Chapter 5 Classification I: training & predicting
1/20
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
21 Terms
When should you use classification?
When the response variable is categorical (e.g., yes/no, species type) and you want to predict class labels.
What is a training dataset?
A dataset with predictors and known labels used to teach the model patterns for making predictions on new data
What is Euclidean distance?
The straight-line distance between two points in space.
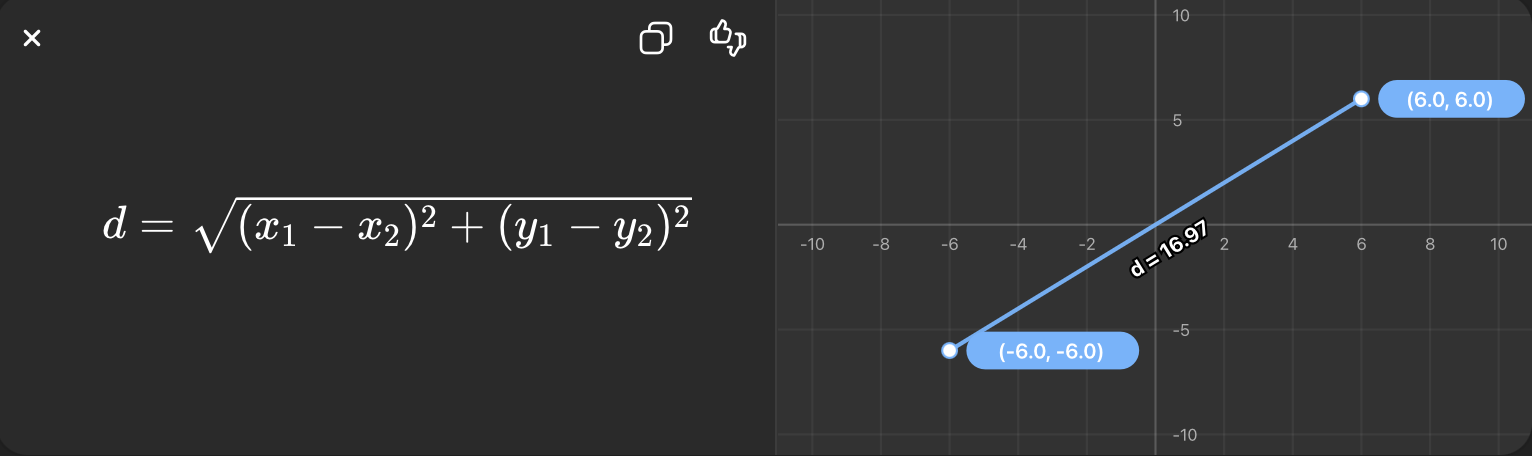
What is K-nearest neighbors (KNN)?
A classification algorithm that assigns a class based on the majority label among the K closest training points.
Why is scaling important in KNN?
Because distance calculations are sensitive to variable scale; larger-scale variables dominate distances.
Steps in KNN classification workflow
Split data (train/test)
Preprocess (scale, center, clean)
Specify model
Fit model to training data
Predict on new/test data
Evaluate performance
What is a recipe in tidymodels?
A set of preprocessing steps applied to data before modeling.
It includes steps such as centering and scaling predictors, handling missing values (imputation), and balancing classes (e.g., upsampling).
Centering vs scaling
Centering: subtract mean
Scaling: divide by standard deviation
step_center(all_predictors()) + step_scale(all_predictors())
What is imputation?
Filling in missing values.
Syntax: step_impute_mean(all_predictors())
What is balancing data?
Adjusting class distribution to avoid bias toward majority class.
Syntax to upsample: step_upsample(outcome_variable)
What does bake() do?
Applies the trained recipe to new data
KNN model specification in R
knn_spec <- nearest_neighbor(weight_func = "rectangular", neighbors = 5) |>
set_engine("kknn") |>
set_mode("classification")
What does set_mode("classification") do?
Tells the model to predict categorical outcomes.
What is a workflow and why do we use it?
Combines preprocessing (recipe) and model into one object. Ensures consistent application of preprocessing and modeling steps.
glimpse()
Quickly view structure of a dataset
distinct()
Returns unique rows/values — removes duplicate rows
fct_recode()
Is used to rename or relabel the categories (levels) of a factor variable.
For example, if a variable has levels like "M" and "F", you can change them to "Male" and "Female" without altering the data itself.
drop_na()
Is used in a data wrangling pipeline to remove rows that contain missing (NA) values
data |> drop_na()
bind_rows() vs bind_cols()
bind_rows(): stacks datasets verticallybind_cols(): combines datasets horizontally
When to use drop_na() vs imputation?
drop_na(): when few missing values
imputation: when you want to keep data
drop_na() removes entire rows that contain missing values, so you lose those observations.
Imputation fills in missing values (e.g., using the mean), allowing you to keep all observations.
Why and how preprocess data?
Ensure variables are comparable and usable
Common steps:
recipe(class ~ ., data = training_data) |>
step_scale(all_predictors()) |>
step_center(all_predictors()) |>
step_impute_mean(all_predictors()) |>
step_downsample(class)