STAT 3302 – Final: Multivariate Normal Distribution (MVN)
1/8
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
9 Terms
What is the Multivariate Normal (MVN) distribution and how do we write it?
We write X ~ Nₚ(μ, Σ), where:
X is a random vector with p components
μ is the mean vector (where the distribution is centered)
Σ is the covariance matrix (describes spread and correlations)
Σ must be positive definite
Special case: if μ = 0 and Σ = I (identity matrix),
then X ~ Nₚ(0, I) is called the standard multivariate normal and each component is an independent standard normal N(0,1).
What is the density formula for the MVN distribution?
The term inside the exponent, (x−μ)ᵀΣ⁻¹(x−μ), measures how far x is from the mean — the further away, the smaller the density.
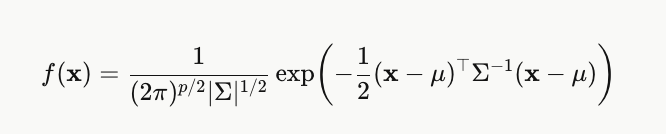
What do the mean vector μ and covariance matrix Σ tell you about an MVN distribution?
μ tells you where the distribution is centered. E[X] = μ.
Σ tells you the spread and correlations. Var(X) = Σ.
The diagonal entries of Σ are the variances of each individual variable.
The off-diagonal entries are the covariances between pairs of variables.
What happens when you apply a linear transformation to an MVN vector?
Linear combinations of normal variables are still normal. The mean gets transformed by A, and the covariance gets "sandwiched" by A.
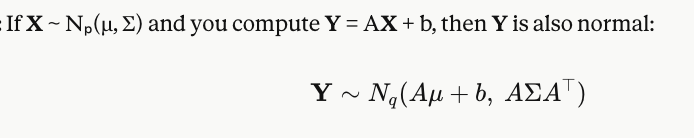
What are the marginals of an MVN distribution?
If X ~ Nₚ(μ, Σ), then each individual component Xᵢ is also of a normal distribution.
And any subset of the components is also MVN. So if you ignore some variables and just look at others, they're still jointly normal.
For MVN, what does zero covariance between two variables mean?
zero covariance = independence.
So if Cov(Xᵢ, Xⱼ) = 0 and the variables are jointly normal, then Xᵢ and Xⱼ are independent.
This is a special property of MVN that doesn't hold in general.
What is the conditional distribution of X₁ given X₂ in a bivariate normal?
The conditional mean is a linear function of X₂
The conditional variance is smaller than σ₁₁ — knowing X₂ reduces uncertainty about X₁
The more correlated X₁ and X₂ are, the more variance is explained
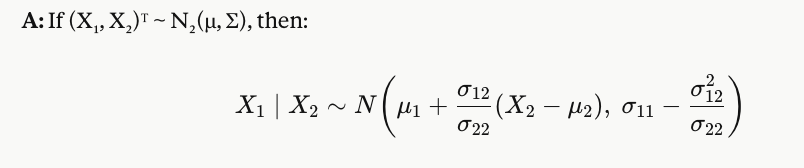
What is E[X₁ | X̄] when X₁, X₂, X₃ are independent variables of N(0,1) and X̄ is their average? What is Var(X₁ | X̄)?
General pattern for n i.i.d. N(0,1): Var(X₁ | X̄) = 1 − 1/n.
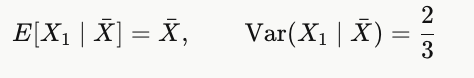
What is the Wishart distribution and when does it appear?
