Statistiek: H9: Meervoudige lineaire regressie
1/73
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
74 Terms
Wat is de notatie voor een meervoudig lineair model?
Yi = β0 + β1xi1 + β2xi2 + β3xi3 + ... + εi
-> moeilijker om te toetsen dan het enkelvoudige model
-> uitkomst is niet meer binair (het model geldt of niet)
Welke 4 uitkomstmogelijkheden zijn er bij het toetsen van de meervoudige lineaire regressie?
Case: je wenst te analyseren of de variabele uitgaven afhankelijk is van meerdere predictoren nl. "duur" en "leeftijd"
1) het model geldt, met twee predictoren
2) het model geldt met duur als predictor
3) het model geldt met leeftijd als predictor
4) het model geldt niet, duur en leeftijd zijn geen predictoren
Visuele analyse: 2 predictoren
Wat is de R commando voor een 3-dimensionele spreidingsdiagram? (3: je werkt met 3 variabelen: 1 afhankelijke en 2 predictoren)
scatterplot3d
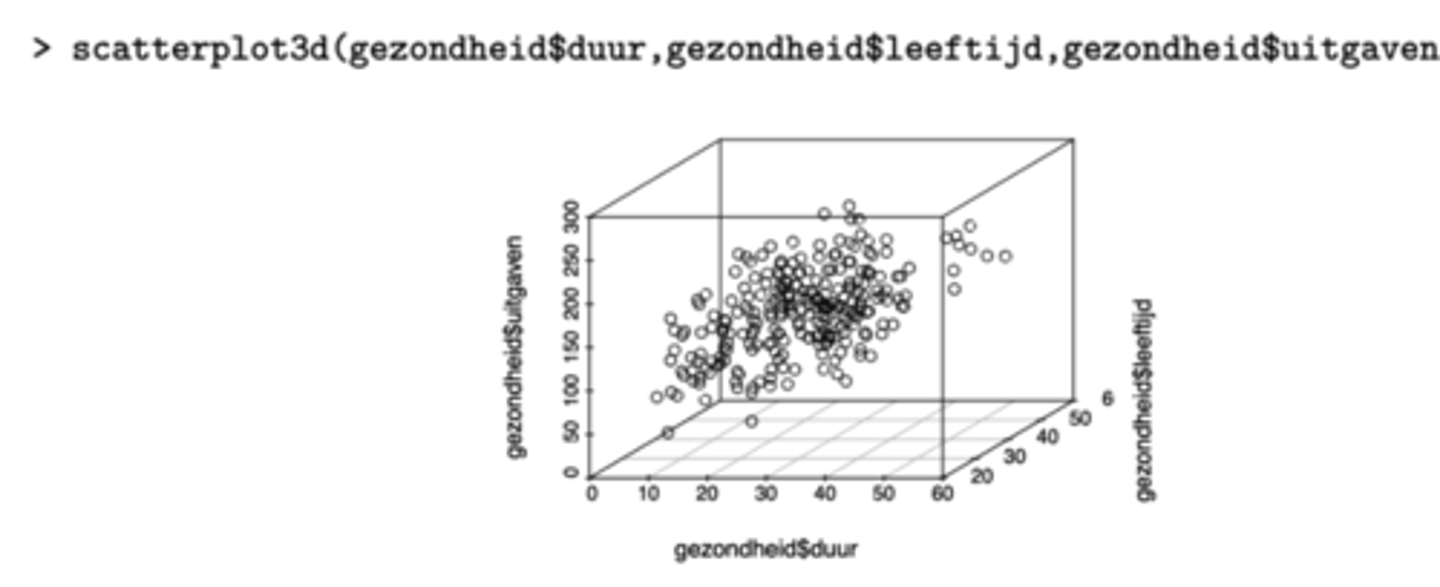
Welk verband is duidelijk te zien op de grafiek?
Welk verband is minder duidelijk om te zien? Wat kunnen we daaraan doen?
- duidelijk: verband tussen duur en uitgaven (stijgend verband)
- onduidelijk: verband tussen leeftijd en uitgaven
-> we kunnen de grafiek roteren om het verband beter te zien, dit kan op 2 manieren
1. gebruiken van de functie plot3D
2. volgorde van de argumenten aanpassen
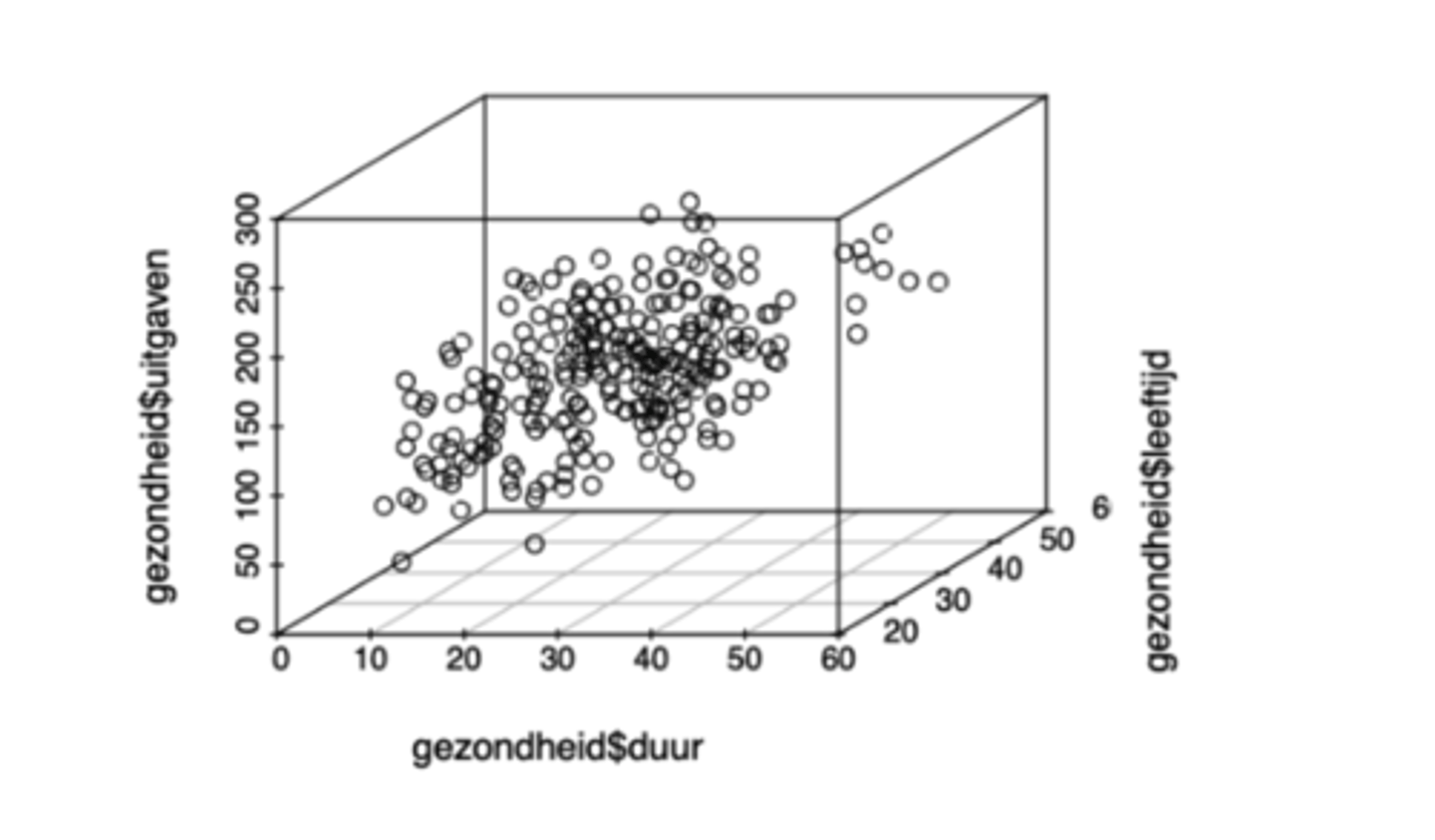
Grafiek die we verkrijgen met de R-functie plot3D
Visuele analyse: met meer dan 2 predictoren
-> kunnen we dit nog makkelijk visualiseren?
We kunnen dit niet meer in eeneens visualiseren, omdat de puntenwolk dan in een ruimte ligt met meer dan 3 dimensies.
Visuele analyse: met meer dan 2 predictoren
-> wat kunnen we doen met de R-functie "pairs"
"pairs" zal alle paarsgewijze spreidingsdiagrammen tekenen: het is een tabel met allerlei bidimensionale spreidingsdiagrammen
! voor nominale variabelen zijn de corresponderende spreidingsdiagrammen niet relevant -> aan R een lijst geven van de variabelen waarvoor we wel een diagram willen
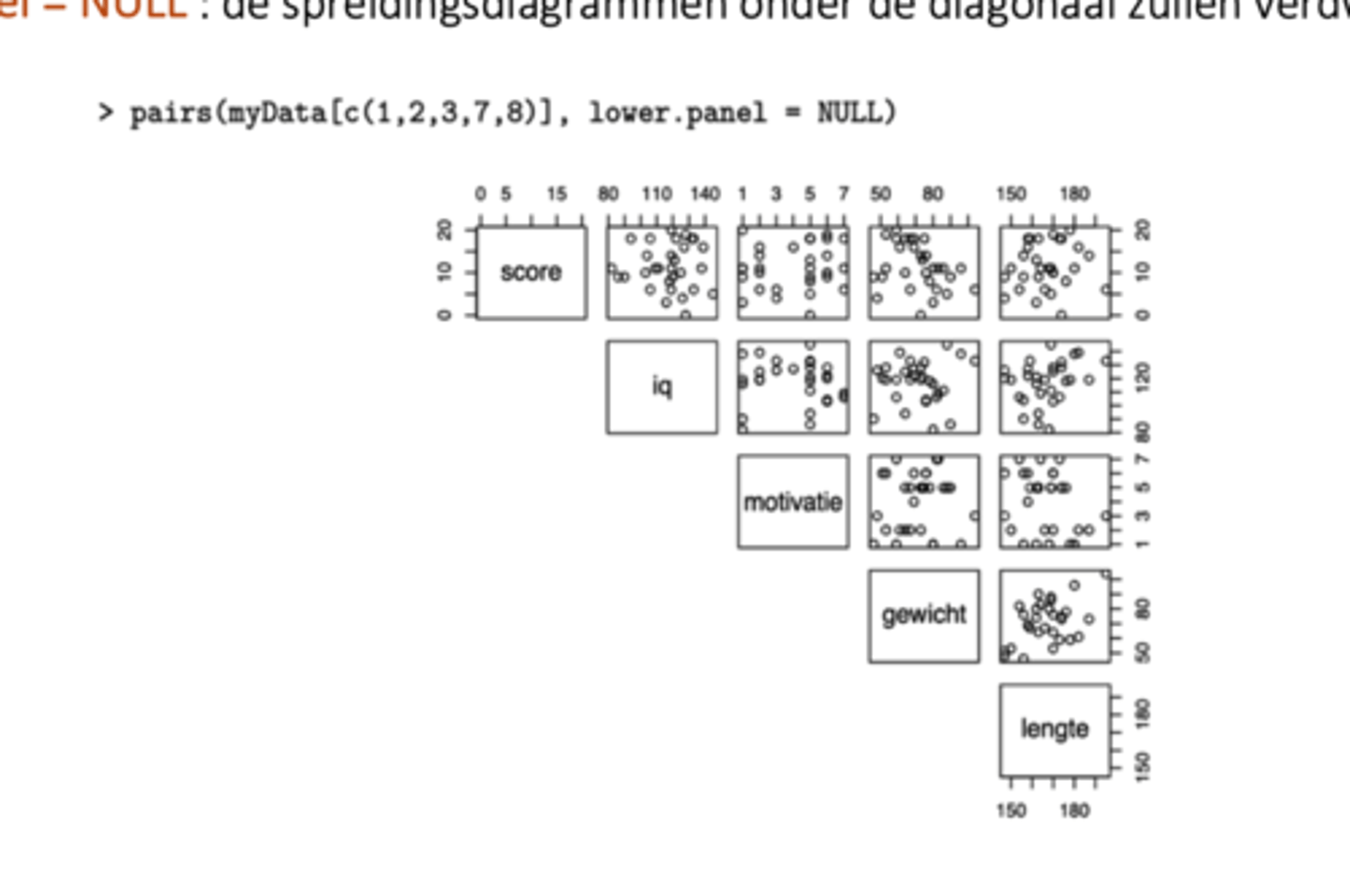
Visuele analyse: met meer dan 2 predictoren
-> waarvoor gebruiken we de functie lower.panel = NULL
alle spreidingsdiagrammen onder de diagonaal zullen verdwijnen
! we kunnen deze functie ook gebruiken als er slechts 2 predictoren zijn!
Het meervoudig lineair model: KANSREKENEN
-> van welk model maken we gebruik?
Yi = β0 + β1xi1 + β2xi2 + β3xi3 + ...βpxip + εi
-> dit is een model met p predictoren
Gauss-Markov assumpties
1) E(εi) = 0 voor alle i
2) V(εi) = (Vεj) voor alle i, j (homoscedasticiteit)
= aan een constante σ²ε
3) COV(εi, εj) = 0 voor alle i, j
-> dankzij deze restricties is het aantal parameters fors gereduceerd
Het meervoudig lineair model - Kansrekenen
De voorwaardelijke verwachting
Iets complexer dan enkelvoudig lineair model: we gaan voor elke predictor een waarde bepalen
De voorwaardelijke verwachting van Y onder de hypothese dat het meervoudig lineair model geldt is:
E(Yi | Xi1 = xi1, ... Xip =xip) = β0 + β1xi1 + ... + βpxip
hypervlak
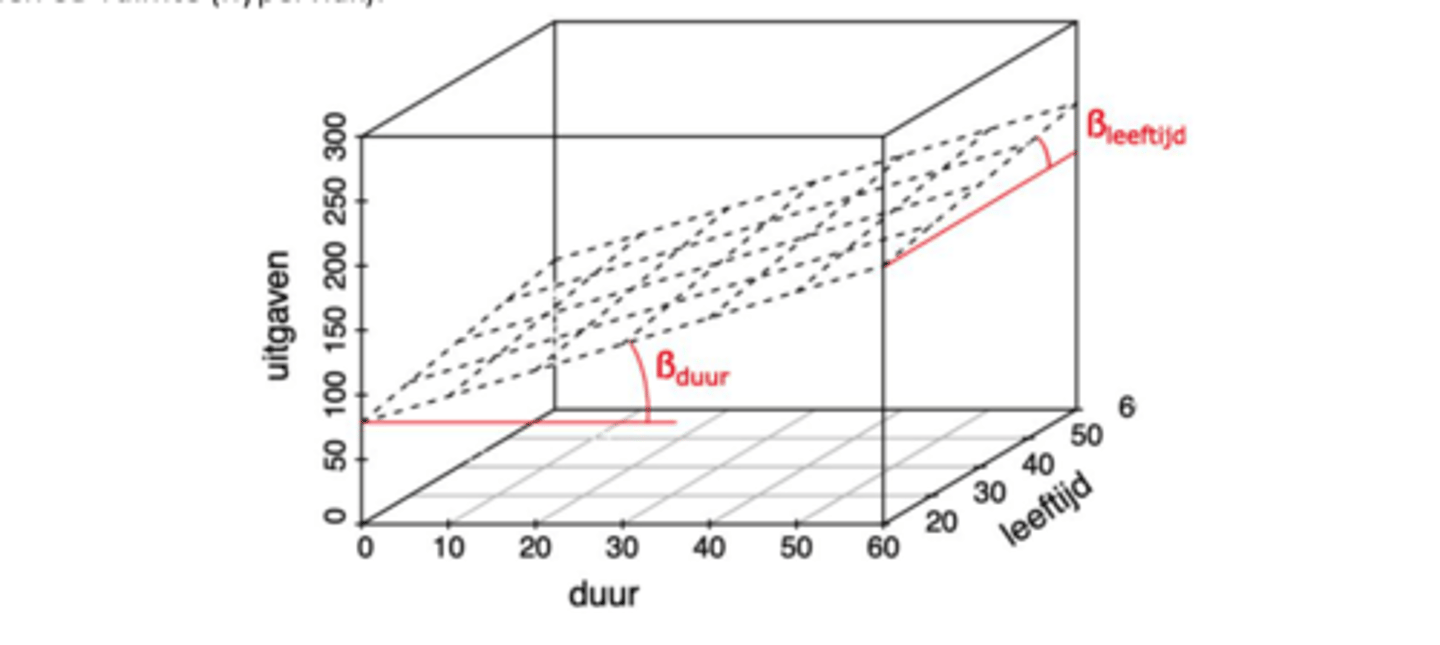
Het meervoudig lineair model- Kansrekenen
De voorwaardelijke verwachting: de populatieresiduen
Yi - β0 - β1xi1 - ... βpxip = εi
Het meervoudig lineair model - Kansrekenen
De voorwaardelijke variantie
V(Yi/Xi1 = xi1, ..., Xip = xip) = σ²ε
De voorwaardelijke variantie van Yi is gelijk aan σ²ε en is onafhankelijk van xij. (Het is dus niet σ²εi !)
Het meervoudig lineair model - Kansrekenen
De correlatiecoëfficiënt
-> wat is het verband tussen de correlatiecoëfficiënt en de regressiecoëfficiënt?
-> wat is de reden voor dit verband?
β₁ = ρXY . σY/σX
reden voor dit verband: beiden hebben betrekking op het verband tussen 2 variabelen (andere manier, maar meten hetzelfde)
Het meervoudig lineair model - Kansrekenen
De correlatiecoëfficiënt
-> waarom is er geen simpele relatie tussen ρXYj en βj?
ρXYj = De correlatiecoëfficiënt tussen de afhankelijke variabele Y en predictor j. Kan nog berekend worden, het wordt berekend los van de andere predictoren
Maar de coëfficiënt βj dat het verband tussen Y en Xj kenmerkt is niet los van de andere predictoren: hij representeert het verband tussen Y en Xj binnen het meervoudig lineair model, dus rekening houdend met de andere predictoren.
=> Voor die reden is er geen simpele relatie tussen ρXYj en βj.
Het meervoudig lineair model - Kansrekenen
Afsluiter: hoeveel parameters bevat het meervoudig lineair model?
-> wat is kenmerkend voor deze parameters?
p + 2 parameters
-> deze zijn bijna altijd onbekend (want de meeste populaties zijn te groot om volledig onderzocht te kunnen worden)
Puntschatting bij meervoudige lineaire regressie
-> op welke basis schatten we parameters?
-> welke methode gebruiken we?
- op basis van een steekproef
- we gebruiken dezelfde methoden als bij het enkelvoudig lineair model, nl. de kleinste kwadraten methode
Puntschatting bij meervoudige lineaire regressie
-> output bij functie "lm"
- + teken = de opsomming van de predictoren (geen optelfunctie)
- uitgaven worden verklaard door de predictoren duur en leeftijd
- de output: de lijst van coëfficiënten van het best passende (hyper)vlak, deze zijn gebaseerd op een steekproef
b0 = 59,26, bduur = 2,02, bleeftijd = 0,95
-> deze coëfficiënten worden gebruikt om de parameters van het meervoudig lineair model te schatten

Puntschatting van βj
-> wat is de beste schatter voor elke predictor j? efficiënt en zuiver?
-> schatting?
- de beste schatter van βj = Bj -> efficiënt en zuiver
- de schatting = bj
Puntschatting van βj: wat zijn 3 principes om de variantie van de schatter zo klein mogelijk te houden?
1. σ²ε moet zo klein mogelijk zijn
2. n moet zo groot mogelijk zijn
3 s2x moet zo groot mogelijk zijn (indien te klein range restriction)
Puntschatting van β0
-> wat is de beste schatter van β0? -> efficiënt en zuiver?
-> schatting?
- de beste schatter van β0 = B0 -> efficiënt en zuiver
- schatting = b0
Puntschatting van β0: wat zijn 3 principes om de variantie van de schatter zo klein mogelijk te houden?
1. σ²ε moet zo klein mogelijk zijn
2. n moet zo groot mogelijk zijn
3 s^2x moet zo groot mogelijk zijn (indien te klein range restriction)
De predicties: in de praktijk kennen we β0 en β1,... βp niet
-> wat gebruiken we dus om predicties te maken?
-> wat is het resultaat?
schatters ipv parameters
-> het resultaat is niet meer een predictie, maar de schatter van een predictie
De variantie van de schatter ^Yi: wat zijn 3 principes om de variantie zo klein mogelijk te houden?
1. σ²ε moet zo klein mogelijk
2. n en s^2x zo groot mogelijk
3. de predictie is beter indien xi1, ...xip dichtbij x̄1, ... x̄p (kleine x)
Puntschatting van σ²ε: wat is de schatting?
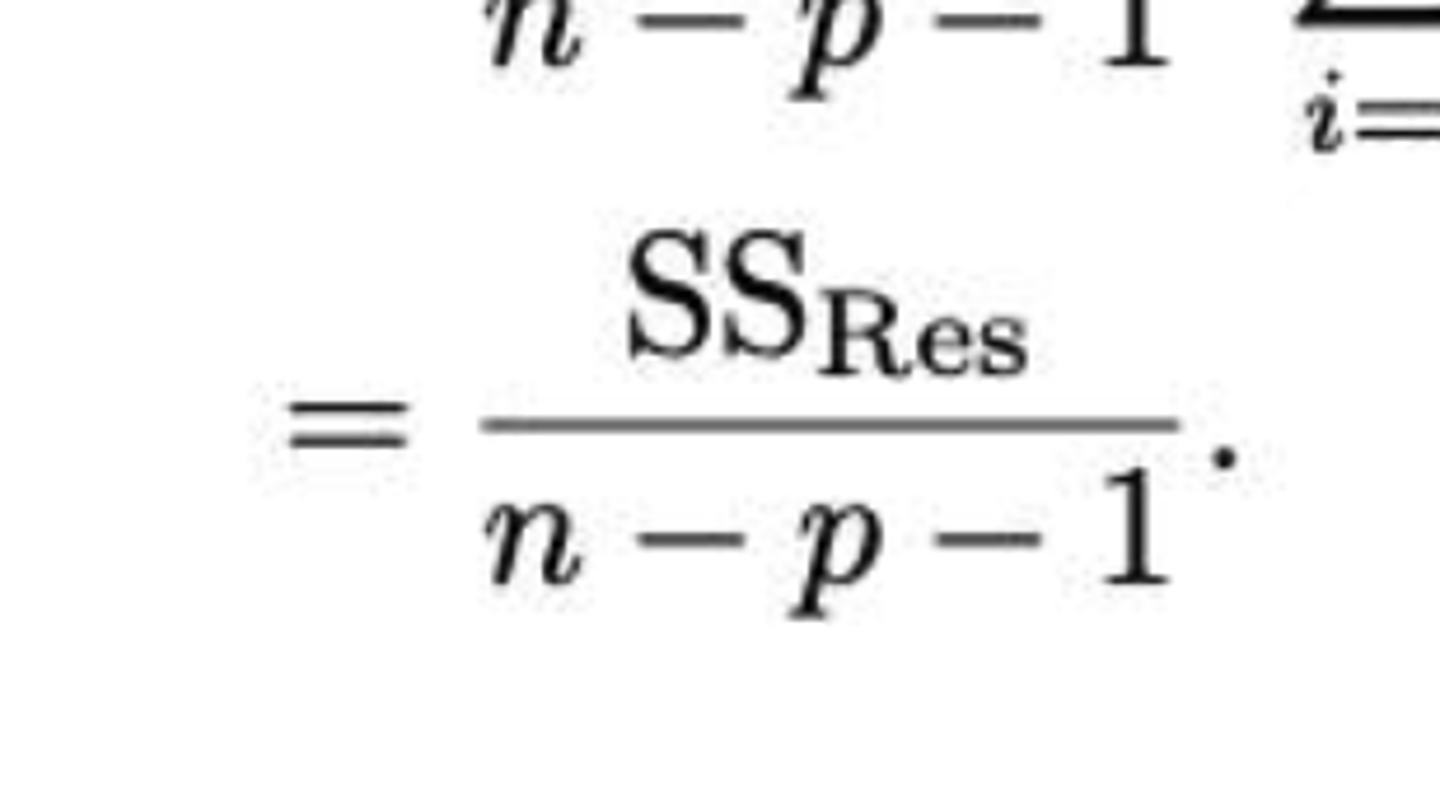
Wanneer treedt collineariteit op?
-> hoe wordt dit ook wel genoemd?
Als twee (of meer) predictoren met elkaar correleren. Dit wordt ook wel multricollineariteit genoemd.
Wat is moeilijk om te doen wanneer de correlatiecoëfficiënt tussen twee predictoren groot is?
Dan is het moeilijk om βj te schatten. Ifv het toeval zal de schatting sterk variëren. De variantie van de schatter zal groot zijn, wat impliceert dat de schattingen niet bruikbaar zijn.
-> Het lineaire model met sterk gecorreleerde predictoren kan dus niet gebruikt worden.
(Multi)collineariteit: wat als ρ bijna nul is? (in de praktijk zal de correlatiecoëfficiënt zelden gelijk zijn aan 0)
Dan is het probleem niet ernstig en mag het genegeerd worden.
Met welke R-functie kunnen we de mate van collineariteit bekijken?
"vif" (variance inflation factor)
(Multi)collineariteit: aan welke waarde is "vif" gelijk in een ideale situatie?
VIF = 1
(Multi)collineariteit: wat wil dit zeggen: VIF =1?
dat er GEEN correlatie is tussen de predictoren
(Multi)collineariteit: wat gaat er gebeuren als sommige predictoren met elkaar correleren?
dan zal VIF toenemen
(Multi)collineariteit:
hoe gaan we dat na in R?
welke uitkomsten zijn al dan niet problematisch?
Nagaan in R:
> myLM <- lm(formula = uitgaven ~ duur + leeftijd, data = gezondheid)
> vif(myLM)
UItkomsten:
alle vif’s = 1 => Perfect, er is geen collineariteit
alle vif’s < 3 => Goed
alle vif’s < 10 maar minstens één vif > 3 => grijze zone
VOORZICHTIG zijn, risico dat de p-waarde niet exact zal zijn + als deze dan rond de 5% ligt dan neem je beter geen beslissing
één of meerdere vif’s > 10 => DUIDELIJKE COLLINEARITEIT -> het model mag NIET gebruikt worden
(Multi)collineariteit: hoe kunnen we het probleem oplossen?
Als (multi collineariteit optreedt moeten we één of meerdere predictoren met grote VIF weglaten
! je hoeft niet altijd de predictor met de grootste VIF weg te laten, inhoudelijke argumenten kunnen ook gebruikt worden om te kiezen welke predictor je wil gebruiken
Intervalschatting: waarvan gaan we uit? (2)
1. de GM-assumpties zijn voldaan
2. de fouten zijn normaal verdeeld
-> εi ~ N (0, σ²ε) voor alle i
Intervalschatting: hoe berekenen we het betrouwbaarheidsinterval?
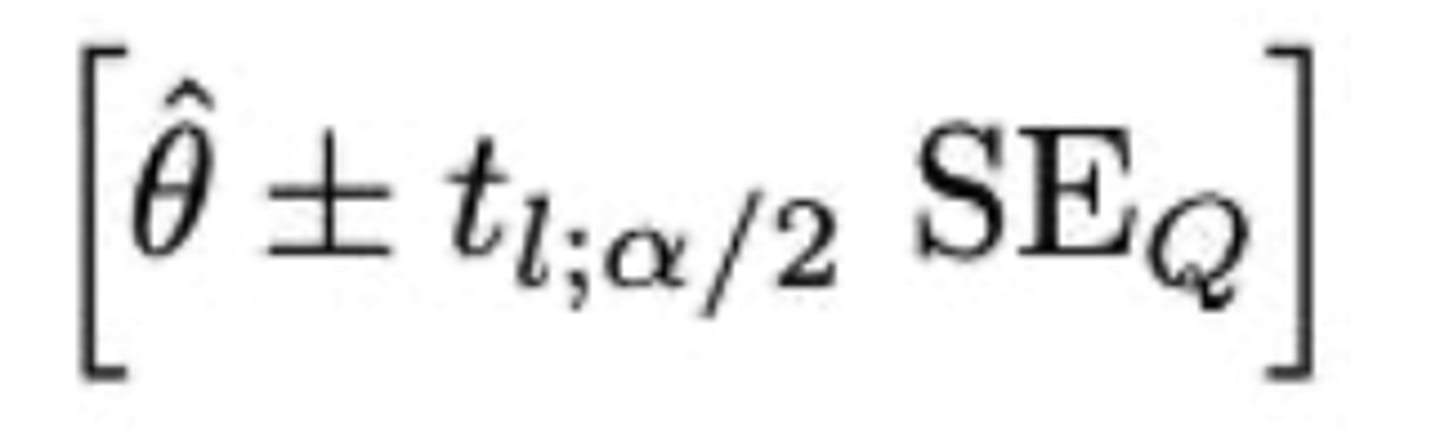
Welke functie gebruiken we om de betrouwbaarheidsintervallen te bepalen?
confint(myLM, level = 0.95)
myLM (je moet de lm die je hebt berekent een naam geven, bv: > myLM <- lm(formula = uitgaven ~ duur + leeftijd, data = gezondheid)
let op: maakt gebruik van het argument level (ipv sig.level of conf.level)
Toetsing: waarvan gaan we uit? (2)
1. GM-assumpties voldaan
2. fouten normaal verdeeld
-> -> εi ~ N (0, σ²ε) voor alle i
Voorwaarden voor de toetsing (4)
- de afhankelijke variabele Y moet continu zijn en van interval of ratiomeetniveau
- de onafhankelijke variabele moet van interval of ratiomeetniveau zijn of 0-1
- de meetfouten moeten normaal verdeeld zijn (normale qq-plot) of de steekproef moet groot zijn
- GM-assumpties moeten voldaan zijn
TOETSING: de coëfficiënt βj = 0
-> hoe luidt de nulhypothese?
-> hoe luidt de alternatieve hypothese?
-> wat gaan we precies toetsen?
-> aan de hand van welke toets wordt dit gedaan?
H0: βj = 0
Ha: βj ≠ 0
-> we toetsen of Xj een predictor van Y is (rekening houdend met andere predictoren <-> bij enkelvoudige lineaire regressie houden we geen rekening met andere predictoren)
> summary(myLM) en een t-toets
Afhankelijk of we een enkelvoudig lineair model of meervoudig lineair model gebruiken, kunnen we andere p-waarden bekomen - hoe komt dat?
OMDAT
we bij een enkelvoudig lineair model GEEN rekening houden met andere predictoren
we bij een meervoudig lineair model WEL rekening houden met andere predictoren
zo kan het zijn dat bij ELM βj geen predictor is en bij MLM βj wel een predictor is
-> als je vermoedt dat Xj niet de enige predictor is en als je over data beschikt mbt die predictoren, kan je gebruikmaken van een MLM. als je geen reden hebt om te denken dat er andere predictoren zijn, dan mag je het ELM gebruiken.
TOETSING: de coëfficiënten βj zijn allemaal 0
-> hoe luidt de nulhypothese?
-> hoe luidt de alternatieve hypothese?
-> wat zullen we precies gaan toetsen?
-> HOE zullen we dat toetsen?
- H0: β1 = ... βp = 0
- Ha: minstens één van de coëfficiënten is NIET 0.
-> we toetsen of het meervoudig lineair model volledig fout is / we gaan het meervoudig lineair model vergelijken met het nulmodel waarbij alle coëfficiënten βj nul zijn.
nulmodel: Yi = β0 + εi
model 1: Yi = β0 + β1xi1 + ... βpxip + εi (alternatieve hypothese)
-> toetsen d.m.v F-toets en corresponderende p-waarde aflezen uit de output (indien p-waarde < 5%, dan kunnen we besluiten dat het lineair model met 2 predictoren beter past dan het nulmodel zonder predictor)
Model vergelijking: model A VS model B
Model A: lineair model met k predictoren
Model B: algemener model met p predictoren
-> model A is genest in model B: model met k predictoren (model A) vormt een subset van het model met p predictoren (model B)
Hoe zullen we aan modelvergelijking doen? (model A VS model B)
We zullen gebruik maken van de residuen van beide modellen, om ze te vergelijken nemen we het verschil van de sum of squares.
-> indien verschil tussen beide groot: evidentie dat model B (met p predictoren) beter is dan model A (met k predictoren)
-> indien het verschil tussen beide klein: we het knn toeschrijven aan toeval
Modelvergelijking: wat is altijd groter: ResA of ResB?
ResA (model A met k predictoren) is altijd groter dan ResB (model B met p predictoren)
ResA past puntenwolk minder goed, omwille van minder gegevens.
Modelvergelijking: hoe bereken je het verschil tussen de residuen van model A en model B?
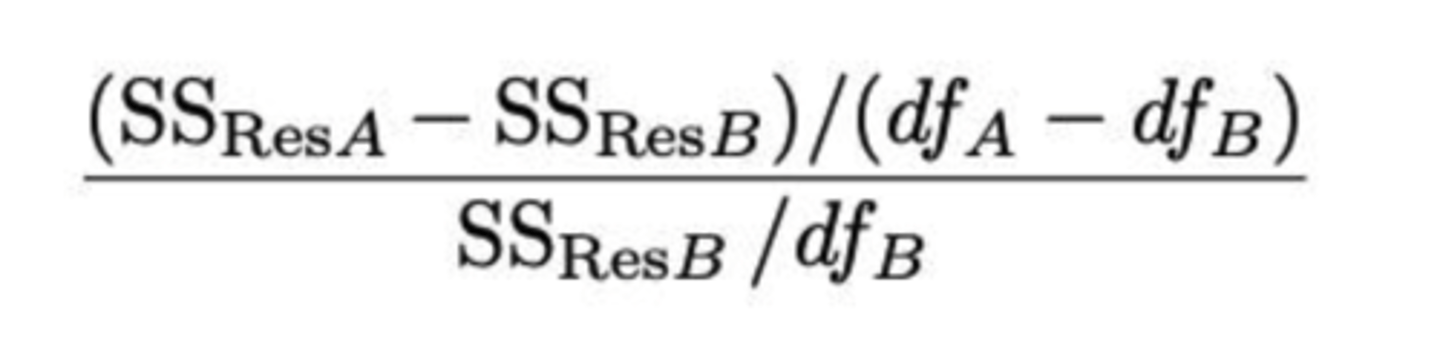
Wat is DfA en DfB?
- DfA: aantal vrijheidsgraden van model A = n - k - 1
- DfB: aantal vrijheidsgraden van model B = n - p - 1
(deze verhouding is F-verdeeld)
Wat doet de R-functie "anova"?
-> wat analyseert het en wat berekent het?
anova = analysis of variance
-> analyseert de varianties van beide modellen (model A VS model B)
-> DAARNAAST: berekent de functie ook de F-verhouding van de vergelijking en de aansluitende p-waarde!
Specifieke vergelijkingen - de regressiecoëfficiënten βj zijn allemaal 0.
-> welke modellen zullen we hier vergelijken?
We vergelijken:
- het model met een aantal predictoren
met:
- het model zonder predictoren (NULL = geen predictoren)
afbeelding: model met een aantal predictoren is beter
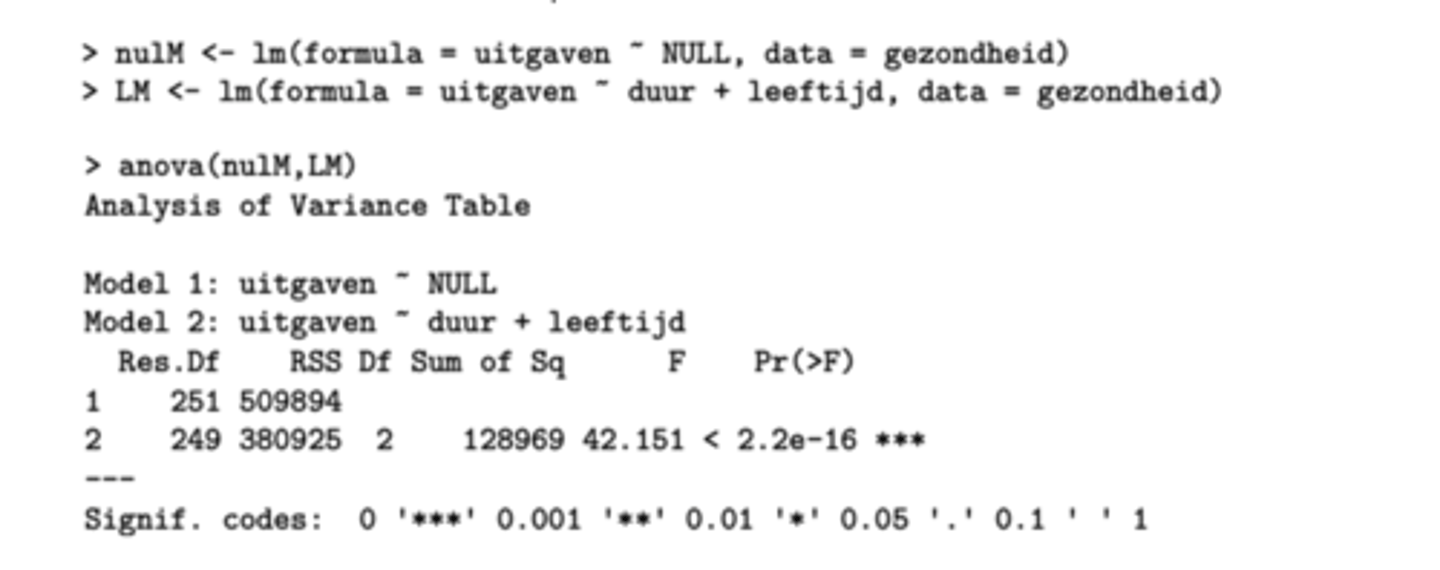
Specifieke vergelijkingen - de coëfficiënt βj = 0
-> welke modellen zullen we hier vergelijken?
> anova(LMA, LMB) (F-toets)
We vergelijken:
model B met p predictoren
met model A met slechts p-1 predictoren
afbeelding: model B is beter dan model A
want p-waarde van de F-toets < 0.05

Selectie van een optimale subset van predictoren: ACHTERWAARTSE SELECTIE
We startsen het meervoudig lineair model met alle potentiële predictoren erin en je gaat telkens één predictor uitsluiten.
DUS:
STAP 1: start met alle predictoren in het model
STAP 2: voer de > summary(lm(formula = … ~ … + … + … + …)) uit
STAP 3: verwijder de predictor met de grootste p-waarde (t-test) en groter dan α (dit is de slechtste predictor)
STAP 4: voer de > summary(lm(formula = … ~ … + … + …))
STAP 5: kijk in die uitkomst of er opnieuw een predictor is met een p-waarde groter dan α, als dat zo is verwijder je die (de grootste als eerst).
-> stop wnr alle p-waarden < α
Selectie van een optimale subset van predictoren: ACHTERWAARTSE SELECTIE
-> welke toets zullen we hanteren bij elke stap?
-> bij elke stap is de kans op een fout van de ... soort gelijk aan ...?
-> wat kiezen we daarom voor α?
-> t-toets bij elke stap
-> bij elke stap is de kans op een fout van de 1ste soort gelijk aan α; de kans op minstens één zo'n fout voor alle stappen is dus groter dan α
-> daarom: kiezen we best een significantie kleiner dan α
Wat is het nadeel van elke methode om de optimale subset van predictoren te selecteren?
-> hoe proberen we dit op te lossen?
daar waar we veel toetsen uitvoeren, telkens met een significantie α, is de kans op minstens één type-1 fout groter dan α
-> we proberen dit op te lossen door een zo klein mogelijke α te hanteren.
Selectie van de optimale subset van predictoren: waarmee werken we best om de validiteit van de technieken te verhogen?
-> wat is daarvoor de vuistregel?
We werken best met steekproeven die groot genoeg zijn. De vuistregel: n/p is best groter dan 40.
Selectie van de optimale subset van predictoren: wat is de beste attitude om nadelen te compenseren?
kruisvalidatie
De determinatiecoëfficiënt R^2
Dezelfde interpretaties als bij het ELM, aangezien definitie en interpretatie onafhankelijk is van het aantal predictoren.
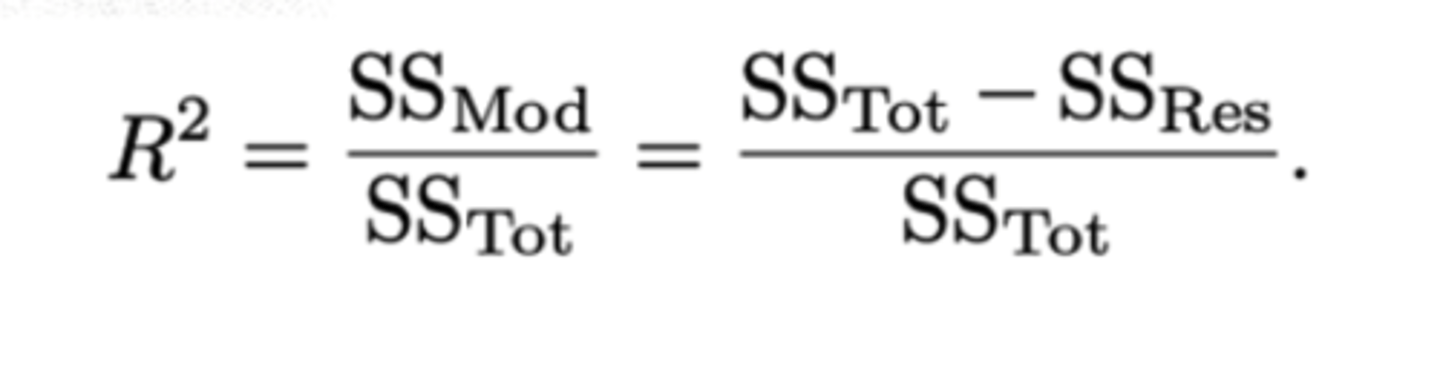
Waar kunnen we de (aangepaste) determinatiecoëfficiënt aflezen in R-output?
Op de voorlaatste lijn van de output van het commando.
De power van meervoudige lineaire regressie: waarvan mogen we NIET spreken? Waarvan wel?
- we mogen NIET spreken van: de power van een meervoudige lineaire regressie
wel van: de power van een specifieke toets (vb. een toets met een specifieke regressiecoëfficiënt)
De power van een specifieke toets (MLR)
-> welke twee modellen wensen we te vergelijken?
-> wat stelt onze nulhypothese hierrond?
-> wat stelt onze alternatieve hypothese hierrond?
- model met k predictoren = model A
- model met p predictoren = model B
-> H0 stelt dat het A-model geldt
-> Ha stelt dat model A niet geldt, maar model B wel.
Met welke R-functie berekenen we de power van een specifieke toets bij MLR?
-> welke 3 argumenten heeft deze functie?
power.f2.test
- aantal vrijheidsgraden in de teller (u): p - k
- aantal vrijheidsgraden in de noemer (v): n - p -1
- de effectgrootte f^2
Formule voor de effectgrootte bij het berekenen van de power van een specifieke toets voor MLR?
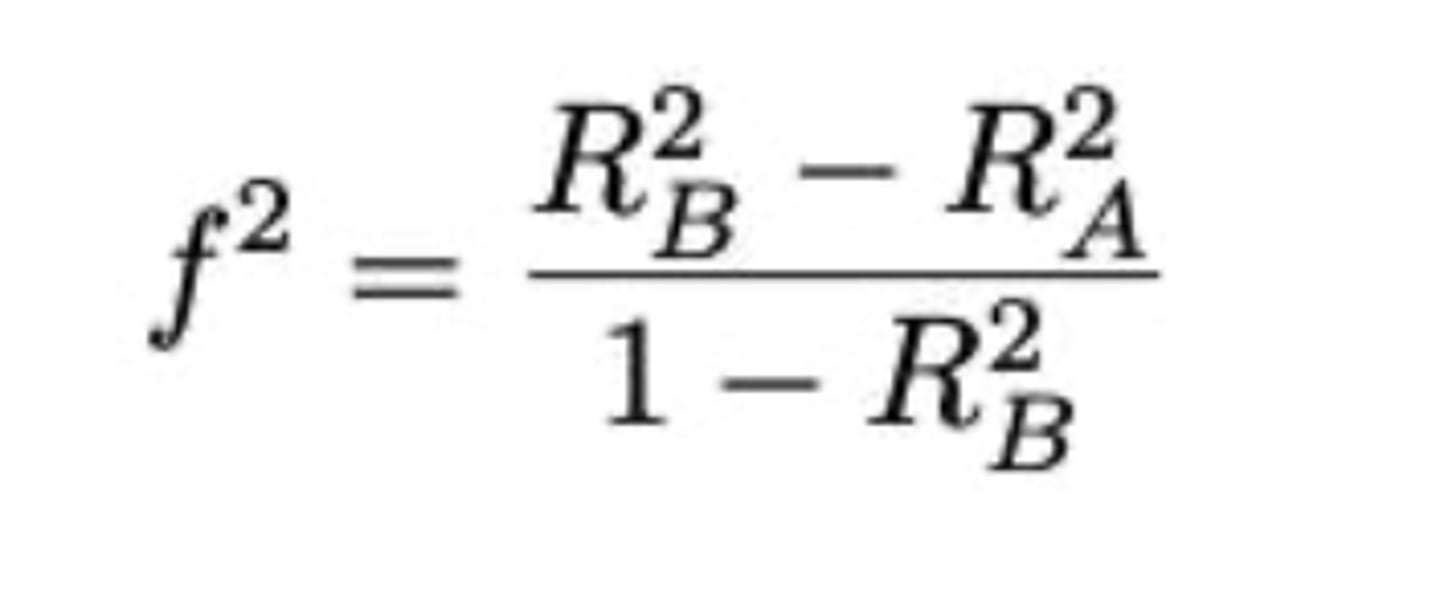
eigenschappen van de effectgrootte
- kan variëren tussen 0 en oneindig, geen duidelijke betekenis (uitspraken zoals: f^2 = 0,15 = matige effectgrootte = zinloos)
- we moeten de effectgrootte dus op basis van R^2 berekenen, maar ook deze zijn moeilijk te interpreteren. -> we knn de waarden uit vroeger OZ of uit pilootOZ overnemen.
De power van een specifieke toets: MLR - alle regressiecoëfficiënten zijn 0
-> welke modellen vergelijk je?
-> welke R2 bekomen we bij model A en B?
je vergelijkt een model A zonder predictoren (nulmodel) met een model B met p predictoren.
model A: we bekomen een R2 van 0, omdat het model geen predictoren heeft, zal het ook niets verklaren
model B: we moeten deze nog berekenen, of opzoeken in literatuur (((of zelf inschatten?)))
De power van een specifieke toets: MLR - de regressiecoëfficiënt βj is nul
-> welke modellen vergelijken we hier?
-> welk model zal meer van de variantie verklaren en waarom?
We vergelijken:
- model A met p - 1 predictoren
met
-een model B met p predictoren
-> model B zal meer variantie verklaren, aangezien ze één predictor meer telt.
-> we gaan na of het verschil tussen de determinatiecoëfficiënten (R^2) groter is dan wat te wijten is aan toeval
Controle van de modelassumpties: de functie plot
-> wat zijn de assumpties van meervoudige lineaire regressie (tip: hetzelfde als bij enkelvoudige lineaire regressie) (2)
- Gauss-Markov assumpties
- normaliteitsassumptie (van de residuen)
Controle van de modelassumpties: de functie plot: wat zal het commando "plot(myLM)" tekenen?
Het zal 4 diagrammen tekenen die ons helpen om de modelassumpties na te gaan. Telkens als je enter drukt, verschijnt er een nieuw diagram.
Controle van de modelassumpties: Residuals vs. fitted - Gauss-Markov 1
-> wat vinden we op de horizontale as en wat op de verticale as?
-> wat betekent elk punt op de rode curve?
horizontale as: predicties
verticale as: residuen
elk punt op de rode curve = een schatting van de voorwaardelijke verwachting van εi
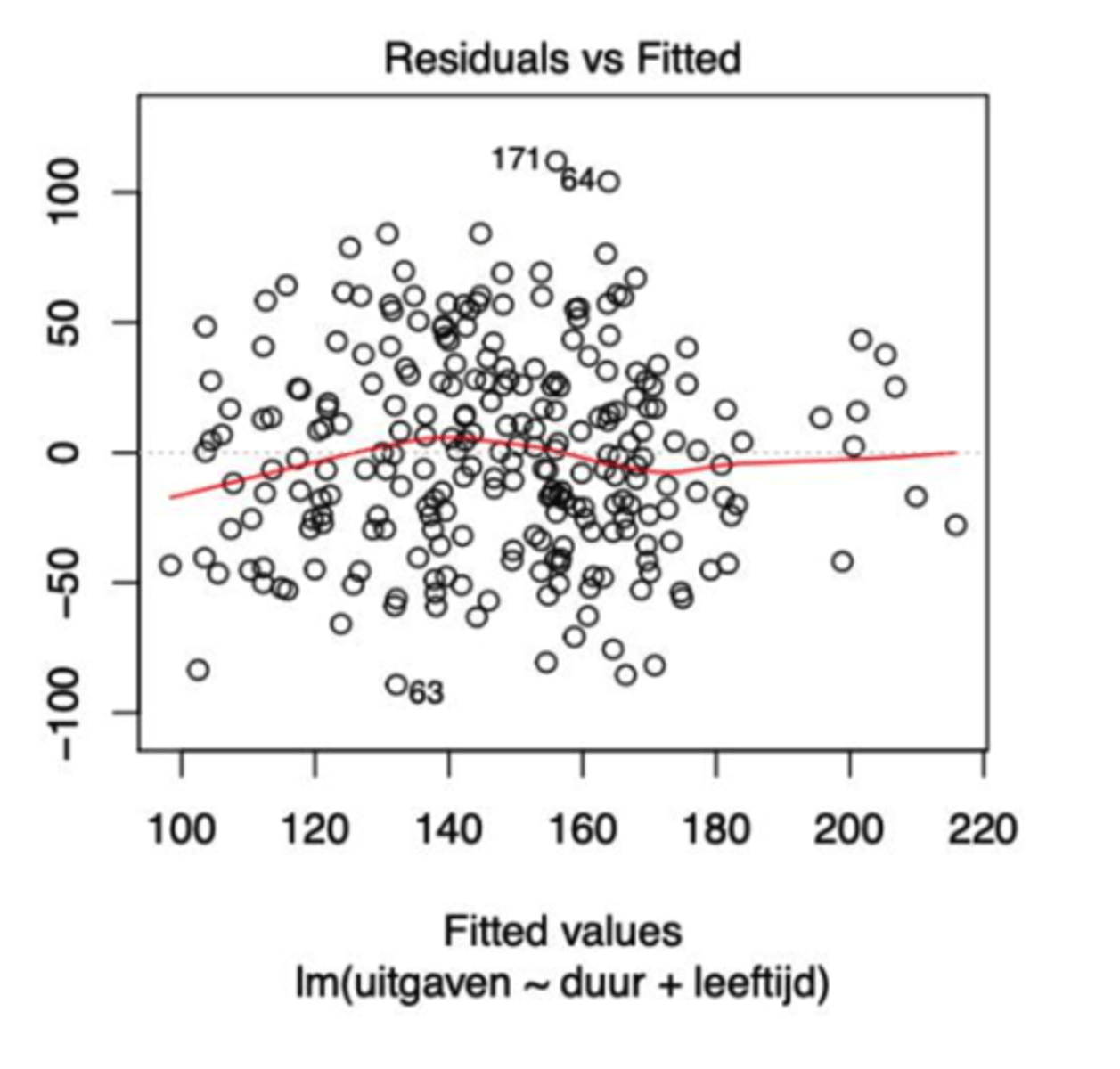
Controle van de modelassumpties: Residuals vs. fitted - Gauss-Markov 1
-> hoe kunnen we uit het spreidingsdiagram afleiden dat er al dan niet voldaan is aan de 1ste assumptie?
1ste assumptie: E(εi) = 0 voor alle i
-> impliceert dat de voorwaardelijke verwachting van de residuen 0 is
-> de rode curve moet ongeveer horizontaal zij, ter hoogte van het nulpunt op de verticale as
op de figuur: we zien GEEN duidelijke afwijking, dus er is aan de 1ste GM-assumptie voldaan
Controle van de modelassumpties: Residuals vs. fitted - Gauss-Markov 1
-> we zien op de spreidingsdiagram enkele punten met een getal ernaast, wat is dat?
outliers of speciale punten
-> het getal representeert het individu in het dataframe
-> het is dan aangeraden om die punten afzonderlijk te bekijken

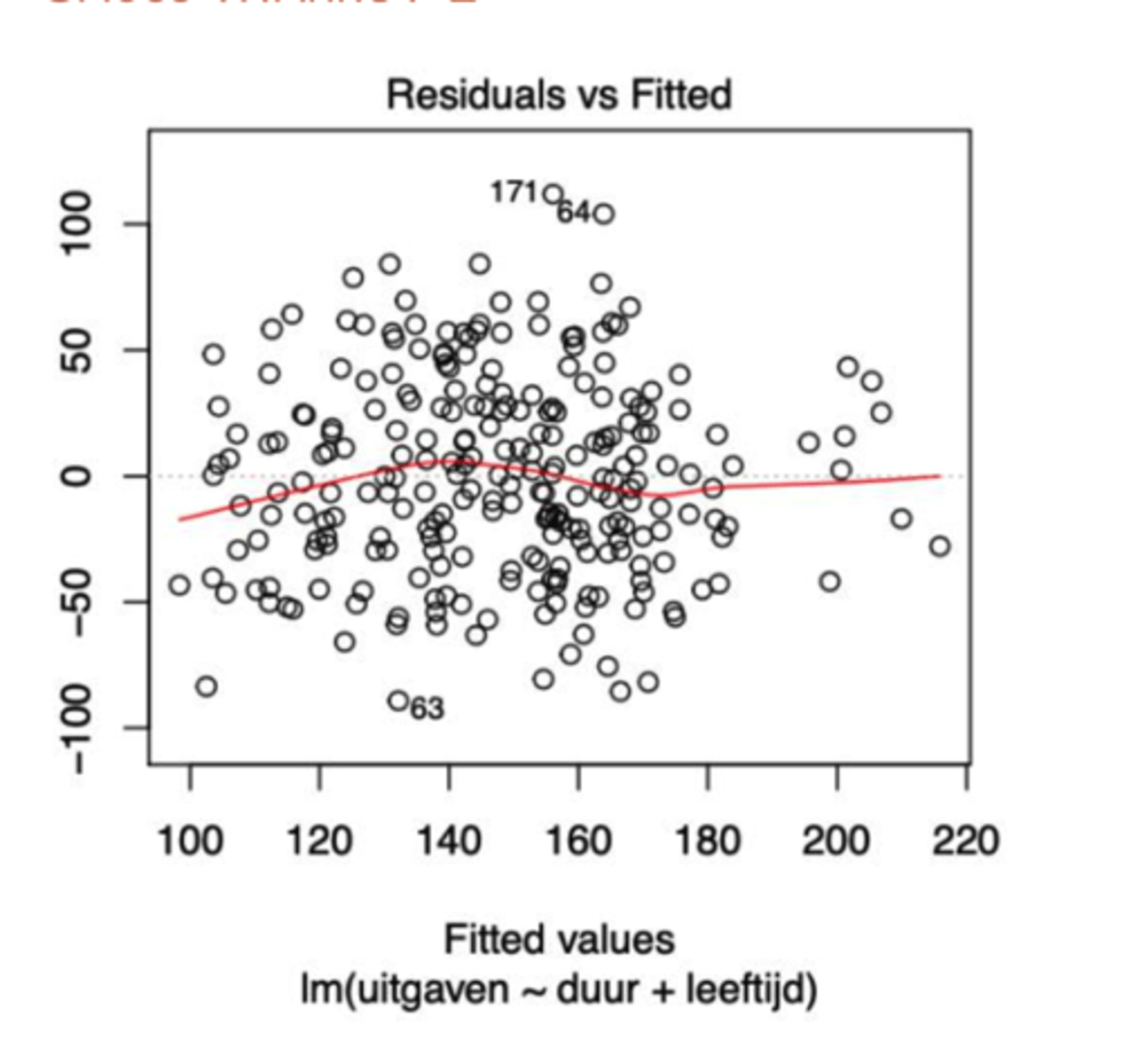
Wordt er op de spreidingsdiagram aan de 1ste GM-assumptie voldaan of niet?
Neen, deze wordt niet voldaan. De schattingen van de voorwaardelijke verwachting zijn niet constant -> de rode curve volgt een paraboolvorm.
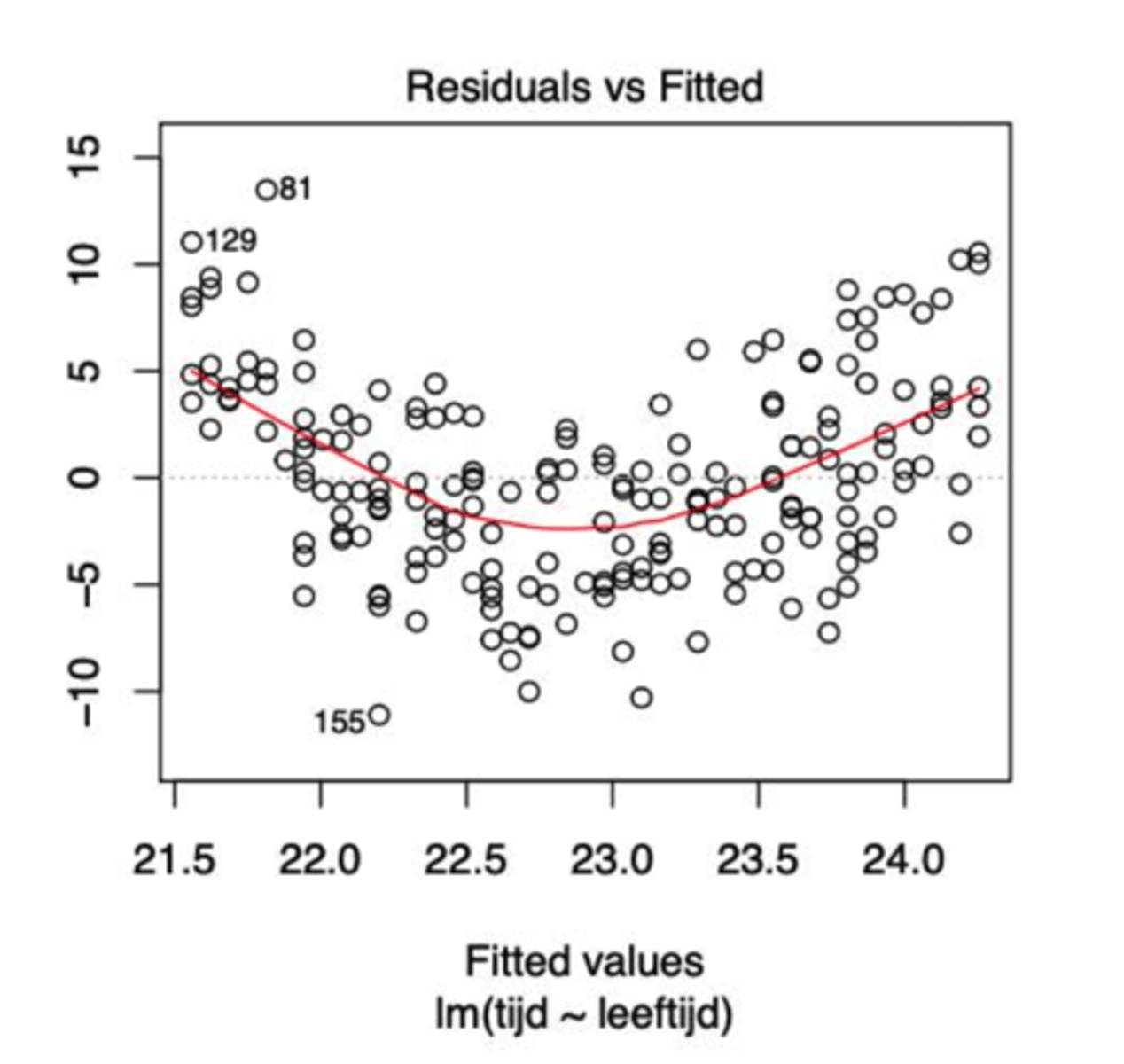
Controle van de modelassumpties: Normal Q-Q - normaliteit
komt overeen met commando qqnorm(residuals(lM))
-> kijken of de punten op de diagonaal liggen zonder afwijkingen
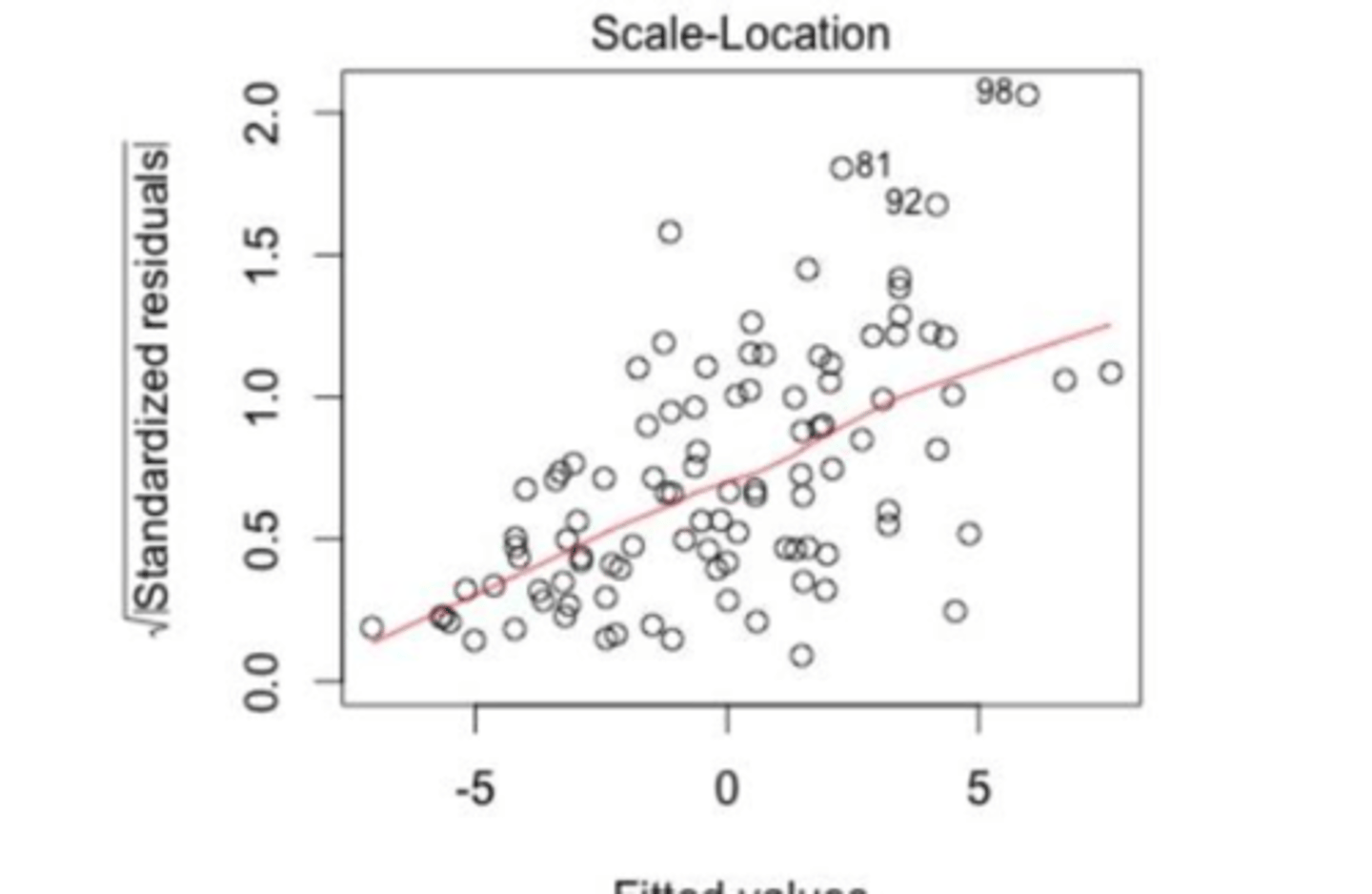
Controle van de modelassumpties: Scale-location - Homoscedasticiteit
-> wat representeert elk punt op de rode curve?
-> is er aan de 2de assumptie voldaan op de spreidingsdiagram?
de schatting van de vierkantswortel uit de voorwaardelijke variantie van Y
2 de assumptie: stelt dat de voorwaardelijke variantie van de residuen constant is -> impliceert dus een normale horizontale curve
spreidingsdiagram: 2de assumptie voldaan
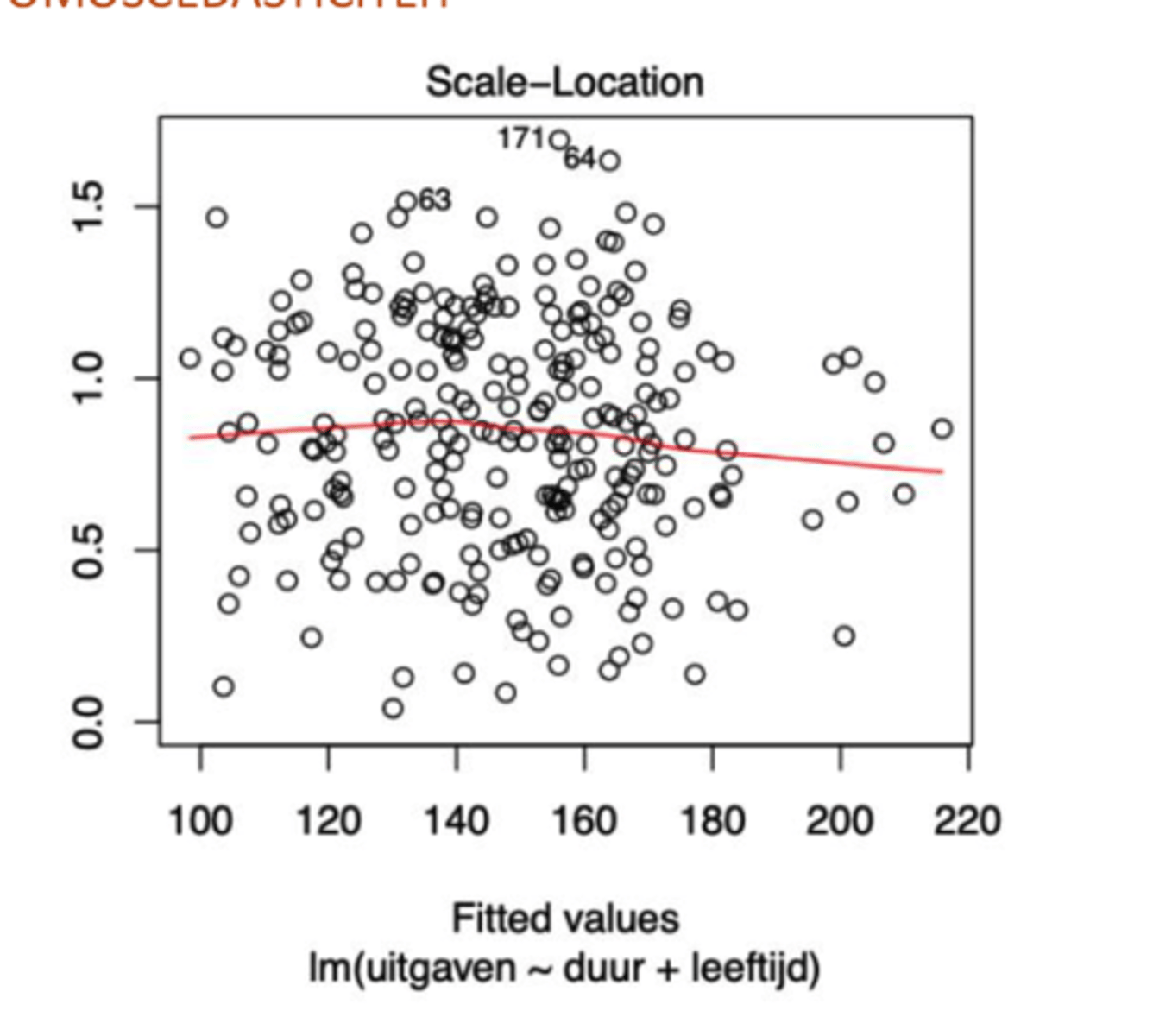
Is er op de volgende spreidingsdiagram sprake van schending van de homoscedasticiteitassumptie?
Ja, de homoscedasticiteitassumptie is geschonden.