STAT 200 pre-midterm
1/30
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
31 Terms
what is a numerical vs categorical variable?
categorical = outcomes fall in different categories
numerical = outcomes can be measured on a numerical scale
numerical variables can be transformed into categorical (ex. age → age range)
subgroups = levels (ex. category = faculty, levels = science, arts, etc.)
what are the ways to summarize categorical variables?
frequency / relative frequency tables
contingency tables (two-way table)
graphical displays (bar charts, pie charts - based on frequencies)
what are marginal distributions?
separate variables into separate tables
determine distribution of each table
what are conditional distributions and what are contingency tables used for?
set one level as a condition - this is the total used for determining frequency
ex. a place of residence for arts students - arts students is the condition
what are the ways to summarize numerical data?
graphical displays (histograms, stem-and-leaf displays, boxplots)
shape of distribution of data
numerical summaries
how are histograms used for numerical data?
make categories for numerical values
find frequencies for numerical values
advantage - helps us look at shape of distribution
modality, symmetry of distribution, presence of outliers
disadvantage - lose actual data points
what is modality?
number of peaks - unimodal, bimodal, multimodal
what are the different symmetries of distribution?
symmetric
skewed to the right / positively skewed
long right tail
skewed to the left / negatively skewed
long left tail
what are the numerical summaries for numerical data?
measures of center
mean, median
measures of spread
variance, standard deviation, interquartile range
percentiles (quantiles) / quartiles
5-number summary
minimum, first quartile (Q1), second quartile (Q2), third quartile (Q3), maximum
how are stem-and-leaf displays used for numerical data?
split data into 2 parts
all except last digit of data = stem
last digit of data = leaf
list unique stems
list leafs in ascending order
rotating should match histogram shape
how are boxplots used for numerical data?
makes use of 5 number summary
draw Q1 and Q3 → make box
find Q2 / median → draw line
find boundaries for outliers
LB = Q1 - 1.5(IQR)
UB = Q3 + 1.5(IQR)
draw boundary lines (whiskers) → line at value closest to boundary that is not an outlier
if no outliers → extend whiskers to min and max
outliers outside of boundaries marked by circles
draw min and max
what is the mean and how to calculate?
the average of a dataset
sum of all observations / number of observations
what is the median and how to calculate?
exact middle value of a dataset
if odd number of data points
= ((n+1) / 2)th data point
if even number of data points
= average of (n/2)th + (n/2+1)th data points
what is variance and how to calculate?
shows total variation
squared deviations of values from the mean
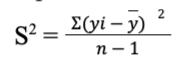
what is standard deviation and how to calculate?
the square root of variance
s = sqrt(s2)
what are percentiles / quartiles?
position where a certain amount of data points are below it
quartile 1 = value in data set that has 25% of values below it
quartile 2 = 50%
quartile 3 = 75%
what is the interquartile range and when is it used?
different between Q1 and Q3 (Q3 - Q1)
used when you have skewness or outliers
better that using standard deviation / variance for these conditions
how does shifting data affect measures of center / spread?
add a constant c to each observation in the data
any measure of center (median / mean) shifts by constant c
shifting the data does not change the spread (variance, SD, range, IQR)
how does scaling data affect measures of center / spread?
multiply each observation in the data by a positive constant c
measures of center and spread will be multiplied by constant c
variance of the new data will be c2 times the original variance
when is standardizing data used?
to compare observations measured on different scales
ex. different currencies
to compare observations from two different distributions
ex. class averages across different semesters
what is a z-score and how to calculate?
z = observation - mean / SD
gives the distance between an observation and the mean in units equal to the standard deviation
the number of standard deviations that a value is above of below the mean
z = 0 → observation = mean
what are characteristics of the normal model?
bell-shaped, unimodal
symmetric about the mean 𝜇
spread of distribution determined by the value of SD 𝝈
denoted by N(𝜇, 𝝈)
what are terms used for population vs sample standard deviations?
population numerical summaries = parameters
𝜇 = mean, 𝝈2 = variance, 𝝈 = SD
sample numerical summaries = statistics
ȳ = mean, s2 = variance, s = SD
how are values from the normal model standardized?
calculate z-score
z-score follows the standard normal model with mean = 0 and SD = 1
what is the 68-95-99.7% rule?
Interval → % data falling in interval
Within 1 SD of mean = ~68%
Within 2 SD of mean = ~95%
Within 3 SD of mean = ~99.7%
what is a scatterplot and when is it used?
helps visualize possible relationships between 2 quantitative variables
explanatory variable plotted on x-axis
response variable plotted on y-axis
explanatory variable is believed to have influence on the value of the response variable
what are the patterns of a scatterplot that must be described?
direction
positive → x and y values tend to go in the same direction
negative → x and y values tend to go in the opposite direction
form
linear vs non-linear
how scattered are the points?
strong relationship → points close to each other
weak / no relationship → points spread out / randomly scattered
any outliers?
any points outside of pattern seen
what is correlation and the correlation coefficient?
correlation refers to the degree of linear association between 2 quantitative variables x and y
correlation coefficient r is a measure of the strength of a linear association between 2 quantitative variables
what are the different types of correlation
positive correlation = large values of x are linearly associated with large values of y
r = +1 gives perfect positive correlation
negative correlation = large values of x are linearly associated with small values of y
r = -1 gives perfect negative correlation
what are properties of the correlation coefficient r?
swapping x and y values does not affect the value of r
the value of r does not change if all values are shifted or scattered;ed
r is sensitive to outliers, may not give a reliable measure of strength of a linear relationship in the presence of outliers
how do association and causality differ?
the existence of a linear relationship between 2 variables x and y does not imply that an increase in one variable leads to an increase of decrease in another
association does not imply causation
there may be a lurking variable (third variable) that associates both x and y