Kaarten: Statistiek2 Hf1: Data manipulatie | Quizlet
1/47
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
48 Terms
De data in R: Functie om vectoren aan te maken
<- c(…) vb: > leeftijd <- c(18, 22, 17, 19, 19)
(het pijltje verwijst naar de naamgeving)
Wat is een vector?
een reeks objecten dat als één samengesteld object beschouwd wordt door R
De data in R: Als we enkel de data willen zien van een bepaald individu gebruiken we ...
vierkante haakjes →
[...]
➡Bv: leeftijd [3] zal output 17 geven
![<p>vierkante haakjes →</p><p>[...]</p><p>➡Bv: leeftijd [3] zal output 17 geven</p>](https://knowt-user-attachments.s3.amazonaws.com/2bc9fb2a-e2a9-4a1c-9a3b-012428a7b6d1.png)
De data in R: Gemiddelde
mean

De data in R: Lengte van de vector opvragen
= hoeveel afzonderlijke waarden zitten er in de vector: length (steekproefgrootte)

De data in R: De kleinste waarde van de vector
min

De grootste waarde van de vector
max vb: > max (leeftijd)
[1] 22
![<p>max vb: > max (leeftijd)</p><p>[1] 22</p>](https://knowt-user-attachments.s3.amazonaws.com/45fd9f27-8e5a-49f9-bb39-c7a9a67d765e.png)
Het mediaan van de vector
median vb: > median (leeftijd)
[1] 19
wat is een string
een reeks tekens zonder betekenis voor R (bv: ABC1$, 2018, intrinsieke-motivatie,
...)
Hoe verwarring vermijden wanneer men een reeks tekens ingeeft die niets betekenen voor R (een string)? (2)
- Om verwarring te vermijden moet je een string altijd tussen aanhalingstekens zetten
➡Hierdoor weet R onmiddellijk dat bv variabele roker van ordinaal of nominaal meetniveau is → R weet dat de strings niet-numeriek zijn
- Een andere manier om verwarring te vermijden is door het commando factor te gebruiken
! vb. bij postcode zou R 9000 interpreteren als een getal, maar door aanhalingstekens weet R dat hij het zo niet moet opvatten

Wat is het grote verschil tussen een factor en aanhalingstekens gebruiken bij een string?
aanhalingstekens bij een string: je zegt gewoon aan R: "dit is tekst" (R kan hier niks mee doen)
factor: je zegt aan R: "het gaat om een categorische variabele" (hier kan R wel mee werken)
(vb. als je bij een factor het gemiddelde zou opvragen zou je foutmelding krijgen)
wat moet je doen als je een vector wil aanmaken met waarden van een ordinale variabele?
dan moet je ook het
commando factor gebruiken, maar je gebruikt ook de argumenten levels en ordered
levels
geeft aan hoeveel verschillende waarden er in de vector zijn

Ordered
geeft aan dat de volgorde die je gebruikt de juiste volgorde is
geef een voorbeeld waarbij je de data "uitslag" met drie mogelijke uitkomsten (goud, brons, zilver) in R wilt ingeven
> uitslag <- factor( c("brons", "goud", "goud", "brons", "zilver", "brons", "brons", "brons"), levels = c("brons", "zilver", "goud" ),
ordered =
TRUE)
(ordered: brons < zilver < goud)
wat is het commando data.frame
met het commando data.frame kunnen we tegen R zeggen dat verschillende vectoren bij elkaar horen
(vb. bij 30 studenten 8 variabelen gemeten -> duidelijk maken aan R dat 8 vectoren betrekking hebben op dezelfde 30 studenten)
! data frame is zeer belangrijk, want alle datasets worden in deze vorm weergegeven
maak een data frame aan voor: score, iq, motivatie, geslacht, roken, opleiding, gewicht, lengte
> myData <- data.frame(score, iq, motivatie, geslacht, roken, opleiding, gewicht, lengte)
Wat zal ik krijgen als ik MyData intyp in R?
tabel met alle data van het dataframe Mydata
(R heeft daarbij zelf een extra kolom aangemaakt met een nummer voor elke student)
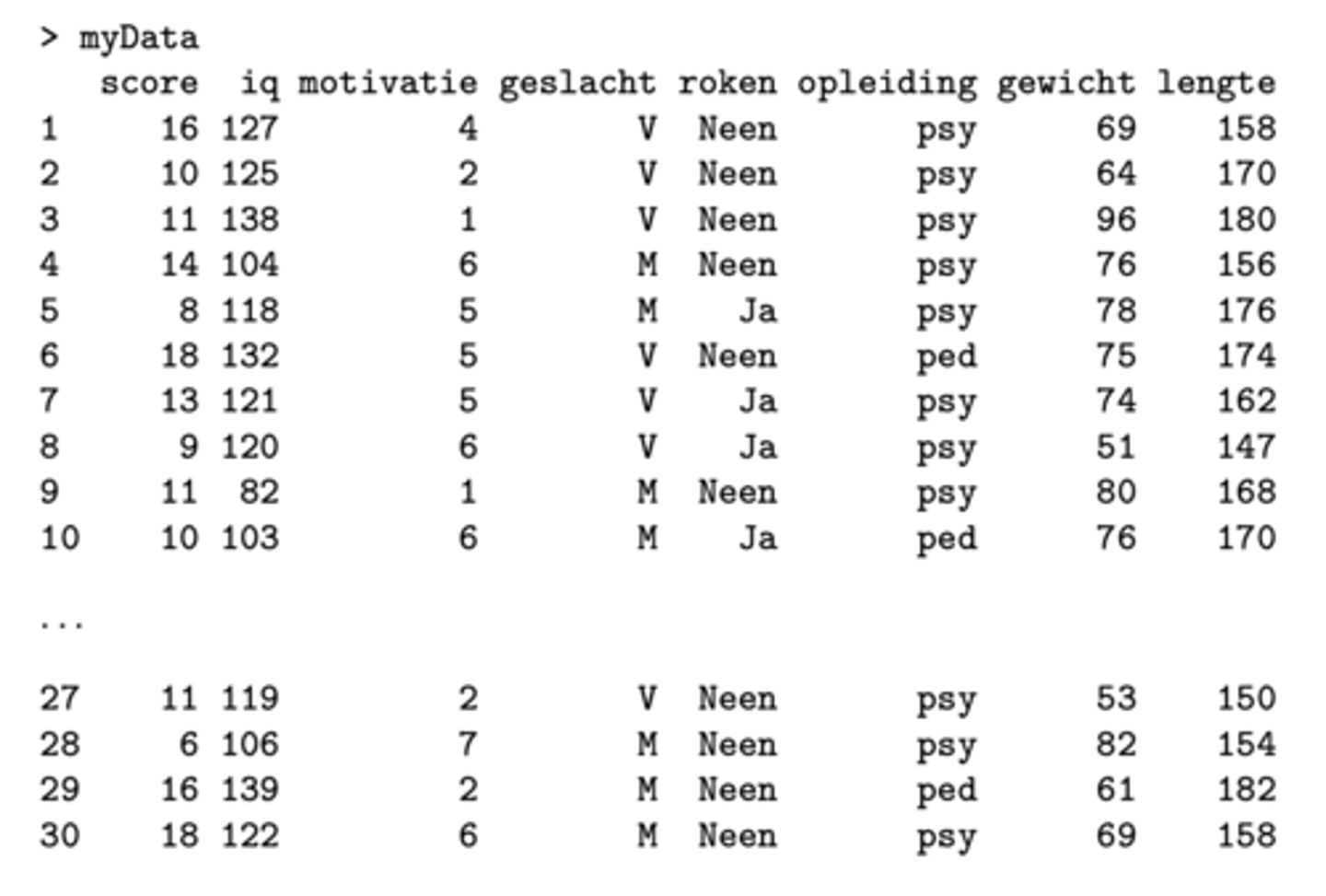
hoe kan ik een specifieke kolom raadplegen van een dataframe?
Indien je een specifieke kolom van deze tabel wil raadplegen typ je myData gevolgd door $ en de naam van de variabele
vb. = myData$gewicht

commando voor aantal rijen en kolommen weergeven
dim

commando steekproefgrootte
dim(...) [1]
commando voor het Het aantal variabelen
dim(...) [2]
Steekproefgrootte
length (...)

commando voor eerste 6 rijen
head
commando voor laatste 6 rijen
tail
commando gebruikt om data op te slaan
write.csv
vb: > write.csv(myData, file = "myData.csv", row.names = FALSE)

commando gebruikt om data in te lezen
read.csv
vector aanmaken
c( )
hoe ken je een naam toe aan een functie
<-
gemiddelde
mean ( )
lengte van een vector (aantal waarden in een vector)
length ( )
kleinste waarde in een vector
min ( )
grootste waarde in een vector
max ( )
mediaan van de vector
median ( )
vector aanmaken van ordinale variabelen
factor ( c(" "), levels = c (" "), ordered = TRUE)
vector aanmaken van categorische variabelen
factor ( c ( ))
data frame aanmaken
data.frame ( )
aantal rijen en kolommen weergeven
dim ( )
steekproefgrootte van data set aan R vragen (twee verschillende manieren)
dim ( )[1] OF length (...$... )
aantal variabelen
dim ( ) [2]
eerste 6 rijen data frame weergeven
head ( )
laatste 6 rijen data frame weergeven
tail ( )
data frame opslaan
write.csv ( , file = " ", row.names = FALSE)
data frame lezen
read.csv ( file = " ")
Wat is het codeboek?
Een document dat beschrijft hoe gegevens in een databestand gecodeerd worden. Is handig voor zowel de onderzoeker, als voor externe lezers. We kunnen het zien als een soort handleiding dat we verplicht dienen op te stellen tijdens het onderzoek.
Wat is missing data?
Een ontbrekend antwoord in de dataset. (vb. antwoord niet leesbaar, testbatterij plat, participant weigerde te antwoorden etc.)
Hoe kunnen we missing data aanduiden in R?
NA (= Not Available)
Wat zijn conditionele vragen? Wat is hierbij bijzonder nuttig?
"zo ja, volgende vraag - zo nee, geen volgende vraag"
! waarde NVT of "niet van toepassing" van belang hierbij