down
Little devils receive distal stimuli from the environment and look through a series of features in order to identify distinct features
Put Together
Little demons in another area will then shout in relation to the different distinct features which are being pinged. The more features that the Little demon has in relation to what is being pinged, the louder they will shout
Recognition
A big decision demon will then be listening to each shout and pick the one that is being shouted the loudest.
Mirroring
An image demon will then project the image of the thing the decision demon picked
Define serial processing.
A bottom-up process where the process is happening through a number of steps.
Define parallel processing.
A process where everything is being done at the same time.
ie. in Pandemonium the demons were all working at the same time
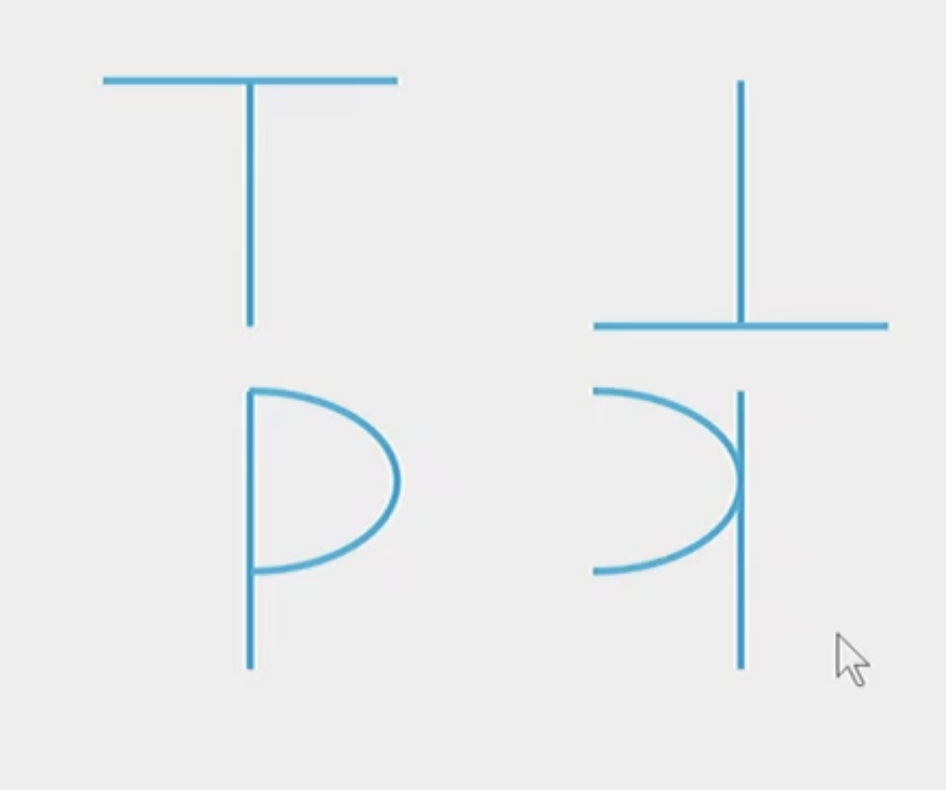
What are some limitations of the feature matching theory?
Configuration
It doesn’t tell you how to put the features together. So if it’s put in a different configuration, you won’t know how to understand it even though technically the features are all there
2D
it only feature matches for things that are 2D, but most of the things we see in the real world are 3D
Is there physiological evidence for feature matching?
Yes.
There are feature detector neurons (ie. cells) in our primary visual cortex.
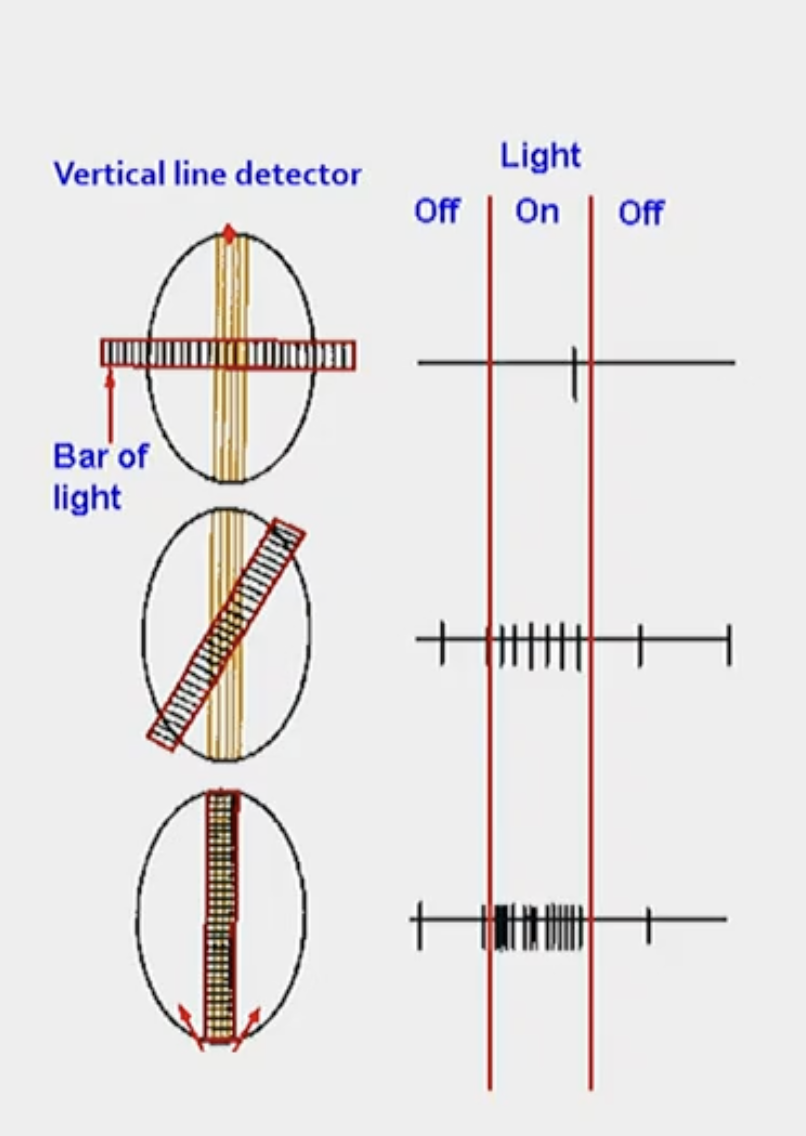
How do feature detector neurons work (super simple model)?
Legend
The oval is a feature detector neuron
Inside the oval there is a vertical line detector (used to detect for a vertical line)
The bar of light is the stimulus
On the right is a representation of action potentials
As you can see, when the bar of light is perpendicular to the vertical line detector in the feature detector neuron, there is nothing showing up on the action potential
As the bar of light moves though, the cell starts to respond more and things start to pop up on the action potential
Once the bar of light is a vertical bar of light, the cell responds maximally (because the vertical line detector in the feature detecting neuron detected a vertical line)
Why did Biederman create Biederman’s Recognition by Components theory?
Because he knew that the feature matching theory didn’t account for 3D objects. So he felt that this theory was describing how human vision works
He also knew that human vision is viewpoint invariant but computers were not. So he also wanted to address the problem that computer engineers were facing
Explain Biederman’s Recognition by Components.
It is a 3D feature matching theory.
Biederman believed that all objects were a combination of 3D objects called “Geons.” Therefore, he thought that in order to understand the 3D world we needed to break the input down into separate Geons. Then, we could re-organise the Geons into wholes and recognise what you were looking at from there.
So same idea as the Pandemonium but for 3D stuff now.
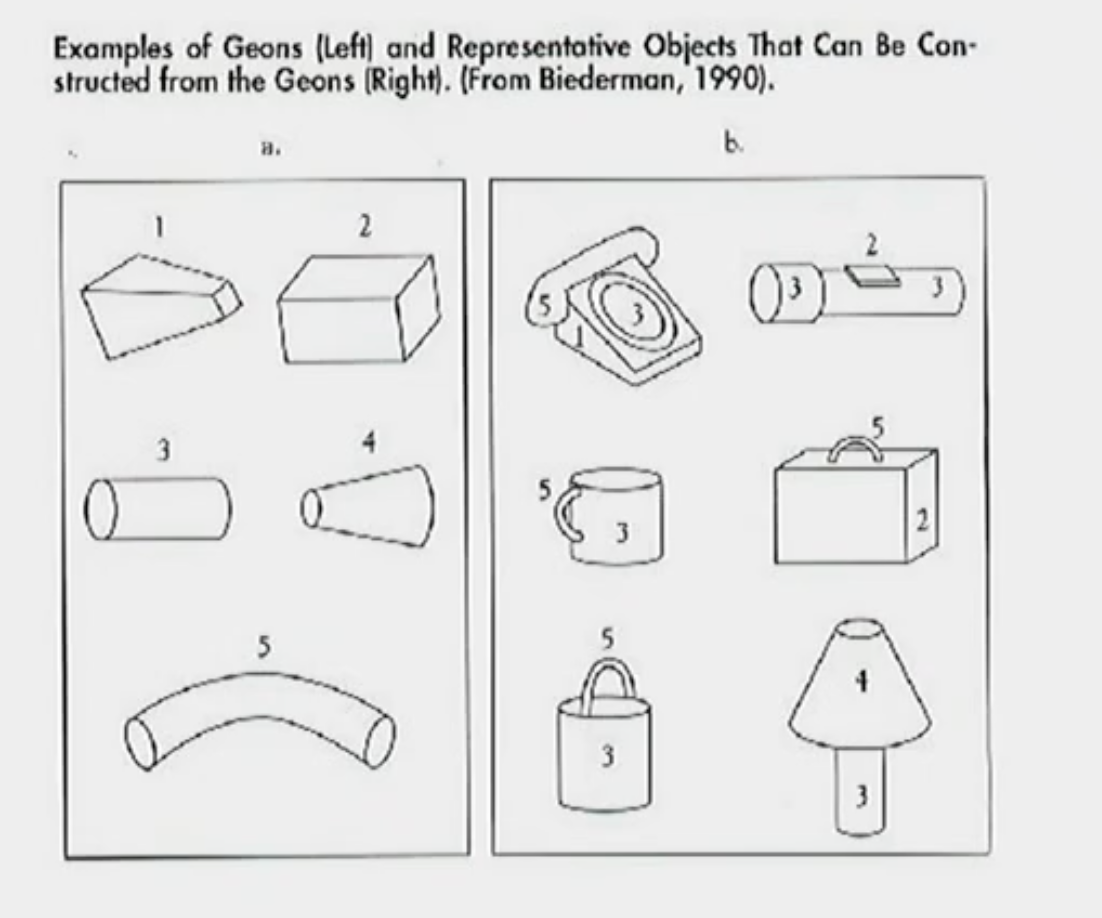
Define viewpoint invariant.
When you can recognise something from any angle.
How did Biederman explain how human vision worked? How did he think this would help computers?
This is because he felt that as long as you could recognise the part from any angle, you can also recognise the whole (which is a combo of all the parts) from any angle.
Therefore, he felt that this same principle could be applied to computers.
Were Geons viewpoint invariant? Why?
This is because they have non-accidental properties. Meaning, they are properties that belong to the object and are not just perceived due to seeing it from a specific viewing angle.
Hence, Biederman felt that as long as you can see those non-accidental viewing properties on a Geon, you will always be able to recognise an object.
What is an example of a non-accidental property?
The parallel lines on your phone, you can always see it regardless of the angle you look at the phone from.
What type of processing is Biedermans Recognition by Components theory?
Serial processing.
Define non-canonical vewipoint.
When we look at something from an unusual angle and can’t see the Geons. Then, we have a harder time, or cannot, recognise the object.

Was Biedermans Recognition by Components theory helpful?
Yes!
Allowed for lots of advances, but then hit a wall till AI recently.
What does recent information about human vision tell us about our viewpoints?
Evidence from psychology and physiology does nto support the idea that we use a viewpoint invariant approach to identify objects.
Instead, humans have a viewer centred bias.
Are there cells in our visual system that respond to specific viewpoints of things?
Yes, they are called cortical neurons.
What are the arguments against bottom-up processing?
Analysing each feature one step at a time takes a LONG time (#tedious)
Theories that rely on features to identify objects cannot distinguish things with the same features
Recognising patterns often relies on top-down processing

What’s an example of top-down processing?
In the image it looks as though the middle parts are indented into the image and the other ones are poking out. This is just a visual illusion as this is a 2D image.
However, we are using a ‘light from above’ heuristic to perceive depth and so, in our minds, it looks like those circles have depth when they really don’t.

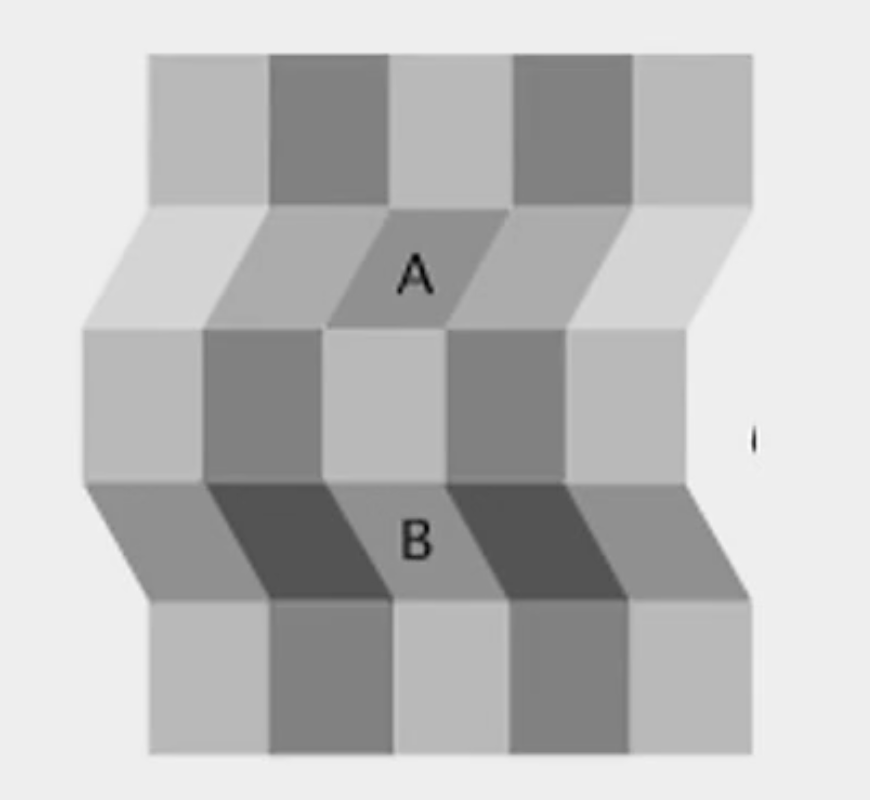
What is another example of top-down processing?
In the image, when the middle section is poking out, it looks as though A and B are a different shade of grey. This is because we are using the ‘light from above’ heuristic which is making us think we are seeing depth and a shadow. Hence, we used our knowledge of depth and shadows in the real world to understand what’s happening in the image (top-down processing).
Contrastingly, when you push the middle section into the page, it looks like A and B are the same shade of grey. Therefore, even when the stimuli didn’t change, our perception of the image was still able to change simply by altering our ‘light from above’ heuristic. Hence, we used our understanding of shadows and depth again in order to make sense of the image, and this time, it changed our perspective (which are examples of both top-down processing and experience error).
Explain gestalt psychology.
It is concerned with how perception gets organised into meaningful units (ie. the whole is different than the sum of its parts).
In the image you will see a jumble of shapes, but when you re-arrange you’ll notice its a …. bicycle.

What was Gestalt interested in?
He talked about the techniques we use to put individual components of a stimulus together.
These rules are used to predict what will be perceived based on one law at a time (it’s tough to predict what the outcome will be when we use multiple laws at the same time).
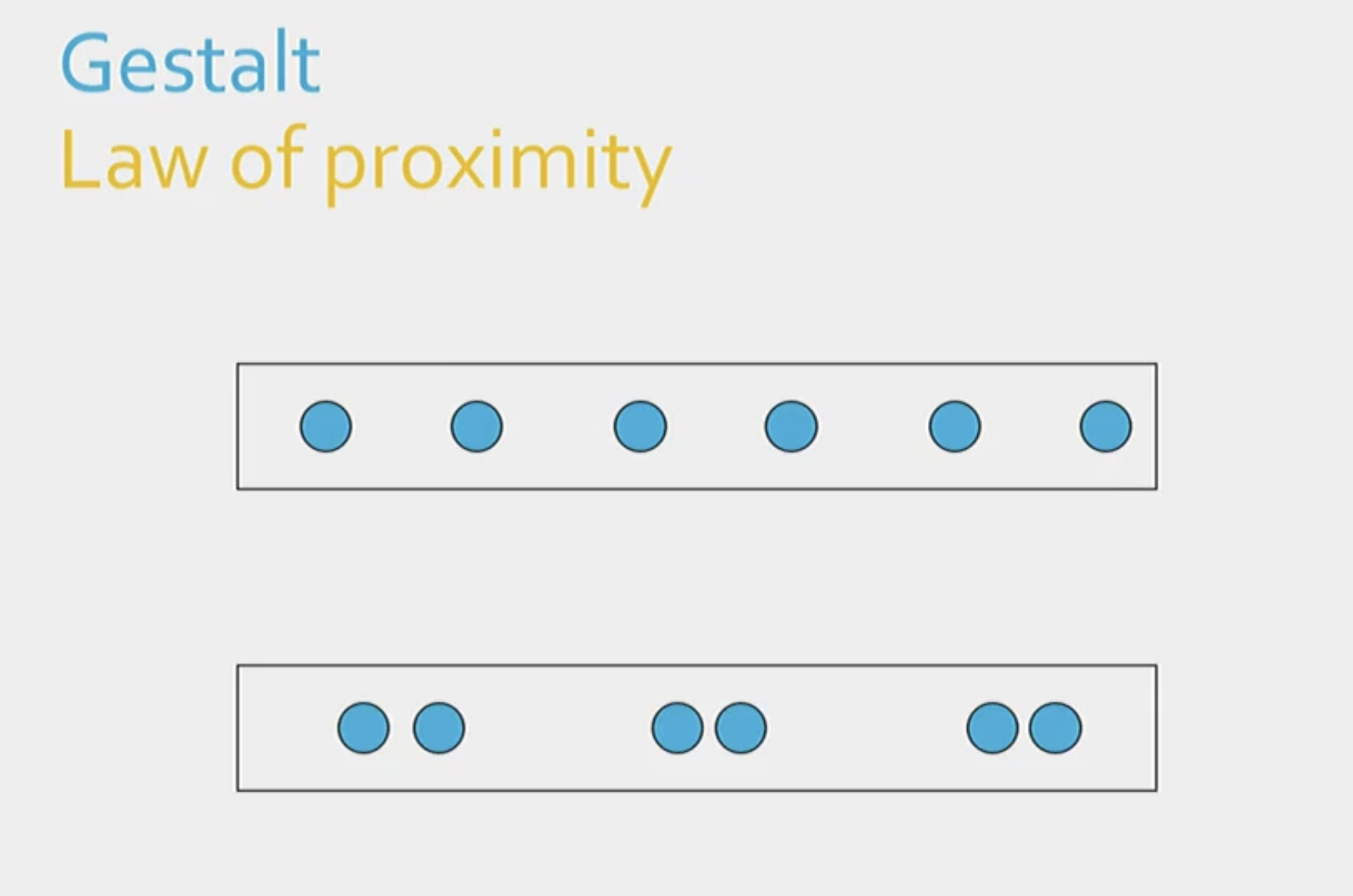
Define the law of proximity.
The tendency to group features of the image that are close together.
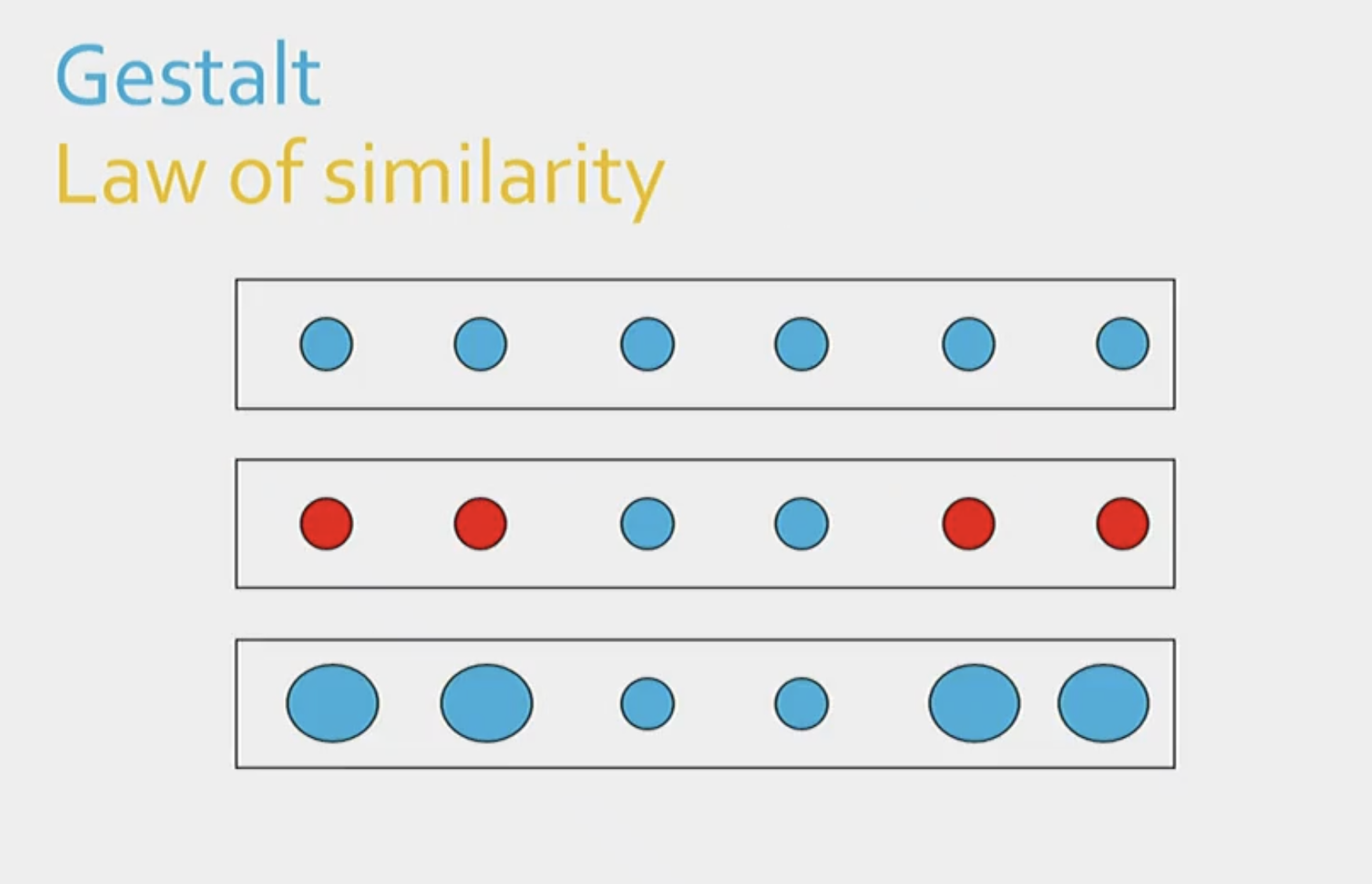
Define the law of similarity.
The tendency to group together features of the image that have similar properties in some dimension, such as color or luminance.
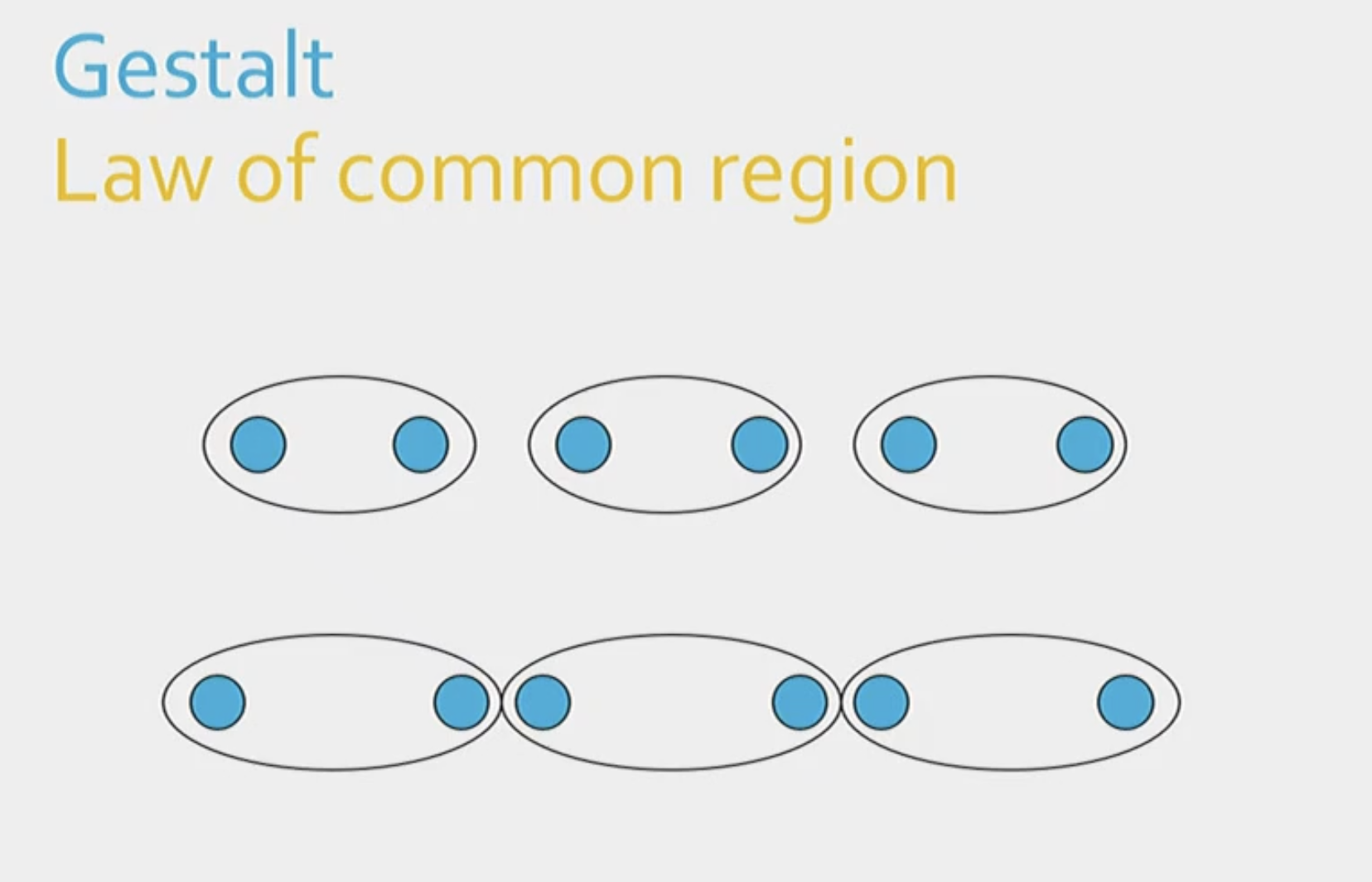
Define the law of common region.
The tendency to group things if they are enclosed within a shared, closed boundary, such as a border or background colour.
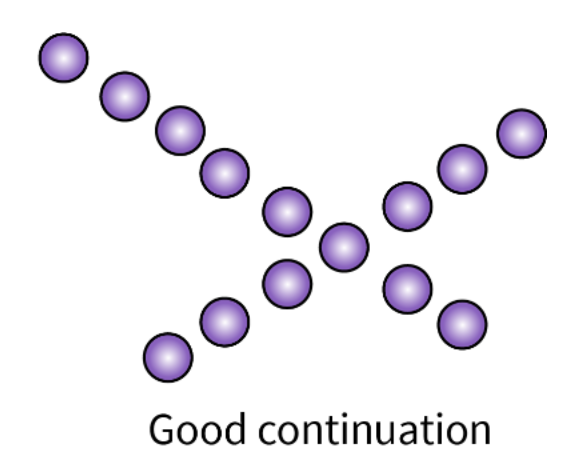
Define the law of good continuation.
The tendency to group together features that form a smooth, continuous path rather than those with a sharp discontinuity.
In the image, the tendency is to see the image made up of two straight, overlapping lines rather than, say, two "V" shapes (one upside down) connected at the vertex.
Explain Gestalts role of experience.
This theory can use both top-down processing and bottom-up processing or just bottom-up processing.
For example, in the image if you’ve seen something like it before you can draw from your past experience and figure out what the image is. Hence, using bottom-up processing to first analyse the picture and see if its familiar. Then, use top-down processing to quickly identify it rather than continue to use the bottom-up step by step process.
In contrast, if you’ve never seen the image you can use bottom-up processing to analyse step by step and slowly figure it out.

Explain the perception/action approach.
It is considered to be an embodied cognition approach from Gibson’s “direct perception” approach. Basically meaning that the environment contains all the information we need for perception.
Hence, in lab experiments when 2D images are used in an artificial environment, we are studying “indirect perception” which he felt was ‘wrong’ and unnatural as it lacked the necessary components from our real environment.
What is an example of the perception/action approach?
“This is not a pipe”
Gibson talks about how using artificial environments is us just studying representations of the real thing rather than the real thing itself. Hence, Gibson argues that that’s not a true test of perception.

Explain Gibson’s ambient optic array theory.
When structures get in the way of light in an environment and thus give us all the information we need for perception.
To explain, light can travel in a straight line forever and so the structures in our environment ‘get in the way’ of it from going straight forever. However, in them getting in the way, they get illuminated and highlighted in our natural environment, giving us all the information we need in order to perceive it.
However, looking at stuff from one angle is not enough. Hence, Gibson said that we needed to compare our ambient optic array from different locations and then combine them to create one whole percept. This was called optic flow.
Define optic flow.
The change in our ambient optic array from moment to moment.
In Gibson’s perspective, what did optic flow show us? And how was that useful for perception?
If there is optic flow in the optic array, then the observer is in motion
The direction of the optic flow indicates the direction the observer is moving
Gibson felt that this was all we needed to know for perception. He felt that no further computation was required, just those 2 things.
The change in your optic array as you spin around.
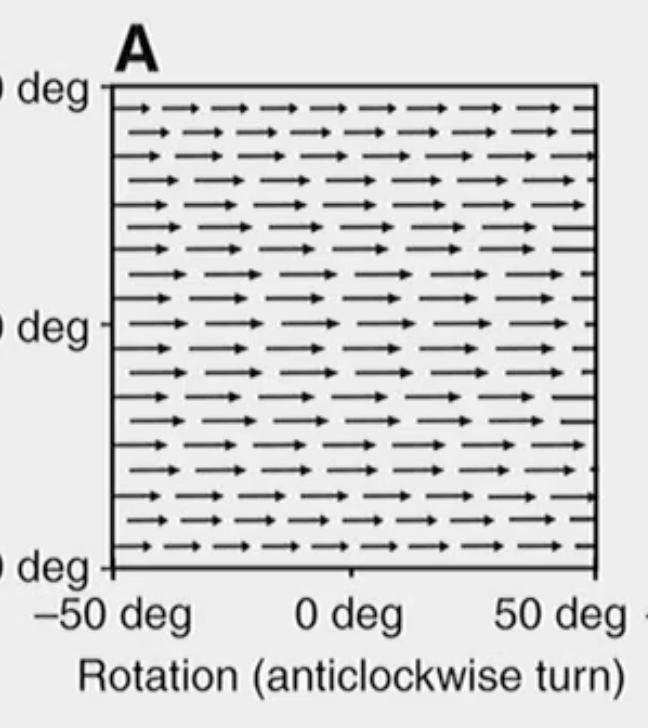
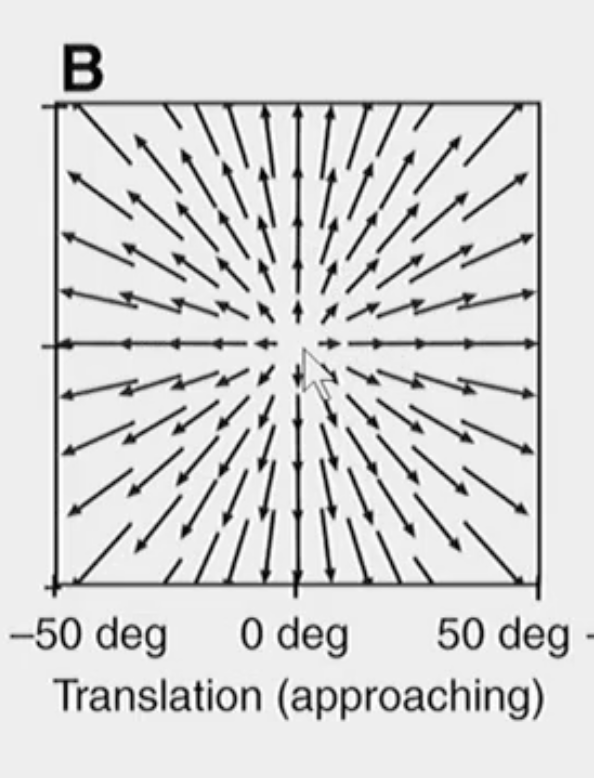
The change in your optic array as you are walking straight.
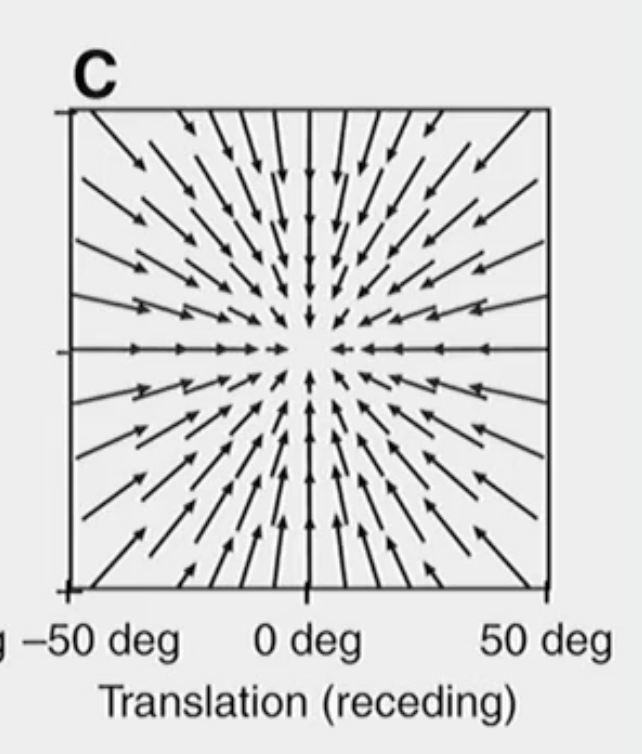
The change in your optic array as you walk backwards.
Explain object affordances.
Gibson felt that the goal of perception was to give the perceiver information about an objects’ affordance for them.
ie. by viewing the world I can see that a chair is in front of me and through my perception of it, I can figure out whether it will be able to hold my weight and whether I can sit on it easily enough.
Hence, Gibson’s direct approach was very extreme in the sense that it was just about visual input mixed in with your understanding of yourself and your environment in order to act appropriately. He didn’t feel that other cognitive processed were needed (ie. memory via top down processing, proximal stimulus).
What do most researchers think about the connection between perception and action?
Most researchers think both action and representations are involved in perception. However, they think that action influences how we perceive the world.
Explain the Ebbinghaus Illusion and how it illustrates the difficulties in reconciling the connection between perception and action.
Let’s pretend the orange circles are balls. The left orange circle looks smaller than the one on the right, but actually they’re the same size. Nonetheless, scientists found that even though the balls don’t look the same in size in people’s percept, people used the exact same hand movement to pick up both balls. This indicates the independence in perception and action.
Now, let’s pretend that the orange circles are golf holes. The perceived bigger golf hole is where people actually got more goals (even though they’re actually the exact same size). Therefore, this indicates the connection between perception and action.
Evidently, this example shows the difficulty in understanding whether perception and action are connected or not.
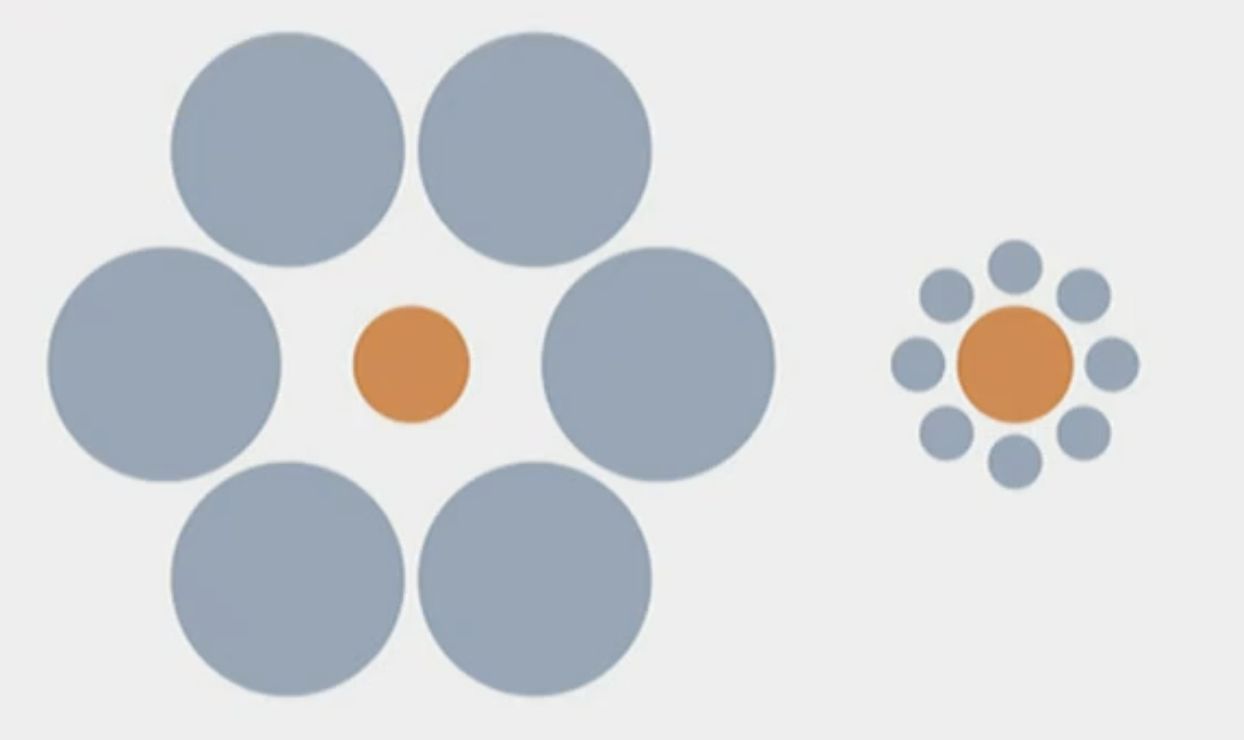
Explain, from a cognitive neuroscience perspective, the difficulties in reconciling the connection between perception and action.
It has been known for 40 years that perception and action are processed independently.
Visual input is processed ventrally through the temporal lobe to process object identity (‘what’ pathway). Visual information is also sent dorsally through the parietal lob (‘where/how’ pathway).
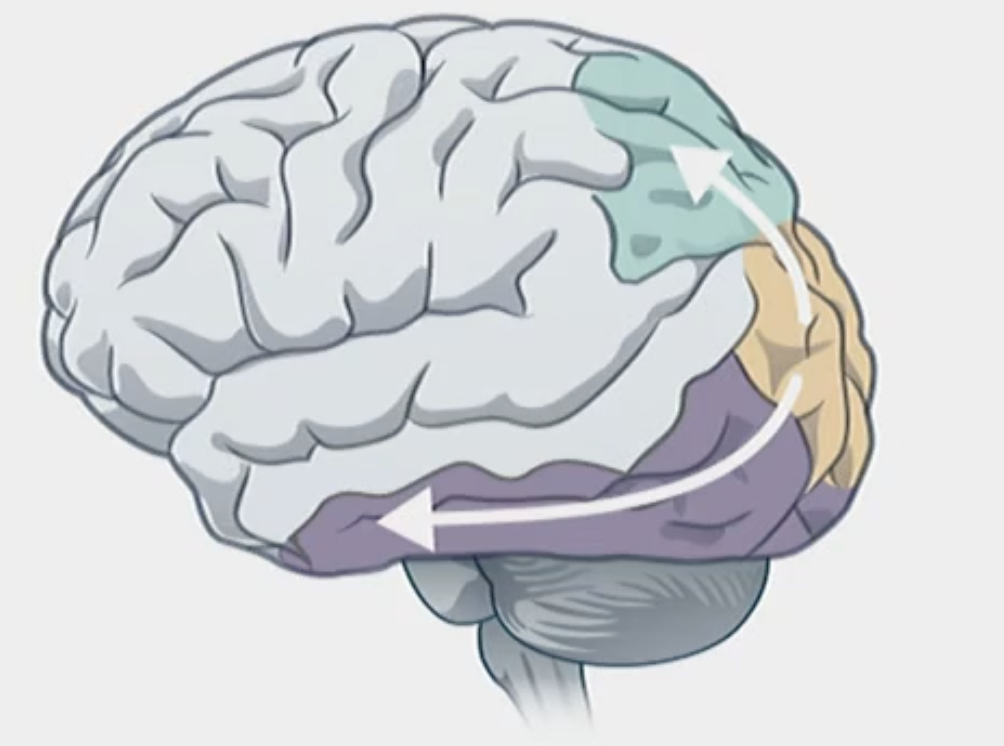
How do different areas of our brain activate for the perception of faces, places and objects.
Here is a ventral view of the temporal lobe:
Fusiform face area, FFA - active when viewing faces (visually processing area)
Parahippocampal place area, PPA - active when looking at places
LO - active when viewing human made objects
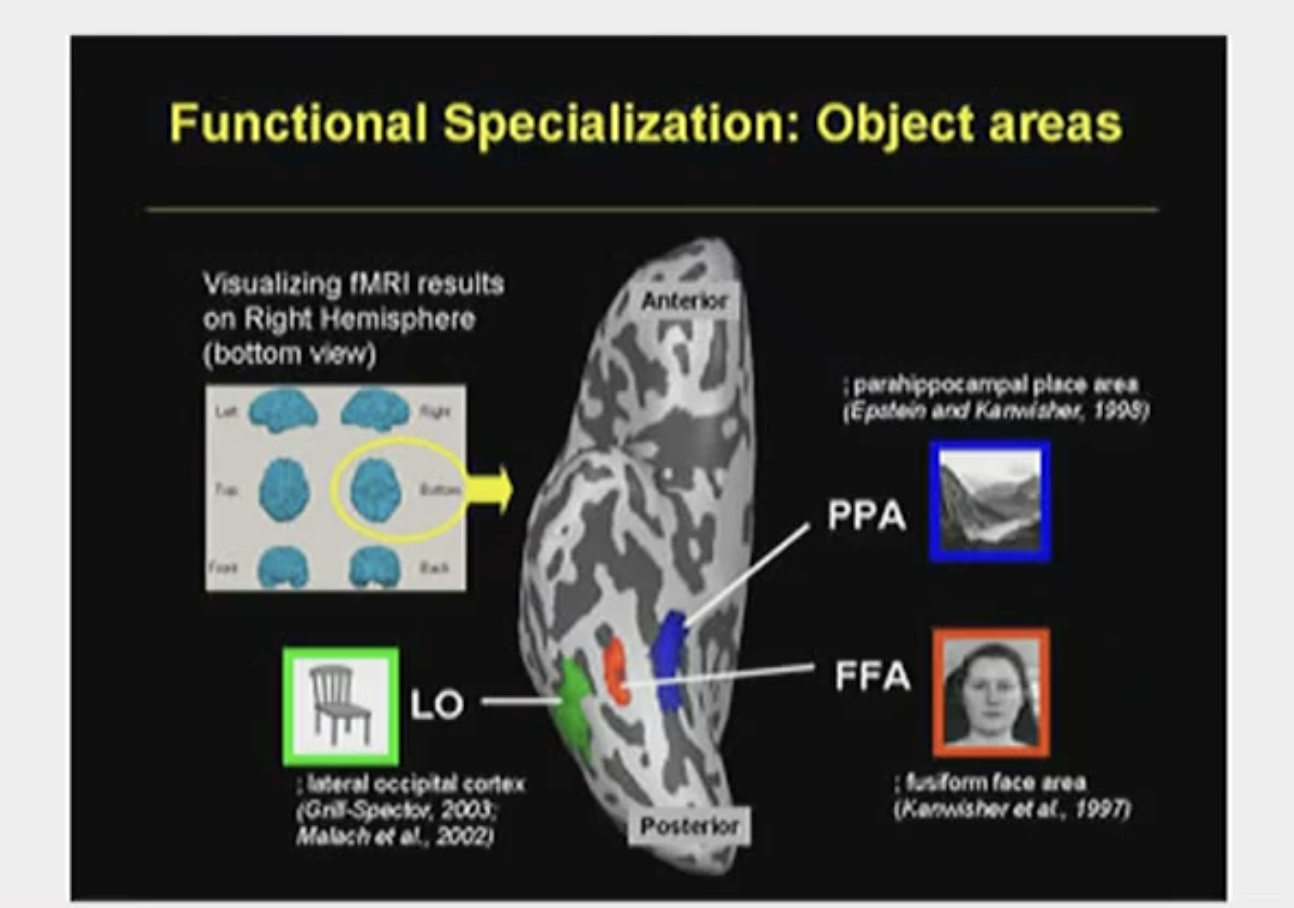
Agnosia patients endure damage where in their brain?
Temporal lobe (what pathway), knowing how to recognise objects.
Explain Ideomotor Apraxia.
Damage to the dorsal, where/how pathway. Deficit in action towards objects (ie. knowing how to act towards objects).
Explain blindsight.
They are blind because the visual cortex is damaged. But some of them have blindsight where they can act in the environment as though they can see. There is no conscious vision but their movements are as if they can see.