Software Side Channels - 18
1/25
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
26 Terms
What is a Microarchitectural Attack?
Abuse hardware side-channels from software by exploiting microarchitectural components
What is Microarchitecture?
(Assembly) Instructions lowest abstraction in programming
Defined by the Instruction Set Architecture
But hardware needs to execute these instructions, including:
Decoding instructions
Interacting with memory
Detecting faults
All of this is implemented in the microarchitecture
Analogy: CPUs are the interpreter for assembly instructions. The microarchitecture is the “code” for the interpreter
What are Micro-Architectural Components?
Modern CPUs are complex
Multi-stage instruction pipelines
Out-of-order execution
Branch prediction
MicroOps
Huge gains for performance
But not designed for security
What are the types of Micro-Architectural Components?
Branch Predictors and CPU caches
What are Branch Predictors?
Control flow of programs is decided by branches
The branch prediction unit (BPU) tries to predict the target for each branch
General good heuristic:
“For already encountered branches, assume the same branch target again”
Often true in practice, e.g.:
Loops
Frequently called functions
Indirect branches for class methods in OOP
What is Speculative Execution?
CPU assumes that prediction of BPU as correct
And begins to speculatively execute the instructions on branch target side
No need to wait on computation result for data-dependent branches
This happens in the microarchitecture(!)
If prediction was correct:
Huge performance gain
Results from speculative execution are architecturally committed
If prediction was incorrect (“misprediction”):
Discard results of speculative execution
Restart pipeline at correct branch target
More or less same performance as if branch prediction was not in-place
What is Direct Branch Prediction?
Branches to fixed targets
May be conditional
In (x86) assembly, e.g.: jmp, jnz, jz, etc
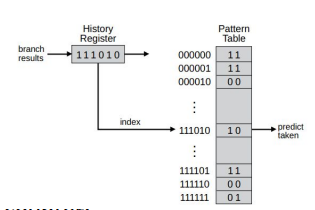
Performed via the “Pattern History Table” (PHT)
Keeps track of previously taken/non-taken history
Uses the resulting history as index into the pattern table
Optional: Also as index into branch target address cache
Simplest form: Pattern table is a saturating 2-bit counter:
MSB used for prediction
For taken branches, increment entry
For not–taken, decrement entry
What is Indirect Branch Prediction?
Branches with targets computed at run-time
In (x86) assembly, e.g.: jmp [rax], call [rdi]
More complicated to predict
Prediction via:
Branch History Buffer (BHB)
Branch Target Buffer (BTB)
Creates tags for prediction by combining:
Source
Destination
History
![<ul><li><p> Branches with targets computed at run-time </p><ul><li><p>In (x86) assembly, e.g.: jmp [rax], call [rdi] </p></li><li><p>More complicated to predict </p></li></ul></li><li><p>Prediction via: </p><ul><li><p>Branch History Buffer (BHB) </p></li><li><p>Branch Target Buffer (BTB) </p></li></ul></li><li><p>Creates tags for prediction by combining:</p><ul><li><p>Source </p></li><li><p>Destination </p></li><li><p>History</p></li></ul></li></ul><p></p>](https://assets.knowt.com/user-attachments/48d72456-8d3d-4b89-8a34-6a286d714733.png)
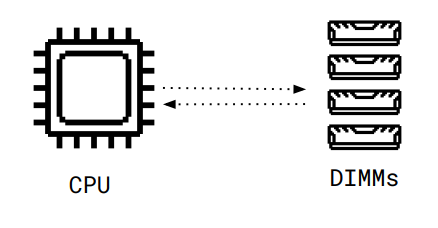
What problem do CPU caches solve?
Accessing data from memory is a bottleneck
Data transfer via bus
Memory controller to map physical addresses to DIMMs
Complex organization of memory on DIMM (Bank, Ranks, Rows)
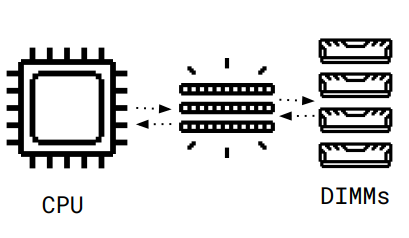
How do CPU caches solve this problem?
CPU Caches:
Microarchitectural component between memory and CPU
Caches memory contents
Usually implemented with SRAM
Small sizes
Fast access types
What are the main ideas with CPU Caches?
Previously accessed data & instruction:
Have a high likelihood to be accessed again
Let’s keep them close to the CPU!
When data is loaded from DIMM, bring it into cache
Subsequent operations are on value in cache
Huge performance optimization
When cache is full and new values are loaded from memory:
Write data back from cache to memory (“evict” old values)
What are the types of caches?
I-Cache: Instruction Cache, for executed code
D-Cache: Data Cache, for accessed data
What is the cache granularity?
Organized in “Lines”
Usual cache line size: 64kb
Single memory access brings (or evicts) full line from cache
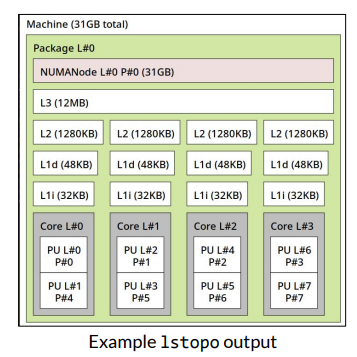
What is the Cache Hierarchy?
L1: Very Small & Very Fast
Typically located directly on the CPU
L2: Small & Fast
Typically located on CPU or in proximity
L3: Large & Slow
Typically shared across multiple cross
Memory: Very large & very slow
What side channel does the CPU cache introduce?
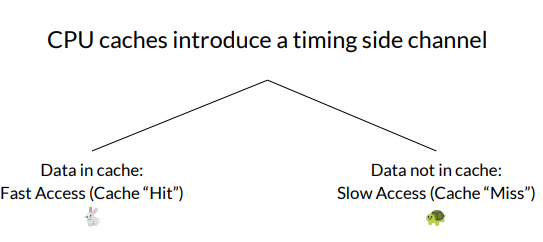
What is the Flush+Reload cache attack?
Originally leaks from a victim to a spy process
Assumes shared memory between victim and spy
Can even work via L3
Shared code and libraries(!)
Strategy:
1) Spy flushes cache
2) Victim carries out operations
3) Spy probes cache and measures time:
Fast access: victim brought value into cache
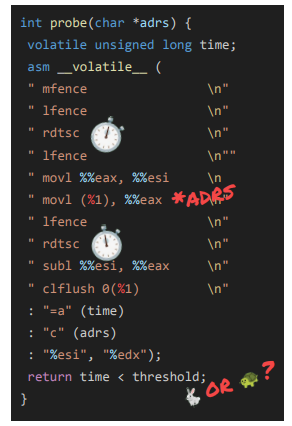
What are some other cache attacks?
Flush & Flush
Evict & Reload
Prime & Probe
What is the Flush & Flush attack?
Mechanism: Flush takes longer when data is cached
Use-case: Same as flush and reload, but more stealthy
What is the Evict & Reload attack?
Mechanism: Use cache eviction policies to evict sensitive data from cache
Use-case: clflush (or similar) instruction unavailable, shared memory available
What is the Prime & Probe attack?
Mechanism:
(1) Attacker primes cache by filling all values.
(2) If later access is slow, victim accessed relevant cache line in-between
Use-case: clflush (or similar) instruction unavailable, shared memory unavailable
What do these cache attacks allow?
Breaking cryptography by learning:
Which parts of code was executed (e.g., Square-and-Multiply in RSA)
Which parts of data was accessed (e.g., look-up tables in AES)
Building covert channels
Transmitting information between two processes not allowed to communicate
Exfiltrating data during transient execution attacks
We can probe whether certain data ended up in cache
Wha the Platypus attack?
Uses Intel‘s Running Average Power Limit (RAPL) functions to measure power consumption of target operations
Similar to traditional power side channels
What is RAPL?
Running Average Power Limit
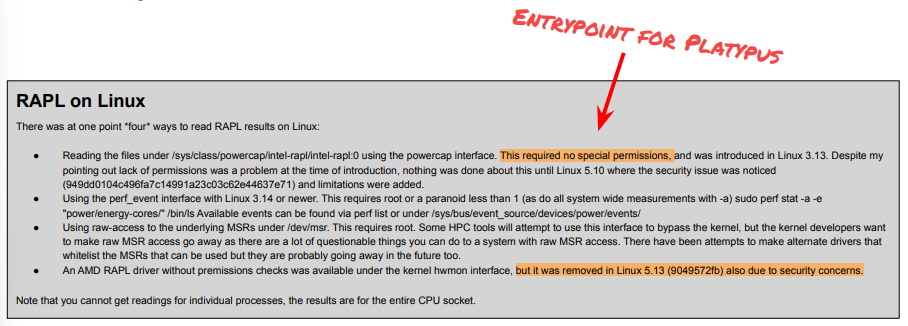
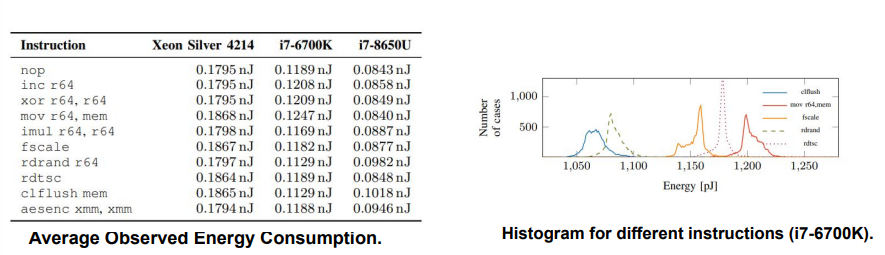
How can you measure instruction energy consumption using RAPL?
RAPL allows to measure the consumed energy over sampling period
Update intervals up to 50µs
Energy is closely related to power consumption:
Cumulative consumed power over time
RAPL measurements can target four different domains
package (PKG), power planes (PP0 and PP1), and DRAM
Similar interfaces available for AMD
What is an example platypus with an unprivileged attacker?
Breaking KASLR within 20 seconds
Using the (unprivileged) powercap interface directly
And requires Intel TSX for fault suppression
Not possible on modern systems
What is an example platypus with a privileged attacker?
Side-channel attack on execution in SGX enclave
Recovering RSA private keys within 100 minutes
Leaking of keys for AES-NI between 26-277 hours