H5: Structuur van beweging
1/6
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
7 Terms
Wat is SfM
SfM = Structure from Motion
scènereconstructie vanuit meerdere camerastandpunten, vaak gebruikt in fotogrammetrie
Centrale vraag: gegeven veel afbeeldingen, hoe kunnen we:
Bepalen vanwaar ze genomen zijn? (motion)
Een 3D-model van de scène opbouwen? (structure)
Toepassingen:
Photo tourism: fotocollecties in 3D verkennen (zie dia 5)
3D selfie (figuurafdruk via meerder camerastandpunten)
Typische verwerkingsstappen
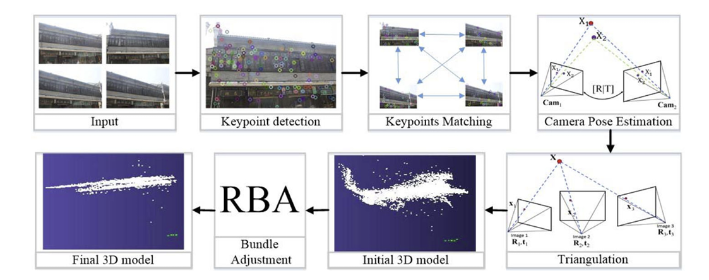
Input afbeeldingen
Keypuntdetectie
Keypuntmatching
Camera pose-schatting (via essentiële matrix, PnP-algoritme, ...)
Triangulatie → initieel 3D-model
Bundle adjustment → finaal 3D-model
PnP algoritme
Het PnP algoritme (Perspective-n-Point) is een methode binnen Structure from Motion om de exacte camerapositie en -oriëntatie (de pose, bestaande uit de rotatiematrix R en translatievector t) te berekenen ten opzichte van een gekend referentie-object in de scène.
Om dit algoritme te kunnen gebruiken, moet aan twee voorwaarden voldaan zijn:
De camera is intrinsiek gekalibreerd (de interne matrix K is bekend).
Je kent de relatieve 3D-posities (en dus de fysieke afstanden dij) van een klein aantal referentiepunten op het object (bijvoorbeeld de hoeken van een doos met bekende afmetingen).
Het algoritme werkt wiskundig op basis van de volgende stappen:
1. Kijkhoeken berekenen (De geometrie) Omdat de camera gekalibreerd is, kunnen we de 2D-beeldpunten via K−1 omzetten naar genormaliseerde, 3D-kijkstralen (eenheidsvectoren x^i en x^j). De hoek θij tussen twee van deze kijkstralen komt exact overeen met de hoek waaronder de camera de twee fysieke 3D-punten pi en pj ziet. Deze hoek kan simpelweg berekend worden via het inproduct: θij=arccos(x^i⋅x^j).
2. De Cosinusregel toepassen Nu we de kijkhoek θij kennen én we de fysieke afstand dij tussen de twee referentiepunten op het object weten, kunnen we de driehoek vormen tussen de cameralens (c) en de twee punten. Door de cosinusregel op deze driehoek toe te passen, ontstaat de vergelijking: di2+dj2−2didjcos(θij)−dij2=0 Hierbij zijn di en dj de onbekende afstanden van de camera tot de specifieke punten.
3. Het stelsel oplossen (Linear PnP) Als we 3 referentiepunten gebruiken, krijgen we 3 van deze vergelijkingen. Door substitutie leidt dit wiskundig echter tot een erg complexe vierdegraadsvergelijking (in di2) die lastig op te lossen is. De oplossing is het Linear PnP algoritme:
Als we minimaal 5 punten gebruiken, kunnen we minimaal 6 van dit soort combinaties (triplets) maken.
In plaats van de complexe machtsvergelijking op te lossen, behandelt het algoritme de machten di8,di6,di4 en di2 tijdelijk als vier afzonderlijke, lineaire variabelen.
Hierdoor ontstaat een overgedetermineerd stelsel van 6 lineaire vergelijkingen met 4 onbekenden, dat razendsnel kan worden opgelost met SVD (Singular Value Decomposition).
4. De PnP pijplijn in de praktijk In echte Computer Vision toepassingen wordt dit als volgt in een robuuste pijplijn (met RANSAC) gegoten:
Gebruik een feature detector om de 2D-projecties van minimaal 5 bekende 3D-punten te vinden.
Pas het Linear PnP algoritme toe om de afstanden di te vinden, waarmee je direct de 3D-coördinaten van de punten ten opzichte van de camera weet (pi=c+dix^i).
Omdat je deze coördinaten nu in de camera-ruimte hebt, én ze vooraf al bekend waren in de wereld-ruimte, kun je de rotatie R en translatie t afleiden.
Gooi dit in een RANSAC-lus: kies willekeurig 5 punten, bereken de pose, test hoeveel andere beeldpunten (features) hiermee correct op het model vallen (consensus), en herhaal dit om de beste transformatie zonder outliers te vinden.
Gebruik tot slot alle goedgekeurde inliers om het R en t model te verfijnen.
Triangulatie
Triangulatie is een techniek binnen Structure from Motion (SfM) om de daadwerkelijke 3D-coördinaten van een punt in de ruimte te berekenen, op basis van zijn 2D-projecties in meerdere foto's.
Om triangulatie te kunnen toepassen, geldt er een belangrijke voorwaarde: de camera's moeten gekalibreerd zijn en de exacte cameraposities en projectiematrices (P) moeten al vooraf bekend zijn (bijvoorbeeld via het PnP-algoritme of de essentiële matrix).
Hier is een gestructureerde uitleg van hoe dit concept in elkaar zit:
1. Het verschil tussen Triangulatie en Stereovisie Hoewel beide technieken diepte proberen te schatten, zijn er duidelijke verschillen:
Stereovisie gebruikt meestal 2 camera's die dicht bij elkaar staan (narrow baseline) om parallax te vermijden, met perfect uitgelijnde assen (stereorectificatie). Het zoekt matches per pixel op horizontale lijnen en levert een depth map op.
Triangulatie kan 2 of meer camera's gebruiken die veel verder uit elkaar staan (wide baseline) en waarvan de kijkassen kriskras door elkaar lopen. Men zoekt matches via feature-detectoren (zoals SIFT of ORB) en genereert daarmee een 3D point cloud (reconstructie).
2. Het geometrische probleem In een perfecte, wiskundige theorie trek je een denkbeeldige kijkstraal (ray) vanuit het centrum van de eerste camera door het gevonden pixel (x), en een tweede straal vanuit de tweede camera door het corresponderende pixel (x′). Het exacte snijpunt van deze twee stralen is je 3D-punt X. In de praktijk bevatten onze metingen echter fouten en ruis, waardoor deze stralen elkaar in de 3D-ruimte net niet snijden en ze niet perfect aan de epipolaire beperkingen voldoen.
3. De wiskundige oplossing (Lineaire methoden) Om toch de beste benadering van het 3D-punt X te vinden, gebruikt men de projectievergelijking x=PX. Omdat x en X in homogene coördinaten staan, geldt er een schaalfactor λ (λx=PX). Door kruiselings te vermenigvuldigen, kan men λ elimineren. Voor elke camera levert dit 2 bruikbare lineaire vergelijkingen op. Voor N camera's krijg je zo een wiskundig stelsel van de vorm AX=0, waarbij A een 2N×4 matrix is. Men lost dit stelsel op via een van de volgende methodes:
Homogene methode: Men zoekt de vector X=(X,Y,Z,U)T met lengte 1 (∣∣X∣∣=1) die de fout ∣∣AX∣∣ minimaliseert met behulp van SVD. Nadeel: Het resultaat is niet invariant voor projectieve of affiene transformaties.
Inhomogene methode: Men dwingt de laatste coördinaat op 1 (X=(X,Y,Z,1)T), waardoor het een stelsel van 3 onbekenden wordt, en lost dit via Least Squares op. Nadeel: Dit werkt niet voor 3D-punten die (bijna) oneindig ver weg liggen (U=0).
4. Onzekerheid en de "Trade-off" De wiskundige nauwkeurigheid van triangulatie hangt sterk af van de hoek tussen de camera's:
Als camera's heel dicht bij elkaar staan, lopen de kijkstralen bijna parallel. Hierdoor wordt de onzekerheidsmarge (de foutmarge) in de diepte gigantisch groot.
Staan de camera's ver uit elkaar, dan snijden de stralen onder een scherpe hoek en is de triangulatie heel accuraat. Echter, door de totaal andere kijkhoek is het in de praktijk veel moeilijker om met een algoritme nog corresponderende features te matchen. Dit is een klassieke trade-off in Computer Vision.
5. Schaal-ambiguïteit Zelfs met perfect gekalibreerde camera's levert triangulatie (in combinatie met de essentiële matrix) een reconstructie op die slechts tot op een onbekende schaalfactor (scale factor) accuraat is. De computer weet namelijk niet of hij naar een gigantisch gebouw in de verte kijkt, of naar een miniatuurversie (zoals in Mini-Europa) vlakbij. Om de absolute dimensies (in meters) te weten te komen, moet minstens één fysieke afstand in de scène (een "yard stick") op voorhand bekend zijn.
Bundle adjustment
Bundle adjustment = het meest algemene probleem waarbij zowel cameraparameters als 3D-scène onbekend zijn
Doel: verfijn initiële schattingen van camera-en structuurparameters simultaan door de totale reprojectiefout te minimaliseren
minPj,Xi∑i∑jvij d (Q(Pj,Xi)−xij)2Pj,Ximini∑j∑vijd(Q(Pj,Xi)−xij)2
waarbij:
Q(Pj,Xi)Q(Pj,Xi) de voorspelde projectie is
xijxij de geobserveerde projectie is
vij=1vij=1 als punt ii zichtbaar is door camera jj, anders vij=0vij=0 (indicatorvariabele)
→ Niet-lineair optimalisatieprobleem (typisch opgelost met het Levenberg-Marquardt algoritme)
Pose estimation from fundamentele matrix
Het stuk over Pose estimation from fundamental matrix (ook wel zelfkalibratie genoemd) lost een groot probleem op binnen Structure from Motion (SfM).
Tot nu toe had je voor het berekenen van de camerapositie (pose) altijd iets van voorkennis nodig: ofwel kende je de 3D-punten al (zoals bij het PnP-algoritme), ofwel was je camera al intern gekalibreerd (zodat je de Essentiële matrix kon berekenen). Maar wat als je een stel willekeurige vakantiefoto's van het internet plukt (zoals bij Photo Tourism), waarbij zowel de 3D-scène als de camera's en hun instellingen volledig onbekend zijn?
Je kunt dan niet direct beginnen met de ultieme optimalisatie (Bundle Adjustment), want dat algoritme is traag en heeft een heel goede initiële gok nodig om te werken.
Hier is hoe men dit wiskundig oplost puur op basis van de Fundamentele matrix (F):
1. Vereenvoudigende aannames (De intrinsieke matrix K) Omdat we de interne cameramatrix K niet kennen, doen we een paar veilige, standaard aannames over de lenzen om het probleem te versimpelen:
Er is geen skew (scheeftrekking van de pixels).
Er is geen lensvervorming (optical distortion).
De pixels zijn perfect vierkant (aspect ratio = 1).
Het middelpunt van de foto (principal point) ligt exact in het centrum.
Door deze aannames blijft er wiskundig gezien in de matrix K nog maar één onbekende over per camera: de brandpuntsafstand (focal length f).
2. De Fundamentele matrix berekenen Met behulp van feature-detectoren (zoals SIFT) zoeken we naar overeenkomsten tussen de twee foto's en berekenen we de Fundamentele matrix F (bijvoorbeeld met het 8-punten algoritme). Omdat de beelden vanuit ten minste twee verschillende standpunten moeten zijn genomen, is dit goed te doen.
3. De Kruppa-vergelijkingen toepassen Nu komt de wiskundige truc. Men past Singular Value Decomposition (SVD) toe op de matrix F.
Dit levert singuliere waarden (σ0,σ1) en singuliere vectoren (u0,u1,v0,v1) op.
Men stopt deze waarden in een hele specifieke set formules, de zogenaamde Kruppa-vergelijkingen.
Deze vergelijkingen koppelen de eigenschappen van de Fundamentele matrix direct aan de matrices Di=KiKiT. Het resultaat is een stelsel van twee kwadratische vergelijkingen met als enige onbekenden de brandpuntsafstanden f0 (van camera 1) en f1 (van camera 2).
4. Het Resultaat: Zelfkalibratie Door deze kwadratische vergelijkingen op te lossen, vind je de brandpuntsafstanden en heb je de camera's in feite gekalibreerd zonder ooit een kalibratiepatroon (zoals een schaakbord) te gebruiken!
Omdat je nu de Fundamentele matrix F én de interne cameramatrices K0,K1 kent, kun je direct de Essentiële matrix (E) berekenen. Zoals we in de vorige hoofdstukken hebben gezien, kun je die matrix E vervolgens weer decomposeren om de exacte rotatie (R) en translatie (t) van de camera's te vinden. Dit vormt dan de perfecte startpositie om de hele scène via triangulatie in 3D te reconstrueren.
Factorisatie onder orthografie
Het stuk over Factorization under orthography (ook wel de Tomasi-Kanade factorisatie genoemd) beschrijft een elegante wiskundige methode binnen Structure from Motion (SfM). In tegenstelling tot de eerdere methoden (zoals de essentiële matrix) berekent deze methode de cameraposities (motion) en de 3D-vorm van het object (structure) tegelijkertijd in één grote matrixberekening, puur op basis van het volgen van kenmerken (feature tracking) over meerdere videoframes.
Om dit wiskundig op te lossen, maakt de methode een paar versimpelende aannames:
Orthografische projectie: Men gaat ervan uit dat er geen perspectiefvervorming is. Dit betekent dat er wiskundig niet gedeeld hoeft te worden door de diepte (Z), waardoor de projectie een puur lineaire vergelijking wordt. Dit is een geldige aanname zolang het object relatief ver weg is ten opzichte van zijn eigen diepte (zoals inzoomen met een telelens).
Er is één star (rigid) object en alle geselecteerde kenmerken (features) blijven in elk frame zichtbaar.
Het algoritme werkt in vier grote stappen:
1. De 'Centroid Trick' (Translatie elimineren) In een orthografisch model is de projectie een combinatie van rotatie en translatie. De briljante eerste stap is om de translatie (tx,ty) volledig weg te werken. Dit doet men door voor elk frame het geometrische middelpunt (de centroid) van alle gevonden 2D-punten te berekenen. Vervolgens trekt men deze centrumcoördinaat af van alle individuele punten. Hierdoor valt de translatie van de camera mathematisch volledig weg, en blijft er per punt enkel een 2×3 matrix over die puur de 3D-rotatie (en dus de kijkhoek) beschrijft (x=M⋅X).
2. De Measurement Matrix (W) en "Rank 3" Vervolgens stopt men alle gecentreerde 2D-coördinaten van álle N punten uit álle F videoframes in één gigantische matrix, de Measurement matrix (W) van formaat 2F×N. Omdat elk 2D-punt simpelweg het product is van de camerabeweging en de 3D-structuur, kan deze enorme matrix theoretisch opgesplitst (gefactoriseerd) worden in twee kleinere matrices: W=M⋅S.
M (Motion matrix): Bevat alle camerarotaties (formaat 2F×3).
S (Structure matrix): Bevat alle werkelijke 3D-coördinaten van het object (formaat 3×N).
De cruciale ontdekking hier is dat, hoewel matrix W enorm veel data bevat, zijn wiskundige rang (rank) maximaal 3 kan zijn, omdat de onderliggende 3D-wereld nu eenmaal maar 3 dimensies heeft.
3. Factorisatie via SVD Om W daadwerkelijk in M en S op te splitsen, gebruikt men Singular Value Decomposition (SVD) (W=UDVT). Omdat onze metingen in de echte wereld ruis bevatten, zal de rang van W in de praktijk groter dan 3 zijn. Men dwingt het systeem daarom terug naar rang 3 door simpelweg alle singuliere waarden weg te gooien, behalve de drie allergrootste. Dit levert de wiskundig meest optimale "Least Squares" benadering op voor M en S.
4. De Metrische Transformatie (Orthonormaliteit) De SVD levert een geldige wiskundige oplossing op, maar nog niet de juiste fysieke oplossing. Je kunt de ruimte namelijk wiskundig schuin samendrukken met een willekeurige 3×3 matrix Q, zolang je het object maar precies omgekeerd vervormt met Q−1 (W=(MQ)(Q−1S)). Om de échte, fysieke matrix Q te vinden, gebruikt men de regel van orthonormaliteit: de assen van de camera in de echte wereld staan loodrecht op elkaar en behouden hun schaal. Door dit als wiskundige eis te stellen (rijen van M moeten orthogonaal zijn en lengte 1 hebben), ontstaat een stelsel vergelijkingen waarmee men exact kan uitrekenen wat de juiste M en S moeten zijn.
Conclusie: Je stopt een hele hoop 2D-tracks in een grote matrix, haalt het middelpunt eruit, forceert de matrix via SVD naar 3 dimensies, en trekt het resultaat recht met behulp van loodrechte camera-assen. Het eindresultaat is direct het volledige 3D-model én de route die de camera heeft afgelegd!
photogrammetry
Het stuk over Photogrammetry (fotogrammetrie) vormt de praktische afsluiting van Hoofdstuk 5. Fotogrammetrie is de wetenschap en technologie van het maken van metingen uit foto's. In de context van Computer Vision (en specifiek Structure from Motion of SfM) betekent dit het reconstrueren van een complete, uiterst gedetailleerde 3D-scène op basis van een grote verzameling (vaak ongestructureerde) overlappende 2D-foto's.
Volgens de slides verloopt de moderne fotogrammetrie-pijplijn voor grootschalige 3D-modellen in de volgende opeenvolgende stappen:
1. Beeldassociatie (Scene Graph) Je start met een willekeurige collectie foto's (bijvoorbeeld vakantiefoto's of beelden van een drone). De eerste stap is uitzoeken welke beelden met elkaar overlappen door de gezamenlijke kenmerken (features) te matchen, zodat er een netwerk (scene graph) ontstaat.
2. Structure from Motion (SfM) → Sparse Model Vervolgens wordt SfM toegepast om gelijktijdig de posities van alle camera's in de ruimte te bepalen én een eerste, schaars 3D-model (sparse model) te genereren. Omdat dit voor duizenden foto's rekenkundig erg zwaar is, gebruikt men voor grootschalige scènes specifieke architecturen:
Incremental: Het model wordt foto per foto opgebouwd en uitgebreid.
Global: Alle cameraposities worden in één groot wiskundig stelsel tegelijk berekend.
Hierarchical: De fotocollectie wordt opgesplitst in kleinere, lokale clusters die later worden samengevoegd.
3. Multi-View Stereo (MVS) → Dense Model Zodra de exacte posities en oriëntaties van alle camera's dankzij SfM bekend zijn, stapt men over op MVS-algoritmes. Terwijl SfM alleen de opvallende 'features' (zoals hoeken) in 3D plaatst, berekent MVS voor vrijwel elke pixel de diepte, vergelijkbaar met standaard stereovisie maar dan vanuit talloze hoeken. Het resultaat is een extreem dichte puntenwolk (dense point cloud) of een gesloten 3D-oppervlak.
Klassieke methoden hiervoor zijn bijvoorbeeld Semi Global Matching (SGM) en COLMAP.
Moderne methoden maken steeds vaker gebruik van Deep Learning (zoals MVSNet).
Moderne Toepassingen (View Synthesis) Deze SfM-fotogrammetrie vormt tegenwoordig ook de onmisbare eerste stap (het bepalen van de cameraposities) voor de nieuwste view synthesis technologieën, zoals NeRF (Neural Radiance Fields) en 3D Gaussian splatting. Hiermee kan de computer niet alleen de geometrie snappen, maar ook fotorealistische beelden genereren vanuit volledig nieuwe camerastandpunten.
Softwarepakketten Het hoofdstuk sluit af met een overzicht van software die deze gehele pijplijn (van ruwe foto's tot afgewerkt 3D-model) voor je automatiseert:
Open-source pakketten: COLMAP, AliceVision Meshroom, OpenDroneMap, OpenMVG, Visual SFM.
Commerciële software: Agisoft Metashape, Pix4D, Autodesk Reality Capture.