Cognitive Modelling termen h1-7
1/72
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
73 Terms
Nativists
Individuals who believe that certain skills or abilities are innate and not acquired through experience. The idea that we are a “mechanical mind” of inputs and outputs.
Empiricist
That experience is the foundation of all knowledge and that when we are born, we are born with a clean slate (Tabula Rasa). Furthermore that the mind could be broken down into elements that when combined produced the whole of consciousness.
Natural selection
The process of which a species evolves by adapting to it’s environment. Learning is also an
evolved mechanism.
The brain
The brain originally existed for movement, but because of an arms race between carnivores and herbivores it evolved adaptive behavior. The brain is a prediction engine.
The neuron
A cell that caries signals throughout the brain. Consisting of dendrites as input, the cell body, the axon and the synapse as output.
Glutamate
Is excitatory, activating receptors, tends to increase the likelihood of the postsynaptic neuron firing. Most common neurotransmitter.
GABA
Is inhibitory (slowing down), activating receptors that tend to decrease the likelihood of the postsynaptic neuron firing.
Synaptic plasticity
The ability of synapses to change as a result of experience.
long-term potentiation (LTP)
A process in which synaptic transmission becomes more effective as a result of recent activity.
long-term depression (LTD)
A process in which synaptic transmission becomes less effective as a result of recent activity.
Hebbian Learning
The principle that learning involves strengthening the connections of coactive neurons; often stated as, “Neurons that fire together, wire together.”
Synaptogenesis
After birth the neurons are in place but still make new many new connections
Pruning
Many of these new synapses will be eliminated -> experience based fine tuning of functional networks
Latent Learning
Automatic Statistical Analyses of the World
Habituation
A decrease in the strength or occurrence of a behavior after repeated exposure to the stimulus that produces that behavior.
Dishabituation
A renewal of a response, previously habituated, that occurs when the organism is presented with a novel stimulus.
Spontaneous recovery
Reappearance (or increase in strength) of a previously habituated response after a short period of no stimulus presentation.
Sensitization
A phenomenon in which a salient stimulus (such as an electric shock) temporarily increases the strength of responses to other stimuli (including the habituated stimulus)
mere exposure learning
Combination of habituation (to similarities) and Sensitization (to differences).
synaptic depression
A reduction in synaptic transmission; a neural mechanism underlying habituation.
homosynaptic
Occurring in one synapse without affecting nearby synapses.
Long-term habituation
Elimination of presynaptic terminals
Hippocampus
It converts short-term memories into long-term memories by organizing, storing and retrieving memories within your brain. Your hippocampus also helps you learn more about your environment (spatial memory), so you’re aware of what’s around you, as well as remembering what words to say (verbal memory).
Spatial Learning
Making cognitive maps used for learning & planning (replay and pre-play) of for example a maze.
Dog of Pavlov
Classical Conditioning, when a dog is conditioned that a bell means food it begins to salivate when it hears a bell. With Unconditioned response (UR): A response for which no training was necessary to establish it.
Unconditioned stimulus (US): A stimulus that elicits a response without training.
Conditioned response (CR): A response whose occurrence depended on particular conditions of training.
Conditioned stimulus (CS): A stimulus that, through training, elicits a response.
Conditioning leads to general effect, extinction to context specific changes
Rescorla Wagner
Formulas for emulating conditioning:
Vt+1=Vt+dVt
dVt = a(Vmax – Vt)
V is the association made with the stimulus and a is the learning rate.
Latent inhibition
Part that Rescorla Wagner doesn’t explain. That prior overexposure to a stimuli makes it harder to learn a conditioned response from that stimuli.
Pearce-Hall
Formulas that try to fix latent inhibition with a dynamic learning rate.
Vt+1=Vt+dVt
dVt = S * at* Vmax
at = |Vmax - Vt| (t >= 1)
S is the intensity of the CS
instrumental condition
In which an animal learns how its own behavior is instrumental in causing specific consequences.
Law of effect
The observation that the probability of a particular behavioral response increases or decreases depending on the consequences that have followed that response in the past.
discriminative stimulus
A stimulus that signals whether a particular response will lead to a particular outcome.
reinforcement
The process of providing outcomes for a behavior that increase the probability of that behavior occurring again in the future.
free-operant paradigm
An operant conditioning paradigm in which the animal can operate the experimental apparatus “freely,” responding to obtain
reinforcement (or avoid punishment) when it chooses.
primary reinforcer
A stimulus, such as food, water, sex, or sleep, that has innate biological value to the organism and can function as a reinforcer.
secondary reinforcer
A stimulus (such as money or tokens) that has no intrinsic biological value but that has been paired with primary reinforcers or that provides access to primary reinforcers.
drive reduction theory
The theory that organisms have innate drives to obtain primary reinforcers and that learning is driven by the biological need to reduce those drives.
Homeostasis
compensatory responses
continuous reinforcement schedule
A reinforcement schedule in which every instance of the response is followed by the consequence.
partial reinforcement schedule
reinforcement schedule a reinforcement schedule in which only some responses are reinforced.
dorsal striatum
Plays a critical role in operant conditioning
orbitofrontal cortex
Is, among other regions, involved in tracking the outcomes of behavior.
fixed-ratio (FR) schedule
Reinforcement after an predictable number of responses
variable-ratio (VR) schedule.
Reinforcement after an unpredictable number of responses
fixed-interval (FI) schedule
Reinforcement after a specified amount of time
variable-interval (VI) schedule
Reinforcement after an unpredictable amount of time
Operant conditioning
A type of learning in which behavior changes based on its consequences. Reinforcement strengthens a behavior, while punishment reduces the likelihood of it occurring again. The timing and consistency of reinforcement or punishment play a key role in how quickly and effectively learning happens.
hedonic value
The subjective “goodness” or value of a reinforcer.
motivational value of a stimulus
The degree to which an organism is willing to work to obtain access to that stimulus.
insular cortex (insula)
A region involved in conscious awareness of bodily and emotional states and may play a role in signaling the aversive value
of stimuli.
dorsal anterior cingulate cortex (dACC)
A subregion of prefrontal cortex that may play a role in the motivational value of pain.
Dopamine
Neurotransmitter that’s important in reinforcement.
Temporal Difference Learning
Temporal Difference (TD) Learning is a model-free reinforcement learning method used by algorithms like Q-learning to iteratively learn state value functions (V(s)) or state-action value functions (Q(s,a)). Rescorla-wagner has not way to deal with time, TD has. By learning updates value estimates after each time step using the Bellman equation and Temporal Difference error. Basically that thing you did in week 1 with that reward.
Markov Decision Process
The Markov assumption poses that the world is composed of a set of finite states (S), actions
(A), a set of transition probabilities (T), and rewards (R). When you enter one state, it does not matter where
you came from with regards to predicting the future outcome of your actions in terms of transitions
Q-Learning
A model-free reinforcement learning algorithm that helps an agent learn how to make the best decisions by interacting with its environment. Instead of needing a model of the environment the agent learns purely from experience by trying different actions and seeing their results
model based
learning a ‘‘model’’ of action-outcome relationships and use this to plan actions by forecasting their outcomes. A mouse that stops pulling a lever, even if it associates it with food, when he gets food that makes him sick. Another example is AlphaGo, Q-learning + Deep Neural Nets & Tree search.
model free
Learning a direct mapping from perceptual inputs to action outputs. A mouse that keeps pulling a lever because it associates it with food as a habit, even though that food makes him sick.
explore-exploit problem
Finding the right balance between exploring or exploiting a resource to optimize (speed up) learning and
maximize rewards.
epsilon-Greedy policy:
With probability epsilon chose a random bandit, otherwise choose the bandit with highest expected value. keeps exploring even when
everything is explored. Not always optimal, not optimal at all stages of the task.
Softmax
allows the current estimates of Q (s, a) to influence the probability of exploration:
Upper Confidence Bound
Optimism in the face of uncertainty. Exploration bonus and directed exploration.
Prediction error
The difference between the predicted values made by some model and the actual values.
The SASRA algorithm
(State, Action, State, Reward, Action) takes into account all possible actions the agent will take in the next step.
TM = rt+1 + C E(Q(st+1, at+1))−Q(st ,at )
E(Q(st+1, at+1)) = e E(pi(random)) + (1-e) * E(pi(Qmax))
Learned Helplessness
The concept that you can learn to be helpless:
In group one, dogs were strapped into harnesses temporarily and then released. In group two, dogs were harnessed and subjected to electric shocks, which they could avoid by pressing a panel with their noses. In group three, dogs also received shocks, but unlike group two, they couldn't control the shocks. For this group, the shocks appeared random and beyond their control. When placed in the shuttlebox again, dogs from the first two groups quickly learned that jumping the barrier stopped the shock. However, those in the third group did not attempt to avoid the shocks.
DQN
Basically if you merged Q-learning and neural nets. It’s especially useful in environments where the number of possible situations called states is very large like in video games or robotics.
catastrophic forgetting
The tendency of an artificial neural network to abruptly and drastically forget previously learned information upon learning new information.
Expected Utility
How much you expect to get from a situation. If you expect 100 dollars, but there is a 5 % change you wont get it, it’s expected utility is 95 dollars and a disappointed feeling when you don’t get it. It’s similar to the Q-values. Utility shows the satisfaction or happiness derived from a good/service/money while the expected value simply shows us the monetary value.
Expected Value
A generalization of the weighted average. So if there is a 0.5 chance of winning 10 dollars and a 0.5 chance of getting 20 dollars the expected value is 15 dollars.
Weber-Fechner Law
Weber’s law, also known as Weber-Fechner law, explains that perception of intensity of a stimulus grows at a slower rate than the actual physical intensity. When dealing with intense stimuli (high initial intensity), larger changes are necessary for stimulus discrimination detection than those with less sensitive ones. This is also a rule that is applicable in expected utility.
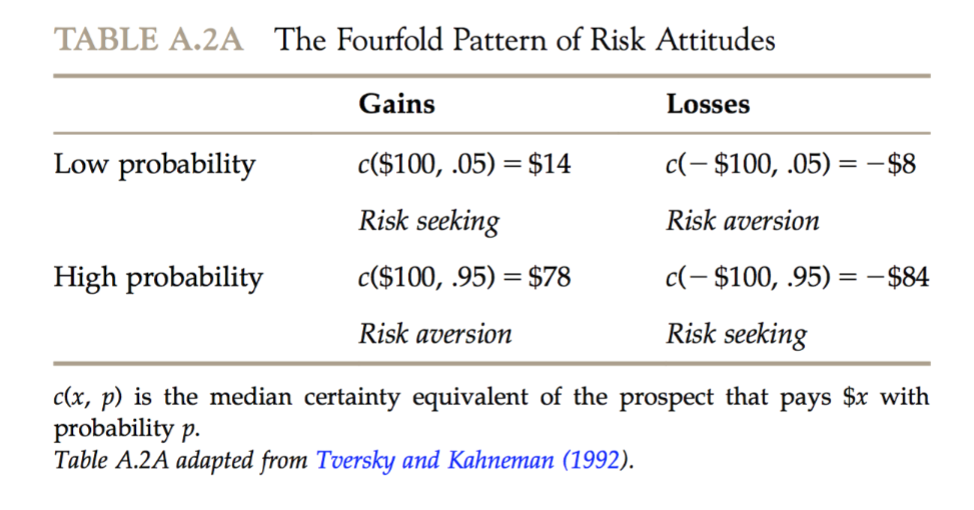
Prospect Theory
Rejects the expected utility hypothesis and states that probabilities are also not linearly weighted.
Discounted Utility
That the subjective worth shrinks as a function of approximately 1/t when there is more time between now and getting the reward. For example that 35 euro in 210 days is worth less than 100 euro in 270 days but 35 euro today is worth more than 100 euro in 60 days.
Pavlovian System
One decision-making systems of multiple systems that can semi-independently drive decision-making:
Although diverse stimuli can participate in Pavlovian learning, the available actions remain
limited (e.g., salivate, approach, avoid, freeze). Example: pavlov dogs salivating
Habit System
One decision-making systems of multiple systems that can semi-independently drive decision-making:
The habit system entails an arbitrary association between a complexly recognized situation and a complex chain of actions (Typical Q-RL). Once learned, cached actions are fast but can be hard to change.
goal-directed system
One decision-making systems of multiple systems that can semi-independently drive decision-making:
Deliberative action-selection is a complex process that includes a search through the expected consequences of possible actions based on a world model. It is very flexible, it is computationally expensive and slow.