Lecture 11: more data trumps over smarter algorithms
1/24
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
25 Terms
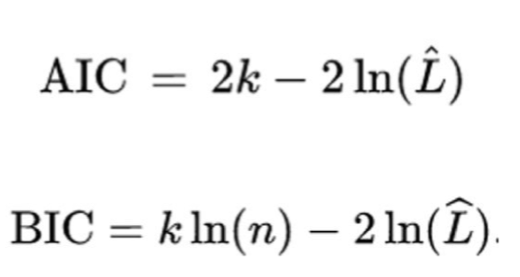
what do “AIC” and “BIC” represent?
likelihood function: measure of fit that can be done with probabilistic data
*BIC is more frequent (it was the thing saw in the last set of card, a BIC > 2 means that something important is happening)
what are the different definitions of parameter? (3)
hyperparameter: how a neural network is operating
parameters as weights in a model
parameter as a way of controlling for a model’s behaviour (in psychology)
what does this article talk about?
the right way of modelling and what aspects you want to emphasize on
how are classical models compared?
with the number of parameters (ex: AIC, BIC)
what issue do co-occurence models face?
the amount of training material needed
why are books not the ideal source of training material?
because most people don’t get their language experience from books only
how many tokens/words do people consume per year?
12 millions
true or false: your linguistic environment can depend on your educational level
true
true or false: two people with high vocabulary might have different type of vocabulary
true: a physics professor will have high vocabulary, but different from an anthropology professor
define “computational complexity”
technique that dictates the maximum or minimum number of steps that an algorithm is going to take given an input size
true or false: all cognitive models fall under the same class
false: they can be separated into different classes
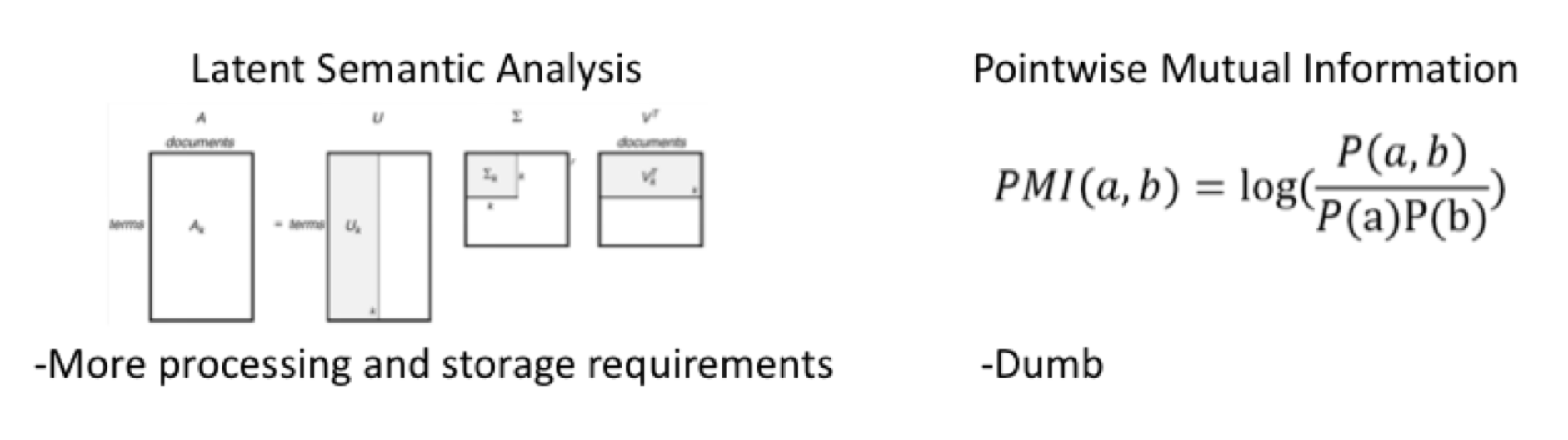
explain how we contrasted point wise mutual information (PMI) from latent semantic analysis (LSA)
trained both on small corpus (6 millions words from Wikipedia)
tested PMI on large Wikipedia corpus of 400 million words
tested on synonym test and word similarity data
LSA was better than PMI on smaller training data, but on bigger data PMI was better
suggests that overcoming limitation of distributional model is to increase training materials
why don’t you need complex learning mechanisms?
there is a trade off: complex learning mechanisms OR simpler models but trained with more data
should you have simplicity in the training model or with the number of training exemplars?
this is a competing model in psychology because we want both but they don’t work well together
define “productive vocabulary”
words you use when communicating
define “receptive vocabulary”
words you can understand
what’s the difference between productive and receptive vocabulary?
productive: words you use when communicating with others
receptive: words you can understand
we have larger [productive/receptive] vocabulary than [productive/receptive] vocabulary because […]
receptive larger than productive
because you don’t use all the words you know when communicating
why is BEAGLE more advantageous than Gaussian?
it’s less noisy
how can we understand the language variability between each user?
by understanding individual differences and the way they use language
define “average similarity of words” (ASW)
average similarity between two words across all users
define “total representation” (TR)
train a single model on all user corpora
what’s the difference between “average similarity of words” and “total representation”?
ASW: average the similarity between two words across all users
TR: train a single model on all user corpora
how could you increase the power in average similarity of words?
by taking into account the variability in word meaning
what do you need to stimulate human learning? (4)
learning mechanism
realistic training materials
representation
simplicity
what was the conclusion of the article?
humans have a lot of experience with the world
models need to scale
complexity of training algorithm needs to be understood and balanced