Learning Rate and Overfitting/dropout
1/14
Earn XP
Description and Tags
Da slide 166 a slide 189
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
15 Terms
Importance of calibrating learning rate
if too small slow convergence;
if too great a swing and / or divergence
the optimal value changes according to the network architecture of the loss function, etc. if you start from a known architecture and already applied by others to similar problems, start from the recommended values and try to increase / decrease by monitoring convergence and generalization.
Attention: the fact that the loss decreases without oscillating does not mean that the value is optimal (especially in the tuning of pre-trained networks): monitor accuracy on the validation set.
Adaptive learning rate techniques can help.
Learning rate annealing
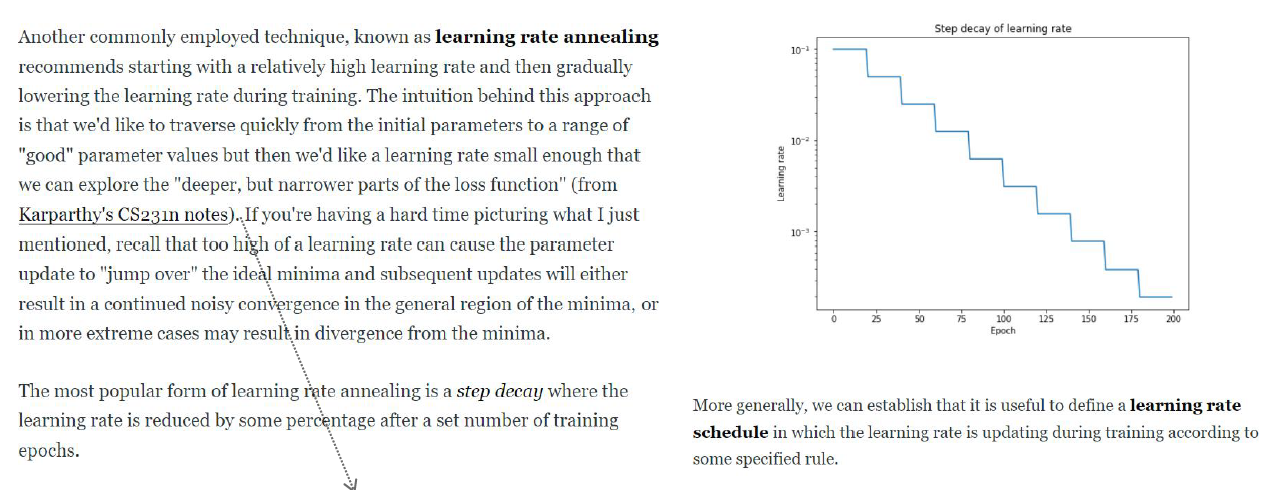
Cyclic learning rate (what is it and why it works)

Cyclic learning rate: thresholds

CLR according to Smith

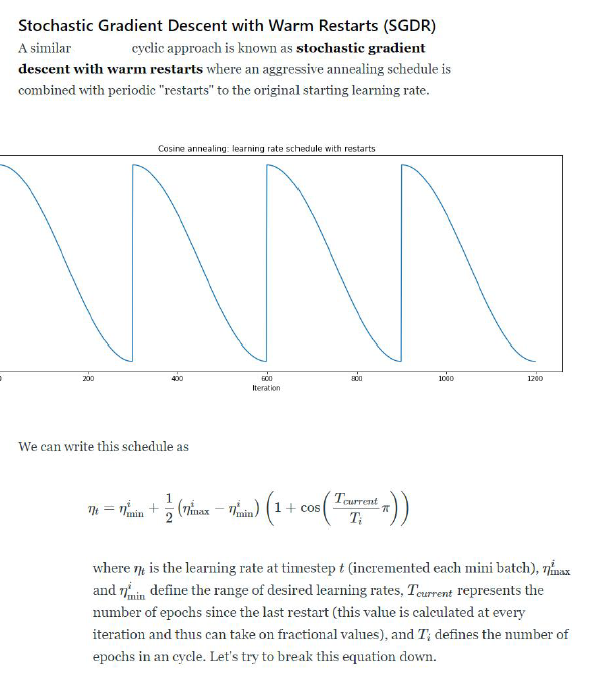
Stochastic Gradient Descent with Warm Restarts
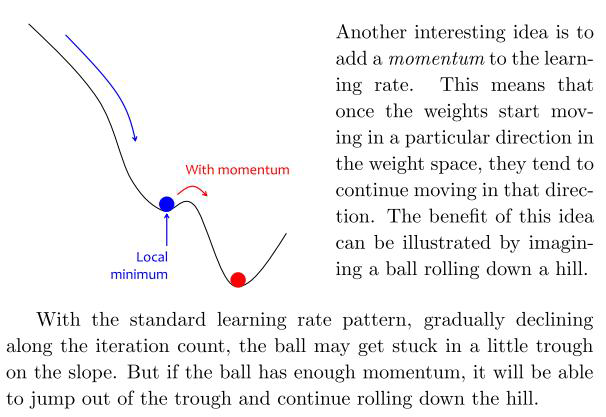
Momentum
SGD with mini-batch can cause a “zigzag gradient” which slows down convergence and makes it less stable.
You can think of Gradient Descent as a ball rolling down on a valley. We want it to sit in the deepest place of the mountains, however, it is easy to see that things can go wrong. Attracted by the force of gravity, the ball tries to move to the lowest point.
In physics, the moment gives a motion without sudden oscillations and changes of direction.
In SGD, to avoid oscillations, the physical behavior can be emulated: the last update of each parameter is saved, and the new update is calculated as a linear combination of the previous update (which gives stability) and the current gradient (which corrects the direction )
During training the update direction tends to resist change when momentum is added to the update scheme. When the neural net approaches a shallow local minimum it's like applying brakes but not sufficient to instantly affect the update direction and magnitude. Hence the neural nets trained this way will overshoot past smaller local minima points and only stop in a deeper global minimum.
Thus momentum in neural nets helps them get out of local minima points so that a more important global minimum is found. Too much of momentum may create issues as well as systems that are not stable may create oscillations that grow in magnitude, in such cases one needs to add decay terms and so on. It's just physics applied to neural net training or numerical optimizations.
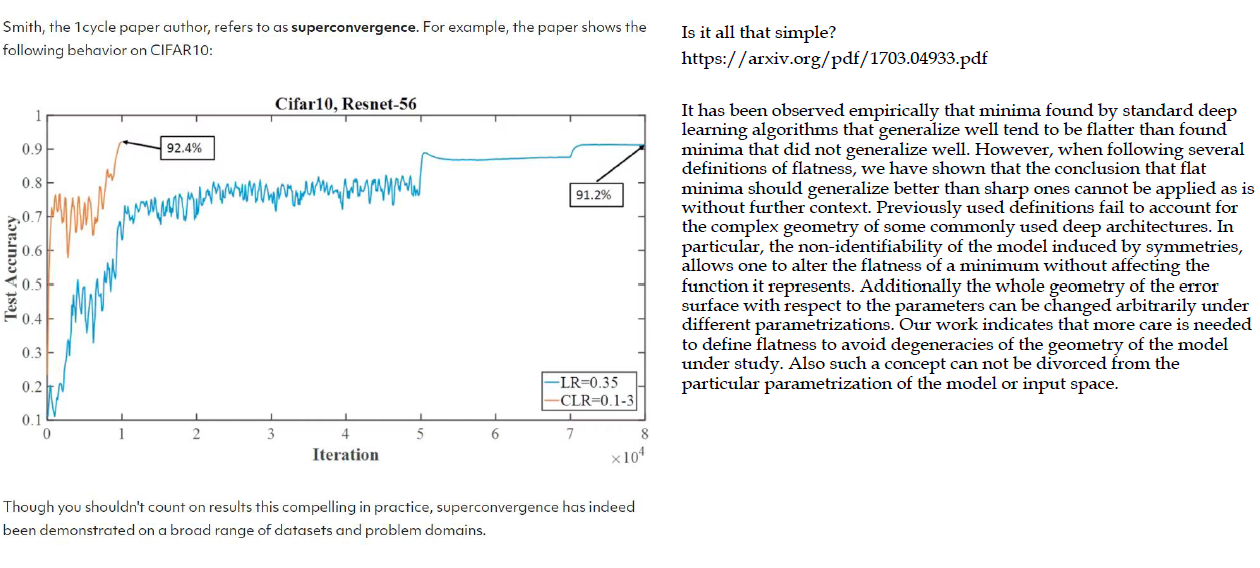
One cycle learning rate
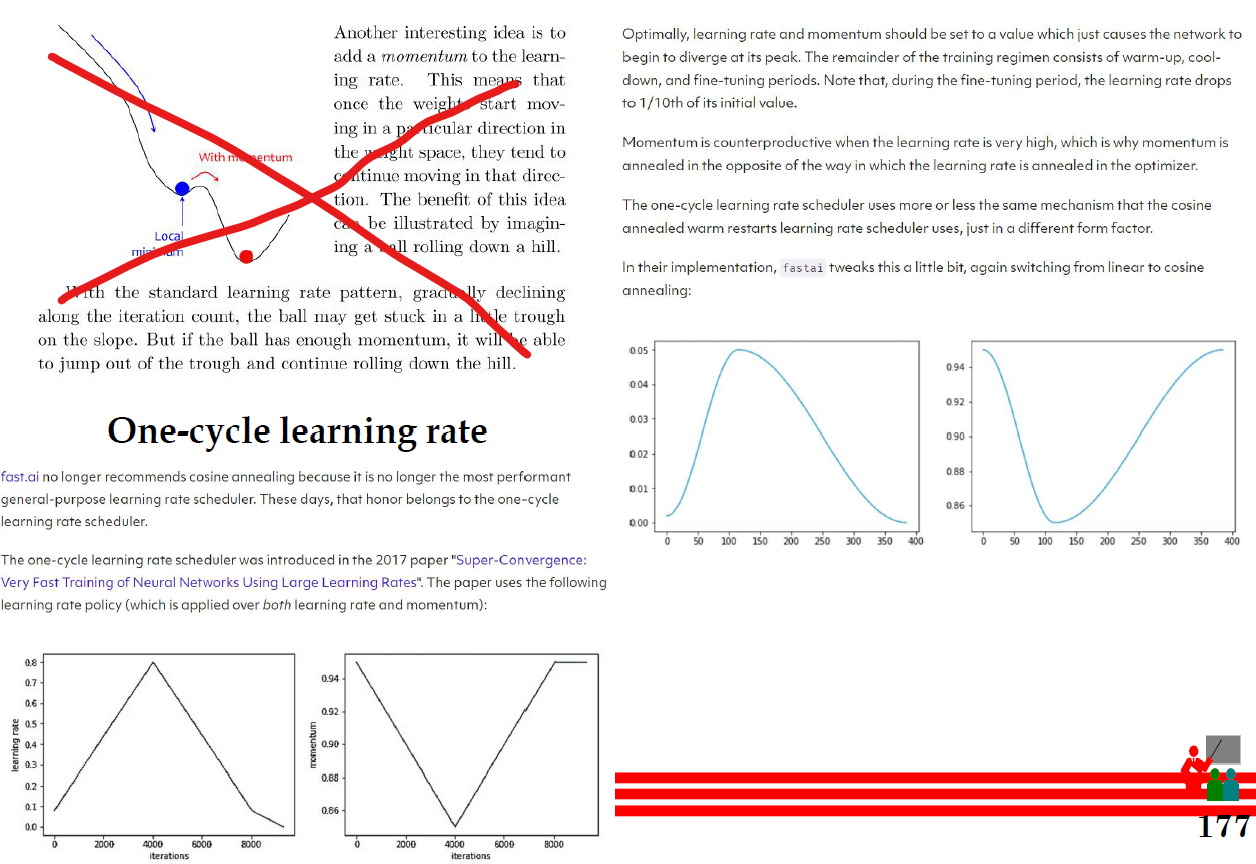
Superconvergence
Adam
The intuition behind the Adam is that we don’t want to roll so fast just because we can jump over the minimum, we want to decrease the velocity a little bit for a careful search.
Adam tends to converge faster, while SGD often converges to more optimal solutions. SGD’s high variance disadvantages gets rectified by Adam (as advantage for Adam).
To summarize, Adam definitely converges rapidly to a “sharp minima” whereas SGD is computationally heavy, converges to a “flat minima” but performs well on the test data.
Adam is useful when the computation time of SGD is unfeasible (or very expensive). Moreover, it is usually applied in transformer

diffGrad

Check list for convergence problems

Overfitting revisited: bias-variance tradeoff

Robustness through perturbations

Dropout
Dropout is a technique where randomly selected neurons are ignored during training. They are “dropped-out” randomly. This means that their contribution to the activation of downstream neurons is temporally removed on the forward pass and any weight updates are not applied to the neuron on the backward pass.
As a neural network learns, neuron weights settle into their context within the network. Weights of neurons are tuned for specific features providing some specialization. Neighboring neurons become to rely on this specialization, which if taken too far can result in a fragile model too specialized to the training data. This reliant on context for a neuron during training is referred to complex co-adaptations.
You can imagine that if neurons are randomly dropped out of the network during training, that other neurons will have to step in and handle the representation required to make predictions for the missing neurons. This is believed to result in multiple independent internal representations being learned by the network.
The effect is that the network becomes less sensitive to the specific weights of neurons. This in turn results in a network that is capable of better generalization and is less likely to overfit the training data.
