2 - Binary Classification
1/38
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
39 Terms
SGD Advantages
Uses less memory than full‑batch GD
Faster updates
Helps escape local minima
Works well for large datasets
SGD Disadvantages
Noisy updates
Loss curve fluctuates
Requires tuning learning rate
SGD Assumptions
Loss function is differentiable
Mini‑batches are representative of the dataset
Mini-batch GD advantages
More stable than pure SGD
Faster than full‑batch GD
Efficient on GPUs
Mini-batch GD disadvantages
Still noisy
Batch size must be chosen carefully
Mini-batch GD assumptions
Data is shuffled
Batches are independent
Dataloader advantages
Automatically batches data
Shuffles data
Handles parallel loading
Makes SGD efficient
Dataloader disadvantages
Requires correct transforms
Can bottleneck if num_workers is too low
Dataloader assumptions
Dataset implements getitem and len
Logistic Regression advantages
Simple
Fast
Outputs probabilities
Works well for linearly separable data
Logistic Regression disadvantages
Only models linear boundaries
Struggles with complex patterns
Sensitive to outliers
Logistic Regression assumptions
Classes are linearly separable
Input features are meaningful
Uses sigmoid → outputs in (0,1)
Sigmoid Activation advantages
Smooth
Outputs probabilities
Differentiable
Sigmoid Activation disadvantages
Saturates (vanishing gradients)
Not ideal for deep networks
Sigmoid Activation assumptions
Output should be a probability
BCE Advantages
Proper loss for binary classification
Strong gradient signal
Works well with sigmoid
BCE Disadvantages
Sensitive to extreme predictions
Requires correct label encoding (0/1)
BCE Assumptions
Labels are 0 or 1
Output is a probability
What is Stochastic Gradient Descent?
An optimisation method that updates parameters using the gradient from a single sample or mini‑batch
Why use SGD?
It saves memory, is faster, and helps escape local minima
What is mini-batch GD?
Computing gradients on a small random subset of the data
What does DataLoader do?
Creates batches, shuffles data, and loads it efficiently
What does shuffle=True mean?
Data is randomly shuffled each epoch
What does drop_last=True do?
Drops the last incomplete batch
What is the shape of a batch?
imgs: (batch_size, 3, 32, 32)
labels: (batch_size,)
Why remap CIFAR‑10 to 0/1?
To convert a 10‑class problem into a binary problem
Why not use label=0 and label=1 directly?
Because CIFAR‑10 labels are integers 0–9, not booleans
What is logistic regression?
A linear model whose output is passed through a sigmoid to produce a probability. Formula where w and b are learnable parameters:
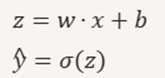
What does sigmoid do?
Maps any real number to a value between 0 and 1
Why use sigmoid?
To interpret output as a probability
Why flatten images?
Logistic regression expects a vector, not a 3D image
What does BCE measure?
The difference between predicted probability and true label.
Why use BCE?
It is the correct loss for binary classification
What are the steps of a training loop?
1. Forward pass
2. Compute loss
3. Backward pass
4. Update parameters
Zero gradients
Why use nn.Module?
To structure models cleanly and use built‑in optimizers
What does forward() do?
Defines how the model computes outputs
What is nn.Parameter?
A tensor that PyTorch treats as a learnable parameter
Why threshold at 0.5?
Sigmoid outputs probabilities; ≥0.5 means class 1
How is accuracy computed?
Correct predictions / total samples