8.22 - Experience introduction
1/14
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
15 Terms
Anomaly
Observed behaviour that violates an orthodox economic view of what is rational
How is ‘max something else’ still irrational & what to do
Max something else used as way to model deviation from standard theory and show people are still ‘rational’
But the new model still violates ST assumptions of rationality → model irrational
2 options on what to do:
Either non-ST objective function that is maximised is the true preference set
Therefore the preferences aren’t irrational
Model is of rational behaviour with subjects with non-standard preferences
OR Context leads to subjects attention drawn to things that make them become irrational – perception distorted
E.g. overweighting rare events
Internal validity
Design warrants reliable conclusions about an effect that did operate in the experiment
External validity
Design warrants reliable conclusions about an effect that would operate outside the experiment
Validity in experiments
Well controlled experiments have high internal validity
BUT external validity may sometimes be questionable
Scepticism about external validity is more convincing if reasons provided for why inference is valid
External validity in experiments
Since early generalised scepticism about artificiality of lab environments waned (took ages), external validity concerns about experimental findings have become:
more precisely targeted (at particular claims / findings)
Better rationalised by hypotheses about why conclusions of some experiments may not generalise
More investigable - possibly more experiments
Experience and External validity
Critics argue experiments use inexperienced subjects and this undermines any external validity
unfamiliar / complex tasks
limited opportunity for reflection / practice / discussion
only modest incentives - less reason to be truthful
young / less experienced students used
Critics and experiments
Critics argue that ST shouldnt have to apply everywhere (not got general applicability)
testing outside its domain proves nothing
Experiments only test outside of where ST should operate and so findings arent applicable
ST can only ‘reasonably be expected’ to apply in the lab if:
Decision problems are simple enough
Incentives adequate
Time for learning / experience sufficient
Preference discovery
Individuals have a consistent set of preferences, but such preferences only become known to the individual with thought and experience
Preferences independent of learning process
Plott (1996) - Theory
Choices go through a 3 stage process
Inexperienced - impulsive behaviour
Experienced - After experience there is deliberation + reflection (especially if incentives sufficient)
Converged - Beliefs about other players converge to reality
Discovered preferences are those revealed by choices at end of 3-stages
inexperienced subjects may not conform to it - thats why they violate ST
ST only applies to discovered preferences
Plott & Binmore critique
Both experimenters and are critics of tests with too low incentives or inexperiences subjects
ST shouldnt apply to these domains
Critique of anomalies is doubled edged:
defending ST against low stakes / inexperience in the lab also means it should hold in the field
Very common for field to either use low incentives or infrequent tasks
How to test Plott & Binmore critique
Empirically testable as it predicts prevalence of anomalies to fall as:
incentives get stronger / more realistic
More experienced subjects gets
Esponda et al (2024) - OV
Tests effect of experience on judgment of probability
testing for Bayes rule application
In each round subject given question with same underlying base rate and signal probabilities
asked prob of success or failure
Incentivised to give what subject thinks true answer is
200 rounds + 2 treatments
Primitives - subjects told underlying probabilities at start + at end see result (success or failure) & record of signals / previous outcomes
Could work out in rd.1 and give correct answer in all rounds after
No Primitives - Subjects never told underlying probabilities
only have experience to rely on
Design provides signal & outcome experience in both treatments
Esponda et al (2024) - prediction
Predicts many subjects will answer wrongly the first time
Perefect base-rate neglect → think test reliability is probability
Base-rate neglect → thinking prob < reliability BUT > true value
Perfect signal neglect → Thinking probability is random chance as reliability not 100%
Previous studies suggest base-rate neglect strong when inexperienced subjects face this kind of problem
Esponda et al (2024) - RESULTS
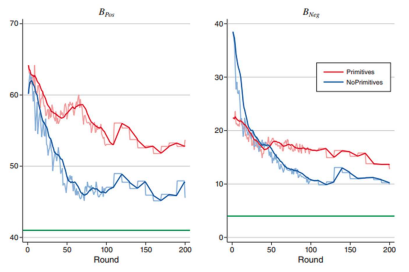
Both treatments not near true Bayes answer in rd.1
Judgement of prob moves in right direction for both BUT learning flattens off after rd.100
No-Priv learns a lot faster in both cases
No-Priv more accurate at end of study
more explicit information not always helpful - incorrect mental models cause persistent deviation