Lecture 1 methods of master class : Panel Regressie
1/18
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
19 Terms
What are the three types of data
Cross-section: many units, one period
Time series: one unit, many periods
Panel data: many units, many periods
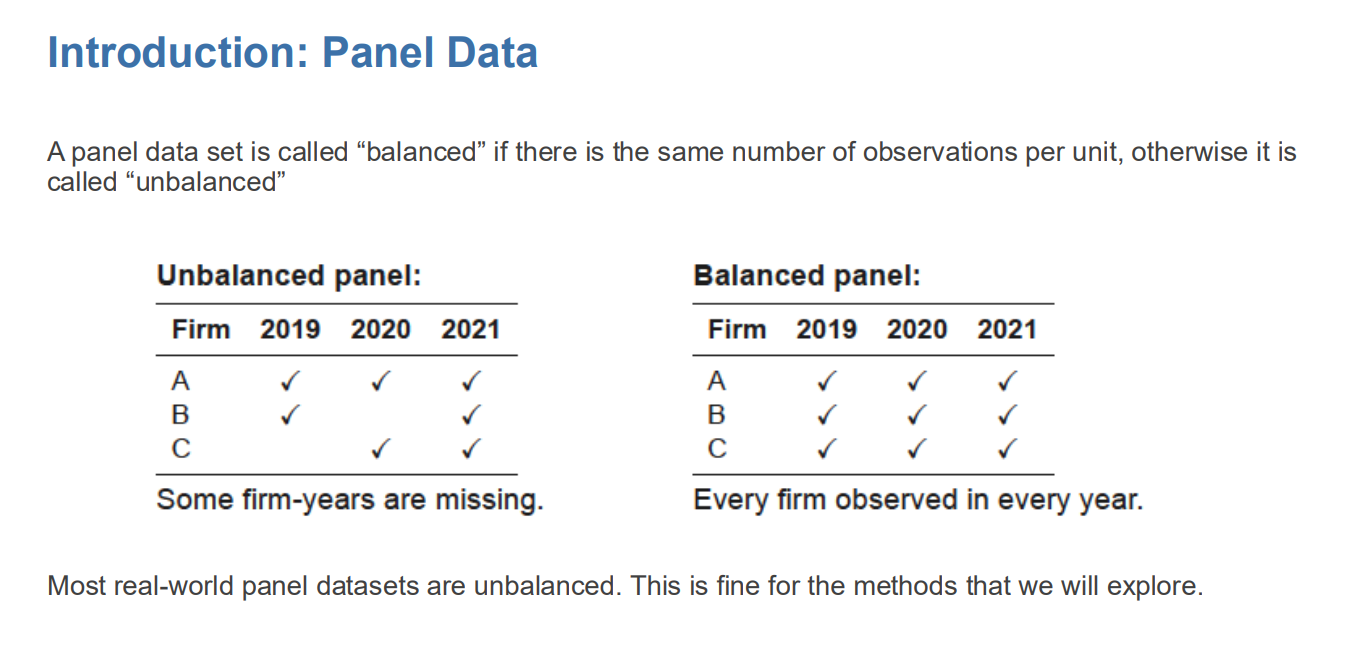
What is a balanced vs. unbalanced panel dataset?
Balanced panel: Every unit observed in every time period.
Unbalanced panel: Some unit-time observations are missing.
Most real panel datasets are unbalanced.
What is the pooled regression model in panel data?
You simply stack all observations together and run one normal regression as if it were one big dataset.
What are the two main problems with pooled OLS in panel data?
Technical problem : Errors are often correlated within units →
This breaks the OLS rule that errors must be independent.
As a result, coefficients and standard errors can become biased or misleading.Conceptual problem : Mixes between groups and within the same groups → hard to interpret how variables behave within or between groups separately
What two types of variation exist in panel data?
Between variation: differences across units
Within variation: changes within the same unit over time
Why are errors often correlated within units?
Errors tend to be correlated within units because of unobserved factors that are not measured in the data or variables (unobserved unit) that have a constant effect over time (time constant). These factors—such as ability, culture, or management quality—impact the independent variable consistently within each unit.
Why is within-unit variation more credible for causal inference?
It compares a unit with itself over time, controlling for time-constant characteristics.
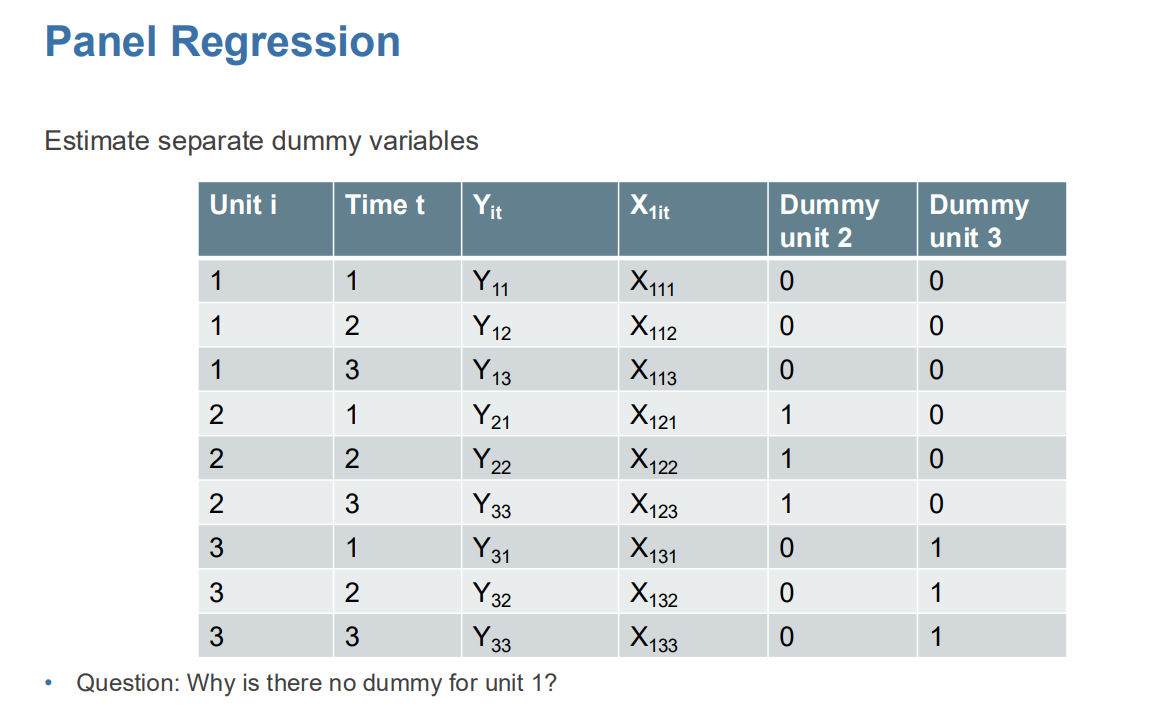
How do we run a regression that only uses within unit variation?
Two ways:
Estimate separate dummy variables for each unit (Yes(1) and no (0))
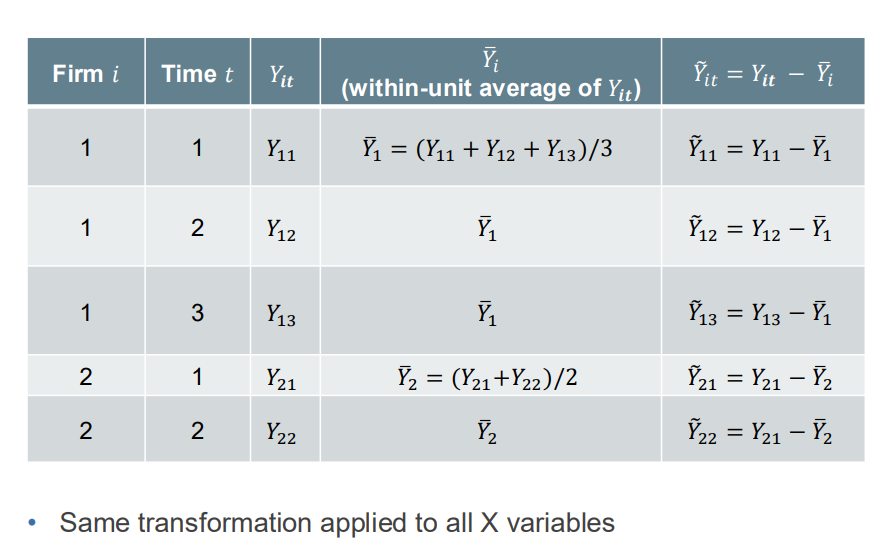
Demean Y and X variables by using unit level averages (“within transformation”)
Note Bij 100 observaties met dummyvariabelen kunnen er maximaal 99 dummyvariabelen voorkomen, omdat één categorie als referentie wordt gebruikt en dus niet apart wordt weergegeven.
Calculate within transformation? (weten hoe)
Subtract the unit average from each observation:
This removes time-invariant unit effects.
Why can’t time-invariant variables (e.g., gender) be estimated with fixed effects?
Omdat de within-transformatie alle variabelen verwijdert die niet veranderen in de tijd.
What is the Solution for accounting for correlation in error terms
Cluster standard errors
What is the key panal assumption about error terms?
Error terms must not be correlated across observations.
On which level to cluster?
If possible, cluster on the same level as your fixed effects
ow many levels of clustering do most standard software packages allow?
Up to two levels of clustering.
What should you do if you have more than two fixed effects when clustering?
Cluster on the level with fewer categories because it leads to more conservative (larger) standard errors.
Why is it good if your results are still significant after clustering on the level with fewer categories?
It means your results are robust and reliable despite the larger standard errors.
Why is it advised not to cluster on fixed effects with fewer than 50 categories?
Because it makes standard errors too large, making it hard to find significant results.
What Panel Regression Does
Controls for unobserved unit-specific effects that are constant over time
Focuses only on within-unit variation
Because of this, panel regression is better at answering causal questions like:“Did X cause Y?” compared to standard OLS regression
What Panel Regression Does NOT Do
Does not control for unobserved unit-specific effects that change over time.
not solve all problems in answering “Did X cause Y?”