multivariate analyse deel A
1/44
Earn XP
Description and Tags
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai | Chat |
|---|
No analytics yet
Send a link to your students to track their progress
45 Terms
univariate technieken, bivariate technieken en mulitvariate technieken
univariate technieken: beschrijvende statistiek
bivariate technieken: verband tussen 2 variabelen
multivariate technieken: verband tussen meerdere variabelen.
absolute variabele
volledige informatie → telbaar → aantal delicten
onafhankelijke variabele vs afhankelijke variabele
onafhankelijk: variabele(n) die je gebruikt om de afhankelijke variabele te voorspellen
afhankelijk: variabele waar jeiets over wil weten
model fit en parsimonie
hoe goed beschrijft het model de werkelijkheid (data)
Simpel model met zo min mogelijk variabelen heeft de voorkeur → fitmaten revisited: sommige fitmaten ‘straffen’ voor complexiteit
Maten voor centrale tendentie en maten voor spreiding
modus: meest voorkomend
mediaan: middelste getal
gemiddelde
range: min en max bereik
Variantie: S2 → gem som van afwijkingen2
standaarddeviatie: hoeveel wijkt men af van M
inferentiële statistiek
gebruikt steekproefdata om conclusies te trekken over een gehele populatie
Lakmoesproef: heeft ieder lid van de populatie een gelijke kans om in de steekproef terecht te komen
Mx (steekproefgemiddelde) zuivere schatter van mx (populatiegemiddelde), mits steekproef random uit populatie getrokken.
betrouwbaarheidsintervallen: marge om een puntenschatting heen, geeft weer hoe zeker je bent van je schatting. Z
Toetsen:
H0: veronderstelling over werkelijkheid
H1: alternatieve hypothese, kans op H0 is klein
type I fout (toestand = H0, maar beslissing H1)
type II fout (toestand = H1, maar beslissing = H0)
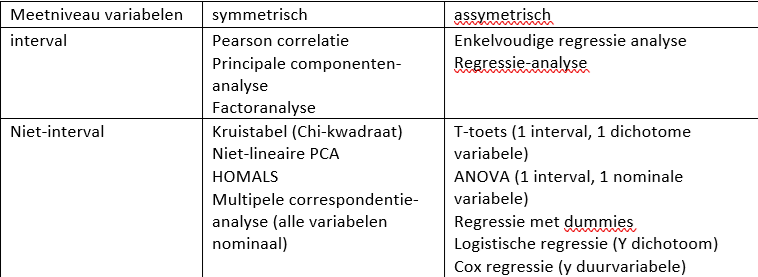
symmetrisch vs asymmetrische techniek
symmetrisch: alle variabelen zijn gelijk
assymetrisch: er is een afhankelijke en een onafhankelijke variabele
data cleaning
Typo's
Uitbijters: zorgen voor vertekeningen
Altijd inspecteren
Analyse met en zonder uitbijters draaien
Bij weglaten altijd rapporteren
Kunnen univariaat of multivariaat zijn
zorgen voor slechte fit of vertekeningen → leverage/koevoet-effect
Onmogelijke combinatie (zwangere opa's): iemand van 4 jaar die veroordeeld is
Missings:
listwise deletion: respondent met missende waarde wordt verwijderd
Probleem: dataverlies (dus verlies in respondenten) vertekening
Imputatie -> geavanceerde methode van opvullen. Hiervoor onderzoeken wat voor missing het is.
Hercoderen, transformeren en somschalen:
Wat te doen met scheef verdeelde variabele?
Wortel/logaritmisch transformeren of variabele terugbrengen tot kleiner aantal
Variabelen samennemen
soorten missings
MCAR (Missing Completely at Random): geheel toevallig proces
MAR (Missing at Random): niet toevallig voor de onafhankelijke variabelen. Geen afwijkingen op de afhankelijke variabele
MNAR (Missing Not at Random): niet toevallig voor de afhankelijke variabelen bijv. respondenten met een specifiek hoog recidiverisico
missings toetsen
MCAR (Missing Completely at Random):
geen verband met afhankelijke of onafhankelijke varaibelen
Als Little-test niet significant is
Listwise deletion MLE
MAR (Missing at Random):
Geen verband met afhankelijke , wel verband met onafhankelijke variabelen
Als T-Toets niet significant is
MLE, Multiple imputation
MNAR (Missing Not at Random)
verband met afhankelijke variabele en verband met onafhankelijke variabele
als T-Toets significant is
Multiple imputation
Repliceerbaarheid
Je moet gedurende ‘een voor de discipline gebruikelijke termijn’ na je onderzoek je resultaten kunnen reproduceren
Wat is gebruikelijk in de criminologie? 5 jaar wordt veel genoemd…
Werk met SPSS syntax! Met commentaar (omdat je het na 4 jaar niet meer weet...)
regressie
a = intercept → startpunt meestal niet geïnterpreteerd
b = hellingshoek → geïnterpreteerd als ‘toename’- een stapje x geeft een toename ter grootte van b. dit is ongestandaardiseerd gewicht = schaalafhankelijk, dus inhoudelijk te interpreteren
e = errorterm/voorspelfout, verschil tussen echte en voorspelde Y
multicollineariteit en gestandaardiseerde bèta
twee onafhankelijke variabelen voorspellen (deels) hetzelfde, er is hiertussen een sterke onderlinge samenhang
bij berekenen gestandaardiseerde b worden regressiecoëfficiënten andere variabelen meegenomen → bij berekening van de ene regressiegewicht wordt rekening gehouden met de ‘overlap’ van twee variabelen
‘gegeven de overige variabelen in het model’
multipele regressie steekproefgrootte
Vuistregel is dat per variabele er minstens 10 respondenten moeten zijn.
bij te veel variabelen → meer risico multicollineariteit en gecompliceerd model tegen weinig winst
wel zo goed mogelijke fit → daarom gebruiken we ‘penalty’ fit maten → adjusted R2 straft voor te veel variabelen, houdt rekening met toevallig verklaarde variantie (k = aantal X-variabelen)
multipele regressie assumpties
X en Y interval
lineair verband tussen X en Y: inspecteer scatterplot
X is fixed (de categorieën van X zijn door onderzoeker gekozen, robuust tegen schending) en Y is random
errortermen/voorspelfouten zijn
onderling afhankelijk: beredeneren of testen met Durbin_watson statistiek (ligt tussen 0 en 4, idealiter rond de 2)
normaal verdeeld → normaliteit: maak histrogram van residuen, normaalverdeling toetsen → alleen bij kleine steekproeven en grote afwijkingen zorgen maken. Kolmogorov-Smirnov toets
homoscedastisch: inspecteer scatterplot van Y tegen error.
Uitbijters
score van 3 standaarddeviaties
inspectie van diagnostische plot met de gestandaardiseede voorspelde y-waarden tegen de gestandaardiseerde residuen.
DFBeta’s geven aan per respondent hoeveel de voorspelling van de regressiecoëfficiënten veranderen als deze respondent verwijderd wordt.
leverage/koevoet-effect: uitbijter heeft disproportioneel grote invloed op de oplossing, domineert deze zelfs. waarden hiervan kan je uitdraaien
soorten regressiemodel
ENTER → procedure gebruikt alle variabelen die je opgeeft
BACKWARD → procedure begint met alle variabelen en verwijdert variabelen die niet bijdragen (standaard p>.10)
FORWARD → procedure begint met 1 variabele en voegt variabelen toe die de voorspelling verbeteren (standaard p<.05)
STEPWISE → variant van backward of forward, waar gaande het iteratieve proces eerder toegevoegde / verwijderde variabelen alsnog verwijderd/toegevoegd kunnen worden
stapppenplan
missing values
Y normaal verdeeld: nee → waarden transformeren (wortel of log), gewone regressieanalyse en kijken of het problemen oplevert
correlaties: kijken voor multicollineariteit
regressie analyse-toetsing
controle op assumpties
T-toets bij missing values
T-toets om te vergelijken of personen met missings afwijken van personen zonder missings. Geen significante verschillen? MAR of MCA
Little’s MCAR test
niet significant dan MCAR en kunnen we de geïmputeerde waarde van variabele gebruiken.
interactie-effect
Als het voor het effect van de ene variabele uitmaakt wat voor waarde de andere variabele heeft.
belangrijk te interpeteren anders hou je geen rekening met ‘differentiële effecten → betere duiding van relaties, voorkomen verspilling
voorwaarden causaliteit
X gaat vooraf aan Y
X correleert met Y
er is geen andere verklaring voor de samenhang tussen X en Y
logistische regressie
afhankelijke variabele is dichotoom
niet Y voorspellen maar de logit van de kans op Y voorspellen
logit → natuurlijke logaritme van de odds
voorspellen functie van Y die alle mogelijke waarden tussen min oneindig en plus oneindig kan aannemen.
Er is geen probleem dat schattingen van de ofhankelijke variabele ongeresticteerd zijn
Gaat voor iedere groep respondenten met covariate pattern proberen te voorspellen welk percentage 1 scoort op y (p-waarde, propensity score)
overall F-toets
overkoepelende toets voor de significantie van alle regressie gewichten tegelijk.
covariate patterns
combinaties van scores op onafhankelijke variabelen -. man en depressief, vrouw en depressief, man en niet depressief etc.
modelfit logistische regressie
Likelihood ratio test (‘hardste criterium’)
classificatietabel
Hosmer-Lemeshow chi-kwadraat
Nagelkerke R2
hoe e-macht regressiegewichten logistische regressie interpreteren?
interpreteren als odds ratio → vertelt hoeveel groter het risico op y is voor iemand met score k+1 op die variabele ten opzichte van iemand met score k, gegeven de overige variabelen in het model.
kan niet gestandaardiseerde b gebruiken want dat geeft aan hoeveel bij verandering op de X de log odds van Y verandert.
Odds ratio → exp(B)
Wald-test
Onderzoekt bij logistische regressie of individuele predictoren bijdragen door te meten of de waarden van de regreissiecoëfficiënten significant van 0 afwijken
is chi-kwadraad verdeeld
bij grote effecten kan de toets de standaarddeviateis van de regressiegewichten veel te groot schatte, waardoor de toest niet meer significant uitvalt → likelihood ratio test uitvoeren.
t-toets bij multipele regressie-analyse
Onderzoekt of individuele predictoren bijdragen door te meten of de waarden van de regreissiecoëfficiënten significant van 0 afwijken
odds ratio’s uitkomsten mbt gestandaardiseerde b
b1 > 0 dan eb1 > 1
b1 = 0 dan eb1 = 1
b1 < 0 dan eb1 < 1 (maar nooit kleiner dan 0)
Likelihood ratio test
Kans op onze dataset met de gevonden waarden van a, b1, b2 etc.
-2log likelihood (‘-2LL’) want χ2 verdeeld met aantal vrijheidsgraden gelijk aan aantal geschatte parameters. Zo kan je fijn toetsen of modellen significant van elkaar verschillen.
Log(L0) = model waar de score van iedereen wordt voorspeld met behulp van gemiddelde score. Heeft df = 1 want gelijk aan aantal geschatte parameters.
log(L1) = model met 2 predictoren is chi-kwadraat verdeeld met 3 vrijheidsgraden (intercept, b1 en b2).
verschil in -2LL is chi-kwadraat verdeeld met vrijheidsgraden gelijk aan parameters model 1 - parameters model 2
kan alleen modellen vergelijken die genest zijn (model met x1 en x2 is genest in model x1, x2, en x3).
Akaike Informatie Criterium (AIC)
Als modellen niet genest zijn en er dus geen gebruik gemaakt kan worden van de likelihood ratio test.
AIC = -2log(l1)+2c met c aantal geschatte parameters
model met laagste AIC waarde heeft de voorkeur → straft voor complexiteit (vergelijk Adjusted R2)
meet niet significantie
classificatietabel
kruistabel wargenomen scores op de y-variabele, en de classifiactie van respondenten in de 0- of 1-categroie volgens de voorspellingen van het model.
ondergrens is 75% dat je met toeval zou kunnen krijgen, het voorspelt substantieel beter als er ongeveer 81,25% heeft.
Nagelkerke R2
pseudo R2
indivatie van de sterkte van samenhang ussen de set predictoren en de afhankelijke variabele.
Grove indicatie voor proportie verklaarde variantie. Het is geen amat voor de verklaarde variantie an sich, heeft hij heeft er wel enig relatie mee.
Hosmer Lemeshow test
bepalen in hoeverre de daadwerkelijke verdeling van respondenten over de kans op ‘1’op de afhankelijke variabele overeenkomst met de geschatte verdeling van die kans.
eerst respondenten ordenen op propensity score, respondenten in rijen verdelen. Dan splitsen naar y=0 en y=1, Mensen met lage propensity score vooral in de y=0 groep.
veel correspondentie → goede schatting, chi-kwadraat moet bij deze test NIET SIGNIFICANT zijn
assumpties logistische regressie
X interval (of ratio) meetniveau → beredeneerd
lineair verband X en log odds Y → beredeneerd
X fixed en Y random → beredeneerd
errortermen
onafhankelijk → beredeneerd
binominaal verdeeld → geen probeem bij N>300
DUS: in praktijk assumpties niet getoets
overlevingsduur-analyse
meten van het effect van diverse onafhankelijke variabelen op de overlevingsduur.
respondent heeft een zeker risico, hazard om een gebeurtenis meet te maken
problemen:
censurering: iemand valt uit en kan niet meer gemeten worden
y is speciale soort variabele
Kaplan Meier
afbeelding van de censurering, rekening houdend met censurering
mogelijk om te toetsen of er verschillen zijn tussen subgroepen (man/vrouw) → toetsen of de curves significant zijn dmv log rank test.
cox regressie
meerdere x-een of meerdere continu/interval x-en
model voor hazard
hazard
risico om een gebeurtenis mee te maken, heeft verband met ‘overleving’: mensen met een grote hazard kleinere kans op ‘overleving’
gebonden aan persoon, tijd en type gebeurtenis
interpretatie: tijd tot volgende ‘event’ of hoeveel gevallen van ‘event’ in tijdseenheid
constante hazard: constant risico
tijdsvariërende hazard: toenemend of afnemend risico met de tijd
cox regressie
model voor hazard
hi(t) = lapda0(t)*e^(gestandaardiseerd b1*x1 + etc)
lapda0(t) blijft ongespecificeerd, is vaak 1
pakken niet hazard zelf als afhankelijke variabele, maar de ratio van de hazard van de personen ten opzichte van die van een fictieve nulpersoon → lapda hoef je dan niet meer te schatten
‘semi-parametrisch’: wel parameters geschat, maar geen verdelingsassumpties gemaakt omdat hazardfunctie zelf niet wordt geschat
hazart ratio
stel x = 1, dan geeft e^bèta de toename van de hazard als X van 0 naar 1 gaat
stel b = .05, dan hazard voor recidive van degene die beheersingsproblemen hadden 1.65 keer → risico is met 65 verhoogd
modelfit cox regressie
Geen R2, alleen relatieve fitmaten
Likelihoodratio die geneste modellen in relatieve zin kunnen vergelijken, maar geen absolute waardering uitspreken over het model
AIC bij niet geneste modellen
penalty voor veel onafhankelijke variabelen
nominale predictor bij coxregressie
gebruik dummy variabelen
voor elke catorgorie een eigen variabelen maken met wel of niet die categorie.
als je 4 categorieën hebt, hoef je maar 3 dummy variabelen te hebben omdat de eerste de referentiecategorie is.
assumpties coxregressie
X is fixed, Y is random
X interval variabelen
waarneming onafhankelijk (hier: status persoon op tijdstip t onafhankelijkvan status persoon op tijdstip t+j)
censurering is random
proportionele hazards → checken met partial residuals, errortermen over de tijd