11: Ocena wydajności metod ED
1/17
Earn XP
Description and Tags
japierdole xdddddddddd
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
18 Terms
wydajność modelu
skuteczność modelu w rozwiązywaniu danego zadania przy użyciu wiedzy, doświadczenia, umiejętności, zdolności realizacji. Mierzona za pomocą dokładności, błędu, kompletności, kosztu lub szybkości
Dokładność (accuracy)
stopień bliskości pomiaru wielkości do prawdziwej wartości
Błąd (error)
.
przetrenowanie (przeuczenie)
model zaczyna zapamiętywać konkretne wartości danych zamiast uczyć się na ich podstawie — gdy model napotyka dane, których wcześniej nie widział, nie jest w stanie wykonać poprawnych operacji
Jak stwierdzić przetrenowanie?
Porównać dokładność wyznaczoną podczas uczenia i testu -- jeśli dokładność uczenia jest dużo większa to very probably, że bidok jest przeuczony ☹
powód przetrenowania
nieodpowiedni dobór parametrów
zbyt złożona budowa
za dlugi czas uczenia
za duże dopasowanie danych
jak naprawić przetrenowanie?
Occam’s razor - wybranie mniej skomplikowanego modelu, upraszczanie
odpowiednia ewaluacja modelu
Dwa typy algorytmów predykcji
algorytmy klasyfikacji:
wartości binarne,
wartości kategoryzowane
prawdopodobieństwa przynależności
Ważną grupę stanowią metody detekcji nowości, wykrywanie szczególnych przypadków.
metody regersji:
wartości ciągłe
KAŻDY Z TYCH ALGOTYMÓW MA INNĄ METODĘ EWALUACJI :
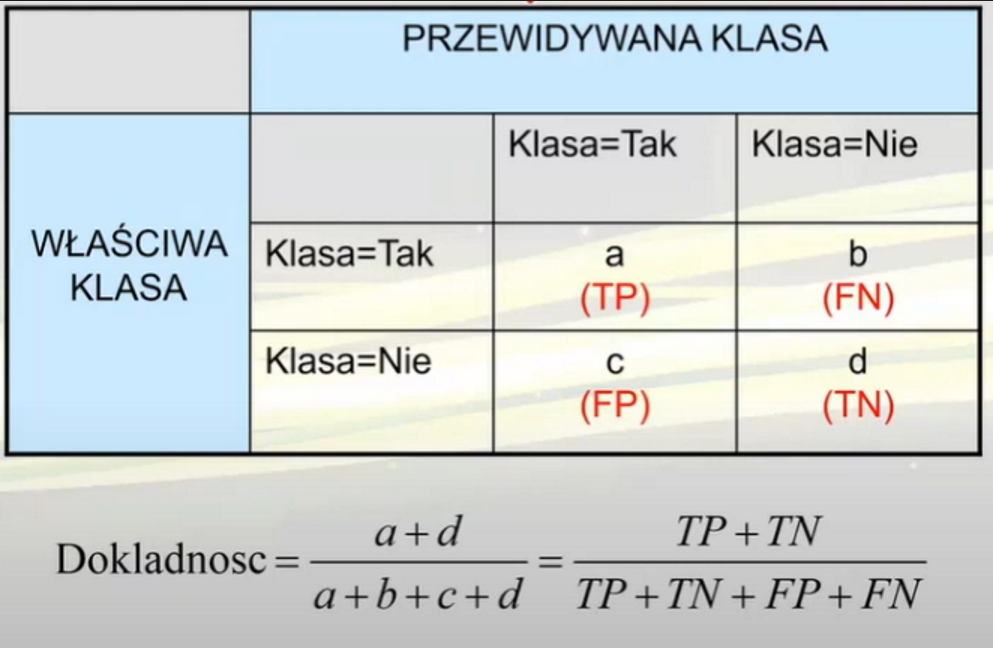
MACIERZ POMYŁEK
Macierz o wymiarach K x K, K -- liczba klas danych, do których stosowany jest klasyfikator
Każdy wiersz CM przedsatawia przypadki z przewidywanej klasy, kolumna CM przedstawia właściwą klasę
+ Łatwo odczytać błąd
Jak liczyć dokładność
TP + TN / (TP + TN + FP + FN)
CM - problem binarny
Lepiej być false negative -- bo dobry przypadek zakwalifikowano jako błąd wiec ogolnie bezpieczniej!!
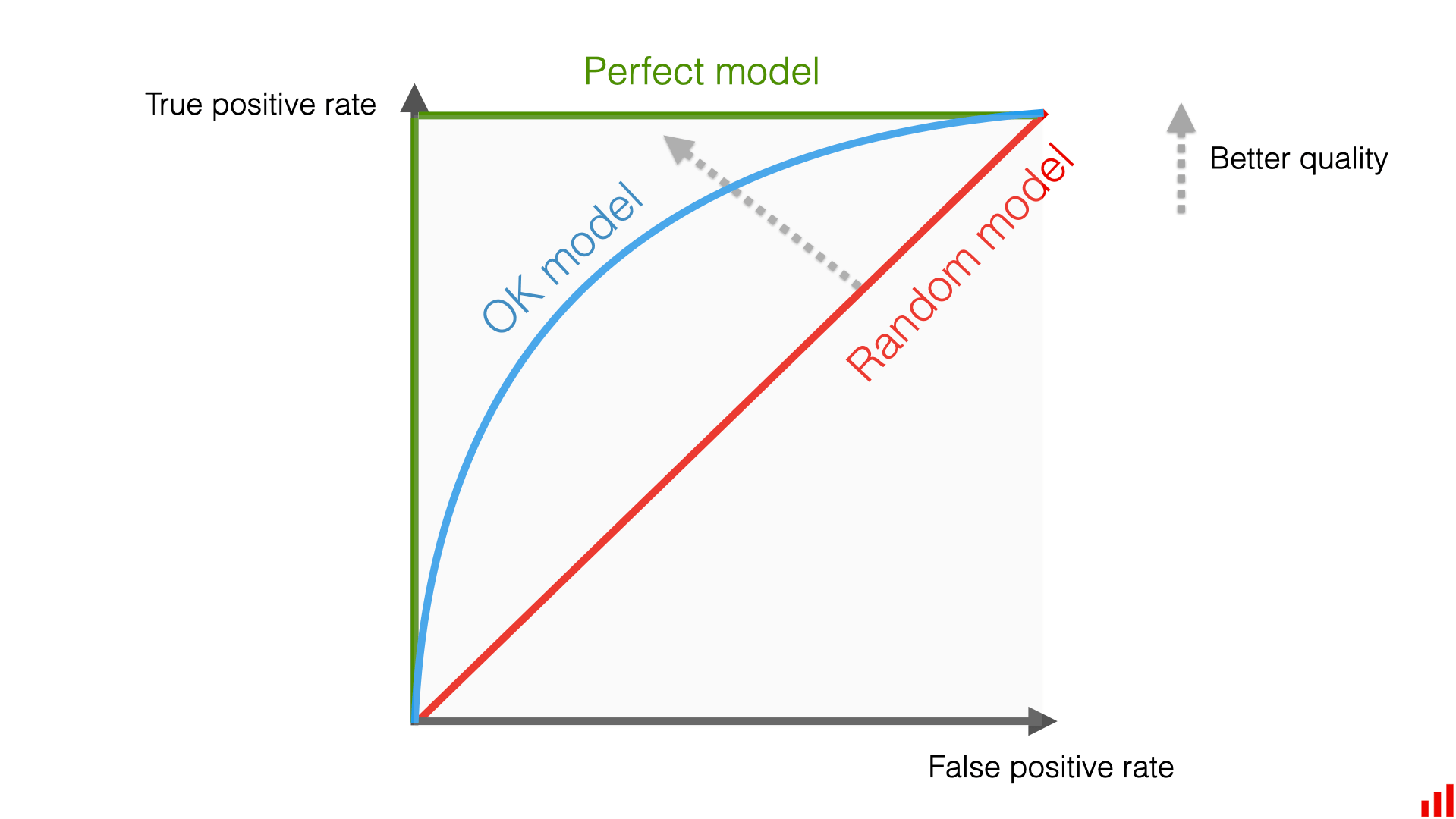
Krzywa ROC
Graficzna ilustracja - wykreślamy krzywą, której punkty wyznaczone są dla klasyfikatorów binarnych powstałych z tego modelu
Przestrzeń 2-wymiarowa [0,1] kompromis między zyskiem a kosztem klasyfikacji
![<p>Graficzna ilustracja - wykreślamy krzywą, której punkty wyznaczone są dla klasyfikatorów binarnych powstałych z tego modelu</p><p>Przestrzeń 2-wymiarowa [0,1]<span> </span>kompromis między zyskiem a kosztem klasyfikacji</p>](https://assets.knowt.com/user-attachments/5cbb08a2-f676-4f4d-a699-bb908a3c3bd7.png)
Punkty charakterystyczne ROC
(0,0):
Sen = 0 => TP = 0 => model nie potrafi rozpoznać pozytywnych jako pozytywne;
1 - Spe = 0 => FP = 0 => negatywne nigdy jako pozytywne
(1,1):
Sen = 1 => FN = 0 => model nigdy nie sklasyfikuje pozytywnych jako negatywne
1 - Spe = 1 => Spe = 0 => TN = 0 => nie potrafi rozpoznać negatywnych jako negatywne
(0,1):
Sen = 1 => FN = 0
1 - Spe = 0 => Spe =1 => FP = 0 :: przypadek idealny
Dlaczego pole pod idealną krzywą ROC jest równe 1
Idealny klasyfikator jest jak najbliżej punktu (0,1)
Pole pod krzywą ROC (czyli AUC area under roc) to prawdopodobieństwo, że klasyfikator nada wyższy wynik losowo wybranemu przypadkowi pozytywnemu niż losowemu negatywnemu. Dla idealnego modelu wszystkie pozytywne mają wynik większy niż wszystkie negatywne, więc to prawdopodobieństwo = 1.
X to FPR, a oś Y to TPR.
Analiza Precision-Recal (PR)
Dokładność z macierzy pomyłek i ROC mogą być wykorzystane do oceny predykcji tylko, gdy liczba rekordów każdej klasy jest względnie równa. Gdy (i) - liczność danych dwóch klas jest zaburzona
i (ii) liczba przypadków negatywnych przeważa, predykcja powinna być oszacowana za pomocą PR
PR ignoruje TN (bo jest ich dużo) → skupia się na wykryciu klasy mniejszościowej (TP, FP i FN).
Skupia się na klasie pozytywnej (mniejszościowej).
Precision = TP / TP + FN (Jak wiele wykrytych pozytywów jest naprawdę pozytywnych?)
Recall = TP /TP + FN (Jak wiele prawdziwych pozytywów model wykrył?)
Wybór modelu do predykcji
1) walidacja prosta
2) k-krotna walidacji krzyżowa (i leave one out)
3) metoda powtarzanego procesu uczenia-testu
4) walidacja krzyżowa wykorzystująca metodę Monte-Carlo (?XDXDXDX)
walidacja prosta
pojedynczy losowy podział wszystkich danych na podzbiór uczący i testowy
80% zbiór uczący, 20% testowy - najczęstsze proporcje
znając przynależność każdego rekordu ze zbioru testowe do klasy, to możemy wyznaczyć wskaźniki oceny modelu
k-krotna walidacja krzyżowa
dzielimy zbiór na k w miarę równych podzbiorów (w których są reprezentanci wszystkich klas), k razy przeprowadzamy uczenie wraz z testowaniem
(na jednym testujemy, na całej reszcie uczymy i powtarzamy to tyle razy ile zbiorów)wybieramy gdy mamy mało elementów albo chcemy, żeby każdy z elementów był kiedyś elementem testowym
LEAVE ONE OUT (LOO) — każdy rekord jest traktowany jako zbiór walidacyjny (jeden element zbioru testowy, reszta uczy) - malo liczne zbiory