Artificial Intelligence Lecture Notes Review
1/21
Earn XP
Description and Tags
These vocabulary flashcards contain key terms and their definitions based on the lecture notes on Artificial Intelligence, covering concepts from machine learning to neural networks.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
22 Terms
Supervised Learning
The process of finding a mathematical function that maps the input features to a specific output through function approximation.
We try to learn y through inputs of X through function approximation
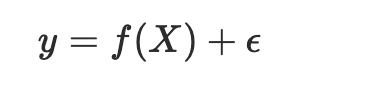
Hypothesis Set (H)
A group of functions or models considered to map features to outputs, chosen based on assumptions about the target function.
options of hypothesis: random forest, logreg, neural… to help us find f that is closes to the real f.
is an assumption about the world before seeing the data
H is the hyothesis set, h is the one we would choose
Linear Separators
assume a function form between X and y. they partition the space with a straight line.
some relationships between X and y can be more complex than this thats why we use ensemble or neural
Decision Trees
Model that partitions the feature space into axis-aligned rectangles based on attributes.
also used for more complex models
also for models with high variance (they can overfit the training set)
also for models sensitive to small variations
Ensemble Learning
Combining multiple models to create a more powerful, stable model by aggregating their predictions.
combining weak learners to create a single, more powerful models.
outputs higher accuracy and stability
by training different versions of data, individual errors are cancelled out.
Bagging
target is reducing variance > more stable output because collective opinion won’t shift due to outliers.
choosing dataset rows with replacement: so same rows can be chosen and some wouldn’t get choosen at all (1/3). (OOB)
Why use?
creates diversity: bootrapped versions of the data, each learn slightly different versions of the data.
reduces variance: different versions of individual errors will cancel each other when you take them as a whole)
done in the training phase of the data
m=p
Out Of Bag
the 1/3 unchosen set of data in the boostraping with replacement method.
trees never see this data during the training. we use this data to estimate the performance without the need for cross validation.
steps:
obtain predictions for each instance 1/3 will be OOB prediction
for each instance, average all 1/3. and let OOB vote on decision
estimation of error metrics. compare OOB error metrics with actual error metrics
bc.oob_score_
accuracy_score(y_test, y_pred)
steps and final prediction of bagging
generate the set of k (number of instances) of training set through bootstrapping with replacement
train unrpruned tree (captures every detail and random noise, memorizes everything, likely will overfit without ensemble) on each of the k datasets. each tree has low bias but high variance
final prediction: if regression: calcualte the average of all predictions and if classification: perform a majority vote.
wisdom of the crowd: by combining trees, we are averaging out random errors. more stable and higher performance.
Random Forest
An ensemble method that adds extra randomness by sampling a subset of features at each split to avoid high correlation and overfitting.
m = sqrt(p)
at each split of tree, extra random subset of m = sqrt(m)
if one features is very strong, better than bagging. more diverse and decorrelated set of data. because hides features randomly so forces to find different patterns.
worse individual trees but better forest.
node is split that maximizes information gain
Boosting
A technique of training models sequentially, where each model focuses on correcting the errors made by the previous ones.
reduces bias !!!!
starts weak and specializes the errors of the previous one.
instead of targeting labels (X, y), each tree is fit the residuals of the prior trees. (X, r)
Boosting steps
set f(x) = 0 and r = y for all instances. start with a model that predicts 0 for all.
fit f to (X,r) > target is residuals not y. train tree on the data. so tree will train to predict on the residuals, not the target data.
update f, add prediction of the new trees to the model.
output is the: weighted average of all the trees iteratively built.
when model does good, residuals decrease.
AdaBoost
A boosting method for classification which adjusts the weights of misclassified instances for subsequent classifiers.
sensitive to noise
rather than target labels, changes the weights of each instance.
missclasified tree has higher weight.
final classifier is weighted average of all classifiers.
alpha : depends on predictors error, the weight.
model evaluation
evaluation if our model is good enough, and is helpful to the problem we are trying to solve.
is the prediciton relevant?
construction gap
disconnect between the complex, real world goal and the quantifiable data actually available to train a machine learning model.
for ex: construction of interest: health needs, observed outcome: heath cost. consequence: can result in racial bias if spending patterns differs by race.
error decomposition
breaking down the error, to see where is it coming from. and each type of error has o dealt differently so important to know where is it coming from.
error = bias² + variance + irreducible error
bias
Clustering
An unsupervised learning technique to discover hidden structures or subgroups in a dataset.
K-Means
An algorithm that partitions data into K clusters by minimizing within-cluster variation.
DBSCAN
A clustering method that identifies clusters based on the density of data points.
Neural Network
A supervised learning algorithm designed to approximate complex functions using interconnected layers.
Activation Function
A function applied by a neuron in a neural network to introduce non-linearity, common examples are Sigmoid and ReLU.
What is weak learner?
model doing slightly better than random guessing.