Data Warehousing Vocabulary Practice
1/31
Earn XP
Description and Tags
Comprehensive vocabulary flashcards covering Data Warehousing definitions, features, processing types, architectural approaches (Inmon vs. Kimball), and schema designs (Star vs. Snowflake).
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
32 Terms
Data Warehousing
A collection of data that helps an analyst to make informed decisions in an organisation.
OLAP
OnLine Analytical Processing tools that allow us to analyse data in a multi-dimensional space, resulting in data generalisation and data mining.
Subject-oriented
A feature of a data warehouse focusing on modelling and analysis of data around a specific subject rather than ongoing operations.
Integrated
A feature of data warehouses constructed by combining data from many different sources such as relational databases or flat files.
Time-variant
A feature where the data collected in a warehouse is identified with a particular time period.
Non-volatile
A feature where previous data is not erased when new data is added to the data warehouse.
Information Processing
A type of warehouse processing that deals with querying, basic statistical analysis, and reporting using crosstabs, tables, charts, or graphs.
Analytical Processing
Processing of information using OLAP operations such as slice and dice, drill down, drill up, and pivoting.
Data Mining
Knowledge discovery by finding hidden patterns and associations, constructing analytical models, and performing classification and predictions.
Enterprise Data Warehouse (EDW)
A data warehouse environment that services an entire enterprise. May have a operational data store and physical and virtual data marts
Data Marts
Subsets of data used by individual departments or groups, often building on a dimensional data model.
Operational data store
A hybrid form of data warehouse containing integrated information from many different databases.
Update Driven Approach
An alternative approach where information from multiple heterogeneous sources is integrated in advance and available for direct query. Have high performance and data is copied, processed, integrated, annotated, summarised and restructured in semantic data stores in advance
Data extraction
The warehouse tool function of gathering data from many different sources.
Data cleaning
The warehouse tool function of finding and correcting data errors.
Data transformation
The warehouse tool function of converting source data into the specific data warehouse format.
Metadata
Known as 'data about data', it defines warehouse objects and acts as a directory to help locate the contents of a data warehouse.
Normalisation
A process for converting complex data structures into simple and stable data structures with minimal redundancy, often categorized as 3NF or 4NF.
Inmon Approach
A Top-Down approach to data warehouse design that utilizes entity relationship modelling and normalisation. Time, cost and maintenance are high
Kimball Approach
A Bottom-Up approach to data warehouse design that focuses on dimensional modelling to allow for different individual models of interest. Time, cost and maintenance are low
Denormalisation
A data structure using fewer tables to group data; it offers better performance when reading data for analytical purposes by reducing query complexity.
Fact Tables
Tables that contain the measurements of a business, such as sales, purchase orders, or shipment information.
Dimension Tables
Tables that store descriptions of the dimensions of the business, such as products, customers, vendors, or stores.
Transaction Fact Tables
A type of fact table used to record information related to specific events, such as individual product sales.
Snapshot Fact Tables
A type of fact table that records information applying to specific moments in time, such as year-end accounts.
Surrogate primary keys
A single column integer related to a natural primary key used to map fact tables to specific rows in dimension tables.
Star Schema
A schema where the fact table connects all information sources by pulling data from dimension tables and duplicating it to simplify queries.
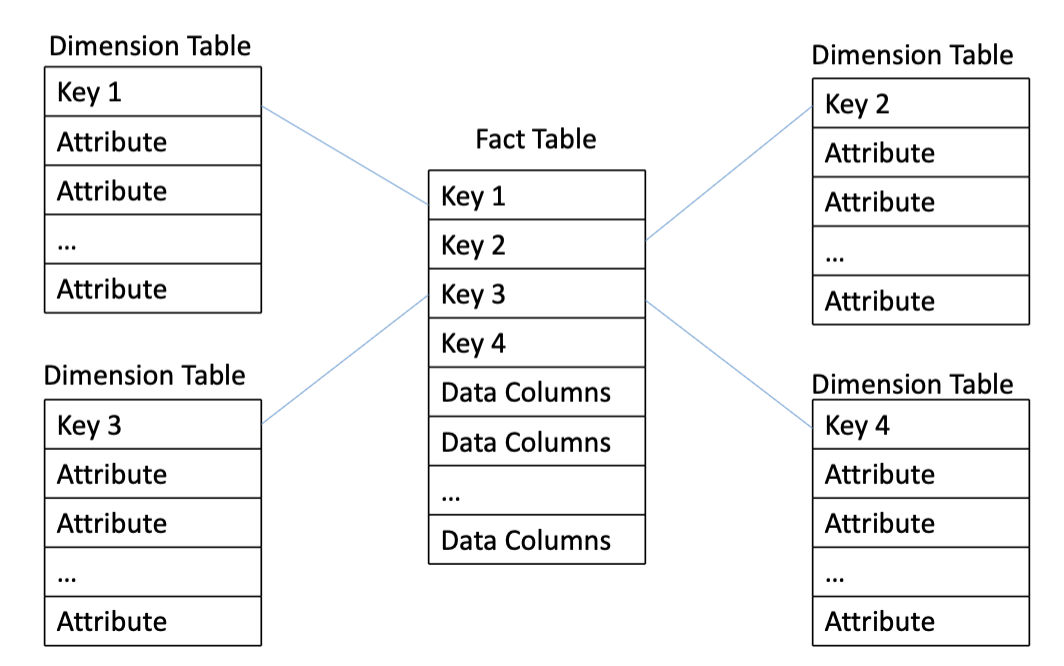
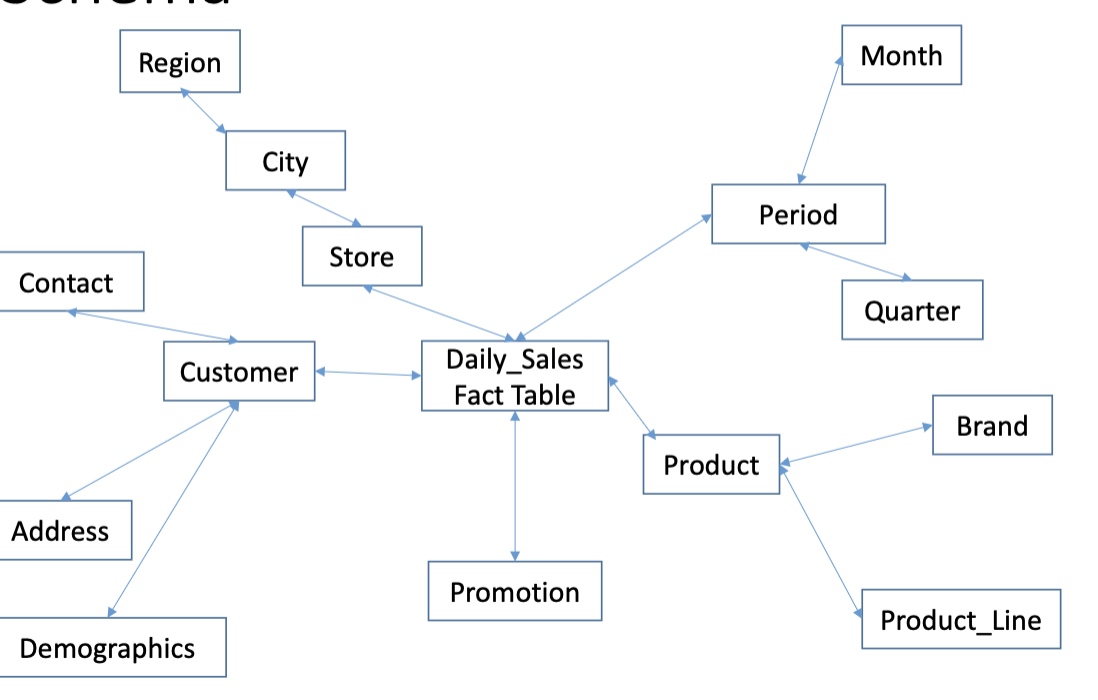
Snowflake Schema
A multi-dimensional structure that normalises data within a star schema, splitting dimension tables into a series of normalised tables. Has more complex queries as they need to dig deeper
Process flow
Extract and load data
Clean and transform data
Backup and archive data
Manage queries and direct them to appropriate data source
Benefits of star schema
Is denormalised, thus queries are simpler as data connects though fact tables. Removes the bottleneck of normalised schema, used OLAP cubes.
Challenges of star schema
Decreased data integrity due to denormalisation, can’t handle complex queries and no many to many relationships as schema is too simple
Accumulating snapshot tables
Records information running tally of data - year to year sales figure