BIOL 308 - Lectures 2-5
1/53
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
54 Terms
Functions of DNA?
3 main functions
store information
replicates faithfully (preservation of information)
has ability to mutate (variability of information)
Central Dogma of Moleular Biology
DNA → RNA → Protein
DNA undergoes transcription → RNA undergoes translation → Protein
Gene
entire DNA sequence necessary for production of functional protein or RNA
coding sequences for proteins and RNAs;
regulatory sequences act as signals or binding sites
Initiation of Gene Expression
transfer of information
in replication of DNA there is a template strand = antisense strand and an RNA like strand = sense/coding strand
DNA is double helix
DNA strands have → polarity
they are also complementary and antiparallel
Replicates faithfully
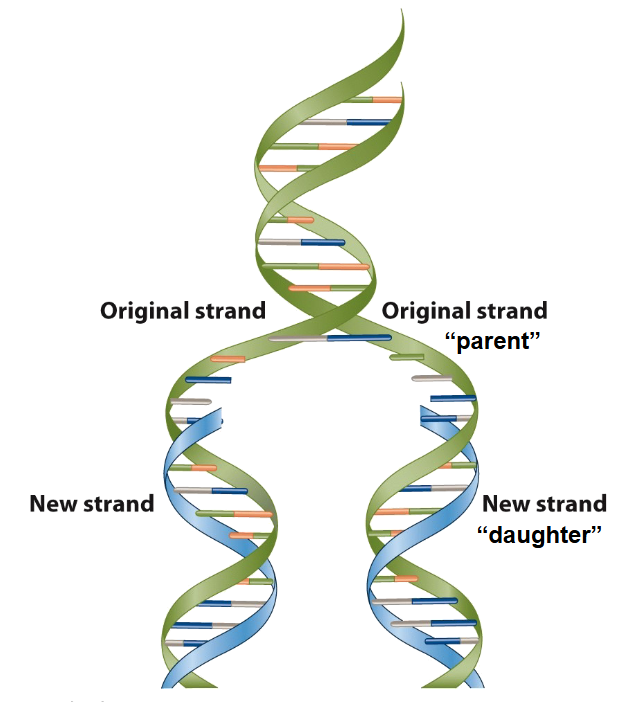
two strand of a parallel DNA separate and each serves as a template for synthesis of a new daughter strand by complementary base pairing
one strand predicts the sequence of the other strand → replication is semiconservative
Meselson and Stahl: thinking/planning
Tried different models: Semiconservative, conservative, and dispersive models
used E. Coli with heavy and light N to see which ones would appear after replication
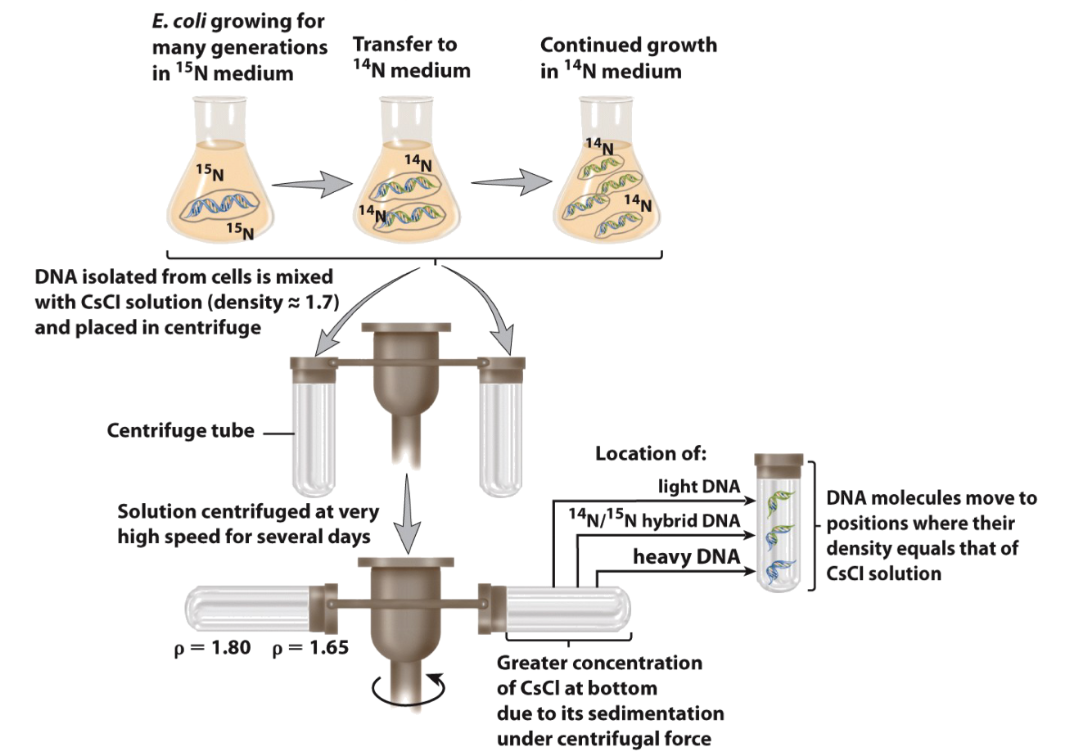
Meselson and Stahl: Outcome
DNA replication is semiconservative
two strands of a parental DNA separate and each serves as a template for synthesis of a new daughter strand by complementary base pairing
Outcome: one strand predicts the sequence of the other strand - information is preserved
has ability to mutate
mutations in coding sequences → possible alteration in protein product
concept of collinearity of genes and proteins
mutations could happen in regulatory sequences
Importance of mutations → formation of new alleles
altered product (= protein or RNA)
no product (knock out)
altered regulation of product expression (if mutation in regulatory sequence) → + selection = EVOLUTION
Overview of nucleic acid structures
Bases:
purines (A&G) and pyrimidines (C, T, U)
Sugars:
2-deoxyribose (DNA) → has a 2- H and 3’ OH
ribose (RNA) → has a 2- OH and 3’ OH
Phosphate → PO4
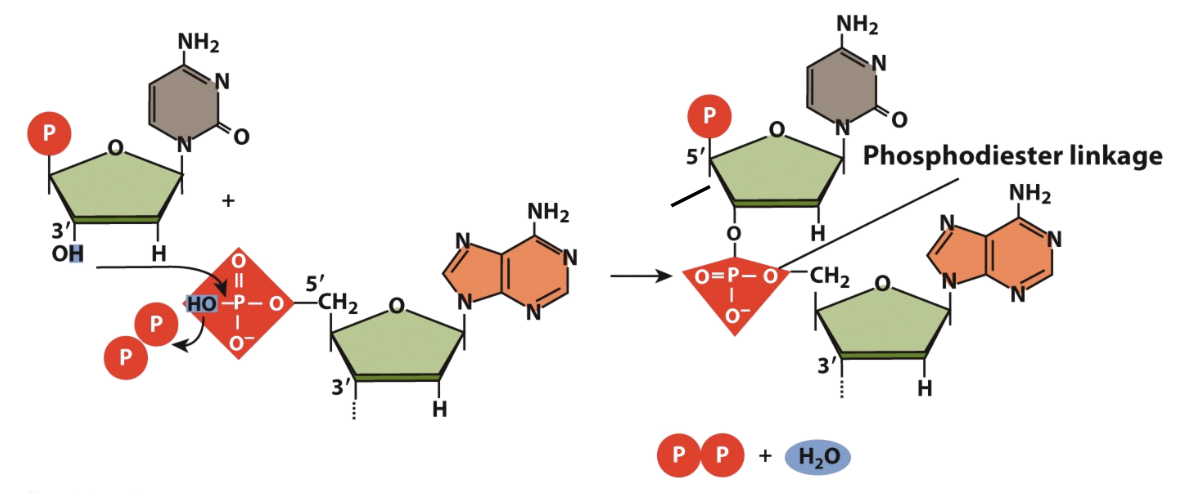
Makeup of a Polynucleotide chain
the H of the 3’ OH binds to the HO of a phosphate on another nucleotide forming a phosphodiester linkage
chains are read in the 5’ to 3’ direction, both ends running antiparallel to one another
Chargaff’s rule
#purines = #pyrimidines
#A=#T and #G=#C
Major and Minor Grooves
binding sites for different (regulatory) factors
each factor recognizes specific nucleotide sequence on DNA
each nucleotide sequence “exposes” specific - unique - distribution of acceptors and donors
Forces that help form DNA double helix
Rigid phosphate backbone - overall negative charge to the molecule
Stacking interactions - Van der Waals interactions between bases (weak, but many)
Hydrophobic interactions - highly negative phosphate backbone “outside” vs. nonpolar "(hydrophobic) bases “inside”
Ionic Interactions - salts (+ve ions) stabilize phosphate backbone (DNA shielding)
Hydrogen Bonding is responsible for complementary base pairing but is not the most energetically significant component
Alternative Forms of DNA: A-DNA
Orientation: right-handed orientation
major grooves: deep and narrow
minor grooves: shallow and broad (superficial),
conditions: low humidity (75%) and high salt
Alternative Forms of DNA: B-DNA
Orientation: right-handed orientation
major grooves: moderate depth and wide
minor grooves: moderate depth and narrow
turning: every 10.5 bases
conditions: high humidity (95%) and low salt
Alternative Forms of DNA: Z-DNA
orientation: left-handed orientation
major grooves:
very shallow, virtually nonexistent “single groove”
minor grooves: very deep and narrow
conditions: with very high MgCl2, NaCl or ethanol. In the presence of methylated cytosine: high humidity and low salt
Unusual Forms of DNA
Triple helix DNA:
formed when purines make up one strand and pyrimidines the other, then a third strand can be accommodated
in a test tube, but also likely in vivo during DNA recombination or repair
gene therapy possibilities
Chromosomal DNA is a dynamic structure
localized structural polymorphisms
constant
DNA sequence
local environment
allows for recognition of DNA
gene expression
DNA repair
Denaturation of DNA
two sequences that are not complementary will not hybridize
two DNA molecules previously denatured by heating
slow renaturation by cooling
renatured DNA” 2 wild type molecules and two hybrid molecules
Factors that Denature DNA
heat
low ionic strength promotes repulsion between negative phosphate back-bones (low salt)
high pH: “stripping” of H+ shared between electronegative centers (NaOH)
agents that influence H-bonds
competition: have functional groups that can form H-bonds with the electronegative centers (NH2- and O=; urea, formamide)
covalent modifications: modify electronegative centers and block the formation of H-bonds (formaldehyde, glyoxal)
agents that enhance the solubility of hydrophobic substances (organic solvents, temperature, pH)
Monitoring DNA Denaturation
progress of denaturation can be monitored by examining the properties of the molecule that change when the strands separate
viscosity - rarely used = difficult
absorbance - commonly used
How does absorption spectrophotometry work?
Tm: melting temperature (temp at which 50% of the DNA is denatured
absorbance changes depending on the stacking of purines and pyrimidines:
in double stranded DNA that bases are stacked and absorbance if lower (hypochromic)
in denatured single stranded DNA the bases are unstacked and absorbance increases (hyperchromic)
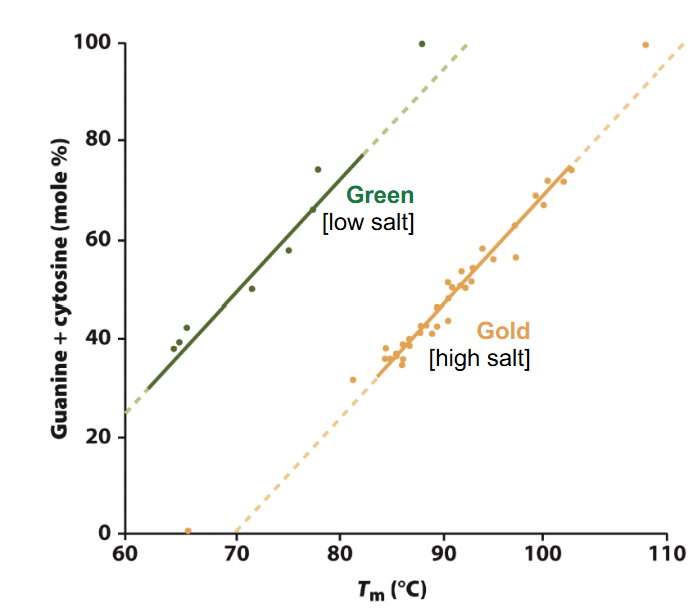
Denaturation and GC content
Tm is a function of the GC content
more GC: higher Tm needed
AT regions separate first during denaturation
the Tm of DNA increases by 0.4°C with every 1% increase in G-C content under normal condition
higher salt = higher Tm
Renaturation
is the recombination of two complementary single stranded DNA
dependent on: DNA concentration - complementary single strands must “fine each other” (number of copies)
Salt concentration - ionic conditions - mask repulsion forces of phosphate backbone
temperature: 20-25°C below Tm
Time (reaction time)
Size of the DNA fragment (length)
Complexity - simple sequences re-nature faster than complex sequences
these properties are used to analyze and classify DNA
CoT analysis
rate of renaturation = measure of complexity of DNA/genome
re-association kinetics: speed at which a single strand sequence is able to find a complementary sequence and base pair with it
expect: increase in genome size = increase in complexity
simple sequences re-nature more quickly than complex sequences
Co= starting concentration
t = rxn time (in sec)
Cot analysis conditions
units of complexity are measured in terms of nucleotides
if a genome is all unique (nonrepeating_ in a sequence then: complexity = # of nucleotides
if a genome contains unique sequences and some repetitive sequences then: complexity = # of unique nucleotides + total # of nucleotides from one copy to each repetitive sequence
if two DNA sequences do not have repetitive sequences and have similar C-G contents, their sizes are proportional to their Cot ½
Complexity examples
DNA composed of the repeating copolymer dAT (ATATATATAT) has a complexity of 2
DNA composed of the repeating tetrameric sequence (ATGC) n has a complexity of 4
A DNA composed of 10 5 non-repeating nucleotide pairs in length has a complexity of 105
A DNA composed of 10 5 non-repeating nucleotide pairs, plus 100 copies of dAT, 50 copies of (ATGC) in length has a complexity of 105 + 2 + 4
How is a Cot analysis carried out?
take a control DNA which is known and 100% complementary and unknown DNA
Shear them into small pieces (approx. 200bp)
Denature with heat
allowed to cool slowly (re-anneal)
Sub-samples removed: ds & ss DNA measured (abs at 260nm measured over time decrease during renaturation)
Data points plotted as a proportion of ssDNA (or %dsDNA) out of the total DNA
E. coli Genome vs. Calf Genome
e. coli: no repetitive sequences - genome is one unique sequence
difficult for sequences to find complementary sequences
once they are found - fast re-association
calf: lots of highly repetitive sequences - fast re-association
some moderately repetitive sequences slower re-association at the beginning
slowest (those unique sequences are comparable to E. coli genome)
Highly Repetitive
often short sequences, but there are many of them, they are able to find each other very easily → fast renaturation.
Moderately repetitive
moderate # (10-100), find each other with little difficulties, need little more time → middle renaturation. Some of them lack coding function. Some of them - code for different gene families: globin genes, immunoglobulin genes, genes for tRNAs and rRNAs etc.
Unique repitition
one to few copies, have lots of difficulties to find each other during renaturation → slow renaturation → mostly protein coding sequences
Reassociation is inversely proportional to the genome (DNA) size
the DNA sources are:
synthetic DNA duplex of poly A and poly U polynucleotide chains;
MS-2 DNA (bacteriophage); T4 DNA (more complex bacteriophages then MS-2)
E. coli DNA
if a genome does not contain repetitive sequences, the complexity of the genome (expressed in # of nucleotides) is the same as the genome size
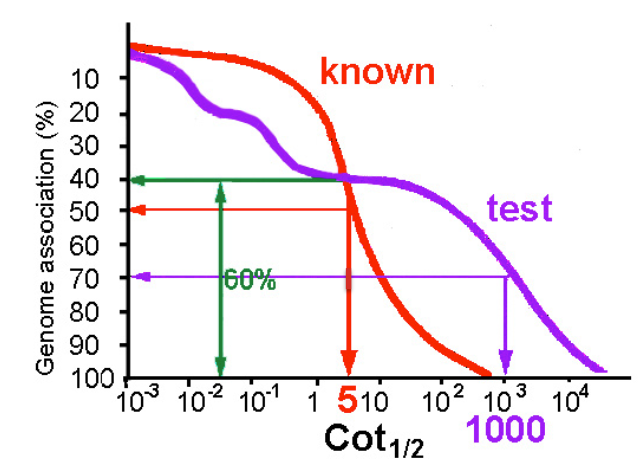
Determining Genome Size by Cot Analysis
calculate the ratio between the rate of renaturation (Cot ½) of known unique sequence DNA and that of the unique fraction of unknown test sample
Cot ½ (known)/ Cot ½ (test) = size of genome (=4 × 106bp)/size of unique fraction of test genome
5/1000 = 4 × 106 bp/x = 8 × 108 = size of the unique part of the unknown genome which represents about 60% of the whole
x/100 = 8 × 108 bp/60; x = approx size of total unknown genome = 1.3 × 109 bp
Cot analysis revived: aids genome sequencing
unique, protein coding sequences could be “purifies” from the mix
faster sequencing
cheaper sequencing
Is complexity of genome correlated with the biological complexity of the organism?
N = haploid chromosome #
C = DNA/haploid cell
C varies greatly; general increase from prokaryotes to eukaryotes; large differences within eukaryotes
C value paradox
no correlation between the amount of DNA (size of genome) and the apparent complexity of organisms
Circular DNA
is composed of 2 strands of DNA that form a closed structure without free ends = “double circle”
prokaryotic genomic DNAs, plasmids and many viral DNAs are circular
chloroplast and mitochondria also have circular genomes = endosymbiotic theory
Denaturation of circular DNA
circular DNA can also be denatured like linear DNA
however, two strands cannot unwind and separate like linear DNA
in vivo, nicking occurs naturally during DNA rep.
can be induced experimentally by using an enzyme
Both circular and linear DNA:
primary structure of DNA: sugar-phosphate “chain” with purine and pyrimidine bases as side chain(s)
secondary structure of DNA double helical structure (H bonds between A-T and G-C; stacking interactions; phosphate backbone “outside"“)
Tertiary/higher order structure: double stranded DNA (both circular and linear) make complexes with proteins - supercoil
Supercoiling
“coiling of a coil”
reduce stress on DNA by twisting/untwisting double helix
Topological isomers - DNA differing only in their states of supercoiling
important for packing of DNA - circular of linear
DNA helix become topographically linearized (locally uncoiled) during replication and transcription
base pairing is interrupted
DNA molecules exhibits supercoiling
Positive and Negative Supercoils
when a protein opens double-stranded DNA
in the front of the opening: DNA becomes overwound (more twists than normal) → creates a + supercoil, DNA is under greater torsional stress
behind the opening: DNA becomes underwound (fewer twists than normal) → creates - supercoils, DNA is more relaxed and tends to unwind;
Topology Numbers
Twisting Numbers (T): measures how tightly the two DNA strands twist around each other
Right-handed DNA: +T, left-handed DNA: -T
Writhing Number (W): measures supercoiling (how many times DNA helix crosses over itself)
Relaxed DNA: W = 0; -ve supercoils: W< 0; +ve supercoils: W> 0
Linking Number (L): Total number of times one DNA strand wraps around the other
includes both normal and twisting and supercoiling: L = T + W
for closed circular DNA, L is constant unless DNA is cut
Topoisomerases
are enzymes that recognize and regulate supercoiling and play an important role in replication and transcription
Most cell DNA are negatively supercoiled
negative supercoils store energy - energy of negative supercoils can be converted into unwinding of double helix
DNA overwound: +ve supercoiling: reduce chance of DNA-protein interaction
DNA underwound: -ve supercoiling: store energy that could help strand separation - unwinding favoured (for rep and transcription)
Prokaryotic
+ and - supercoils essential in prokaryotes - studies with mutants
topoisomerase I: nicking-closing enzyme, makes transient cuts in one strand - relaxes negative supercoiling in one strand - relaxes (-) supercoiling in prokaryotes, changes L# in steps of 1
topoisomerase II - relaxes + supercoiling (uses ATP). Makes double-stranded cut, pass a duplex DNA through it and re-seals the cut, changes L# in steps of 2
Gyrase (one of bacterial Topo II): introduces - supercoils
Reverse gyrase - in hyperthermophillic archaea, topo I generates + supercoils (requires ATP)
stabilizing the genome structure at high temperature (genetic knock-out experiments: reverse gyrase mutant is viable but shows significant growth defects at high temperature)
protecting the DNA strand breakage promoted by exposing DNA to high temperature
mRNA
messenger RNA, specifies order of amino acids during protein synthesis
tRNA
transfer RNA, during translation mRNA information is interpreted by tRNA
rRNA
ribosomal RNA, combines with proteins aids tRNA in translation
Small RNAs
variety of regulatory functions
Riboenzymes
RNAs with enzymatic functions (in splicing, and peptide bond formation during protein synthesis)
RNA functions
Noncoding RNAs: Regulatory
Coding RNAs: code for proteins
Noncoding RNAs: riboenzymes, transport