Gradient Descent
1/10
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
11 Terms
Gradient Descent Idea
sample input and target
measure the error
adapt the model to step where we descend to direction of low error
repeat till low error is found
Parameter Update
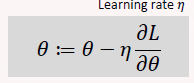
Gradient

Dataset
each elem is a n dimensional vector x
prediction target y is a tensor which we called ground truth
Model
The model has a set of adaptable parameters, 𝜽∈𝚯, generally real numbers: 𝜽 in ℝ.
We write: A model with parameters 𝜃 is 𝑓𝜃:𝑋→𝑌
parameters control behaviour of the model
Learning Algorithm
params are adapted by loss fn
Goal to minimize loss functions
low loss=low error=high accuracy
Linear Regression
Goal: minimize the difference btw y (actual) and ŷ(prediction)
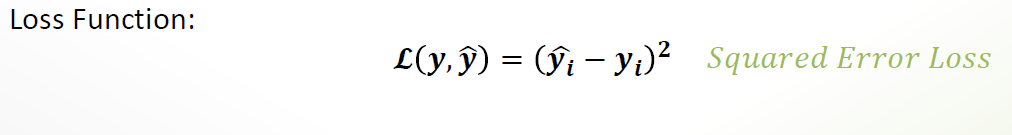
Convex loss function
single global minimum
can be optimized much faster than with gradient descent
Learning Rate
determines how fast we adapt the parameters
high value= faster learning= risk of overshooting the minimum
low value=slower learning=hit minimum with accuracy
Logistic Regression
using regression for classification
idea: encode probability of belonging to a class as numeric probablity
fitting a (inverse) logistic function (aka sigmoid) to the data
based on the predicted value we assign a class
Gradient Descent use
applied to any differentiable model
train a linear/logistic regression model
SVMs
Neural networks
large language models