ai key terms
1/231
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
232 Terms
what is the definition of AI?
the area of cs which studies rational agents
what problems can AI solve?
object detection, travelling salesman problem (TSP), search problems
what are machine learning problems?
problems that require a model to be built automatically from data
what is supervised learning?
learning with a teacher
what is a teacher for supervised learning?
expected output, label, classes etc.
what does supervised learning solve?
classification and regression problems
what is a classification problem?
predict categorical class labels
what are regression problems?
a prediction of a real value
what is unsupervised learning?
learning without a teacher to find hidden structures/insights in data
what is reinforcement learning?
learning with (delayed) feedback/reward, learning with a series of action
what is the task of formulated supervised learning?
given some input x, predict an appropriate output y
what is the goal of formulated supervised learning?
a function f such that f(x) = y
what is training data?
examples of input-output pairs used in supervised learning
what is training/modelling in supervised learning?
where supervised learning helps to find a good f (function that gives appropriate outputs with given inputs)
what is a prediction in supervised learning?
given an input x, predicting its output, y
what are other terms for input?
attribute
feature
independent variable
what are other terms for output?
target, response, dependent variable
what are other terms for function?
hypothesis, predictor
what is overfitting?
when the training data is fitted ‘too well’
the model learns every irrelevant detail (noise) in a training data set
what is the danger of overfitting?
the model will not work well on new data,
what is linear regression?
a ML algorithm for regression problems
what is gradient descent?
a general strategy to minimise cost functions
what does regression mean?
learning a function that captures the trend between input and output, where the output is a continuous value, to predict target values for new inputs
what is the general rule for univariate linear regression?
find the best line that captures the trend in data
what is a loss function?
criterion hat measures how well a ML mode’s predictions align with actual outcomes
how does loss function work?
quantifies the error/difference between predicted and true values
what is the loss function also known as?
the g-function
what is the vector of partial derivatives called?
the gradient vector
how can linear regression be defined?
a linear and parametric model for regression problems
what is logistic regression?
a linear and parametric model for classification problems
what are K-nearest neighbours?
a non-parametric model that can be used for both classification and regression problems
what is a parametric model?
model that summarises data with a finite set of parameters by making assumptions on data distributions
what is an example of a parametric model?
neural networks
what is a non-parametric model?
model that cannot be characterised by a bounded set of parameters and makes no assumptions on data distribution
what are some examples of non-parametric models?
instance based learning that generate hypothesis using training examples, like kNN, decision trees
what are the three steps for logistic regression?
model formulation
cost function
learning algorithm by gradient descent
why use a cost function for logistic regression?
tells you which parameters are better/worse
why use a learning algorithm by gradient descent for logistic regression?
helps you find the best parameters to minimise the cost function
what is a sigmoid function and what is it used for?
a function that produces an S-shaped curve by mapping any real-valued number into a value between 0 and 1
used in logistic regression and neural networks to model probabilities and make binary classifications
what is a composite function?
a linear function (inner) embedded in the sigmoid function (outer)
what is the decision boundary in a sigmoid function?
the set of all possible inputs where a sigmoid function outputs exactly 0.5
what is a classification boundary in a sigmoid function?
the set of samples that give you a half chance of output
why does the sigmoid function require a new cost function?
MSE (mean squared error) becomes non-convex, meaning there is a bounded sigmoid between output (0,1). gradient descent does not work well on non-convex functions
how is a cost function calculated on a sigmoid function?
using cross-entropy loss, measuring the difference between the predicted probabilities and the actual class outcomes
what is an advantage of using a new cost function on a sigmoid function?
the loss is convex, so it can be minimised easily
what are the basic steps of logistic regression?
given training data, fit the model, by minimising the cross-entropy cost function
what are some extensions of logistic regression?
non-linear logistic regression, multiclass logistic regression
what is non-linear logistic regression?
instead of a linear function inside the expression in the sigmoid, we can use a polynomial function of the input attributes
what is multiclass logistic regression?
uses a multivalued version of sigmoid
what is the ‘no free lunch’ (NFL) theorem?
states that no optimisation or learning algorithm is universally the best-performing algorithm for all problems
what is the implication of the NFL theorem?
if learner A1 is better than learner A2 for a task, f, then there is another task g for which learner A2 is better than learner A1
what does kNN stand for?
k-Nearest Neighbours
what type of algorithm is kNN?
a non-parametric, instance-based model
what does it mean for an algorithm to be non-parametric?
no assumptions are made about the functional form of the model, complexity grows with the data set, allowing them to model complex, nonlinear relationships
what does it mean for an algorithm to be instance-based?
the prediction is based on a comparison of a new point with data points in the training set, rather than a model
why might kNN be called a ‘lazy’ algorithm?
there is no explicit training step, and it defers all the computation until prediction
what can kNN be used for?
both regression and classification problems
how does kNN work generally?
(instead of approximating a model function f(x) globally) kNN approximates the label of a new point based on its nearest neighbours in training data, where k = the radius of a circle that is used to include data, and k can be increased to include more data/decreased to include less data.
when is hamming distance used?
for discrete/categorical values (ie. {rainy, sunny}
what are the inputs for a kNN algorithm?
neighbour size k > 0, distance metric D, training set, a new unlabelled data
what steps are in the kNN algorithm?
for each example in the training set, calculate the distance metric from the new unlabelled data (x^j), and select k training examples closest to the unlabelled data (x^j)
what are the dangers of overfitting?
has worse generalisation performance on data
what are the dangers of underfitting?
has poor generalisation performance on data
what impacts the complexity of the final model when using kNN?
the value for k, as k decides how many samples we use to label the new example
when using kNN, what happens when k is small?
there is a small neighbourhood, high complexity, and a risk of overfitting
when using kNN, what happens when k is large?
there is a large neighbourhood, low complexity, and a risk of underfitting
what value for k do practicians often use in kNN?
often choose k between 3-15, or k < \sqrt N (where N is the number of training examples)
when is learning bias is embedded in kNN?
when attributes have different ranges, the attribute with the larger range is treated as more important by the kNN algorithm
potentially impacting performance if you do not want to treat attributes differently
what is normalisation in kNN?
linearly scaling the range of each attribute, by using the formula
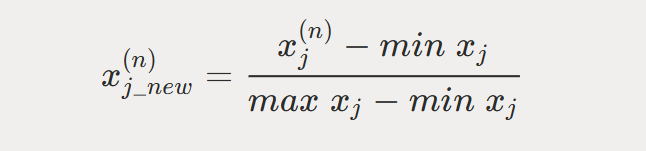
what is standardisation is kNN?
linearly scaling each dimension to have 0 mean and variance 1 (by computing mean and variance)
what is the kNN algorithm with normalisation and standardisation?
normalise and standardise the unlabelled data (x^j).
for each example in the training set, normalise and standardise the example and calculate its distance from the unlabelled data.
select training examples closest to the unlabelled data.
return the plurality vote of labels from the k examples (classification) or the average/median of the y values of the k examples (regression)
what are the advantages of kNN?
non-parametric, instance-based, lazy algorithm
easy to implement and interpret
it can approximate complex functions so it has very good functions
what are the disadvantages of kNN?
need to specify the distance metrics and pre-define k value
it has to store all training data (large memory space) and calculate distance of each training example to the new example
it can be sensitive to noise, especially when k is small
performance is degraded greatly as data dimension increases (curse of dimensionality)
what is the curse of dimensionality in kNN?
as volume grows larger, the neighbours become further apart, the prediction becomes less accurate. distances are less meaningful in high dimensions
what are hyperparameters?
higher-level free parameters
what is the depth in a neural network?
the number of hidden layers
what is the width in a neural network?
the number of hidden neurons in a hidden layout
what is the activation function in a neural network?
choice of non-linearity in non-input nodes
what is a regularisation parameter in a neural network?
a way to trade off simplicity vs fit to the data
how is a predictor obtained?
by training the free parameters of the considered model, using the available annotated data
why evaluate predictors?
serves to estimate its future performance, before deploying it in the real world
how are predictors evaluated?
the available annotated data is split randomly into a training set, used to estimate the free parameters, and a test set, used to evaluate the performance of a trained predictor before deploying it
what methods can be used to evaluate models for model choice?
holdout validation, cross-validation, leave-one-out validation
what is the method for holdout validation?
randomly choose 30% of data to form a validation set
remaining data forms the training set
train your model on the training set
estimate the test performance on the validation set
choose the model with the lowest validation error
re-train with chosen model on joined training and validation to obtain predictor
estimate future performance of the obtained predictor on test set
deploy the predictor
how do you estimate the test performance on the validation set when using holdout validation?
if regression, compute the cost function (MSE) on the examples of the validation set instead of the training set. if classification, compute the 0-1 error metric (not cross-entropy cost!)
what is the method for k-fold cross-validation?
split the training set randomly into k (equal-sized) disjoint sets
use k-1 of those together for training
use the remaining one for validation
permute the k sets and repeat k times
average the performance on k validation sets
what is the last step in k-fold cross-validation?
repeating for other models
choose the model with the smallest average 3-fold cross validation error
retrain with chosen model on joined training and validation to obtain the predictor
estimate future performance of the obtained predictor on test set
deploy the predictor in real world
what is the method for leave-one-out validation?
leave out a single example for validation, and train on all the rest of the annotated data
for a total N examples, we repeat this N times, each time leaving out a single example
take the average of the validation errors as measured on the left-out points
same as the N-fold cross-validation where N is the number of labelled points
what are the advantages of holdout validation?
it is the computationally cheapest
what are the advantages of 3-fold validation?
slightly more reliable than holdout
what are the advantages of 10-fold validation?
only wastes 10%, fairly reliable
what are the advantages of leave-one-out validation?
doesn’t waste data
what are the disadvantages of holdout validation?
most unreliable if sample size is not large enough
what are the disadvantages of 3-fold validation?
wastes 1/3 of annotated data, computationally 3-times as expensive as holdout
what are the disadvantages of 10-fold validation?
wastes 10% of annotated data, computationally 10-times as expensive as holdout
what are the disadvantages of leave-one-out validation?
computationally most expensive
in supervised learning, what is a labelled observation?
where each observation is a tuple (x,y) of feature vector x and output label y, which are related according to an unknown function f(x) = y
what happens during training a supervised learning model?
the labelled observations are used to learn the relationship between x (input) and y (output)
what is the goal of supervised learning?
ensure that the learned model h(x) accurately predicts the output label of a previously unseen, test feature input
what are labels in supervised learning?
the ‘teacher’ during training, the ‘validator’ of results during testing