Key facts for Applied Maths
1/101
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
102 Terms
Chapter 2
Chapter 2
Mean formula in a frequency table
Σfx
———
Σf
(This means 'sum of frequency times x / sum of all frequencies)
Variance formula
∑fx²/∑f - mean²
(mean of the squares minus the square of the mean)
standard deviation
square root of variance
Variance from a list
∑x²/n - mean²
(n = number of values)
State the assumption involved with using class midpoints to calculate an estimate of a mean from a grouped frequency table
Using midpoints assumes that the data is distributed uniformly throughout each class.
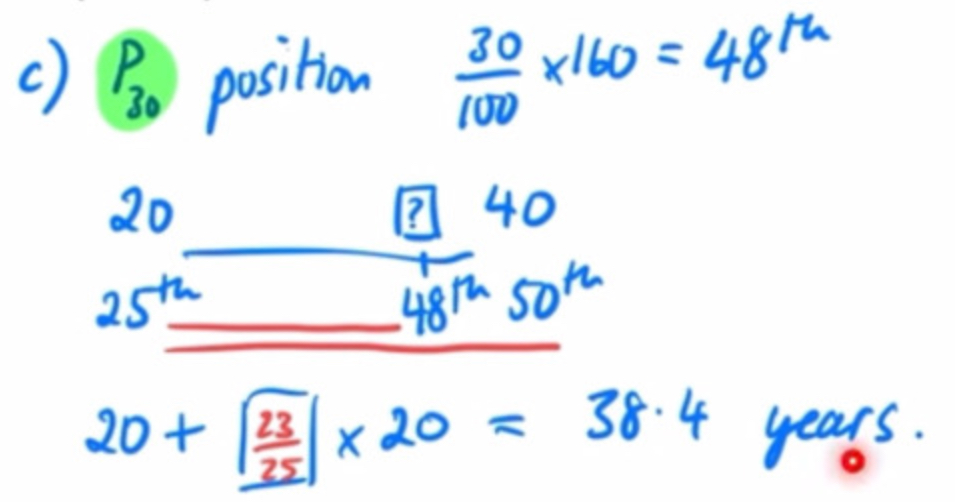
30th percentile — meaning and calculation
30% of scores are at or below this point
The 75th percentile for the weight of cows is found out to be 450kg. What does this mean?
75% of the cows weigh 450kg for less
When doing linear interpolation…
The value of the median/Q1/Q3 don't need to be rounded
Coding
• Mean is affected by +/-, and multiplication/division.
• Variance/standard deviation is only affected by multiplication/division.
Example: Some values were coded using h = 0.1(g - 5). What do you do?
Make g the subject of the equation and use that to find mean and variance/SD.
Chapter 3
Chapter 3
Anomaly
A type of outlier where the data value has been collected incorrectly
Why is it important to clean the data?
To remove any outliers before calculating summary values
What must you do when asked to compare two sets of data?
Compare:
- one of the averages (mean/median)
- the spread of the data (IQR/variance/standard deviation)
(I.e data set two is more varied/consistent than…)
Why should an outlier data value be a) included, b) excluded?
a) Because it is a piece of data and all data should be considered.
b) Because it is an extreme value and could affect the investigation
Histograms
area = k x frequency
frequency = k x area
Chapter 4
Chapter 4
When given a question that asks you to draw a scatter graph, which data set is used as the x axis?
Whichever data set is presented first
Independent variable
AKA predictor/controlled variable.
This is what is being controlled (what I control). It goes on the x axis
Dependent variable
AKA the response variable.
This is what is being measured (not controlled), and it goes on the y axis
What makes estimating other values, using a scatter graph, reliable?
- Making predictions for the dependent variable (y value) using the independent variable (x value), NOT the other way around
- Within the given data range; NO extrapolation
- Strong correlation
- Large sample size
Describe the correlation between distance from the city centre and population density (example)
There is a negative correlation
Interpret your answer to the previous question
As distance from the city centre increases, the population density decreases. (Ensure your answer is in context to the question)
regression line equation
y=a+bx
(a is the y-intercept, b is the gradient)
What is the significance of the value of b on your regression line? (Example: b = -9.84)
- Since b is negative, there is a negative correlation
- As the distance from the city centre increases by 1km, the population density decreases by 9.84 people per hectare.
A graph shows that the number of car accidents and the number of fast food restaurants in a town have a strong correlation. What does this mean?
• The data shows that the number of car accidents and the number of fast food restaurants in a town strongly correlate. However, it does not show that the relationship is causal.
• Both variables could correlate with a third variable, for example the number of roads coming into the town.
Chapter 6
Chapter 6
What is a discrete variable?
A variable that can take only specific numerical values in a given range, e.g. shoe size
What is a uniform distribution?
Where all of the probabilities in the distribution are equal, e.g. rolling a fair dice; the probability of each event occurring is 1/6
The binomial distribution
X~B(n, p)
What does x, n and p represent?
x = the number of successes
n = the total number of trials
p = the probability of a success
X can be modelled with a binomial distribution if… (commonly asked in exams)
• There is a fixed number of trials, n
• There are only two outcomes, either success or failure
• There is a fixed probability of success for each trial, p
• The outcome of each trial is independent of the outcome of any other trial
When do you use PD mode and when do you use CD mode?
PD — when you're looking for the probability of one certain amount of successes. E.g. P(X = 8).
CD — when you're looking for the probability of more/less than a certain amount of successes. E.g. probability of no more than 2 successes = P(X ≤ 2).
Which sign is the one used on the CD distribution on the calculator?
Less than or equal to
P(X < a)
P(X ≤ a - 1)
Example: P(X < 5) = P(X ≤ 4)
P(X > a)
1 — P(X ≤ a)
Example: P(X > 5) = 1 — P(X ≤ 5)
P(X ≥ a)
1 — P(X ≤ a - 1)
Chapter 7
Chapter 7
What is a significance level?
The threshold a probability (p-value) needs to go below for us to reject the null hypothesis (H0) and consider the alternative hypothesis (H1)
How do you set up a hypothesis test answer?
X ~ B(n, p)
H0: p = k
H1: p ? k
significance level: 5%
x value (if needed)
James finds out that the probability of getting 6's on a dice is higher than expected (the p-value of getting 20 sixes is below the significance level of 5%, being 0.035). What do you answer?
0.035 < 0.05 There is sufficient evidence to reject H0 and accept H1, so p > 1/6. James should conclude that the proportion of sixes is higher than expected and the dice may be biased.
What is the test statistic?
What we use to measure whether we should accept or reject the null hypothesis. So in James' example, the test statistic is the number of sixes he rolled.
What do you do in two-tailed hypothesis tests (p ≠ k), when you're trying to find out the critical region?
Halve the significance level for each tail
What is the p-value?
Probability value we find in hypothesis tests (AKA the significance level).
Probability above which the null hypothesis is true.
In a two-tailed hypothesis test, it is found out that the probability that P(X ≤ 4) = 0.015 is below the significance level of 0.025. What is the p-value?
The p-value is the actual significance level. In order to find this, you must double 0.015 so that you find the p-value in both tails, which is 0.03.
Modelling — how to criticise the model? Comment on… (8)
- Particle
- smooth
- light
- light string
- inextensible string
- smooth pulley
- value of g
- constant resistance
Particle
Meaning: Dimensions of object are negligible
How it is used in calculations: Air resistance can be ignored, dimensions can be ignored
Smooth
Meaning: no friction
How it is used in calculations: frictional forces can be ignored
Light
Meaning: has no mass
How it is used in calculations: mass can be ignored
Light string
Meaning: the string has no mass
How it is used in calculations: tension is equal throughout the string
Inextensible string
Meaning: the string cannot stretch
How it is used in calculations: if connecting two particles, the acceleration of both particles is equal
Smooth pulley
Meaning: there is no friction at the pulley
How it is used in calculations: the tension in the string either side of the pulley is equal
If g = 9.8, then…
Use a more accurate value for g
If there is constant resistance, then…
Have resistance vary with speed
If a particle is used, then…
- consider the dimensions of the body
- take spin of the body into account
- include air resistance
If the object is smooth, then…
Take friction into account
If the object is light, then…
Take mass into account
If the question is about projectiles/something being flown/etc., then…
Take wind speed and direction into account
Regression and correlation y2
What is the PMCC?
The product moment correlation coefficient, r.
It measures the strength of correlation, and whether it is positive or negative. It can take on any value between 1 and -1.
E.g. if r = 1, the points are perfectly correlated and lie on a straight line with positive gradient.
What is a regression line?
The mathematically calculated line of best fit.

Log rules reminder

What are the two types of equation that a linear model can be used for?


How do we simplify the two types of equation to make them into a linear model, and draw the graph for both.

What is the PMCC?
The product moment correlation coefficient, r.
It measures the strength of linear correlation in a set of bivariate data, and whether it is positive or negative.
It can take on any value between 1 and -1.
E.g. if r = 1, the points are perfectly positively correlated and lie on a straight line with positive gradient. The opposite for -1.
If r is close to 0, there is little correlation between the data.
Any value above 0.5 shows pretty good correlation.
r doesn’t get affected by scale (e.g doubling all the x values does nothing for r)
Comment on the suitability of a linear regression model when a) r = 0.95, b) r = -0.32
a) Given that r is close to 1, this shows very strong positive linear correlation so a linear model would be suitable.
b) A linear regression model is not the most suitable for these data as the r value is closer to 0 than it is to -1, showing a weak negative correlation. There may be other variables affecting the relationship or a different model might be a better fit.
How to find PMCC?
Statistics → 2-variable → reg results → find r-value.
What is r and p in zero-correlation hypothesis testing?
r = PMCC of a sample
ρ = PMCC of a population (Greek letter rho)
Year 2 probability
Conditional probability formula
P(A|B) = P(A n B)/P(B)
If events are independent, then…
P(A) x P(B) = P(A n B)
P(A|B) = P(A)
If A and B are mutually exclusive…
P(A n B) = 0
P(A u B) = P(A) + P(B)
Normal distribution
What is the normal distribution and what can it be used to model?
It is a continuous probability distribution and it can be used to model things like heights of people and the time taken to get to school.
We get a bell shaped curve with probability density on the Y axis and another variable on the X axis, for example, height.
The distribution is always symmetrical, so the median equals the mean which equals the mode.
There are asymptotes at each end of the curve.
The area under each curve is 1, i.e. the total probability.
What will the calculate do for the inverse normal distribution function?
Less than. E.g. P(X > a) = p.
What is the mean and variance/SD for the standard normal distribution?
Mean = 0, variance/SD = 1.
How do we convert a normal distribution to a standard normal distribution?
z=σ(X−μ)
Standardise the following: X~N(130, 25) to find P(X > 124)

What conditions need to be satisfied to model a binomial distribution to a normal distribution?
If n is large, so that the distribution curve looks curved
If p is close to 0.5, so that the distribution curve is symmetrical
Note: binomial distribution measures discrete values.
When modelling a binomial distribution as a normal distribution, how do we find the mean and the variance?
Mean = np
Variance = np(1-p)

What must we remember to do with finding the probabilities one modelling a binomial distribution as a normal distribution?
remember that a single number represents a range of values, e.g. 5 ≈ 4.5 < x < 5.5
P(X > 5)
P(X ≤ 3)
P(Y > 5.5)
P(Y < 3.5)
Remember that Y represents the ND.
When a particle is accelerating/travelling in the direction of a particular vector… (e.g. - 3i - 4j)
J-component / i-component = ¾ (positive)
What would happen to an object’s motion if a new model included air resistance?
Air resistance would slow down the object
When given the start and end point of a particle (in vector form)…
Put the start and end point on opposite sides of the equation/equals sign.
Why does the frictional force on point A of a ramp act in a particular direction?
Because the frictional force at A must oppose the normal reaction at B (the wall).
How do you find the magnitude of the resultant force acting on a particular point?
Square root of the (frictional force squared plus the normal reaction squared). Magnitude always involves doing this
In a pulley system, the weight hanging off the pulley (less than the weight on the ramp) moves how?
Moves upwards with constant acceleration. On a v-t diagram, this looks like a straight line with a constant slope.
In reality, the string is not light. What does this mean?
The tension acting on the two masses would not be equal.
If the object is stationary, friction is…
Friction is less than or equal to F max.
A much heavier brick is placed on an inclined rough plane. The previous brick was in limiting equilibrium. What will happen to this new brick?
It will remain at rest on the plane. This is because friction is proportional to the weight component, and when a new brick is placed on the plane, the friction will increase by the same proportion as the weight component.
A brick in limiting equilibrium is projected wth speed 0.5ms^-1 down the plane. Describe its motion and why
Since the brick was at rest, it means it had no resultant force down the plane.
No resultant force means no acceleration as we know from F=ma.
Therefore, the brick would slide down the plane with constant velocity (and not accelerate).
Why does the reaction force act in a direction that is perpendicular to the plane?
Because the plane is smooth
How do we know that we must test for the upper or lower tail in a two-tailed hypothesis test?
If the random sample produces a result that’s higher or lower than the null hypothesis.
When asked to find the probability distribution, you must…
Draw the whole table out
A histogram is modelled by a normal distribution. Why might this not be suitable?
Because the data in the histogram is not symmetrical, like the bell curve of a normal distribution.
When given boundaries, question whether…
Whether some results might lie outside of these bounds
When asked to ‘interpret the nature of the relationship’ between two variables…
Give your answer in the specific context of the question
A female is chosen at random from those with heights between 150cm and 175cm. How to find the probability that her height is more than 160cm?
You must use conditional probability formula