Thread Level Parallelism
1/14
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
15 Terms
What is Thread Level Parallelism (TLP) and how does it differ from ILP?
TLP focuses on: Throughput instead of latency.
Previous techniques (ILP) focused on reducing the latency of a single serial program.
Performance depends on instruction count, clock frequency, and ILP, but these improvements are becoming harder to achieve.
Threads allow a process to split into multiple simultaneously running tasks.
What is a process?
- A process is a running instance of a program, with its own memory, resources, and execution state.
What is a thread?
- A thread is a lightweight execution unit within a process that shares the process’s memory and resources with other threads.
Contrast Processes and Threads in terms of resource ownership and sharing.
Processes: Processes have separate memory spaces and resources (e.g. related files). They do not normally share resources.
Threads: Share address space, I/O handles, and process resources.
Each thread has its own: Stack, Register copy, and Program Counter (PC).
What are Parallel Regions and what is the primary performance limitation for TLP?
Programs may execute serially first, then split into threads in a parallel region.
Threads later join back into the master thread.
Limitation: Speedup depends on the serial fraction of the program. Even many threads cannot fully accelerate large serial sections.
Define and compare Coarse-Grain, Fine-Grain, and Simultaneous Multithreading (SMT).
Coarse-Grain MT: One thread executes at a time. The processor switches threads when the current thread stalls (e.g., waiting for memory).
Fine-Grain MT: Thread switches occur every clock cycle. Different threads occupy execution slots each cycle.
SMT: Multiple threads execute simultaneously. Different threads can use execution slots at the same time.
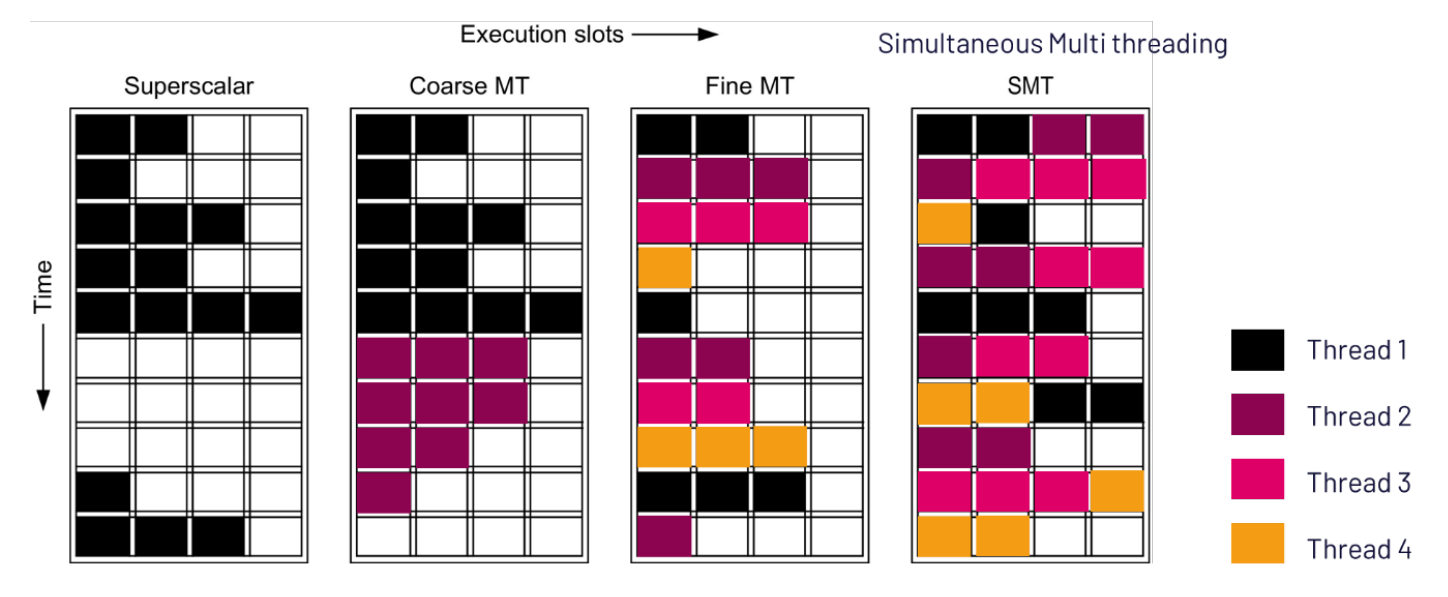
How does hardware resource sharing and context switching vary between multithreading types?
Type | Shared Hardware Resources | Context Switch |
|---|---|---|
Superscalar | Everything | OS context switch |
Fine-grained MT | Everything except RF and control state | Every cycle |
Coarse-grained MT | Similar to fine-grained + separate fetch buffers | On pipeline stall |
SMT | Fewer shared structures (ROB, store queue, return stack separated) | No context switch |
Multi-core | Nothing shared | - |
What is the "Too Much Milk Problem" and what does it illustrate about synchronization?
Two threads check for milk, see none, and both buy milk independently, resulting in duplicate work.
It illustrates that shared memory between threads can create synchronization hazards.
A thread may be context switched after checking a condition but before acting on it.
Explain the logic and failure points of the proposed solutions to the milk problem.
Solution 1 (Note after check): Thread might be switched after checking for a note but before leaving one.
Solution 2 (Note before check): Both threads might leave notes simultaneously, resulting in neither buying milk.
Solution 3 (Wait for note removal): Correct synchronization but complex, uses busy waiting, and has different code for each thread.
What are Locks and Critical Sections in thread synchronization?
Critical Section: Code that accesses shared resources.
Lock: Guarantees only one thread enters a critical section at a time.
Structure:
Acquire(lock)
if (noMilk)
buy milk
Release(lock)
What is an Atomic Operation and what are common approaches to implementing them?
Atomic Operation: Executes as one indivisible operation where either the entire sequence completes or none of it occurs.
Common approaches:
Fetch-and-add
Compare-and-swap
Load-linked/store-conditional
Describe the Fetch-and-Add operation and provide an example.
Atomic sequence:
Load → Add → Store.Hardware guarantees the entire sequence executes atomically.
Example: If A = 0, and Thread 0 performs
FETCHADD A,1while Thread 1 performsFETCHADD A,3, the final result is A = 4.
How does Compare-and-Swap (CAS) work and what is the function of BFAIL?
Atomic sequence:
Load → Compare → Conditional Store.The store occurs only if the memory value matches an expected value.
BFAIL (Branch on Failure): Used to retry the operation in a loop if the comparison fails.
What is the Load-Linked / Store-Conditional (LL/SC) sequence?
Atomic sequence:
Load → Arbitrary Operations → Conditional Store.LR (Load-linked): Loads the value.
SC (Store-conditional): Store succeeds only if no other thread modified the memory since the LR.
Example:
spin:
LR X1,A
ADDI X1,X1,1
SC X1,A
BFAIL spin
What is BFAIL and how is it typically implemented?
BFAIL: Branch on failure.
Used to retry failed synchronization operations.
Can be implemented using
BNEZor other branch instruction