Yacine AWS AI Practicioner - Section 3: Amazon Bedrock
1/31
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai | Chat |
|---|
No analytics yet
Send a link to your students to track their progress
32 Terms
1. What is Amazon Bedrock?
Amazon Bedrock is a fully managed AWS service for building generative AI applications using foundation models through a unified API. It removes infrastructure management and provides secure, scalable access to multiple third-party and AWS models.
2. What problem does Amazon Bedrock solve?
Bedrock allows teams to use powerful foundation models without managing GPUs, training infrastructure, or model hosting. It simplifies model access, governance, and scaling while keeping customer data private.
3. What types of models are available in Amazon Bedrock?
Amazon Bedrock provides access to text, image, and multimodal foundation models from multiple providers, including Amazon (Titan), Anthropic (Claude), Meta (Llama), and image models like Stable Diffusion (stability.ai).
- Titan (8k tokens, 100+ languages, content creation/classification, cheapest)
- LLAMA (4k tokens, dialogue, English, customer service, 2nd cheapest)
- Claude (200k tokens [book], multi-language, large text gen, analysis/forecasting/doc comparison, 3rd cheapest)
- Stable Diffusion (77 tokens, image gen, 4rd cheapest)
4. What are Amazon Titan models?
Amazon Titan models are high-performance foundation models built by AWS.
They support text generation, embeddings, and multimodal use cases and can be customized with customer data inside Bedrock.
5. How does Amazon Bedrock handle customer data?
Customer prompts and data are not used to train base foundation models.
Bedrock creates isolated copies of models for customers, ensuring privacy and data separation.
6. What is the Amazon Bedrock Playground?
The Playground is an interactive interface to experiment with foundation models.
It allows users to test prompts, compare model behavior, and evaluate outputs before integrating models into applications.
7. What does “unified API” mean in Amazon Bedrock?
A unified API means developers can switch between different foundation models without changing application logic.
This reduces vendor lock-in and simplifies experimentation and optimization.
8. What is fine-tuning in Amazon Bedrock?
Fine-tuning in Bedrock adapts a foundation model by updating its weights using customer-provided training data stored in Amazon S3.
It improves domain-specific performance but requires additional cost and provisioned throughput.
9. What are the requirements for fine-tuning in Bedrock?
Training data must follow a specific format and be stored in Amazon S3.
Not all foundation models support fine-tuning, and fine-tuned models must use provisioned throughput.
10. What is Retrieval-Augmented Generation (RAG) in Bedrock?
RAG in Bedrock allows models to retrieve external information at inference time.
Bedrock automatically creates embeddings and queries a vector database to inject relevant data into the prompt.
11. What is an Amazon Bedrock Knowledge Base?
A Knowledge Base is a managed RAG feature that connects foundation models to external data sources.
It handles document ingestion, chunking, embedding creation, and retrieval automatically.
You can also use custome AWS Lamba/step function
AWS Bedrock > Builder tools > Knowledge Bases
- Chat with a FM to try
- Create a KB
- Test the KB
- Use the KB
12. What data sources can be used with Bedrock Knowledge Bases?
Common data sources include Amazon S3, Confluence, Microsoft SharePoint, Salesforce, custom, and web pages.
Bedrock continuously uses these sources to provide up-to-date responses.
13. What vector databases are supported for RAG in Bedrock?
Bedrock supports vector storage using:
- Amazon OpenSearch Service
- Amazon Aurora
- Amazon Neptune
- Amazon Kendra
- Amazon DocumentDB
- Amazon MemoryDB
- Amazon S3 vector
- Amazon RDS for PostgreSQL
- Redis
- Pinecone
14. When should you use RAG instead of fine-tuning in Bedrock?
Use RAG when data changes frequently, must remain external, or needs real-time updates.
Fine-tuning is better when adjusting model behavior, tone, or task performance.
15. What are Amazon Bedrock Guardrails?
Guardrails control interactions between users and foundation models.
They filter harmful content, remove PII, enhance privacy, reduce hallucinations, restrict usage of your FM by your users, and enforce compliance and responsible AI policies.
16. What problems do Guardrails help prevent?
Guardrails help prevent unsafe outputs, data leakage, policy violations, and hallucinations.
You can create multiple Guardrails and monitor/analyze user inputs that can violate the Guardrails.
17. What are Amazon Bedrock Agents?
Agents are managed components that enable foundation models to perform multi-step tasks. They can plan actions, call APIs, query databases, and retrieve knowledge using RAG.
Amazon Bedrock automatically assigns the agent to a task, because it knows agent capabilities.
18. How do Bedrock Agents interact with other AWS services?
Bedrock Agents interact with AWS services through orchestrated integrations. They can invoke Lambda functions, call APIs defined with OpenAPI schemas, query databases, and retrieve information from Knowledge Bases. This enables agents to execute multi-step workflows by passing context and results between service interactions.
19. What is the difference between Bedrock Agents and chatbots?
Agents go beyond simple conversation by executing actions and workflows. Chatbots generate text responses, while agents can perform tasks like placing orders or querying systems.
20. How does Amazon Bedrock support model evaluation?
Bedrock supports automatic model evaluation using built-in metrics (toxicity, accuracy, robustness) by using available datasets or your own prompts, as well as human evaluation using subject-matter experts or internal teams.
21. What is automatic model evaluation in Bedrock?
Automatic model evaluation scores model outputs using predefined tasks and statistical metrics such as ROUGE, BLEU, and BERTScore. It is fast and scalable but limited in nuance.
22. What is human evaluation in Bedrock?
Human evaluation relies on people to assess output quality using criteria like accuracy, relevance, and bias. It is slower and more expensive but provides deeper insights.
23. How does Amazon Bedrock integrate with CloudWatch?
Bedrock publishes logs and metrics to Amazon CloudWatch. This includes the model invocations (input/output) logs, text, images, embeddings, filtered content counts, and performance metrics for monitoring and alerting.
24. What is CloudWatch Logs Insights?
To build alerting, analyze logs in real time, full tracing and monitoring of Bedrock.
It's a UI with a box where you can enter queries (like DQL queries in Dynatrace) to fetch logs and apply functions like "filter" or whatever you want to do.
25. What are CloudWatch Metrics?
- Send metrics from Bedrock to CloudWatch
- Monitor FM
- Monitor Guardrails using metrics like ContentFilterCount (how many times a content was filtered)
- Build alarms when something is caught by Guardrails, Bedrock exceeds threshold, etc.
26. What are the pricing models for Amazon Bedrock?
Bedrock offers:
1. On-demand pricing (pay per token or image)
2. Batch inference for cost savings (in S3)
3. Provisioned throughput (max. nb. of input/output tokens processed per min.) for reserved capacity (1 month, 6 months, etc.) and fine-tuned models.
Temperature, Top K, Top P -> no price impact
Model size -> usually smaller model = cheaper
Number of Input and Output Tokens : main driver of cost
27. Is Amazon Bedrock a replacement for Amazon SageMaker?
No. Bedrock is optimized for using and customizing foundation models, while SageMaker is a full ML platform for building, training, and deploying custom models end-to-end.
28. Which AWS services can be used as Vector DB, and which external options?
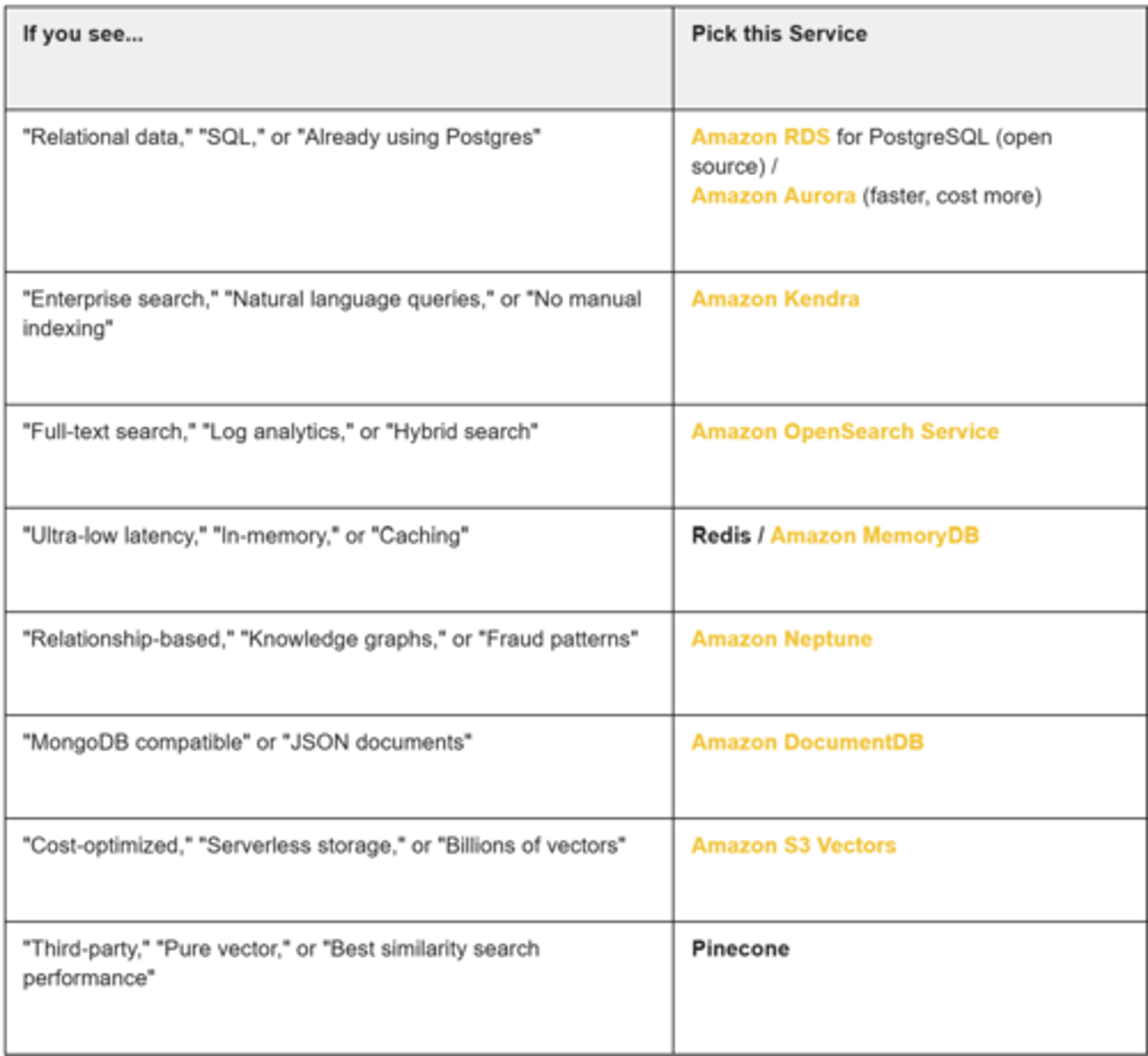
28.1 What happen if you don't specify a Vector DB on Knowledge Base?
If you don’t specify anything, AWS is going to create for you an OpenSearch Service serverless DB.
29. BONUS - Bedrock
IAM with Bedrock
- Implement identity verification and resource-level access control
- Define roles and permissions to access Bedrock resources (e.g., data scientists)
GuardRails for Bedrock
- Restrict specific topics in a GenAI application
- Filter harmful content
- Ensure compliance with safety policies by analyzing user inputs
CloudTrail with Bedrock: Analyze API calls made to Amazon Bedrock
Config with Bedrock: look at configuration changes within Bedrock
PrivateLink with Bedrock: keep all API calls to Bedrock within the private VPC
30. What is OpenAPI?
OpenAPI is a standardized set of rules and information that describes how APIs work, enabling machines and Gen AI to understand and interact with them.
What is AWS AgentCore?
It's a framework-agnostic and model-agnostic fully AWS manged service, letting you deploy agents built with any framework (like LangGraph, CrewAI, Strands Agents) and any LLM. AgentCore handles monitoring, observability, security, and helps you evaluate agent quality across criteria like correctness, helpfulness, safety, and goal success.
Think of AgentCore as the production infrastructure for AI agents—it eliminates the tedious setup work (servers, monitoring, security, scaling) so you can focus on building the agent logic itself. You write the agent code, AgentCore handles deploying it reliably and at scale.