Statistical Inference
1/80
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
81 Terms
What are descriptive statistics and inferential statistics?
Descriptive statistics are basic summaries of observed data. Typically, it is not assumed that the observed data have originated from any probability distribution
e.g. mean, s.d., median, bar charts, histograms
Inferential statistics aims to make inference about a population from the sampled data. Typically involves assuming a probability distribution for some outcome of interest (but not always!)
e.g. confidence intervals, hypothesis testing, linear models, ANOVA
What is a parametric model and the parameter space?

What is a statistic?
e.g. sample mean, sample variance, sample maximum
T(X) is a function of random variables and so is a random variable itself
The probability distribution of T(X) is its sampling distribution.
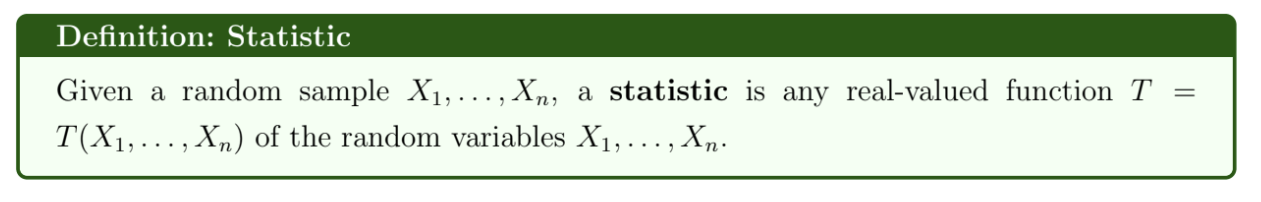
What is the estimator, estimand and estimate?
An estimator of the parameter θ is a statistic T(X) used to estimate θ. The estimator is a random variable
The estimand is the parameter θ we are trying to estimate
The estimate is the realised value of T(X), i.e. the statistic of the data actually observed
What is the likelihood function?
The likelihood function is the probability density / mass function of X, but considered to be a function of θ for fixed X
For multiple observations X, the likelihood is the joint probability density / mass function of X. If the values of Xi are independent, it is the product of their pdf/pmfs.

What is the invariance property of a maximum likelihood estimate?
If θ^ is a maximum likelihood estimate of θ and g is any function then g(θ) is a maximum likelihood estimate of g(θ)
Tips for maximum likelihood estimation
Often easier to find θ that maximises the log-likelihood function
Because the natural logarithm is a strictly increasing function, θ will also maximise the likelihood function
Take second derivatives of the likelihood to check that the likelihood has been maximised
Note that maximising a likelihood by solving a score equation only finds a local maximum - a global maximum may lie at the boundary of the parameter space
What is the score function?
The score function is the gradient of the log-likelihood function / the first derivative with respect to θ
The score equation sets the score function to zero - solve this to derive maximum likelihood estimates
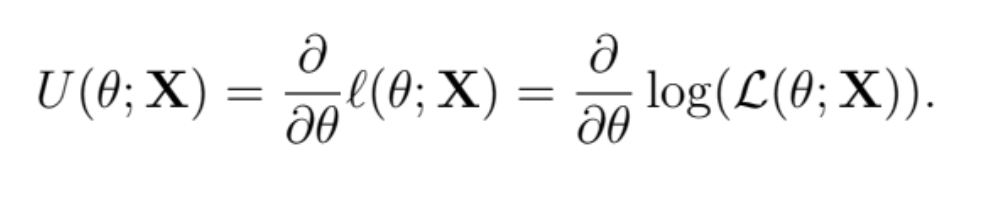
What is the likelihood principle?
Given a sample of data and an assumed statistical model, then the likelihood principle states that all information from the sample that is relevant to the model parameters is contained within the likelihood function
Moreover, two likelihood functions are equivalent if one is a scalar multiple of the other.
What is a sufficient statistic?
T(X) is sufficient for θ if the condition probability distribution of X1,…,Xn given that T(X) = t does not depend on θ
i.e f(x1,…,xn∣T(x)=t) does not depend on θ
If T(X) is sufficient for θ, then knowing more about the sample than T(X) = t is not necessary for making inference about θ
A maximum likelihood estimator (where it exists) is always a function of a sufficient statistic
What is the factorisation criterion?
The joint density can be written as the product of g and h, where g depends on θ and the sufficient statistic, but h does not depend on θ

What is the sufficiency principle?
The sufficiency principle states that if two sets of data x and y result in the same value of a sufficient statistic T (i.e. T(x) = T(y), where T is sufficient for θ) then these sets of data must lead to the same inference on θ
If T is sufficient for θ then,
Any invertible function of T is also sufficient for θ
(T, U), where U(X) is any statistic constructed using X, is also sufficient for θ
Therefore, sufficient statistics are not unique
What are minimal sufficient statistics?
A complete and sufficient statistic will also be minimum sufficient

When is a statistic sufficient in a Bayesian context?

How do Frequentist, Likelihood and Bayesian approaches to inference differ?
The frequentist approach regards the true parameter value θ as fixed but unknown. This approach involves concepts such as unbiased estimators in point estimation and significance levels in hypothesis testing. The properties of the chosen “decision function”, e.g. the point estimator or critical region, depends on the full sample space of x. e.g. if a sample mean Xˉ is unbiased for μ, this means that the expected value of Xˉ, taken over the whole sample space, is equal to μ
The likelihood approach focuses on the probability of the data actually observed and does not take the rest of the sample space into account. We focus on f(x;θ) as a function of θ over the whole parameter space, but only at the single observed data point x.
The Bayesian approach also focuses on the observed data and ignores unobserved points in the sample space. However, the parameter θ is regarded as random rather than fixed and so is assigned a probability distribution that is intended to reflect beliefs about the value of the parameter.
What is the risk function and Bayes risk?
The risk function is the expected value of a loss function
R(θ,δ)=E[L(θ,δ(X))]
The Bayes risk is the expected value of the risk, obtained by integrating the risk function over values of θ. It can be interpreted as the posterior expected loss on taking decision δ(x), given the observation x.
![<p>The risk function is the expected value of a loss function</p><p></p><p>$$R(\theta, \delta) = E[L(\theta, \delta(X))]$$</p><p></p><p>The Bayes risk is the expected value of the risk, obtained by integrating the risk function over values of $$\theta$$. It can be interpreted as the posterior expected loss on taking decision $$\delta(x)$$, given the observation x. </p>](https://knowt-user-attachments.s3.amazonaws.com/41344ee1-7bbb-408d-8408-3d8e6b483fc7.png)
What is an unbiased estimator and what is the bias of an estimator?
Unbiasedness is not invariant - if T is an unbiased estimator for θ, then g(T) is not necessarily an unbiased estimator for g(θ)

What is the mean squared error?
MSE(T;θ)=E[(T−θ)2]
MSE(T;θ)=Var(T)+(Bias(T))2
What are dominant and admissible estimators?

What is the relative efficiency of estimators?

What are weak and strong consistency?
A strongly consistent estimator converges almost surely to θ as n→∞
A weakly consistent estimator only converges in probability
Strong consistency implies weak consistency, but weak consistency does necessarily imply strong consistency

How can we show weak consistency with MSE?
If MSE(Tn;θ)→0 as n→∞
then Tn is weakly consistent for θ
This property is sufficient but not necessary for weak conssitency
What is the mean of the score function?
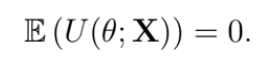
What is the variance of the score function?

What is the Fisher information?
The Fisher information is the variance of the score function
I(θ)=Var(U(θ;X))=E[(∂θ∂logL(θ;X))2]
Under certain regularity conditions (i.e. the likelihood function is continuous in θ and the domain of the density function of X (its support) does not depend on θ), we can show that the Fisher information is also given by
I(θ)=E[−∂θ2∂2logL(θ;X)]
What is the Fisher information of a transformation of θ?

What is the Cramér-Rao lower bound?
Make sure you use In(θ) !!

What is Markov Chain Monte Carlo?
In Bayesian inference, the normalising constant may not be available in closed-form - the integral is intractable.
To produce inferences about the model parameters, we do not need the formula of the posterior distribution, only some summary statistics: posterior mean, posterior median, posterior moments, posterior percentiles, standard deviation, etc. We can calculate these quantities by using a sample from the posterior.
Markov Chain Monte Carlo (MCMC) is a family of methods that can be used to sample from a posterior distribution of interests.
A Markov Chain is a sequence of random draws where each draw only depends on the previous one
Markov chains have 2 important properties
Dependence: the Markov property induces a correlation between iterations, which decreases for distant iterations of the chain
Equilibrium distribution: the chain stabilises in the long run. After a certain number of iterations, the draws represent (approximate) samples from the equilibrium distribution
Therefore, to sample from a posterior distribution, we need to construct a Markov Chain with an equilibrium distribution equal to the posterior distribution. If we are able to do so, if we run the chain for long enough, we will obtain samples from the posterior distribution
MCMC converges theoretically, however, in some cases it may take a large number of iterations to reach convergence and / or iterations might be highly correlated. Using MCMC samples that have not converged yet may induce bias in the estimators
Look at the traceplots - does it appear that the chain has stabilised?
Auto-correlation plots
Run several chains and see if they converge
What are burn-in and thinning?
The iterations before the Markov Chain has stabilised do not represent approximate samples from the (equilibrium) posterior distribution, so we should discard the first M iterations until the chain looks stable.
An appropriate number of burn-in iterations depends on the choice of the initial point and the proposal distribution.
With narrow proposal distributions it might take a long number of iterations to cover a reasonable region of the target distribution
Wide proposal distributions produce too many bad candidates that will be rejected
With bad initial points, it might take a long number of iterations to reach stability
Iterations are correlated, but this correlation decreases for distant iterations of the chain. To obtain independent samples, we need to sub-sample the chain every K iterations.
The ideal value of K depends on the autocorrelation of the samples
What is the Metropolis algorithm?
Requires
An initial point,
A density function proportional to the posterior distribution p(θ)=f(x∣θ)π(θ)∝π(θ∣x) ,
A proposal distribution g(θ∣η) with g(θ∣η)=g(η∣θ). You need to be able to simulate from this distribution. e.g. θ∣η∼Normal(η,σ2) where σ is fixed and controls the length of the steps between iterations
We do not need the normalising constant of the posterior distribution

What is the Metropolis-Hastings algorithm?
Requires
An initial point,
A density function proportional to the posterior distribution p(θ)=f(x∣θ)π(θ)∝π(θ∣x) ,
A proposal distribution g(θ∣η). It is not required that g(θ∣η)=g(η∣θ). You need to be able to simulate from this distribution
Can easily extend to the multi-parameter case if we have a multivariate proposal distribution (e.g. Multivariate normal)

What is the Gibbs sampler?
Used to sample from a posterior distribution of a parameter vector
Requires
An initial point
The conditional distributions for each parameter, given the rest of the parameters and the data. You need to be able to sample directly from these distributions

When does the variance of T(X) attain the CR lower bound?
The variance of T(X) attains the CR lower bound if and only if T(X) and U(θ;X) are linearly related such that
U(θ;X)=A(θ)(T(X)−m(θ))
The linear form must be as above so that E[U(θ;X)]=0 holds
T(X) is unbiased for m(θ) and has a variance which attains the CRLB. T is the MVBUE for m(θ).
Furthermore, it can be shown that A(θ)=m′(θ)I(θ)
So
U(θ;X)=m′(θ)I(θ)(T(X)−m(θ))
Can easily recover the Fisher information = A(θ)m′(θ) and the CRLB = A(θ)m′(θ)
When T(X) is unbiased for θ then m(θ)=θ and m′(θ)=1 , so
U(θ;X)=I(θ)(T(X)−θ)
What are MVBEs and MVBUEs?

What is the score function and variance of the score function for a vector of parameters?

What is the Cramér-Rao lower bound for a k-dimensional parameter?

What is an exponential family of distributions, for one dimensional parameters?
A family of probability distributions with a density / mass function of the form
f(x;θ)=exp{a(θ)T(x)+b(θ)+c(x)}
is said to be an exponential family of distributions
The support of X must not depend on θ
Using the factorisation theorem, we can show that T(x) is sufficient for θ.
Can rearrange to show that the score function is a linear function of T(x), so the variance of T(x) will attain the CRLB.
The likelihood of multiple X is
L(θ;x)=exp{a(θ)T(x)+nb(θ)+c(x)}
where
T(x)=i=1∑nT(xi)
and
c(x)=i=1∑nc(xi)
If a distribution is from an exponential family, then sufficient statistics for the distributional parameters are guaranteed to exist, and there exists a conjugate prior distribution for the distributional parameters
Examples of exponential families of distributions are Binomial, Poisson, Exponential, Normal, Gamma, Beta, etc.
What is an exponential family of distributions, for k-dimensional parameters?
Suppose now that θ is k-dimensional
A family of probability distributions is an exponential family if
f(x;θ)=exp{r=1∑kar(θ)Tr(x)+b(θ)+c(x)}
As in the one-dimensional case, the support of X must not depend on θ
Using the factorisation theorem, we can show that T1(x),...,Tk(x) are jointly sufficient for θ
Where the number of jointly sufficient statistics is equal to the dimension of θ , T1(x),...,Tk(x) may be expressed as linear functions of Uj(θ;X) and so estimators that are linear functions of T1(x),...,Tk(x)will have variances than attain the CRLB
What is the Rao-Blackwell theorem?
We will have equality if and only if V(X) is a function of X only through S(X).
If V(X) is unbiased for m(θ), then T(X) is also unbiased for m(θ) and Var(T(X))≤Var(V(X))
T(X) does not depend on θ because the distribution of X, conditional on S(X) does not depend on θ (since S(X) is sufficient for θ)
Essentially: if we take an estimator V(X) for m(θ) and then take the expectation of V(X) conditional on S(X), where S(X) is a sufficient statistic for θ, then we will obtain an estimator with mean squared error that is less than or equal to that of the original estimator V(X).

What is a Minimum Variance Unbiased Estimator?
The variance may not attain the CRLB - if it does, it is a minimum variance bound unbiased estimator
The minimum variance unbiased estimator is unique
If T(X) is the MVUE of m(θ), then T(X) must be uncorrelated with all unbiased estimators of 0. If an estimator is correlated with a random noise, then it can be improved.

What is the efficiency of an estimator?

What is completeness / a complete statistic?
If a statistic has a distribution that belongs to the exponential family of distributions, then the statistic is complete with respect to the unknown distributional parameters

What is the Lehmann-Scheffé theorem?

What are the general properties of maximum likelihood estimators?
A maximum likelihood estimator is necessarily a function of a minimal sufficient statistic
If an estimator, T(X), exists such that T(X) is the MVBUE of an unknown parameter θ, then T(X) is the maximum likelihood estimator of θ
If θ^ is the maximum likelihood estimate of θ, then the maximum likelihood estimate of g(θ) is g(θ^). More generally, in the multiparameter case, if we re-parameterise the likelihood function using functions of the original parameters, then the maximum likelihood estimates of our new parameters are the corresponding functions of the maximum likelihood estimates of our original parameters.
What are the asymptotic properties of maximum likelihood estimators?
Under the weak regularity conditions that
The likelihood function L(θ;X) is continuous in θ
The density / mass function f(x;θ) is such that for all x where f(x;\theta) > 0, ∂θ∂logf(x;θ) exists and is finite. In other words, the log-likelihood function is differentiable.
The order of differentiation with respect to θ and integration over the sample space X may be reversed. This is satisfied when the support of f(x;θ) does not depend on θ.
Then the following properties hold:
The maximum likelihood estimator is a strongly consistent estimator of θ P(limn→∞Tn(X)=θ)=1. It follows that the MLE is asymptotically unbiased.
The maximum likelihood estimator is asymptotically efficient: limn→∞Var(Tn(X))=I(θ)1 . If the sample size is large, the variance of the MLE is approximately equal to the CRLB. Since the MLE is also asymptotically unbiased, it follows that for large samples, the MLE is approximately the MVBUE of θ
The maximum likelihood estimator is asymptotically normally distributed: Tn(X)∼N(θ,I(θ)1) for large n: n(θ^−θ)∼dN(0,I1(θ)1)
What are the asymptotic properties of the maximum likelihood estimator of a k-dimensional parameter?

How do we choose a prior distribution?
We can specify a personal prior, corresponding with our view of the uncertainty about a parameter value, based on expert opinion or deep subject knowledge. Two observers might have two very different personal priors.
If we don’t want to use a personal prior, we can choose a prior that is quite vague, such as a uniform prior or a Jeffreys’ prior
What is a uniform prior?
A uniform or flat prior is a prior distribution where each possible value of θ is, a priori, equally likely
Can be either a discrete or continuous uniform distribution
May be an improper prior, e.g. if θ∈(−∞,∞)
What is an improper prior?
Can obtain a proper posterior from an improper prior

What is Jeffreys’ prior?
Jeffreys’ prior is
π(θ)∝I1(θ)
Note that I1(θ) is the Fisher information of a single observation - not dependent on n!
Jeffreys’ prior is invariant under re-parameterisation of θ, i.e.
π(θ)∝I1(θ)⟺π(g(θ))∝I1(g(θ))
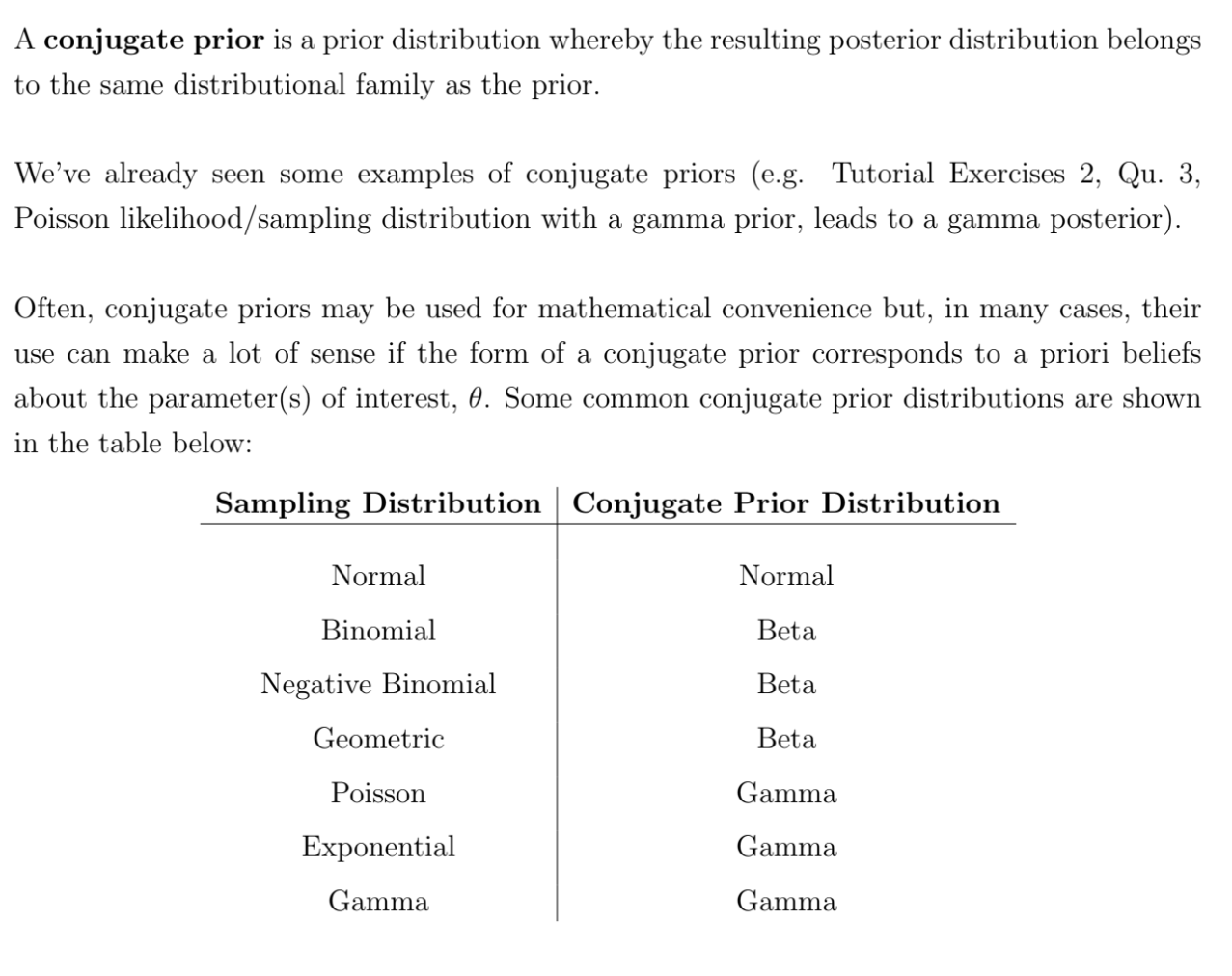
What is a conjugate prior?
A conjugate prior distribution is a prior distribution where, when combined with a given likelihood function, the posterior distribution belongs to the same family as the prior
How do we carry out Bayesian point estimation?
Let the loss incurred in using t(x) to estimate θ be the loss function L(θ,t(x))
The Bayes estimate of θ, denoted θ* is the value t = t(x) that minimises the posterior expected loss
Eθ∣x[L(θ,t)]=∫ΘL(θ,t)π(θ∣x)dθ
Notably, under quadratic error loss, the loss function is L(θ,t)=(θ−t)2 and the Bayes’ estimate is the posterior mean
What is the precision of a normal distribution?

What are simple and composite hypotheses?
A hypothesis about θ can be expressed as
H0:θ∈Θ0
If Θ0 consists of a single value, then the corresponding hypothesis is a simple hypothesis.
e.g. H0:θ=0
Otherwise, a hypothesis is a composite hypothesis
e.g. H_0:\theta>0
What is the critical region of a hypothesis test?

What are type I and type II errors, and the size and power of a hypothesis test?
There are two possible errors that could be made in a hypothesis test
Type I error: Reject H0 when H0 is true (a false positive)
Type II error: Retain H0 when H0 is false (a false negative)
The probability of a Type I error is
α(θ)=P(Type I error)=P(X∈C∣θ∈Θ0)
The probability of a Type II error is
β(θ)=P(Type II error)=P(X∈C∣θ∈Θ0)
The size / significance level of a hypothesis test is
α=supθ∈Θ0α(θ)=supθ∈Θ0P(X∈C∣θ∈Θ0)
The power of a hypothesis test is
1−β(θ)=1−P(Type II error)=1−P(X∈C∣θ∈Θ0)
What is a P-value?
For a two-sided test,
p=P\left(\left\vert{T(X)}\right\vert>t(x\right)\mid H_0)
For one sided tests,
p = P(T(X) > t(x) \mid H_0) if we reject H0 when t(x) is large
p = P(T(X) < t(x) \mid H_0) if we reject H0 when t(x) is small
In words, the P-value is the probability of observing a sample x or a more ‘extreme’ sample under the assumption that H0 is true
Conventionally,
p < 0.01 might be regarded as strong evidence against H0
p < 0.05 might be regarded as sufficient evidence against H0
These notions depend on the problem being studied and the consequences of a type I error
What are the steps of a parametric hypothesis test?

What is the power function?

What is the Neyman-Pearson Lemma?

What is a uniformly most powerful test?

What is the generalised likelihood ratio test?
Testing the null hypothesis H0:θ=θ0 against the general alternative H1:θ=θ0
Calculate sample statistic and compare to the critical value of the χ12 distribution

What is the Wald test?
Testing the null hypothesis H0:θ=θ0 against the general alternative H1:θ=θ0

What is the Score test?
Testing the null hypothesis H0:θ=θ0 against the general alternative H1:θ=θ0
Calculate sample statistic and compare to the critical value of the χ12 distribution
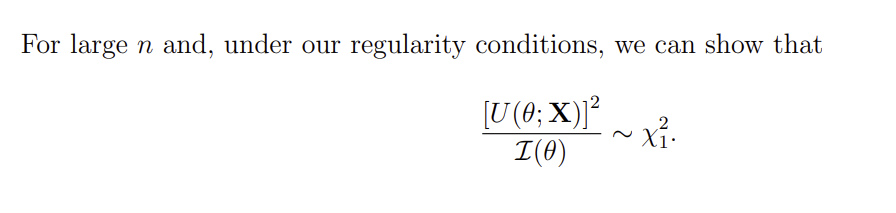
How do the Generalised Likelihood Ratio Test, Wald Test and Score Test compare?

What are the multi-parameter Generalised Likelihood Ratio Test, Wald Test and Score Test?
If θ is a k×1 vector
If our model has many parameters, we should do a single test, rather than one parameter tests on each parameter. From the 2nd test onwards, the results depend on whether the previous tests were accurate - so Type I error is inflated
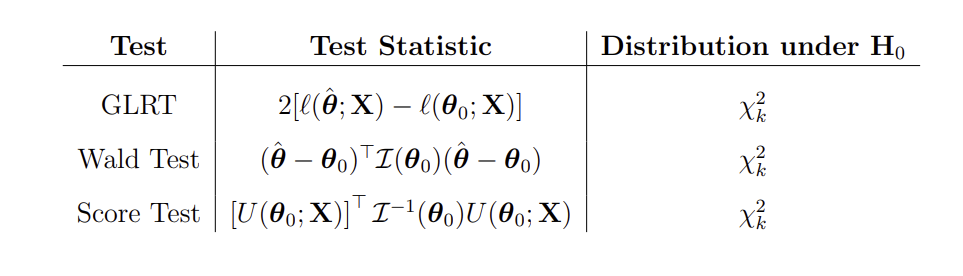
What is the relationship between likelihood ratio tests and sufficiency?

What is a further generalised likelihood ratio test?
If this likelihood ratio can be used to form a test where the distribution of a test statistic is known exactly, then we would use this instead of the asymptotic chi-squared approximation - e.g. t-tests and F-tests

What is a confidence interval?
Can obtain a confidence interval for θ by using the distribution of an unbiased estimator of θ, e.g. Xˉ for μ
There are infinitely many valid 100(1−α)% confidence intervals.
We may want the tails to have equal probability (central confidence interval) or the interval to be as narrow as possible

What is a pivotal quantity?

What are common pivotal quantities for the normal distribution?

What is the relationship between confidence intervals and hypothesis testing?
There is a direct relationship between a 100(1−α)% confidence interval and a size α hypothesis test. If the sample x would result in the null hypothesis H0:θ=θ0 being retained in a test of size α, then θ0 lies within the corresponding 100(1−α)% confidence interval constructed using x, and vice versa.
x∈A(θ0)⟺θ0∈B(x)
where A is the acceptance region and B is the confidence interval
How can we construct a confidence interval based on the maximum likelihood estimator?
This is an approximate confidence interval

What is a confidence region / set?

How can we construct a confidence interval using the probability integral transform?
Suppose that we have X1,…,Xn with X∼D(θ), where T(X) is sufficient for θ, and T(X) is a continuous random variable with CDF:
F(t,θ)=P(T(x)≤t∣θ)
If we define the random variable
U(T(X),θ)=F(T(X),θ)
then U(T(X),θ)∼U[0,1], and hence U(T(X),θ) is a pivotal quantity
Since T(X) is a continuous random variable and F(t,θ) is a strictly increasing function of t, then F−1 exists
Because U(T(X),θ) is a pivotal quantity and the CDF of U is known, we can re-arrange the CDF to obtain a confidence interval
How do we carry out Bayesian Hypothesis Testing?
For simple hypotheses, if the losses are constant (do not depend on θ) we can see that the Bayesian hypothesis test procedure results in a likelihood ratio test

What is a Bayesian credible region?
There are many possible choices for a 100(1−α)% confidence interval. We might choose the most narrow interval, or the central credible interval.
If X1,…,Xn are independent and identically distributed and our usual regularity conditions are satisfied, when n is large, our posterior distribution is approximately
θ∣x∼N(θ^,I(θ^)1)
We can use this to obtain a credible region when n is large

What does ∼˙ mean?
Approximately distributed
What are the differences between confidence intervals and credible intervals?

What is the relationship between I1(θ) and In(θ)?
If the samples are iid
In(θ)=E[−∂θ2∂2logf(X;θ)]=E[−i=1∑n∂θ2∂2logf(xi;θ)]
=i=1∑nE[−∂θ2∂2logf(xi;θ)]=i=1∑nI1(θ)=nI1(θ)
What is the Karl-Rubin theorem? (No longer in course)
