critical perspectives in social psychology
1/35
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
36 Terms
what is replication
repeatedly finding the same results → allows for reliability (consistency of findings), which gives us trustworthy scientific findings
what 5 things does replication allow for (Schmidt, 2009)
protects against false positives (e.g. sampling error)
controls for artifacts
addresses researcher fraud → by different research team carries out replication
test whether findings generalise to different populations → conceptual replication to see whether findings are generalisable
test the same hypothesis using a different procedure
what is a direct replication (Zwann et al., 2017) + what do good results suggest
a scientific attempt to recreate the critical elements (sample, procedure + measures) of an original study → the same/similar results are an indication that findings are accurate + reproducible
what is a conceptual replication + what do good results suggest
to test the same hypothesis using a different procedure → the same/similar results are an indication that findings are robust to alternative research designs, operational findings + samples
what did the open science collaboration (2015) discover regarding replicability
out of a sample of 100 psychological studies, only 36% were replicated, so no way of knowing if findings are accurate or robust
social psychology had particularly low replicability → 23-29%
what did Cristea et al. (2021) find regarding what findings most often get reported
performed a systematic review of the most influential studies in emotion research
found the most highly-cited studies were those that have the highest effect sizes, rather than methodologically better estimates of effect size (e.g. meta-analyses)
basically more extreme findings = more likely to be reported
who is Stapel + what is his instance of bad science
an influential social psychologist on impression formation + stereotypes → 50 of his papers were retracted due to him creating entire datasets to fit his hypothesis
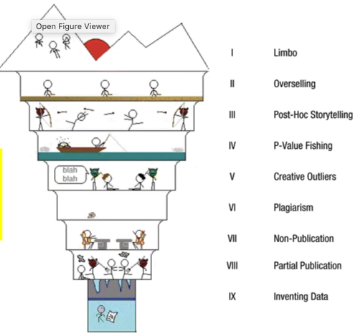
what are the nine ‘circles’ of scientific hell (Neuroskeptic, 2012)
different ranks of dubious to poor research practices → the former are less serious but more common. includes:
limbo
overselling
post-hoc storytelling
p-value fishing
creative outliers
plagiarism
non-publication
partial publication
inventing data
what is outcome switching (pertaining to p-value fishing)
changing the outcomes of interest in the study depending on the observed results → involves selecting convenient outcome based on findings (or what fits your hypothesis), whereas research was capitalised on chance
e.g. if running separate ANOVAs (increasing the likelihood of making type 1 error) and only reporting the one that is significant
what is p-hacking
umbrella term that encompasses outcome switching → taking decisions to maximise the likelihood of a statistically significant effect, rather than on objective scientific grounds
why is outcome switching bad practice
the study needs to be a reliable test of the hypothesis → null findings are just as important as significant ones as due to highlighting the factors that don’t affect an outcome
what does lack of statistical power result from + why is this considered bad practice
small sample size → larger sample = more confidence in findings due to better reflecting the general population, so smaller studies may not have the statistical power to accurately reflect the general population
what analyses are important to carry out before a study to determine the correct sample size + why
power analyses → calculates how many participants in the sample are needed in order to provide enough statistical power to test the hypothesis
if expecting small effect, larger amount of participants required; if expecting large effect, less participants are needed → means small samples are adequate if they provide the correct amount of power
samples that are too large may result in finding significant differences that are actually trivial in the population → must fit study correctly
on what 3 measures did John et al. (2012) assess how common sloppy science was + what were the results
surveyed over 2000 psychologists about their involvement in questionable research practices including:
failing to report all measures/conditions
deciding whether to collect more data after seeing whether results were significant (‘peaking at the data’)
selectively reporting studies that fit hypothesis
found percentage of respondents who engaged in them = surprisingly high
what are moderators
variables that influence the nature - direction and/or size - of an effect → identifying moderators is good as it improves our understanding
not identifying moderators means that findings may be contributed to by another unmeasured factor, so are less valid
in what effect does country/culture act as a moderator (Savani + Job, 2017)
the ego-depletion effect → researchers in US originally found that if people exert self-control on one task (resist temptation), they are worse at exerting it in the second test, so we have limited self-control resources
when replicating measures in India, found the opposite effect (reverse ego-depletion effect) → exerting self-control in one task meant they were better at resisting temptation in the second one
therefore country/culture acts as a moderator by reversing the directional effect of ego depletion
what is ‘second generation research’ (Zanna + Fazio, 1982)
conducting a follow-up study after an initial result was found in order to better understand why certain effects were found → involves identifying possible moderators/mediators that affect outcomes
what is publication bias + what are the 2 circles of scientific hell it refers to
pertains to non/partial publication → the phenomenon that findings that are statistically significant are more likely to be published than those that are not
there is generally good reason for this, e.g. due to ambiguity over the reason for null findings (no effect or poor methodology)
this creates pressure to find significant effects (even if not found in population)
what is the file drawer problem (Rosenthal, 1979)
studies finding significant results are published at a much faster rate than those finding null results → means meta-analyses can severely overestimate the true effect size of phenomena, meaning there is a higher chance that these findings occur by chance
what is open science (Munafo et al., 2017)
the process of making the content + process (including dataset, methodology etc. of producing evidence/claims transparent + accessible to others
without transparency, claims only achieve credibility based on trust in the confidence/authority of the originator
allows process to be both scrutinised for good practice + accurately replicated
how is open science carried out + what is one process for this to occur
documenting the methods + processes by which those methods were developed or decided on in advance
involves the judgements researchers make on what details are deemed critical when writing up the methods section
this can be achieved by pre-registration
what is pre-registration (Nosek et al., 2017) + what does it prevent
an example of open methodology involves defining the research questions, methods + approach to analysis before observing the research outcomes. this prevents:
hypothesising after results are known (hindsight bias)
what is the theory behind pre-registration producing more valid research (Chambers, 2014)
upholds transparency due to research proposals + methodologies being uploaded online → means that reviews of the paper know how study was conducted, so any post-hoc decisions made can be seen
what does Scott believe regarding the value of pre-registration
that is it too constraining → many scientific theories come from chance/exploratory findings alone, so preregistering may reduce the chances of this
what was Bishop’s rebuttal to Scott’s argument
preregistration makes it clear what findings are exploratory and what were hypothesised
science evolves → if we preregister something and find another measure better to use, iterative preregistrations allow you to be open about any methodological changes you made
transparency is worth any drawbacks
what did Protzko et al. (2023) find regarding whether preregistration improves replicability
attempted to replicate 16 novel experimental findings using rigour-enhancing practices e.g. large sample sizes, preregistration + methodological transparency → found 86% of the expected effects were replicated (in comparison to 36% that open science collaboration found)
what was a major error made in Protzko et al. (2023)’s study
replicability wasn’t the original outcome of interest + analyses associated with replicability were not preregistered as claimed
resulted in paper being retracted → example of fabrication + post-hoc storytelling that preregistration aims to work against
what would be the utility of integrating preregistration into the publication process + what would this be known as
rather than evaluating finished articles + including preregistration link, the preregistration should be reviewed first for peer reviewers to assess whether findings should be published, regardless of what they would be
reflects good science as methods are scrutinised rather than the findings obtained → may reduce the file draw problem
this could be achieved by registered reports
how are registered reports carried out (in 2 stages)
the peer review process is split into:
reviewers + editors assess a detailed protocol → study rationale, procedure + detailed analysis plan so that tweaks can be suggested before data collection
following favourable reviews + revisions to meet methodological standards, the journal offers acceptance in principle → publication of the findings is guaranteed provided the authors adhere to approved protocol + conclusions are evidence-bound
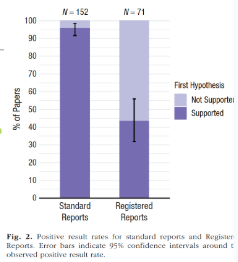
what did Scheel et al. find when comparing standard to registered reports
found only 43% of registered reports’ hypotheses were supported, in comparison to 96% of standard reports → shows drastic rates of publication bias in traditional method + the positive effects of preregistration
what are 3 other ways in which the scientific process can be kept transparent
open source materials + code → open source software e.g. code used to programme an experiment means readers can test + replicate method themselves
also encourages sharing of methodologies for other studies
open data → making the dataset freely available to the public
open access publishing
what are 3 advantages of making a dataset freely available
allows other scientist to verify original analyses
facilitates research beyond the scope of the original research
avoids duplication of data collection
what are 4 criteria Wilkinson et al. (2016) believes data in research should meet
Findable
Accessible
Interoperable → other software packages can access it
reusable
what was the traditional model of publication + what is a limitation of this approach
researchers submit a paper to a scientific journal, who decides whether or not to publish → if so, researcher signs copyright over to the journal, who charges universities, libraries + individuals for access
this limits access to those who have funds to pay for articles/subscriptions → knowledge becomes a commodity
what are 2 types of open access publishing
gold open access → researchers (or their funders/host institution) pay the journal to publish the article, meaning the final version is freely + permanently accessible for everyone
green open access (self-archiving) → put an unformatted version of a manuscript into a repository (storage location)
what are two positive effects of open access publishing (Tenant et al., 2016)
open access works are used more → cited between 36-600% more than works that aren’t, and are given more coverage by journalists/on social media
process facilitates meta-research → enables use of automated text + data-mining tools (which might be a good thing i guess sure???????)