stats-
1/10
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai | Chat |
|---|
No analytics yet
Send a link to your students to track their progress
11 Terms
Logic of hypothesis testing
Researchers propose conjectures about the world and then subject these ideas to severe attempts at refutation through experiments
Scientists try to prove ideas wrong instead of confirmation. We build ideas by having a hypothesis survive several attempts at proving it wrong Knowledge grows through this self-correcting process where theories receive acceptance until evidence show errors
Every hypothesis starts with a “Research question” this is a question of inquiry that inspires us to create an experiment, but are not hypothese
The merit of our scientific questions depends on exactly how we define these research questions. There are no “bad inquiries, just poorly justified ones”
comparision
explicitly compares two or more groups/conditions
operationalization
defines variables in measureable units (hours, scores, frequency)
directionality
predicts exactly what will happen and in which direction (more/less, higher/lower)
testablity
can be provem wrong with single set of data
falsifiablity
The logic of hypothesis testing reflects separating science from pseudoscience. Karl Popper argued that falsifiability defines what makes a theory scientific.
A scientific theory must risk being wrong, making specific predictions, unlike pseudoscience, which explains outcomes after the fact and protects itself from refutation.
scholasticism and empircism
Empiricism: truth flows upward. Truth is only what can be confirmed by the senses
Scholasticism: truth flows downward. Truth is what we say it is
the approach to the scientific method was long and arduous. For much of recorded history, science was “authoritative” and not objective
Karl Popper’s ideas are a recent inclusion that aimed to cap off any vulnerabilities that lead us back to authoritative “science”
Ibn Al-Haytham was the first to come up with an official scientific method, followed by Francis Bacon, Galileo, Descartes, and Popper
Shifting from authoritative (or scholasticism) “science” to empiricism is a shift in epistemology (how do we obtain “truth”)
You do not "know" anything through pure logic alone; you only know things because you have seen, heard, touched, or measured them.
Statistics IS empirical mathematics, and the data are numeric representations of what our senses discovered. Inference is empiricism

null hypothesis significant testing (NHST)
We create the Null Hypothesis. It forces us to start by assuming the most boring, unoriginal version of reality: that nothing happened
The Point: We use a Null Hypothesis because Inference is a one-way street; you can't prove a "Universal Truth" from a "Small Sample," but you can disprove a lie.
Hypotheses-H0(chance) vs. H1 (effect)
H0=null hypothesis
H1=alternative hypothesis
Before collecting data, we define two competing realities, transforming a vague research question into a clear, statistically testable proposition.
We set this up in so that we define two populations, the “Null hypothesis” = no effect, and the “Alternative hypothesis” = effect
You did this when figuring out which group the rocks came from.
You also implicitly placed a “probability” on which group it belonged to
To falsify the null hypothesis, we need a clear mathematical rule that tells us when a result is too unusual to plausibly come from chance alone.
This is called our “Alpha-level” and it is an integral and ubiquitous component of statistic decision making, it represents “falsifiability”
Part and parcel of the Alpha-level is the p-value. This is the number we calculate using the t-test (which requires SE)
Alpha Level (α)
When we set an alpha level we are saying “We only consider this sample ‘rare’ if the chances of acquiring it are less then X”
By convention, scientists use alpha < 0.05, or: If the p-value is ≤ .05, the result is too unlikely under the null, so we reject it.
When we do this, we are entirely outsourcing our decision making process to the alpha level and the pvalue, if we don’t exceed alpha, we stay with the H0
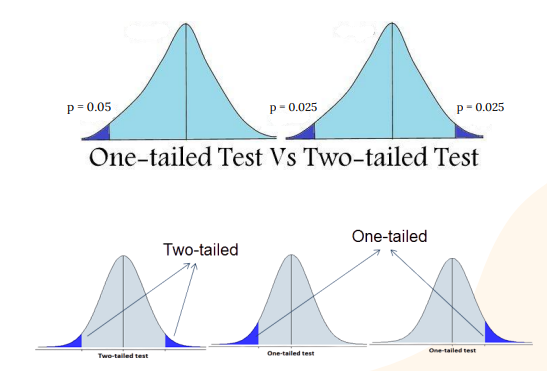
one tailed vs. two-tailed tests
These tables include one-tailed and two-tailed options. The difference depends on where we look for based on whether we predicted a direction.
Two-tailed tests are used when we seek any significant difference from the null without predicting direction, so extreme results on either side count.
One-tailed tests apply when we predict a specific direction, like expecting anxiety scores to decrease; only extreme values in that direction matter.
A one-tailed test is more liberal because it places the entire alpha level of .05 in one tail, creating a larger rejection region.
A two-tailed test is more conservative, splitting alpha between both tails, producing smaller rejection regions in both tails
This difference explains why a z score of 1.80 is significant one tailed but not two tailed, offering power yet risking missed opposite effects.