kartkówki obydwie stata III
1/136
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
137 Terms
Zaznacz czy dane stwierdzenie jest prawdziwe (P) czy fałszywe (F):
a) zmienna niezależna w teście t dla prób niezależnych może być na skali nominalnej
b) na podstawie analizy wariancji wyciągamy wnioski odnośnie różnic średnich w grupach
c) w teście chi-kwadrat liczba stopni swobody zależy od ilości celek
d) zmienna niezależna w analizie wariancji może być na skali nominalnej
a) P
b) P
c) P
d) P
(R - 1) x (C – 1) to liczba stopni swobody:
a) efektu interakcyjnego
b) wariancji błędu
c) efektu głównego w kolumnach
d) ogólnej sumy kwadratów
a) efektu interakcyjnego
Założenie o sferyczności dotyczy
a) Wewnątrzobiektowej zmiennej zależnej
b) Międzyobiektowej zmiennej niezależnej
c) Wewnątrzobiektowej zmiennej niezależnej
d) Zmiennej grupującej
c) Wewnątrzobiektowej zmiennej niezależnej
Dwie grupy studentów (znających i nie znających książki) zaproszono na pokaz kolejno trzech części filmu „Władca Pierścieni”, a po każdej z nich proszono ich o ocenę, na skali od
1 – film bardzo mi się nie podobał do 7 – film bardzo mi się podobał.
Jakim testem zanalizowano wyniki?
a) Jednoczynnikowa analiza wariancji
b) Jednoczynnikowa analiza wariancji w schemacie wewnątrzgrupowym
c) Dwuczynnikowa analiza wariancji w schemacie wewnątrzgrupowym
d) Dwuczynnikowa analiza wariancji w schemacie mieszanym
d) Dwuczynnikowa analiza wariancji w schemacie mieszanym
P/F
Przy równych liczebnościach grup analiza wariancji jest odporna na złamanie założeń
P
P/F
Na podstawie analizy wariancji wyciągamy wnioski odnośnie różnic średnich w grupach
P
P/F
Zmienna niezależna w analizie wariancji może być na skali nominalnej
P
P/F
W analizie wariancji każda zmienna niezależna musi mieć co najmniej 3 kategorie
F
P/F
W analizie wariancji zmienna zależna powinna być na skali co najmniej porządkowej, niezależne - na nominalnej
F
zależna → ilościowa (czyli conajmniej przedziałowa)
niezależna → dowolna
P/F
Najważniejszym założeniem analizy wariancji jest normalność rozkładu
F
Które z poniższych stwierdzeń jest prawdziwe? W analizie wariancji:
a) każda zmienna niezależna musi mieć co najmniej 3 kategorie
b) zmienna niezależna może być na skali nominalnej aby policzyć dla niej dopasowanie do wielomianu
c) zmienna zależna powinna być na skali co najmniej porządkowej, niezależne - na nominalnej
d) zmienne niezależne mogą być na dowolnej skali, zależna - na co najmniej przedziałowej
d) zmienne niezależne mogą być na dowolnej skali, zależna - na co najmniej przedziałowej
Dopasuj odpowiedni test statystyczny do problemu badawczego:
Czy drużyny strzelają średnio więcej goli w meczach rozgrywanych w godzinach rannych, po południu czy wieczorem?
Jednoczynnikowa ANOVA
Dopasuj odpowiedni test statystyczny do problemu badawczego:
Czy średnia liczba goli strzelonych w ciągu całych mistrzostw różni się między drużynami z Ameryki, Azji, Europy i Afryki?
Jednoczynnikowa ANOVA
Dopasuj odpowiedni test statystyczny do problemu badawczego:
Czy występują różnice w średniej liczbie goli strzelonych przez drużyny grające w SPODENKACH o kolorze jasnym lub ciemnym oraz w KOSZULKACH o kolorze jasnym lub ciemnym?
Dwuczynnikowa ANOVA
Dopasuj odpowiedni test statystyczny do problemu badawczego:
Reprezentacja Portugalii wygrała (łącznie z eliminacjami) 8 meczy a 4 przegrała, reprezentacja Senegalu wygrała 9, a przegrała 3 mecze. Jakim testem sprawdzisz czy wyniki tych drużyn istotnie różnią się od siebie?
Chi kwadrat

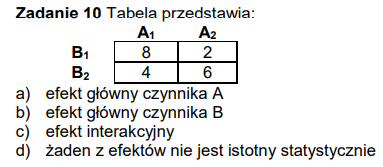
Wielokrotnego wyboru
b) efekt główny czynnika B
c) efekt interakcyjny

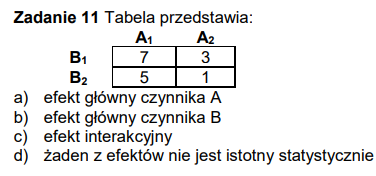
Wielokrotnego wyboru
c) efekt interakcyjny
Wielokrotnego wyboru
a) efekt główny czynnika A
c) efekt interakcyjny
Wielokrotnego wyboru
a) efekt główny czynnika A
b) efekt główny czynnika B
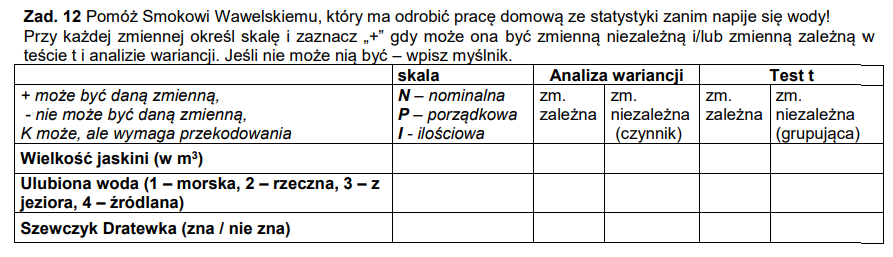
1. Wielkość jaskini (w m²)
Skala: I (ilościowa – metry kwadratowe to liczba)
ANOVA:
zmienna zależna: + (bo ilościowa)
zmienna niezależna (czynnik): – (czynnik musi być jakościowy)
Test t:
zmienna zależna: +
zmienna niezależna (grupująca): –
2. Ulubiona woda (1–4: typ wody)
Skala: N (nominalna – kategorie, liczby to tylko etykiety)
ANOVA:
zmienna zależna: – (bo nie jest ilościowa)
zmienna niezależna (czynnik): +
Test t:
zmienna zależna: –
zmienna niezależna (grupująca): +
3. Szewczyk Dratewka (zna / nie zna)
Skala: N (nominalna – zmienna binarna)
ANOVA:
zmienna zależna: –
zmienna niezależna (czynnik): +
Test t:
zmienna zależna: –
zmienna niezależna (grupująca): +
Efekt główny czynnika A występuje, gdy…
średnie wartości dla całych kolumn (A1 oraz A2) różnią się od siebie.
Efekt główny czynnika B występuje, gdy…
średnie wartości dla całych wierszy (B1 oraz B2) różnią się od siebie.
Efekt interakcji występuje, gdy…
różnica między poziomami jednego czynnika jest modyfikowana przez drugi czynnik. W praktyce sprawdzamy to, badając różnice w kolumnach lub wierszach: jeśli są one stałe (np. wszędzie +2), interakcji nie ma (to czysty efekt addytywny).
Jeśli różnice zmieniają wielkość (np. w jednym wierszu +2, a w drugim +6) lub kierunek (w jednym rośnie, w drugim maleje), oznacza to obecność interakcji
plan z powtarzanymi pomiarami (repeated measures design)
typ planu eksperymentalnego, w którym każda osoba badana [najczęściej] bierze udział w każdym warunku eksperymentu (tzn. pomiar jest powtarzany dla każdej osoby)
Klasyczny – kilka powtarzających się pomiarów tego samego typu (np. zmiany nastroju w czasie)
Analiza profilu – różne wymiary tego samego zjawiska (np. wyniki różnych zadań u tej samej osoby)
Jakie są zalety powtarzanego pomiaru?
• eliminuje zakłócający wpływ zmienności międzyosobowej (różnic indywidualnych), ponieważ te same osoby są przypisane do każdego poziomu zmiennej niezależnej (wewnątrzobiektowej)
• wymaga mniejszej liczby osób badanych
• umożliwia w efektywny sposób zbadanie wpływu konfiguracji różnych bodźców (np. łatwe vs trudne, obrazowe vs werbalne...)
• niezbędny, gdy procedura badawcza zawiera serię różnych oddziaływań (np. ocena wielu bodźców przez jedną osobę)
• eksperyment z powtarzanymi pomiarami jest częściej bardziej wrażliwy i ma większą moc statystyczną niż eksperyment z grupami niezależnymi (zmienne między osobami)
Wrażliwość (sensitivity)
stopień prawdopodobieństwa, z jakim eksperyment wykryje rzeczywiście występujący wpływ zmiennej niezależnej na zm. zależną
Moc testu (power of test)
prawdopodobieństwo, z jakim test statystyczny umożliwia badaczom odrzucenie fałszywej hipotezy zerowej
Jakie są wady powtarzanego pomiaru?
Efekty kolejności (practice effects): Zachowanie uczestników eksperymentu może zmieniać się po prostu ze względu na fakt powtórnego pomiaru, a nie ze względu na manipulację zmienną niezależną
- Pozytywne: uczenie się, nabywanie wprawy
- Neutralne: habituacja
- Negatywne: zmęczenie, znudzenie, efekt wyczulenia
Transfer różnicowy (efekt przenoszenia): Pojawia się, gdy efekt jednego warunku utrzymuje się i wpływa na zachowanie się osób badanych w następnych warunkach
Utrata osób badanych
Efekt kolejności może…
stanowić zagrożenie dla trafności wewnętrznej eksperymentu z powtarzaniem pomiarów, gdy różne poziomy zmiennej niezależnej są wprowadzane w tej samej kolejności dla wszystkich badanych
Transfer różnicowy
można wykazać analizując wpływ kolejności warunków (np. inne efekty gdy zadanie łatwe poprzedza zad. trudne niż wtedy gdy zad. trudne poprzedza proste)
można wykazać na podstawie porównania wyników tej samej zmiennej zależnej testowanej w planie powtarzanych pomiarów i planie grup niezależnych
Założenie sferyczności jest spełnione, gdy…
zmiana w poszczególnych pomiarach u wszystkich osób jest w tym samym kierunku i ma taką samą wielkość
• W przypadku niespełnionego założenia o sferyczności możemy przyjąć różne poprawki, które pokażą bardziej realistyczny wynik testu F.
• Przy poprawkach zmianie ulegają stopnie swobody; są one przemnażane przez statystykę epsilon (poprawkę na zaburzenie tego założenia)
– stąd też inna istotność i wyniki testu F (choć nie zawsze!)
– UWAGA: w opisie wyników zawsze podajemy jaką poprawkę przyjęliśmy oraz ile ona wynosi.
Do czego służy statystyka Epsilon?
do korekty stopni swobody efektu i błędu
przyjmuje ona wartości od 0 do 1
aby wykonać korektę mnożymy stopnie swobody przez wartość Epsilon
trzy wersje:
Greenhouse’a –Geisera (do dużych prób)
Huyhne’a-Feldta (do małych prób, najbardziej liberalny)
Dolna granica epsilon (max. konserwatywny, nie polecany)
(robimy je gdy test sferyczności ISTOTNY statystycznie → sferyczność nie jest założona)
Gdy test sferyczności nie jest istotny statystycznie
sferyczność założona
przy niespełnionych założeniach ANOVY →
Model wielozmiennowy (multivariate repeated measures MANOVA)
Nie wymaga spełnienia założenia o sferyczności - możemy podawać wyniki z tabeli testu wielu zmiennych; są one niezależne od założenia sferyczności, bo oparte na różnicach między poziomami czynnika (czy średnie z różnic różnią się istotnie od zera)
Najczęściej podawany test to Lambda Wilksa
Założenie o homogeniczności kowariancji (test Boxa równości macierzy kowariancji – powinien być ni.)
testy nieparametryczne
Są mniej restrykcyjne jeśli chodzi o założenia dotyczące natury i rozkładów badanych zmiennych (tzw. testy niezależne od rozkładu)
Zalety testów nieparametrycznych
zmienna zależna nie musi być na skali ilościowej
zmienna zależna nie musi mieć rozkładu normalnego lub możemy go nie znać
skala może być porządkowa
rozkład odbiegający od normalnego lub nieznany
wariancje nas nie interesują
próby nie muszą mieć podobnej liczebności
Wady testów nieparametrycznych
mają zwykle mniejszą moc (czyli prawdopodobieństwo odrzucenia hipotezy zerowej, gdy jest ona fałszywa) niż testy parametryczne, gdy spełnione są założenia
Trzy kryteria podziału testów nieparametrycznych
• testy porównujące dwie grupy lub więcej grup (podział wg liczby grup)
• testy dla grup niezależnych lub zależnych
• testy oparte na rangach bądź znakach (podział wg stosowanej metody)
Testy nieparametryczne: podział według liczby grup
Dla dwóch grup
Próby niezależne (oparte na rangach): Test U Manna-Whitneya (W Sumy rang Wilcoxona), Test serii Walda-Wolfowitza oraz Test Z Kołmogorowa-Smirnowa.
Próby zależne (oparte na rangach): Test znaków rangowanych Wilcoxona.
Zmienne dychotomiczne (zależne): Test McNemara (wskazany dla 2 prób).
Dla dwóch lub więcej grup
Próby niezależne (oparte na rangach): Test H Kruskala-Wallisa, który jest opisany jako rozszerzenie testu U Manna-Whitneya.
Próby zależne (oparte na rangach): Test rang Friedmana oraz W Kendalla.
Zmienne dychotomiczne (zależne): Test Q Cochrana (wskazany dla $k$ prób).
Testy nieparametryczne: podział według grup:niezaleznych/zaleznych
1. Próby niezależne (grupy niezależne)
Oparte na rangach:
Dla 2 grup (k = 2): Test U Manna-Whitneya (oraz W Sumy rang Wilcoxona), Test serii Walda-Wolfowitza, Test Z Kołmogorowa-Smirnowa.
Dla 2 i więcej grup (k ≥ 2): Test H Kruskala-Wallisa (rozszerzenie testu U Manna-Whitneya).
Oparte na znakach:
Wspólny dla k = 2 oraz k ≥ 2: Test mediany.
2. Próby zależne (grupy zależne)
Oparte na rangach:
Dla 2 grup (k = 2): Test znaków rangowanych Wilcoxona.
Dla 2 i więcej grup (k ≥ 2): Test rang Friedmana oraz W Kendalla.
Oparte na znakach:
Wspólny dla k = 2 oraz k ≥ 2: Test znaków Fishera.
Dla zmiennych dychotomicznych (binarnych):
Z ramki na dole slajdu wynika, że dla tego typu zmiennych zależnych stosuje się:
Dla 2 prób: Test McNemara.
Dla wielu prób (k prób): Test Q Cochrana.
Testy nieparametryczne: podział według rang/znaków - metody
1. Metoda oparta na RANGACH
A. Dla prób niezależnych:
Dla 2 grup ($k = 2$):
Test U Manna-Whitneya (W Sumy rang Wilcoxona)
Test serii Walda-Wolfowitza
Test Z Kołmogorowa-Smirnowa
Dla 2 lub więcej grup ($k \ge 2$):
Test H Kruskala-Wallisa (rozszerzenie testu U Manna-Whitneya)
B. Dla prób zależnych:
Dla 2 grup ($k = 2$):
Test znaków rangowanych Wilcoxona
Dla 2 lub więcej grup ($k \ge 2$):
Test rang Friedmana
W Kendalla
2. Metoda oparta na ZNAKACH
W przypadku testów opartych na znakach, schemat nie różnicuje ich ze względu na to, czy grup jest dokładnie dwie ($k = 2$), czy więcej ($k \ge 2$) – stosuje się te same testy dla obu przypadków:
Dla prób niezależnych: Test mediany
Dla prób zależnych: Test znaków Fishera
kryteria podziału testów nieparametrycznych
Rodzaj prób | Metoda oparta na | Dwie grupy (k=2) | Dwie i więcej grup (k≥2) |
Niezależne | Rangach | Test U Manna-Whitneya Test serii Walda-Wolfowitza Test Z Kołmogorowa-Smirnowa | Test H Kruskala-Wallisa |
Niezależne | Znakach | Test mediany | Test mediany |
Zależne | Rangach | Test znaków rangowanych Wilcoxona | Test rang Friedmana W Kendalla |
Zależne | Znakach | Test znaków Fishera | Test znaków Fishera |
Zależne (dychotomiczne) | N/A | Test McNemara | Test Q Cochrana |
test Friedmana
oparty na rangach, nieparametryczny odpowiednik jednoczynnikowej analizy wariancji w schemacie wewnątrzosobowym (z powtarzanymi pomiarami)
test W Kendalla
mierzy zgodność rangowania między pomiarami; wynik interpretuje się jako współczynnik zgodności między oceniającymi
test Q Cochrana
dla zmiennych zależnych dychotomicznych (rozszerzenie testu McNemara)
Do czego wykorzystujemy analizę regresji?
do rozpoznawania wielkości i rodzaju wpływu jednej zmiennej (lub więcej) na drugą
do objaśniania zmienności jednej zmiennej za pomocą zmienności drugiej zmiennej (lub większej liczby zmiennych)
do predykcji (przewidywania) wartości zmiennej zależnej
Czym jest predyktor (lub predyktory) w analizie regresji?
zmienną wyjaśniającą/objaśniającą
zmienną na podstawie której (których) będziemy wnioskować o zmiennej zależnej
Czym jest zmienna zależna w analizie regresji?
zmienną wyjaśnianą/objaśnianą
przez predyktor
Predykcja „reintrodukcja”
• Współczynnik korelacji mówi nam o sile związku pomiędzy X i Y.
• Jednak nie opisuje tego związku w stopniu wystarczającym by przewidywać Y na podstawie X (lub na odwrót)
podstawa regresji
opisanie liniowego związku linią prostą, co pozwala na przewidywanie wyników leżących poza zakresem próby
Błąd (reszta regresji)
• Różnica między wynikiem przewidywanym (przez linię regresji), czyli y’
• a wynikiem rzeczywistym, czyli y
Linia najlepszego dopasowania
• Wyznaczana tak, aby uzyskać w sumie jak najmniejsze odległości wyników od linii
– Metodą najmniejszych kwadratów
• Ze wszystkich możliwych linii wybieramy tę, dla której suma kwadratów reszt (błędów) jest najmniejsza
• UWAGA – reszty (czyli odległości wyników od linii regresji) są liczone prostopadle do osi na której jest predyktor
Współczynnik determinacji (R2)
stosunek przewidywanej sumy kwadratów do całkowitej sumy kwadratów
może być interpretowany jako stopień zmienności Y wyjaśnianej przez zmienność X. (duże R to współczynnik korelacji wielokrotnej)
korelacja cząstkowa
wykluczenie wpływu trzeciej zmiennej, korelującej ze zmiennymi współwystępującymi
w regresji wielozmiennowej
im mniej predyktorów tym lepiej dla modelu!
Test Durbina-Watsona
• Test korelacji seryjnej (lub autokorelacji) reszt.
• Jednym z założeń analizy regresji jest brak korelacji pomiędzy resztami kolejnych obserwacji.
• Zakres wartości testu Durbina-Watsona jest od 0 do 4.
– jeśli reszty nie korelują ze sobą to wartość statystyki DurbinaWatsona wynosi 2 (+/- 0,5 „na oko”).
– wartości bliskie 0 wskazują na b. wysoką dodatnią autokorelację.
– wartości bliskie 4 wskazują na b. wysoką ujemną autokorelację.
Jak interpretować predyktory dwuwartościowe (dychotomiczne)?
Zmienne takie najlepiej zrekodować na dwie kategorie, różniące się o jeden
– najprościej na 0 i 1 [ew. 1 i 2], łatwo wtedy interpretować wyniki, jako przejście z jednej kategorii do drugiej
– jednostką jest „przynależność” (lub nie) do kategorii opisanej jako 1
Współliniowość
to nadmierna interkorelacja zmiennych niezależnych
– korelacja ~1 narusza założenie o braku idealnej współliniowości
– wysokie korelacje zwiększają błąd standardowy SE współczynników regresji
• nie wpływa to na moc predykcji i rzetelność modelu
• ale wpływa na estymacje pojedynczych współczynników
Bardzo wysoki SE b jest wskaźnikiem…
współliniowości
Macierz korelacji jest…
najprostszą metodą oceniania współliniowości
outliery wielowymiarowe
przypadki, których wynik jest nietypowy dla całego równania regresji, gdy weźmiemy pod uwagę wszystkie zmienne
Obserwacje odstające - outliers
obserwacje dla której wartość jednej lub więcej zmiennych wydają się odstawać znacząco od reszty zbioru
obserwacje z nietypowymi wartościami
obserwacje z nietypowymi kombinacjami wartości
Regresja hierarchiczna – wprowadzanie predyktorów grupami
• Wprowadzamy predyktory grupami (blokami)
• Stosujemy gdy mamy wyraźnie przewidywania co do znaczenia (teoretycznego) predyktorów
– W pierwszym bloku wprowadzamy np. zmienne kontrolowane (dzięki temu w następnych ich wpływ jest już wykluczony)
– W kolejnych blokach wprowadzamy kolejne predyktory, by sprawdzić czy ich wpływ jest istotny i znaczący (patrzymy na zmianę R2 )
Zmiana R2
dzięki tej statystyce zyskujemy informację czy wprowadzenie kolejnego predyktora (bloku zmiennych) zwiększyło dopasowanie modelu, czyli czy wzrost R2 jest znaczący (wg Cohena co najmniej 0,06) i istotny
Jeśli nasz predyktor nie jest na skali ilościowej…
• Przy założeniach analizy regresji była mowa o tym, że zmienne muszą być na skalach co najmniej przedziałowych
• Natomiast w życiu mamy często zmienne na skalach nominalnych czy porządkowych, które mogą być ważnym predyktorem naszej zmiennej objaśnianej
• Dlatego chcemy wprowadzić je do modelu regresji
• Tworzymy wtedy zmienne instrumentalne
Regresja hierarchiczna – zasady wprowadzania predyktorów grupami (blokami)
– w pierwszym bloku wprowadzamy np. zmienne kontrolowane (dzięki temu w następnych ich wpływ jest już wykluczony!)
– w kolejnych blokach wprowadzamy predyktory właściwe
O moderacji mówimy gdy…
związek (czasem wpływ ☺) X i Y zależny jest od poziomu zmiennej Z (MODERATORA)
mediacja
włączenie do równania regresji dwóch X’ów zmniejsza współczynnik regresji obu lub jednego z nich
supresja
włączenie do równania regresji dwóch X’ów zwiększa współczynnik regresji obu lub jednego z nich
Połącz w pary testy parametryczne z ich nieparametrycznymi odpowiednikami
Analiza wariancji z powtarzanymi pomiarami
Test Friedmanna
Połącz w pary testy parametryczne z ich nieparametrycznymi odpowiednikami
Test t Studenta dla prób niezależnych
Test U Manna Whitneya
Połącz w pary testy parametryczne z ich nieparametrycznymi odpowiednikami
Jednoczynnikowa analiza wariancji
Test H Kruskala Wallisa
Połącz w pary testy parametryczne z ich nieparametrycznymi odpowiednikami
Test t Studenta dla prób zależnych
Test znaków rangowanych Wilcoxona
P/F Testy nieparametryczne można określić jako niezależne od pewnych cech rozkładu zmiennej w populacji
PRAWDA
P/F Testy nieparametryczne możemy zastosowań do analiz z powtarzanymi pomiarami
PRAWDA
P/F Test Friedmana można stosować dla zmiennych mierzonych na skali porządkowej
PRAWDA
P/F Test Friedmana stosujemy dla prób niezależnych
FAŁSZ
P/F W testach nieparametrycznych rozkład zmiennej zależnej musi być normalny
FAŁSZ
P/F Test znaków rangowanych Wilcoxona jest testem przeznaczonym dla prób zależnych i skal ilościowych
PRAWDA
P/F Testy nieparametryczne mogą być stosowane dla zmiennych zależnych mierzonych na skali ilościowej
PRAWDA
P/F Testy nieparametryczne stosujemy zawsze wtedy, gdy rozkład badanej zmiennej nie odbiega od krzywej Gaussa
FAŁSZ
P/F Testy nieparametryczne stosujemy gdy zmienna zależna jest na skali ilościowej, ale dane nie spełnia założeń niezbędnych dla testów parametrycznych
PRAWDA
P/F Testy nieparametryczne porównują średnie arytmetyczne w dwóch lub większej liczbie grup
FAŁSZ
P/F Testy nieparametryczne nie wymagają, aby wariancje w próbach były homogeniczne
PRAWDA
Wartość korelacji wynosi -0,8. Ile wynosi wartość współczynnika determinacji?
0,64
Współczynnik determinacji (R2) to….
kwadrat współczynnika korelacji (r).
Które z poniższych zmiennych mogą zostać użyte jako zmienne niezależne w analizie regresji?
a. Liczba kroków dziennie
b. zaliczenie lub nie zajęć ze Statystyki 2 (kodowane: 0 - brak zaliczenia; 1 - zaliczenie)
c. wielkość miejscowości zamieszkania (1 - wieś, 2 - małe miasteczko, 3 - miasto, 4 - bardzo duże miasto), po zrekodowaniu na zestaw zmiennych instrumentalnych
d. Prędkość pisania na komputerze (liczba znaków na minutę)
e. czas poświęcony przez studenta na naukę statystyki (w godzinach)
a. Liczba kroków dziennie
b. zaliczenie lub nie zajęć ze Statystyki 2 (kodowane: 0 - brak zaliczenia; 1 - zaliczenie)
c. wielkość miejscowości zamieszkania (1 - wieś, 2 - małe miasteczko, 3 - miasto, 4 - bardzo duże miasto), po zrekodowaniu na zestaw zmiennych instrumentalnych
d. Prędkość pisania na komputerze (liczba znaków na minutę)
e. czas poświęcony przez studenta na naukę statystyki (w godzinach)
Chcąc sprawdzić czy rozkład badanej zmiennej odbiega od rozkładu normalnego można użyć testu:
a. Kruskala Wallisa
b. Friedmana
c. Kołmogorowa Smirnowa
d. Wilcoxona
e. Shapiro-Wilka
c. Kołmogorowa Smirnowa
e. Shapiro-Wilka
W standardowej analizie regresji:
zmienna zależna: ?
zmienna niezależna: ?
Zmienna zależna (wyjaśniana) musi być zmienną ilościową, oznacza to, że dozwolone są tylko dwie skale:
Przedziałowa (interwałowa): Posiada równe odstępy, ale nie ma "prawdziwego zera" (np. temperatura w stopniach Celsjusza – 0°C nie oznacza braku temperatury, można mieć wartości ujemne).
Ilorazowa (stosunkowa): Posiada równe odstępy i ma absolutne, prawdziwe zero (np. waga w kg, wzrost w cm, stężenie w mol/dm³ – 0 oznacza całkowity brak danej cechy).
Zmienne niezależne (predyktory) mogą być zmiennymi ilościowymi LUB zmiennymi jakościowymi, pod warunkiem że są dychotomiczne (zero-jedynkowe) lub zakodowane jako zmienne instrumentalne (tzw. dummy variables).
Może być dowolnego typu. Przyjmuje wszystkie cztery skale:
A. Skale ilościowe (używane w modelu bezpośrednio):
Przedziałowa (np. przewidujemy sprzedaż na podstawie temperatury na zewnątrz).
Ilorazowa (np. przewidujemy ciśnienie krwi na podstawie dawki leku w mg).
B. Skale jakościowe (wymagają przekształcenia w modelu):
Nominalna: Kategorie bez żadnego logicznego porządku (np. płeć, kolor oczu, marka samochodu, grupa krwi).
Porządkowa: Kategorie, które można ułożyć w logicznej kolejności, ale różnice między nimi nie są równe lub mierzalne (np. wykształcenie: podstawowe -> średnie -> wyższe; albo oceny w ankiecie: źle -> średnio -> dobrze).
Przypadki odstające można zauważyć
a. analizując wykresy rozrzutu
b. analizując homogeniczność wariancji
c. analizując reszty standaryzowane
d. robiąc diagnostykę współliniowości
e. analizując rozkłady zmiennych
a. analizując wykresy rozrzutu
c. analizując reszty standaryzowane
e. analizując rozkłady zmiennych
jaki jest nieparametryczny odpowiednik tego testu?
Test t Studenta dla prób zależnych
Test znaków rangowanych Wilcoxona
jaki jest nieparametryczny odpowiednik tego testu?
Jednoczynnikowa analiza wariancji (ANOVA)
Test H Kruskala Wallisa
jaki jest nieparametryczny odpowiednik tego testu?
Analiza wariancji z powtarzanymi pomiarami
Test Friedmanna
jaki jest nieparametryczny odpowiednik tego testu?
Test t Studenta dla prób niezależnych
Test U Manna Whitneya
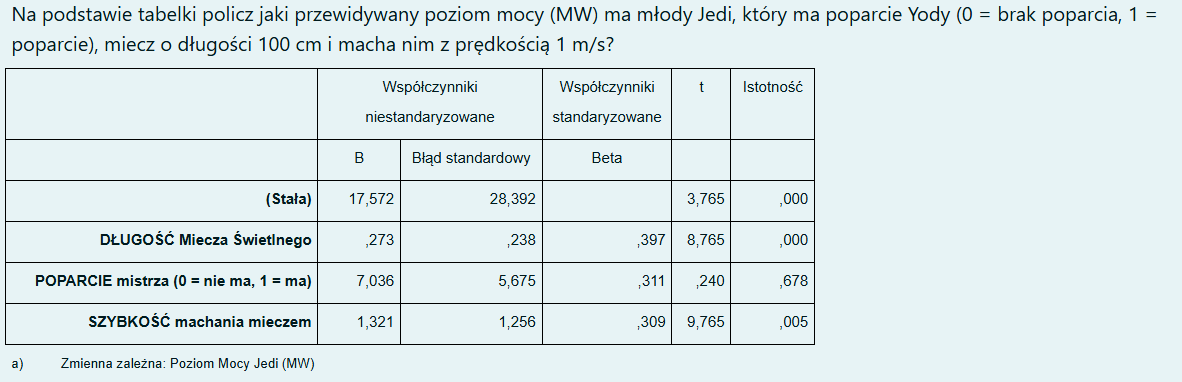
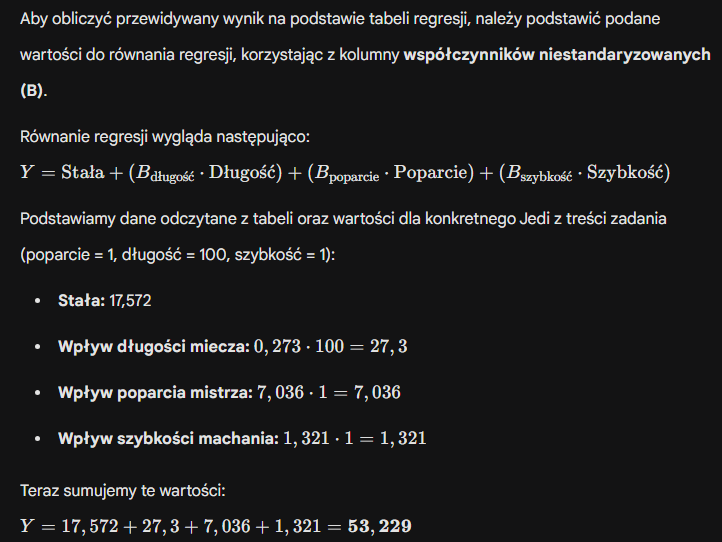
Chciano sprawdzić czy hobbity w Słupkach różnią się istotnie pod względem wzrostu od tych mieszkających w Żabiej Łące. Jakim testem przeprowadzisz analizę statystyczną wiedząc, że ich wzrost mierzono na skali: 1=wysoki wśród niskich, 2=przeciętnie niski, 3=bardzo niski, 4=wyjątkowo niski?
a. testem U Manna Whitneya
b. testem znaków rangowanych Wilcoxona
c. testem t dla prób zależnych
d. testem t dla prób niezależnych
e. testem McNemara lub Q Cochrana
a. testem U Manna Whitneya
Dwie grupy studentów (znających i nie znających książki) zaproszono na pokaz kolejno trzech części filmu „Władca Pierścieni”, a po każdej z nich proszono ich o ocenę, na skali od 1 – film bardzo mi się nie podobał do 7 – film bardzo mi się podobał. Jakim testem zanalizowano wyniki?
a. Jednoczynnikowa analiza wariancji
b. Jednoczynnikowa analiza wariancji w schemacie wewnątrzgrupowym
c. Dwuczynnikowa analiza wariancji w schemacie wewnątrzgrupowym
d. Dwuczynnikowa analiza wariancji w schemacie mieszanym
d. Dwuczynnikowa analiza wariancji w schemacie mieszanym
Studentów zaproszono na pokaz kolejno trzech części filmu „Władca Pierścieni”, a po każdej z nich proszono ich o ocenę, na skali od 1 – film bardzo mi się nie podobał do 7 – film bardzo mi się podobał. Jakim testem można zanalizować wyniki?
a. Analiza wariancji z powtarzanymi pomiarami
b. Test Q Cochrana
c. Test H Kruskala-Wallisa
d. Test Friedmana
e. Dwuczynnikowa analiza wariancji w schemacie międzyosobowym
d. Test Friedmana
O braku autokorelacji reszt świadczy
a. Indeks warunkowy powyżej 30
b. homoskedastyczność wariancji
c. Wartość własna bliska zero
d. wynik testu Durbina-Watsona w granicach 1,5-2,5
d. wynik testu Durbina-Watsona w granicach 1,5-2,5
Przystępując do analizy regresji liniowej musimy upewnić się że:
a. Zmienne kontrolowane są wprowadzone w pierwszym bloku
b. Predyktory nie są nadmiernie skorelowane ze sobą
c. Mamy wystarczającą liczbę osób badanych
d. Włączamy do analizy wszystkie zmienne, które są związane z badanym konstruktem
a. Zmienne kontrolowane są wprowadzone w pierwszym bloku
b. Predyktory nie są nadmiernie skorelowane ze sobą
c. Mamy wystarczającą liczbę osób badanych
d. Włączamy do analizy wszystkie zmienne, które są związane z badanym konstruktem