stat 200 :-)
1/71
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
72 Terms
Hva er forskjellen på R^2 og r^2?
R^2 beskriver hvor mye en modell forklarer variabiliteten i et sett observasjoner.
r^2 (pearson korrelasjon) måler lineær korrelasjon mellom to variabler.
Forskjell på s² med en parameter og s² i lm
1 parameter: s² = s_xx /(n-1)
For lm: s² = SSE / (n-p)
Formel for Resiudals standard error
sqrt(SSE/ n-p)
p = parametere
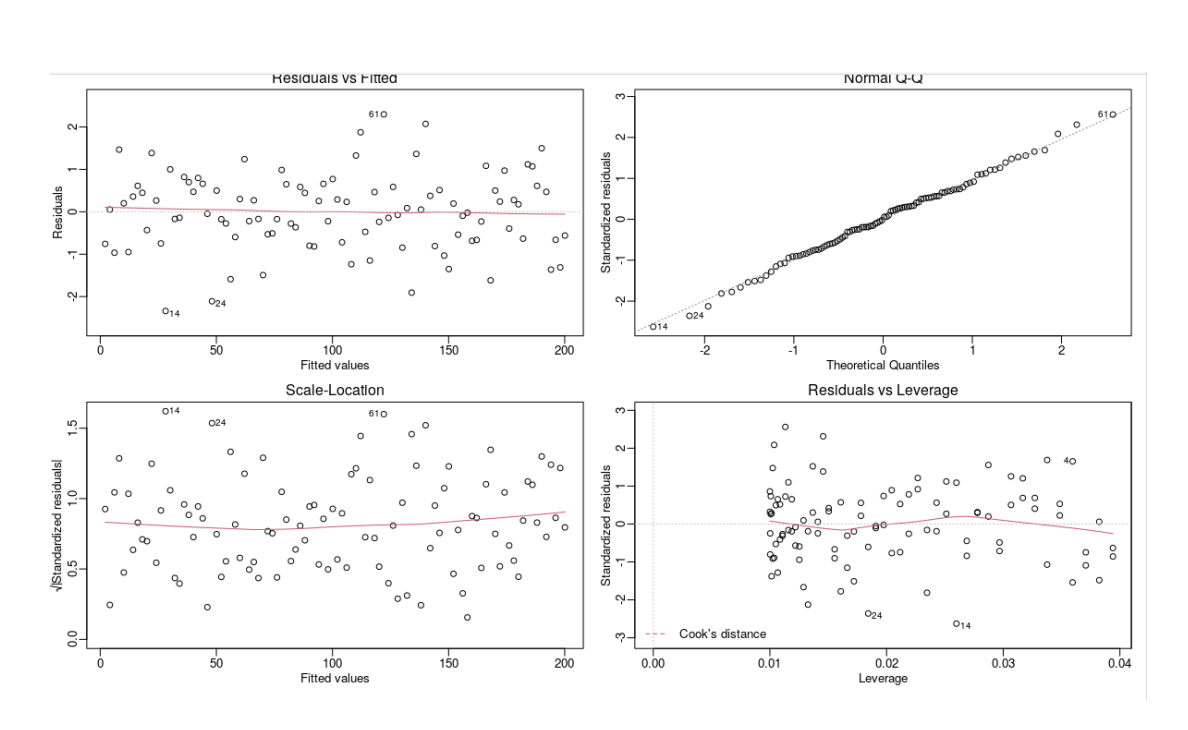
Hva er problemet her?
Ingeting

Hva betyr dette?
GLM med log link funksjon med gamma fordeling, uten intercept ledd
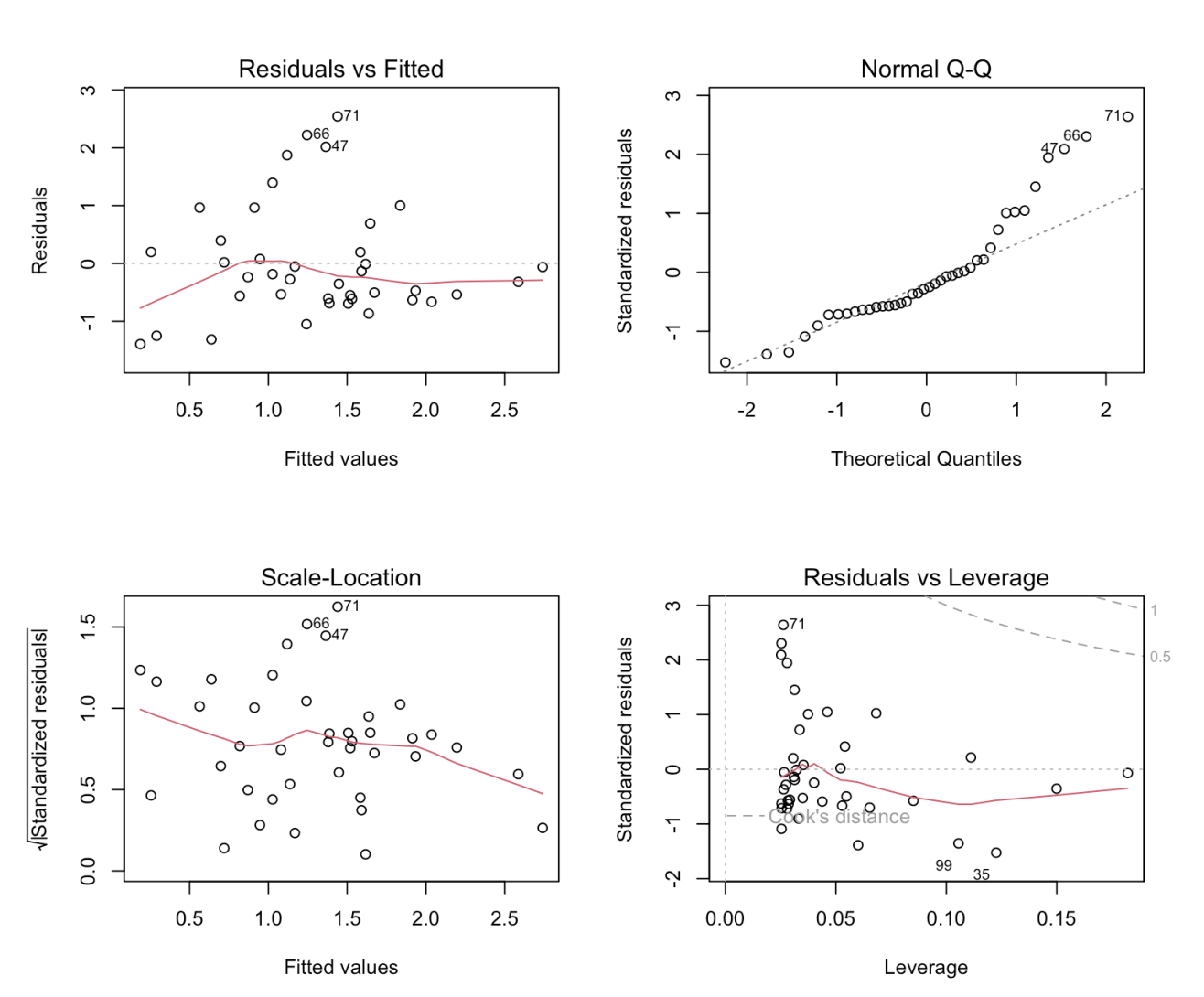
Hva er problemet her?
Ulik varians og avvik for normalitet
Formel SSTr
Når en har outliers i regressions dataen, hva kan en gjøre?
Fjerne punktet, men det er ikke alltid lurt
Bruke Robust regression eller Quantile regression
Vanlig regression bruker least squeres, da vil en outlier påvirke mye
Robust regression og Quantile regression nedvekter outliers på hver sin måte
Formel SSE
Formel for R^2
1 - SSE / SST
Hva er en GLM?
Generalisert linear modell
En utvidelse av lineær regresjon som lar oss modellere ikke-normal responsvariabler (f.eks. binære, tellinger).
Delt i 3 deler:
en lineær prediktor
en link-funksjon som kobler prediksjonen til responsen
en fordeling for responsvariabelen (f.eks. binomisk, Poisson)
Hva er Blocks?
En blokk er egentlig en kilde til variasjon som du ikke er interessert i, men som du må kontrollere for
Brukes i Friedman
Hva er antagelsene for lineær regression?
Uavhengighet linearitet Normalitet konstant varians Ingen outliers som har stor innflytelse på modellen
Hva er Cook's distance?
Cook's distance = et mål på hvor innflytelsesrik en observasjon er i en regresjonsmodell
Hva er statistisk Power?
Power er sannsynligheten for at en statistisk test forkaster nullhypotesen når den faktisk er falsk (altså oppdager en reell effekt), og er dermed lik 1 minus sannsynligheten for type II-feil
Hva er transformasjon og hvorfor vil en bruke det?
Transformasjon er å endre skalaen til data (f.eks. log eller kvadratrot) for å gjøre dem mer egnet for statistisk analyse
Vi gjør det for å:
- gjøre data mer normalfordelte
- gjøre variansen mer konstant (homoskedastisitet)
- gjøre sammenhenger mer lineære
- redusere effekt av skjevhet og outliers
En kan da bruke parametriske tester som har mer power
Hva er forskjellen på en wilcoxon rank sum test og en wilcoxon signed rank test?
Rank sum test brukes på to uavhengige grupper (ikke-parametrisk alternativ til t-test for uavhengige utvalg)
Signed rank test brukes på parvise/avhengige data (ikke-parametrisk alternativ til paret t-test)
Hvordan fungerer en Wilcoxon rank sum test?
Brukes for to uavhengige grupper
Slå sammen alle observasjoner fra begge grupper
Ranger alle samlet (minste = 1), like verdier får gjennomsnittsrang
Summer rangene for den minste gruppen → W
p-verdien er sannsynligheten for å få en lik w eller mer ekstrem
Hvordan fungerer en wilcoxon signed rank test?
Brukes for paret design
Beregn differansen for hvert par (etter − før)
Ignorer par med differanse = 0
Ranger absoluttverdiene av differansene
Gi rangeringen fortegn tilbake
W⁺ = sum positive ranger, W⁻ = sum negative ranger
W = min(W⁺, W⁻) — slå opp i tabell H₀: medianen av differansene er 0.
Hvordan brukes AIC og BIC?
Brukes for å sammenligne statistiske modeller og til å velge mellom ulike modeller (lavere verdi er bedre).
AIC = 2k - 2log(L)
k = antall parametere i modellen (straffes for mange parametere/kompleksitet)
log(L) = log likelihood
BIC = k ln(n) - 2log(L) straffer kompleksitet hardere
Hvor mange dof mister en med å lage en lineær modell?
2 En for slope og en for intercept
Forklar F - statistikk og hvilken test den kommer fra?
ANOVA
F-statistikken tester om minst én forklaringsvariabel i modellen har en effekt, ved å sammenligne modellens forklarte variasjon med uforklart variasjon.
Hvordan ser en LMM ut?
Som en lineær modell, men også med random effects
yij=β0+β1xij+u0i+u1ixij+εij
u0i+u1ixij er random effects
Hva er log-likelihooden til en modell?
Mål på hvor godt modellens estimerte parametere forklarer de observerte dataene.
Hva er ANOVA?
ANOVA tester om minst én gruppes gjennomsnitt er forskjellig fra de andre ved å sammenligne variasjon mellom grupper med variasjon innen grupper.
Hva er ANCOVA?
Kombinasjon av ANOVA og regresjon.
Tester gruppeforskjeller (som ANOVA), men kontrollerer samtidig for én eller flere kontinuerlige kovariater.
Eksempel: sammenlign testresultater mellom tre undervisningsmetoder, men kontroller for elevenes IQ. Fordel: reduserer MSE (finn ut hva det er)→ øker statistisk styrke. Gir mer presise gruppesammenligninger.
Hva er forskjellen på en ANOVA og en ANCOVA?
ANOVA tester om gruppegjennomsnitt er like
ANCOVA gjør det samme, men kontrollerer i tillegg for én eller flere kontinuerlige kovariater, noe som reduserer feilvariansen og gir mer presis testing.
Hva er en falsk positiv?
En falsk positiv er når en statistisk test feilaktig finner en effekt (forkaster H₀) selv om det egentlig ikke finnes noen effekt i virkeligheten.
Hva er en falsk negativ?
En falsk negativ er når en statistisk test ikke finner en effekt (beholder H₀) selv om det faktisk finnes en effekt i virkeligheten.
Hva er model utility test?
Er modellen vår bedre enn ingen modell i det hele tatt?
Ingen modell vil si at den beste gjetningen på y alltid er y_bar, uansett hva x er
For LM er model utility test : om b_1 = 0
Hva er en GLMM og hvordan er en slik model equation?
General linear mixed model
y = h(lmm) uten epsilon
Hva er "least squeres" i enkel regression?
Ønsker en modell som minimerer avstanden mellom predikerte og observerte punkter
Velger regressionslinjen som minimerer summen av de kvadrete residuals
Modellen med lavest sum av "Squeres" er best
Hva er fixed effects og random effects?
Fixed effects er effekter som antas å være de samme for alle observasjoner, mens random effects lar effekten variere mellom grupper eller enheter
Hva er residuales?
Residualer er forskjellen mellom observert verdi og predikert verdi fra modellen
Hva er one-way ANOVA?
One-way ANOVA tester om minst én gruppes gjennomsnitt er forskjellig når vi har én faktor med flere nivåer
Hva er multi-way ANOVA?
To eller flere faktorer og interaksjonen mellom faktorene
Hva er post-hoc test?
Post-hoc tester brukes etter en signifikant ANOVA for å identifisere hvilke spesifikke grupper som har signifikant forskjellige gjennomsnitt
Eks tukey HSD
Hva er forskjellen på paired og unpaired t-test?
Paired t-test brukes når målingene er avhengige/parrede (samme enheter målt to ganger), mens unpaired t-test brukes for to uavhengige grupper
Hva er Shapiro-Wilk-testen?
Shapiro-Wilk-testen tester nullhypotesen om at dataene kommer fra en normalfordeling.
Hva er forskjellen på et konfidensintervall og et prediksjonsintervall i linear regression?
Et konfidensintervall i lineær regresjon beskriver usikkerheten rundt det forventede gjennomsnittet (best fit linjen), mens et prediksjonsintervall beskriver usikkerheten rundt en ny enkelt observasjon
hva er hetro/Homoskedastisitet?
Homoskedastisitet betyr at residualenes varians er konstant over alle nivåer av de predikerte verdiene, mens heteroskedastisitet betyr at variansen varierer
Hvorfor vil en gjøre en ANOVA istedenfor mange parvise t-tester?
Sannsynligheten for å begå minst én Type I-feil øker dramatisk
Hvordan påvirker teststatistikken (f.eks. t eller F) p-verdien?
Jo større absolutt verdi av teststatistikken (t eller F), desto mindre p-verdi, fordi resultatet da er mer ekstremt under nullhypotesen
formel for t-stat
formel std
formel s^2
formel jackknife std
formel r^2
formel s^2 (lineær regresjon)
t-stat: t = (x̄ - μ) / (s / √n)
std:s = √(Σ(x_i - x̄)^2 / (n - 1))
varians:s^2 = Σ(x_i - x̄)^2 / (n - 1)
jackknife std:SE_jack = √(((n - 1) / n)
Σ(θ_i - θ̄)^2)
r^2 = cov (x,y) /(var(x) var(y))
lineær regresjon s^2 :s^2 = SSE / (n - 2)
Hva kan en lese av diagnostic plotsene?
Residuals vs Fitted: sjekk linearitet, konstant varians (homoskedastisitet) og uavhengighet . Skal se tilfeldig spredning rundt 0.
Q-Q plot: sjekk normalitet av residualene. Punktene skal følge den rette linjen.
Scale-Location: sjekk homoskedastisitet. Horisontal linje = OK.
Residuals vs Leverage: identifiser innflytelsesrike observasjoner (Cook's distance).
Hvordan estimeres parametrene i en LM og en GLM?
LM: løse for b_0 og b_1 ved hjelp av normal ligningene
Estimere sigma:
GLM: maximum likelihood estimering. Ingen lukket formel fordi link-funksjonen gjør ligningene ikke-lineære. Løses iterativt med Fisher scoring
Hvilken restriksjoner fra LM opphever GLM?
Normalfordelte feilledd Konstant varians Lineær sammenheng mellom x og y Responsen må være kontinuerlig
Hvor mange parametere er det i random effects delen av en LMM?
1 for slope 1 for intercept Om en har begge blir det en ekstra fra cov mellom dem
Hvilken antagelser er det for en ANOVA test?
Normalfordeling Homoskedastisitet Uavhengighet Tilfeldig utvalg fra populasjonen
Hvorfor er det problematisk å bruke en parametrisk test på data som ikke er normalfordelt?
Parametriske tester antar normalfordeling for å utlede den eksakte fordelingen til testobservatoren under H₀. Er dataene ikke-normale kan: P-verdien bli feil (for lav eller for høy) Type I-feil øke (forkaster H₀ for ofte) Konklusjoner bli upålitelige
Hva er SST, SSR, SSE og SSTr?
SST = SSR + SSE (Total Sum of Squares) SSR = Regression sum of squares SSE = Error sum of squares SSTr = sum of squares treatment
Hva er Fisher scoring og hvorfor trengs det i GLM?
Fisher scoring iterasjoner sier noe om hvor vanskelig modellen var å tilpasse numerisk
Tallet ved "Number of Fisher Scoring iterations" forteller bare hvor mange iterasjoner IRLS-algoritmen trengte før estimatene konvergerte for å finne MLE
???
Hva er Friedman-testen?
Er multi-way ANOVA, men for ikke-parametrisk fordeling
Rangerer ranks innad i hver blokk
Tar gjennomsnitt av hver treatment
regner ut (T+1)/2
Hva er Kruskal-Wallis?
Er One-way ANOVA, men for ikke-parametrisk fordeling
rangerer data og gir ranks
regne ut rank sum og mean rank sum for hver gruppe
regn ut (n+1)/2
Hva er forskjellen på jackknife og bootstrap?
Begge er resampling-metoder for å estimere usikkerhet
Jackknife fjerner én observasjon av gangen og beregner estimatet på resten — gir N delestimater
Bootstrap trekker gjentatte utvalg med tilbakelegging (typisk 1000+) og bygger en empirisk samplingsfordeling
Bootstrap er mer fleksibelt og fungerer for nær sagt enhver statistikk, mens jackknife er enklere men fungerer dårlig for ikke-glatte statistikker som medianen.
Hvordan ser test statistikken for en one way ANOVA og hvilken fordeling følger den?
F = MSTr / MSE = (SSTr / (k-1)) / (SSE / (n-k))
F-fordeling med (k−1, N−k) frihetsgrader.
(Mellom grupper / innad i grupper)
Forskjell på når en bruker R^2 og AIC
Bruk R² når du vil beskrive hvor godt modellen passer dataene dine.
Bruk AIC når du vil velge hvilken av flere modeller som er best
Forskjell på R^2 og justert R^2
R² - når du beskriver én ferdig modell og vil kommunisere forklaringsgrad enkelt
Justert R² - når du sammenligner modeller med ulikt antall variabler, eller vil unngå å bli lurt av overfitting
R^2 øker hver gang du legger til en ny variabel - selv om variabelen er helt tilfeldig og meningsløs, dette fikser en justert R^2
Hvordan estimere epsilon i en LM?
Epsilon er ikke estimert fra normal ligningene.
Vi estimerer sigma med å bruke residualsene:
s = sqrt( SSE / (n - 2) )
SSE = sum of squeres residuales
Hvilken krav er det for å bruke en model equation?
Krav som normalitet og hetroskedasitet må være oppfylt
Ha flere observasjoner enn parametere i modellen
Hva vil adj i p-adj si?
adj betyr adjusting for at vi gjør flere sammenligninger, pga at det er falsk positiv sannsynlighet for hver sammenligning.
Vi justerer derfor kriteriene for å få et positivt resultat
Poisson fordeling
Count, bare positiv
Gamma fordeling
bare positiv, høyre forskjøvet, kontinuerlig
Binomial fordeling
rett/feil
model equation two-sample t-test
y_i = alpha_i + epsilon_i
Test statistikk One sample t-test
T = (x_bar - μ) / (s / sqrt(n))
t-fordeling (n-1)
x_bar = sample mean μ = population mean s = sample s.d
Tester for normalitet
Shapiro-Wilk Anderson-Darling
Tester for homoskedasitet
Bartlett Levene
Model utility test for lineær regresjon
b_1 = 0
t-test for å sjekke:
T = b^_1 / (s/sqrt(s_xx)) t-fordeling (n-2)
b^_1 = estimert stigningstall
Hva er autokorrelajon?
Residualene er korrelert med hverandre
I LM og GLM antar vi at residualene er uavhengige
Test for autokorrelasjon: Durbin-Watson
Hva er LRT?
Likelihood ratio test
Modell test som AIC og BIC
Er mer komplisert, men LRT kan brukes for å teste om en spesifikk variabel bidrar signifikant
En kan bruke det som en statistisk test om en variabel bidrar signifikant