Past CS 330 homeworks
1/20
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
21 Terms

What is the algorithm. What is the time complexity?
Set the left child of the current node v as c_l, and the right child as c_r.
If v has a left child, recursively run this algorithm on the left child and store the result as h_l (the depth of the largest complete subtree rooted there).
If v has a right child, recursively run this algorithm on the right child and store the result as h_r.
If v is missing either child (i.e., it's a leaf or has only one child), set the depth h at this node to 0.
Otherwise, if v has both children, set h = the smaller of h_l and h_r, plus 1. (We take the minimum because a complete subtree can only go as deep as the shallower side allows.)
If this depth h is greater than or equal to the best depth found so far globally, update the global best answer to record v as the root and h as the depth.
Return h to the parent so it can use this result in its own calculation.
T(nl)+T(nr) + c solves to O(n), each node is visited once
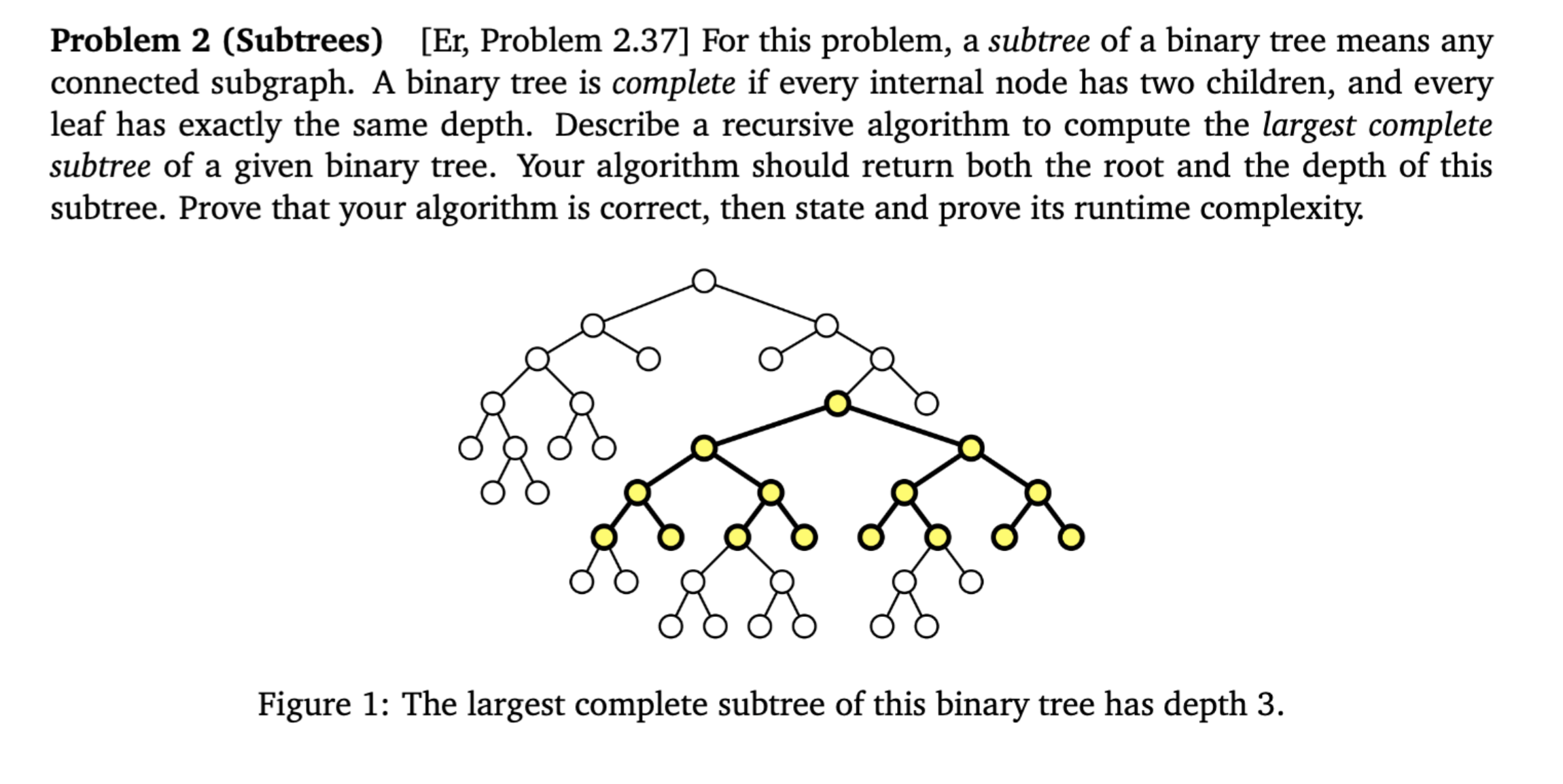
Proof of Correctness
Method: Induction on the size of the subtree rooted at v.
Base Case (leaf node):
If v has no children, it's a leaf
The largest complete subtree is just v itself, which has depth 0
The algorithm correctly sets h = 0 ✓
Inductive Step (internal node):
Assumption: The algorithm works correctly for all nodes smaller than v (i.e., it works for c_l and c_r)
Two sub-cases:
One child is null → largest complete subtree at v has depth 0, algorithm sets h = 0 ✓
Both children exist → we need to show h = min(h_l, h_r) + 1 is correct. This is the core claim, proven in two directions:
Forward: If a complete subtree of depth h is rooted at v, then both children must have complete subtrees of depth h − 1, so min(h_l, h_r) ≥ h − 1
Backward: If both children have complete subtrees of depth h', you can combine v + both subtrees to form a complete subtree of depth h' + 1, so h ≥ min(h_l, h_r) + 1
Together these force h = min(h_l, h_r) + 1 ✓
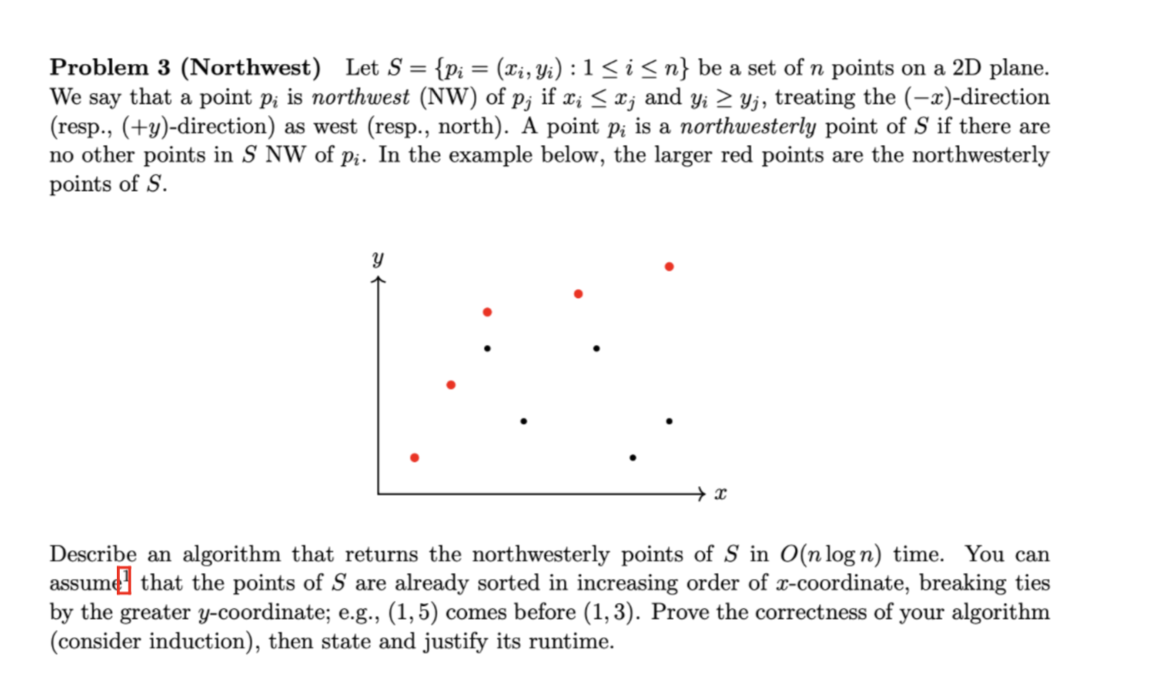
Describe the algorithm and time complexity
The Algorithm (Divide & Conquer)
The strategy is to split the points by their x-coordinates and then filter them based on their y-coordinates.
Pre-sort: Sort points by x (increasing). If x is tied, put the higher y first.
Divide: Split the array into a Left half (L) and a Right half (R).
Conquer (Recurse): Find the Northwesterly points for both halves independently (NWL and NWR).
Combine (The Filter):
Find the highest y-value in the Left half (y∗=maxy in L).
Any point in NWR is only "Northwesterly" for the whole set if its y is strictly greater than y∗.
Final Output: All of NWL + the filtered points from NWR.
Sorting: O(nlogn) to start.
Recurrence: T(n)=2T(n/2)+O(n).
The O(n) comes from finding the max y in L and scanning NWR.
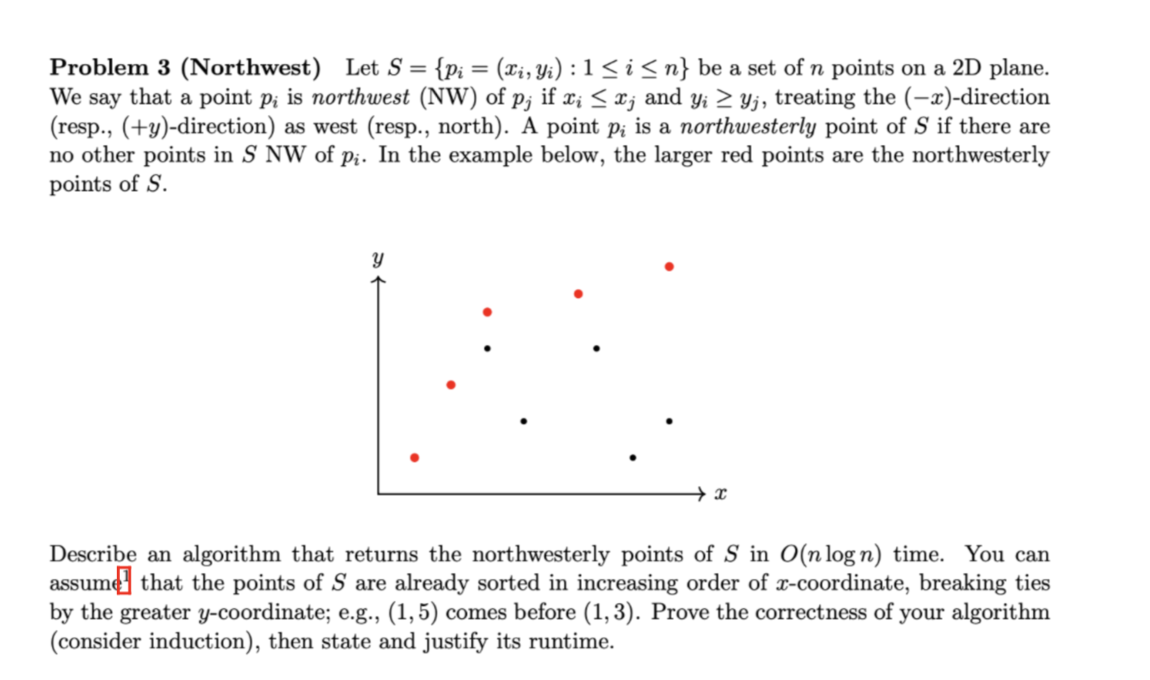
Proof of Correctness Northwestly
Correctness Proof (Inductive Step)
Assume FindNW is correct for all inputs smaller than n. For a set S of size n, we split it into L and R.
The Partition: Every point p∈S falls into one of these four cases:
The "Losers" (p∈/NWL and p∈/NWR): If p was already dominated by a point in its own half, it is disqualified from the total set S.
The "Safe Left" (p∈NWL): These are always kept. Since L is to the left of R (xL≤xR), no point in R can be "Northwest" of a point in L.
The "High Right" (p∈NWR and yp>y∗): These are kept. They are the best in their half, and because they are higher than the highest point in L (y∗), no point in L can be "Northwest" of them.
The "Low Right" (p∈NWR and yp≤y∗): These are discarded. The point in L that has height y∗ is northwest of p (because xy∗≤xp and y∗≥yp).
Key Components to Memorize
Base Case: n=1 is trivially northwesterly.
Hypothesis:
FindNWworks for k<n.The Filter: NWL∪{p∈NWR∣yp>maxyL}.
The Justification: * L points only care about other L points.
R points must beat the "ceiling" (y∗) set by L to stay northwesterly.

Step 1 — Choose what to induct on We induct on the size of the range (right index minus left index plus one).
Step 2 — Handle the base case If the range has just one element, the prefix sum is just that element. Done, trivially correct.
Step 3 — State the inductive hypothesis Assume PrefixSum works correctly for any range smaller than the one we're looking at now.
Step 4 — Recurse on the left half Call PrefixSum on the left half. By the inductive hypothesis (it's a smaller range), every entry in the left half is now correctly filled with its running sum from the left boundary.
Step 5 — Note the midpoint value The entry at the midpoint now holds the sum of all elements in the left half. This is the key value we'll use next.
Step 6 — Recurse on the right half Call PrefixSum on the right half. By the inductive hypothesis, every entry in the right half correctly holds its running sum — but only counting from the midpoint onward. It's missing the left half's contribution.
Step 7 — Add the midpoint to the right half Add the midpoint value to every entry in the right half. Each entry now holds its right-half running sum plus the entire left half sum — which is exactly the correct prefix sum from the left boundary.
Step 8 — Conclude The whole range is now correctly computed, so the induction is complete. ✓

Span and Work


Describe the algo
REARRANGE Parallel Algorithm
This procedure uses a recursive divide-and-conquer strategy to move all positive elements to the front of a range and returns the total count of positive numbers found.
1. Base Case
If the range contains a single element ($l = r$):
Check the value of $A[l]$.
If $A[l] > 0$, return 1.
If $A[l] = 0$, return 0.
2. Divide
Calculate the midpoint m = \lfloor (l+r)/2 \rfloor$ to split the current range into a left and right half.
3. Parallel Recursion
spawn a recursive call to
REARRANGE(A, l, m)to process the left half. Assign the returned count of positive elements to $n_1$.Simultaneously call
REARRANGE(A, m + 1, r)for the right half. Assign the returned count of positive elements to $n_2$.sync the execution to ensure both recursive branches have finished their local rearrangements before proceeding.
4. Parallel Buffer Copy
Create a temporary array $B$ of size $n_2$.
Use a parallel for loop from $i = 0$ to $n_2 - 1$:
Copy the $n_2$ positive elements from the start of the right half ($A[m + 1 \dots]$) into $B[i]$.
5. Parallel Shift (The Merge)
Use a parallel for loop from $i = 0$ to $n_2 - 1$:
Copy the elements from the buffer $B[i]$ back into the main array $A$, starting at index $l + n_1$. This places the right half's positives directly after the left half's positives.
6. Parallel Zero-Fill
Use a parallel for loop from $i = l + n_1 + n_2$ to $r$:
Overwrite the remaining indices in the range with $0$.
7. Completion
Return the sum $n_1 + n_2$ to the caller.

Proof of correctness
Proof of Correctness: REARRANGE
1. Base Case:
For a subproblem of size 1 ($r = \ell$), there is nothing to rearrange. The procedure correctly returns $1$ if $A[\ell] > 0$ and $0$ otherwise.
2. Inductive Hypothesis:
Assume the procedure correctly rearranges subproblems of size less than $n$. Thus, after the parallel recursive calls, the left and right subarrays are locally partitioned:
Left: Positives in $[l \dots l+n_1-1]$, followed by zeroes in $[l+n_1 \dots m]$.
Right: Positives in $[m+1 \dots m+n_2]$, followed by zeroes in $[m+1+n_2 \dots r]$.
3. Inductive Step (The Merge):
We must show the merge steps correctly combine these halves into a single partitioned range:
Buffer Copy: The first parallel loop safely stores the right half’s $n_2$ positive elements into auxiliary array $B$.
Shifting: The second parallel loop writes $B$ into $A$ starting at index $l+n_1$. This places them immediately after the left half's positives, creating a contiguous block of $n_1 + n_2$ positive elements at the front.
Zeroing: The final parallel loop fills all remaining indices ($l+n_1+n_2$ to $r$) with zeroes.
4. Conclusion:
The return value $n_1 + n_2$ accurately reflects the total positive elements. By induction, the algorithm is correct for all $n$.

Work and Span


Describe the algorithm
Here is the Bitonic-Merge algorithm summarized in its most concise, sequential form for an exam:
Base Case: If $\ell = r$, return (the subarray is a single element).
Set Offset: Calculate $m = \lfloor (r + \ell) / 2 \rfloor$ and the offset $t = m - \ell + 1$.
Parallel Swap: For all $i$ from $\ell$ to $m$ simultaneously: If $A[i] > A[i + t]$, swap them.
Synchronize: Wait for all swaps in Step 3 to finish.
Recursive Split: Spawn
BitonicMerge(ℓ, m)and callBitonicMerge(m + 1, r).Final Sync: Wait for both recursive calls to complete, then return.

Prove Bitonic
Proof of Correctness: BitonicMerge
1. Base Case
For $n=1$, the subarray is already sorted. The algorithm returns without changes, which is correct.
2. Inductive Hypothesis
Assume BitonicMerge correctly sorts any bitonic subarray of size $k < n$.
3. Inductive Step
We prove that after the parallel "half-cleaner" loop (the compare-and-swap step):
Partitioning: Every element in the left half $A[\ell \dots m]$ is $\leq$ every element in the right half $A[m+1 \dots r]$.
Bitonic Property: Both resulting halves remain bitonic.
The Swap Logic:
By comparing $A[i]$ with $A[i+t]$ and swapping if $A[i] > A[i+t]$, the smaller elements are forced into the left half and larger ones into the right.
The Contradiction:
If an element in the left were still larger than one in the right, the original array would have required at least two "peaks" to satisfy the swap conditions. Since a bitonic sequence is defined by having only one peak (after circular shifting), this is impossible.
4. Conclusion
Since the halves are correctly partitioned and remain bitonic, the recursive calls (guaranteed by our hypothesis) will sort each half. Because all left elements are $\leq$ all right elements, the entire array is sorted upon completion.

Provide work and span of bionic


Describe the algorithm + time complexity
Steps:
Base Case: If ℓ=r, set B[ℓ]=A[ℓ].
Divide & Spawn: * Compute m=⌊(ℓ+r)/2⌋.
spawnrecursive call for left subarray [ℓ,m].Execute recursive call for right subarray [m+1,r].
Sync: Wait for both recursive branches to terminate.
Parallel Merge: * Execute
parallel forfrom i=m+1 to r.Update: B[i]=B[i]+B[m].
Work and Span Analysis
Span ($T_{\infty}$): The critical path (longest chain of dependencies).
Recurrence: $T_{\infty}(n) = T_{\infty}(n/2) + O(\log n)$
Logic: * $T_{\infty}(n/2)$: Parallel execution of child processes (only one contributes to the path).
$O(\log n)$: Span of the
parallel forloop.
Complexity: $T_{\infty}(n) = O(\log^2 n)$
Work ($W$): Total operations performed across all processors.
Recurrence: $W(n) = 2W(n/2) + O(n)$
Logic: * $2W(n/2)$: Must account for both recursive branches.
$O(n)$: Sequential cost of the loop.
Complexity: $W(n) = O(n \log n)$

Proof of correctness
Goal: Prove that the parallel algorithm correctly computes the prefix sum for any range of size $n$.
1. Base Case ($n=1$):
A range with only one element is already its own prefix sum. The algorithm correctly assigns $B[\ell] = A[\ell]$.
2. Inductive Hypothesis:
Assume the algorithm works perfectly for any subarray smaller than size $n$.
3. Inductive Step (Size $n$):
Left Subarray: By the hypothesis, the first half is computed correctly. Specifically, the last element of the left side ($B[m]$) now holds the total sum of that entire left half.
Right Subarray: Similarly, the second half is computed correctly, but these values are only "local" (they only sum elements starting from the midpoint).
The Adjustment: The algorithm adds the total sum of the left half ($B[m]$) to every element in the right half. This shifts the "local" sums of the right side to "global" sums starting from the very beginning of the array.
Conclusion:
Since both halves are now correctly relative to the start of the range, the algorithm is correct for size $n$.

Describe the algorithm + time complexity
Algorithm (DP)
Initialize a 2D array called DP with a size of (n+1) rows and (v+1) columns, filled with zeros.
Base Cases:
Set DP[0][0] to 1. This means you can successfully make a value of 0 using zero coins.
For all other values in the first row (where the target sum S is greater than 0), DP[0][S] remains 0, as you cannot make a positive value with zero coins.
Iteration: Loop through each coin denomination (k) from 1 to n. Inside that loop, loop through every possible target value (S) from 0 to v.
Case Analysis:
If the current target value S is smaller than the current coin value, you cannot use the coin. Set DP[k][S] equal to the result from the previous coin: DP[k-1][S].
If the target value S is greater than or equal to the coin value, check two things: could you make this value without the current coin (DP[k-1][S]), OR could you make the remaining value if you did use this coin (DP[k-1][S minus current coin value]). If either is true (1), set DP[k][S] to 1.
Result: The answer is stored in the bottom-right cell, DP[n][v].
Time Complexity O(nv). The algorithm uses two nested loops where the outer loop runs n times and the inner loop runs v times. Every cell is calculated once in constant time.
![<p>Algorithm (DP)</p><p>Initialize a 2D array called DP with a size of (n+1) rows and (v+1) columns, filled with zeros.</p><p>Base Cases:</p><p>Set DP[0][0] to 1. This means you can successfully make a value of 0 using zero coins.</p><p>For all other values in the first row (where the target sum S is greater than 0), DP[0][S] remains 0, as you cannot make a positive value with zero coins.</p><p>Iteration: Loop through each coin denomination (k) from 1 to n. Inside that loop, loop through every possible target value (S) from 0 to v.</p><p>Case Analysis:</p><p>If the current target value S is smaller than the current coin value, you cannot use the coin. Set DP[k][S] equal to the result from the previous coin: DP[k-1][S].</p><p>If the target value S is greater than or equal to the coin value, check two things: could you make this value without the current coin (DP[k-1][S]), OR could you make the remaining value if you did use this coin (DP[k-1][S minus current coin value]). If either is true (1), set DP[k][S] to 1.</p><p>Result: The answer is stored in the bottom-right cell, DP[n][v].</p><p></p><p><strong>Time Complexity</strong> O(nv). The algorithm uses two nested loops where the outer loop runs n times and the inner loop runs v times. Every cell is calculated once in constant time.</p>](https://assets.knowt.com/user-attachments/29d5817e-ec18-49a4-bdd4-db079e96a4ff.png)

Proof of correctness
Proof of Correctness (Induction)
Base Case: DP[0][0]=1 is correct as 0 can be formed using no coins.
Inductive Step: For a value j and coin xi, if j<xi, xi cannot contribute to the sum, so we correctly rely on the previous i−1 coins. If j≥xi, we check if j was possible with fewer coins or if the remainder (j−xi) was possible with fewer coins; if either is true, j is possible.

Describe the algorithm + time complexity
Algorithm (Two-Step DP)
Precompute Palindromes: Create a table PAL[i][j]. For all possible substrings, check if the first and last characters match and if the inner substring is already a palindrome (PAL[i+1][j−1]).
+2
Initialize DP: Create an array DP[i] where DP[i] is the minimum cuts for string s[1:i].
+1
Minimize Cuts: For each position i in the string, iterate through all previous positions k.
+1
Update: If s[k:i] is a palindrome (checked via PAL[k][i]), update DP[i] to be the minimum of its current value or 1+DP[k−1].
+1
Result: DP[n] is the minimum number of palindromes.
Time Complexity
O(n2): Both precomputing the PAL table and filling the DP array require nested loops of size n, totaling O(n2)+O(n2)=O(n2).
![<p><strong>Algorithm (Two-Step DP)</strong></p><ol><li><p><strong>Precompute Palindromes:</strong> Create a table <span>P</span>AL[i][<span>j</span>]. For all possible substrings, check if the first and last characters match and if the inner substring is already a palindrome (<span>P</span>AL[i+1][<span>j</span>−1]).</p><p>+2</p><p></p></li><li><p></p><p><strong>Initialize DP:</strong> Create an array <span>DP</span>[i] where <span>DP</span>[i] is the minimum cuts for string s[1:i].</p><p>+1</p><p></p></li><li><p></p><p><strong>Minimize Cuts:</strong> For each position i in the string, iterate through all previous positions <span>k</span>.</p><p>+1</p><p></p></li><li><p></p><p><strong>Update:</strong> If s[<span>k</span>:i] is a palindrome (checked via <span>P</span>AL[<span>k</span>][i]), update <span>DP</span>[i] to be the minimum of its current value or 1+<span>DP</span>[<span>k</span>−1].</p><p>+1</p><p></p></li><li><p></p><p><strong>Result:</strong> <span>DP</span>[n] is the minimum number of palindromes.</p></li></ol><p><br><strong>Time Complexity</strong></p><ul><li><p></p><p><span><strong>O</strong></span><strong>(n</strong><span><strong>2</strong></span><strong>)</strong>: Both precomputing the <span>P</span>AL table and filling the <span>DP</span> array require nested loops of size n, totaling <span>O</span>(n<span>2</span>)+<span>O</span>(n<span>2</span>)=<span>O</span>(n<span>2</span>).</p></li></ul><p></p>](https://assets.knowt.com/user-attachments/c752e4b8-d0bd-4735-8ff7-162a9d4b7615.png)

Correctness
Proof of Correctness
The PAL recurrence correctly identifies all palindromic substrings by expanding from the center. The DPrecurrence ensures optimality by checking every possible "last palindrome" s[k:i] and building upon the optimal solution for the prefix ending at k−1.
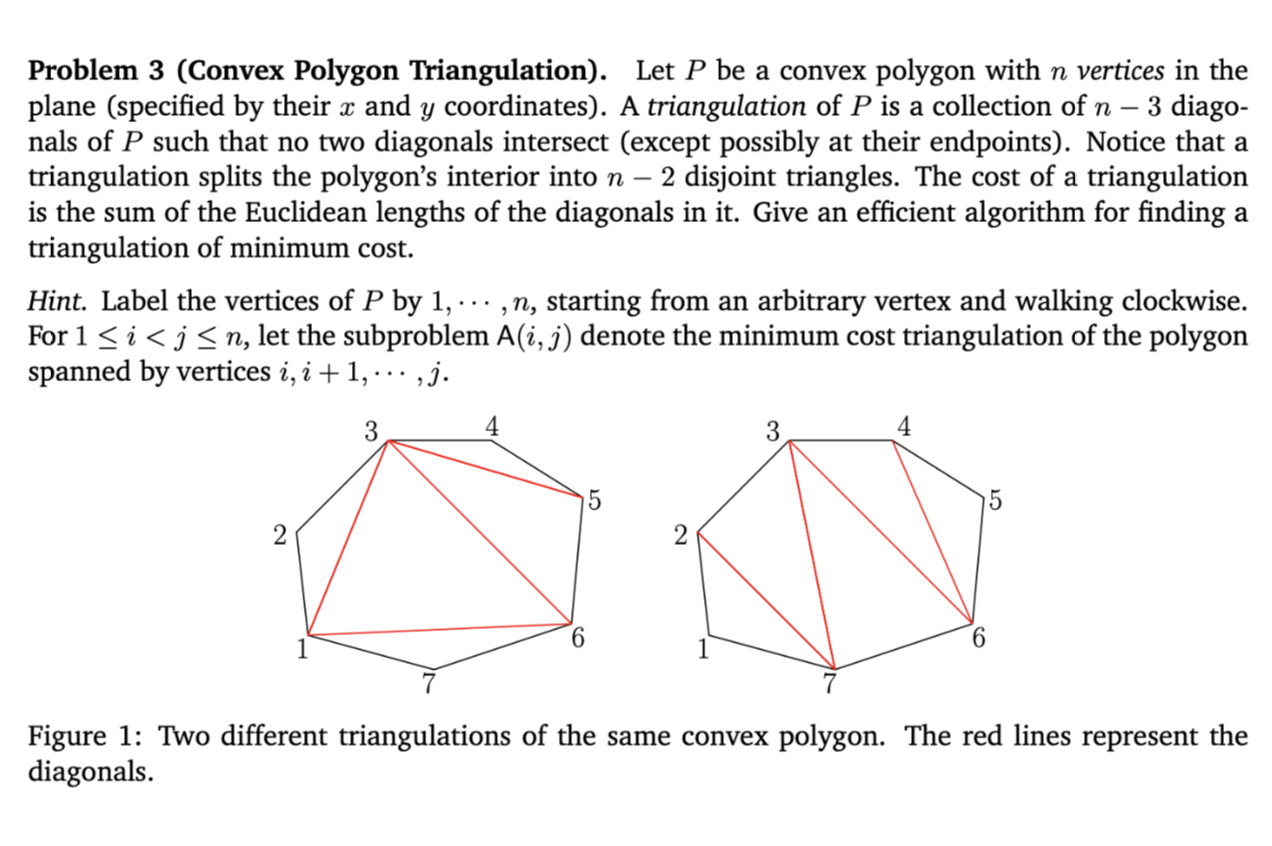
Describe the algorithm
Algorithm (DP)
Label Vertices: Label vertices 1 to n clockwise.
Base Cases: For all i, set A(i,i+1)=0 and A(i,i+2)=0 because 2 or 3 vertices form a triangle or line with no internal diagonals.
+1
Iterate by Gap Size: Loop through subproblem sizes m from 3 to n−1.
Subproblem Optimization: For each range (i,j) where j=i+m, find a vertex k between i and j that minimizes the total cost:
+3
Cost=A(i,k)+A(k,j)+w(i,k,j), where w is the length of the new diagonals created by triangle ijk.
+2
Result: A(1,n) provides the minimum cost for the full polygon.
Time Complexity
O(n3): There are three nested loops: one for the subproblem size (m), one for the starting vertex (i), and one to test each intermediate vertex (k).
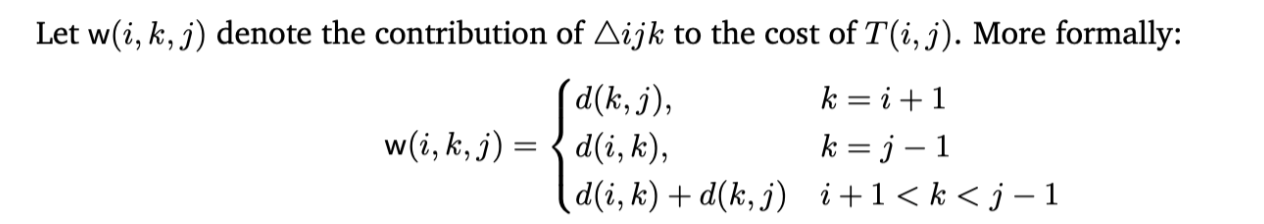
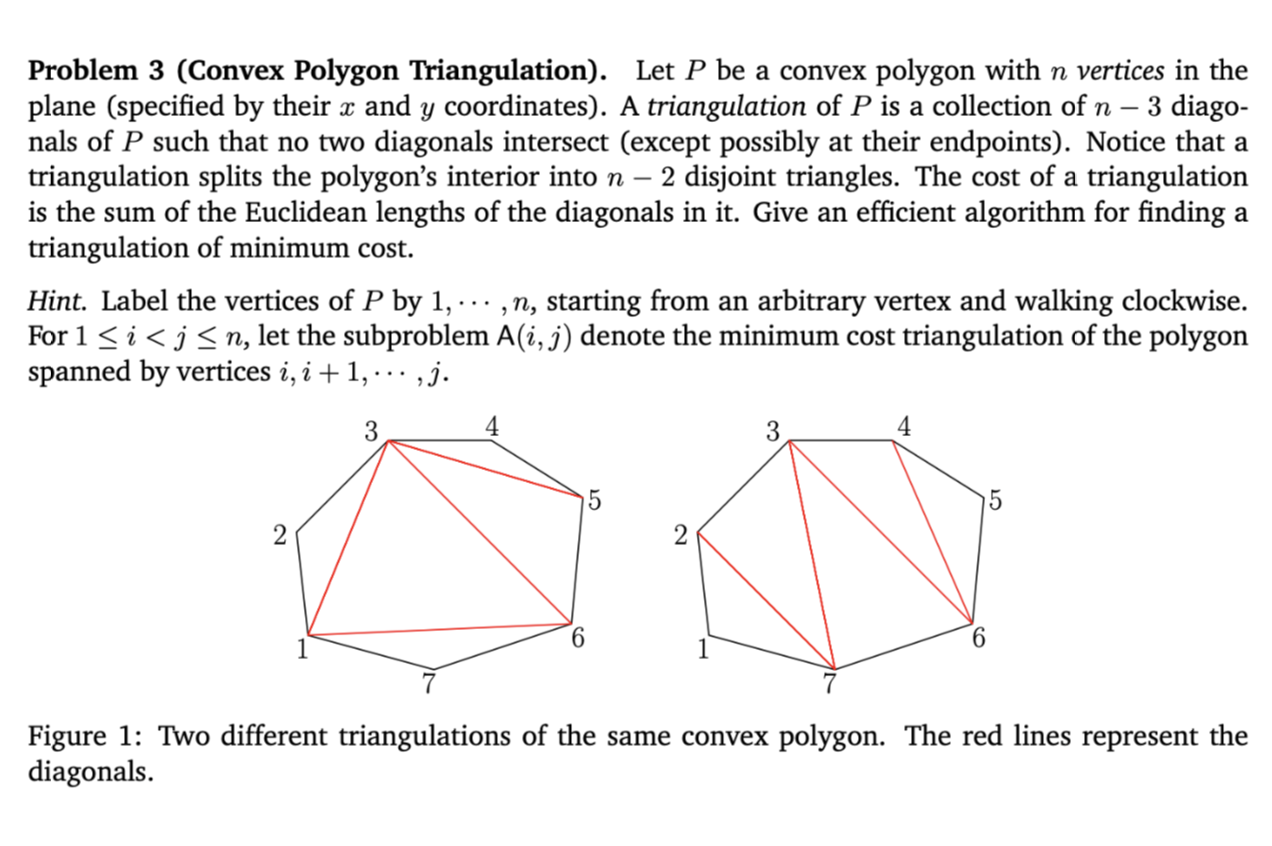
Proof of correctness
Any triangulation of polygon P(i,j) must contain a triangle △ijk for some k. By iterating over all possible k and assuming the sub-polygons P(i,k) and P(k,j) are also triangulated optimally (the optimal substructure property), the recurrence must find the global minimum.
Algo + time complexity
Algorithm (DP)
Initialize: Create a 2D array D[i][j] to store the cost of aligning prefix A[1:i] and B[1:j].
Base Cases: If i=1 or j=1, the cost is the sum of Euclidean distances from the single point in one trajectory to all points in the other.
Recursive Step: For i>1 and j>1, the last points A[i−1] and B[j−1] must be aligned.
Minimize Transitions: Calculate the distance d(A[i−1],B[j−1]) and add it to the minimum of three prior states:
+1
D(i−1,j−1): Both trajectories move forward.
D(i,j−1): Trajectory B moves forward, A stays.
D(i−1,j): Trajectory A moves forward, B stays.
Result: D(∣A∣,∣B∣) is the minimum alignment cost.
Time Complexity
O(∣A∣∣B∣): The algorithm fills an ∣A∣[citestart]×∣B∣ table, where each cell is computed in O(1) time.