6. Lineaire regressie, variantie- en covariantie-analyse
1/42
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
43 Terms
Regressie
een statistische techniek om het verband tussen één (univariaat) of meerdere (multivariaat) afhankelijke variabele (Y) en een set van onafhankelijke predictoren (X) te onderzoeken.
Regressiemodel
een hypothetisch statistisch model dat de relatie tussen de uitkomst en de predictoren beschrijft. De invloed van de predictoren op de uitkomst(en) wordt gemodelleerd
regressie van Y op X
Meetniveau: De uitkomst Y moet gemeten zijn op minstens intervalniveau
Toepassingen van regressie
nagaan van effecten van samenhang tussen variabelen
voorspellen van toekomstige observaties
beschrijven van de algemene datastructuur
stochastisch deel (assumpties bij regressie)
verwachting is nul: E(ϵi)=0
homoscedasticiteit: Constante variantie van de fouttermen (Var(ϵi)=σ)
geen correlatie: fouttermen zijn onderling onafhankelijk (Cov(ϵi,ϵj)=0)
interpratie βl
Als de l-de predictor (Xl) met 1 eenheid stijgt terwijl alle andere predictoren constant blijven, neemt de verwachte waarde van Y toe met βl
lineariteit
Het model moet lineair zijn in de parameters (β). Het verband met de predictoren (X) zelf hoeft niet lineair te zijn (bijv. een kwadratisch verband is toegestaan)
doel kleinste kwadratenschatters voor β
Minimaliseren van de SSE (Error Sum of Squares), verticale kwadratische afwijkingen
residuen (kleinste kwadratenschatters voor β)
= Ei
afwijking tussen observatie (Yi) en gefitte waarde (Ŷ)i
gefitte waarde van Y (= Ŷi) (kleinste kwadratenschatters voor β)
Schatter voor de verwachte waarde van Y
schatters (Bj) (kleinste kwadratenschatters voor β)
kansvariabelen met een steekproevenverdeling
puntschattingen (bj) (kleinste kwadratenschatters voor β)
concreet berekende getallen in een steekproef
Gefitte waarde (Ŷ∗) (predicties)
De voorspelde waarde voor Y op basis van nieuwe predictor-waarden
typisch profiel (predicties)
elke predictor wordt gelijkgesteld aan het steekproefgemiddelde
betrouwbaarheidsintervallen
Extra assumptie: Fouttermen moeten onafhankelijk en identisch normaal verdeeld zijn (ϵi∼N(0,σ2)).
Voorspellen van de verwachtingswaarde; het gemiddelde op populatieniveau (E(Y∗))
Verdeling: Maakt gebruik van de t-verdeling met n−(p+1) vrijheidsgraden.
standaardfout: Gebaseerd op S{Ŷ∗}, de onzekerheid van het geschatte gemiddelde.
Betekenis: Bevat met een bepaalde kans (meestal 95%) de werkelijke gemiddelde waarde voor een specifieke set predictoren.
Predictie-intervallen
Assumptie: Fouttermen moeten onafhankelijk en identisch normaal verdeeld zijn (ϵi∼N(0,σ2))
Voorspellen van een individuele toekomstige observatie (Y∗)
rekening houden met onzekerheid van coëfficiënten + spreiding van individuele observaties (σ2)
Standaardfout: Spred{Ŷ∗} = altijd groter dan standaardfout van het gemiddelde
Altijd breder dan een betrouwbaarheidsinterval (door de extra individuele variatie)
Grafisch kenmerk: In een plot is het predictie-interval (vaak rood) de buitenste band, terwijl het betrouwbaarheidsinterval (vaak blauw) nauwer rond de regressielijn ligt
Diagnostische plots
Redisuen vs gefitte waarde
normale QQ-plot
Scale location
Residuals vs leverage
Residuen vs gefitte waarden
Om heteroscedasticiteit en niet-lineariteit op te sporen
Geen trend, random verspreid, niet systematisch groter/ kleiner (= heteroscedasticiteit)
→ diagnostische plot
Normale QQ_plot
Om te controleren of de fouttermen normaal verdeeld zijn
→ diagnostische plot
Scale location
Inspectie van spreiding van gestandaardiseerde residuen voor homoscedasticiteit
σ2 is gelijk voor elke observatie i → rode lijn moet horizontaal zijn!!
→ diagnostische plot
Residuals vs leverage
invloedrijke observaties opsporen = geen assumptie lineair model, maar eerder correctheid model
Leverage: Maat voor hoe extreem de waarden op de predictoren zijn; geeft het potentieel aan om het model sterk te beïnvloeden. (> 2p/n)
Cook’s distance: Maat voor de feitelijke invloed van één observatie op alle predicties in het model (vuistregel: waarden > 0.80/1 duiden op sterke invloed)
→ diagnostische plot
SST
=Total Sum of Squares
De totale variatie in de gegevens.
SSR
= regression sum of squares
het deel van de variatie dat het model wel kan verklaren
SSE
= errom sum of squares
de onverklaarde variatie of e “fout'“ van het model
determinatioëfficiënt
R2
= De proportie (percentage) van de totale variatie in de uitkomst Y die verklaard wordt door de predictoren in het model (enkel R2 heeft deze interpretatie, Ra2 niet!!!)
Aangepaste determinatiecoëfficiënt
Ra2 (adjusted R2)
➔ Corrigeren voor het aantal predictoren in het model.
➔ De gewone R2 stijgt automatisch als je meer variabelen toevoegt, zelfs als ze nutteloos zijn; de aangepaste versie straft dit af om een eerlijker beeld van de populatie te geven.
➔ bv een model met 20 en één met 5 predictoren vergelijken
Semi-partiële correlatie
= sr2
Het deel van de totale variatie in Y dat uniek door deze specifieke predictor verklaard wordt, bovenop wat de rest al verklaart.
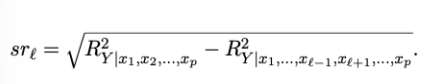
partiële correlatie
= pr2
De samenhang tussen Y en een predictor nadat de invloed van alle andere predictoren uit beide variabelen is verwijderd.
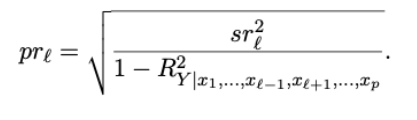
factor
→ regressie met nominale predictoren
statistische term voor een onafhankelijke variabele op nominaal niveau
Variantie-analyse
= anova
specifieke naam voor lineaire regressie wanneer alle predictoren factoren zijn.
→ regressie met nominale predictoren
hercodering
een nominale predictor met I niveaus wordt in het model vertaald naar I−1 hulpveranderlijken.
Dummy-codering
Referentiegroep: één niveau wordt als basis gekozen en krijgt voor alle hulpveranderlijken de waarde 0. ○ de overige groepen krijgen de waarde 1 voor hun eigen specifieke hulpveranderlijke en 0 voor de rest
Intercept (β0): staat voor de verwachte waarde (Y) van de referentiegroep.
Regressiecoëfficiënten (βj): geven het verschil aan tussen de verwachte waarde van groep j en die van de referentiegroep
Effect-codering
Referentiegroep: krijgt voor alle hulpveranderlijken de waarde -1.
de overige groepen krijgen de waarde 1 voor hun eigen specifieke hulpveranderlijke en 0 voor de rest
Intercept (β0): staat voor het marginale gemiddelde (het ongewogen gemiddelde van de gemiddelden van alle groepen).
Regressiecoëfficiënten (βj): geven het verschil aan tussen de verwachte waarde van groep j en het marginale gemiddelde.
Restrictie: de som van alle effecten is nul (∑βi=0), waardoor het effect van de referentiegroep gelijk is aan −∑βj
Genest model
Model B = subset van model A (heeft extra restricties)
Mediatie
= interventie
impliceren van een conceptuele causale relatie
→ er is dus een indirect effect van x op y via een mediator
Paddiagram
= visuele voorstellingen van causale mechanismen tussen verschillende variabelen
→ Hierbij worden padcoëfficiënten gebruikt om de verschillende effecten weer te geven (cf. regressiecoëfficiënten)
De Baron & Kenny methode
= manier om te checken of er mediatie aanwezig is
Sobel test
= meer directe test die probeert te compenseren voor de nadelen van Baron en Kenny-test
→ rechtstreeks kijken voor mediatie-effect
→ probleem: steekproevenverdeling doorgaands niet normaal verdeeld → bootstrap
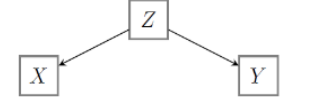
Confounder
→ derde variabele
= er is geen (volledig) verband tussen de onafhankelijke en afhankelijke variabele
→ enkel associatie door gemeenschappelijke oorzaak
→ confounding betekent niet dat Y geen effect geeft op X, een deel wordt gwn door Z als confounder verklaard
oplossing: de confounder opnemen in het model als predictor
Moderatie (=interactie)
→ derde variabele
= het effect van de onafhankelijke op de afhankelijke variabele wordt beïnvloed door de waarden van de derde variabele
→ het effect van de onafhankelijke variabele is afhankelijk van de waarde van de derde variabele
oplossing: moderator (alsook zijn interactie) opnemen in het model als predictor
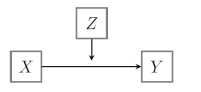
Mediatie
→ derde variabele
= de onafhankelijke variabele is de oorzaak van de derde variabele en de derde variabele is de oorzaak van de afhankelijke variabele (een direct én indirect effect)
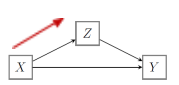
omitted variable bias
→ derde variabele
= vertekening die je krijgt wanneer je een variabele Z niet in het mode opneemt
oplossing: de confounder opnemen in het model = moeilijk
Associatie uitkomst en confounder fout gespecifieerd
Ongemeten confounders niet in model
Designs (3)
Between subjects design: verschillende deelnemers toegewezen aan verschillende condities
Gebalanceerd: even grote groepen
Niet-gebalanceerd: Verschillende groottes
Within subjects design: dezelfde deelnemers toegewezen aan alle (of enkele) condities
Factorieel design: Een ontwerp waarin alle mogelijke combinaties van de niveaus van twee of meer variabelen voorkomen.
Gebalanceerd: De groepen zijn even groot. Dit leidt tot orthogonale (onafhankelijke) effecten.
Niet-gebalanceerd: De groepen zijn ongelijk groot, wat de interpretatie bemoeilijkt omdat effecten elkaar kunnen overlappen
Variantie-analyse
= anova = lineaire regressie met enkel nominale variabelen
Eenwegsvariantie-analyse: Slechts één factor (nominale variabele).
Meerwegsvariantie-analyse: Meerdere factoren tegelijkertijd
Tussensubject: een factor waarbij groepen onderscheiden worden
Binnensubject: een factor waarmee metingen bij eenzelfde subject onderscheiden kunnen worden