Nucleotide and nucleic acids
1/10
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
11 Terms
DNA and RNA
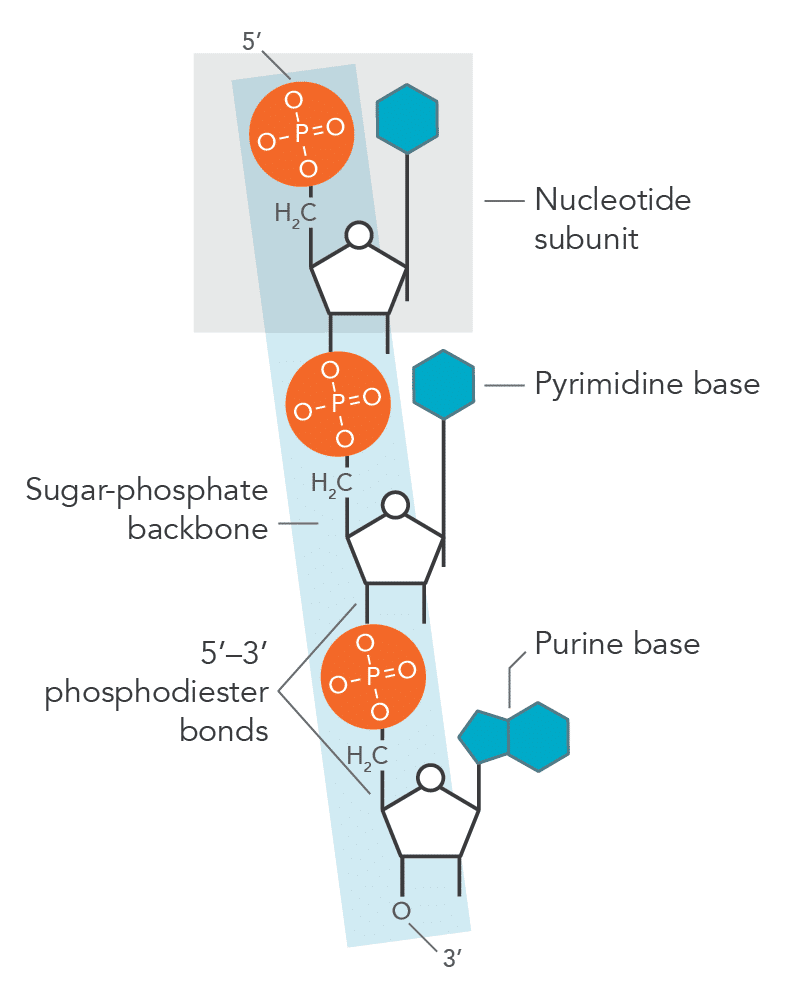
Nucleotide = monomer of nucleic acids (DNA and RNA)
Made of:
Backbone: Phosphate group and pentose sugar
Nitrogen-containing base
DNA nucleotide
Sugar = deoxyribose
Bases = Adenine (A), Thymine (T), Cytosine (C), Guanine (G)
RNA nucleotide
Sugar = ribose
Bases = Adenine (A), Uracil (U), Cytosine (C), Guanine (G)
Purines (double-ring bases)
Adenine (A)
Guanine (G)
Pyrimidines (single-ring bases)
Cytosine (C)
Thymine (T) (DNA only)
Uracil (U) (RNA only)
Synthesis and breakdown polynucleotides
Polynucleotides are formed when nucleotides join together.
Phosphodiester bonds form between the phosphate group of one nucleotide and the pentose sugar of another (5’ to 3’).
Synthesis (condensation reaction):
Water is removed.
Phosphodiester bonds are formed.
Produces a polynucleotide chain (DNA or RNA).
Breakdown (hydrolysis reaction):
Water is added.
Phosphodiester bonds are broken.
Releases individual nucleotides.
ADP and ATP
ATP (adenosine triphosphate) and ADP (adenosine diphosphate) are phosphorylated nucleotides.
Ribose (pentose sugar)
Adenine (nitrogenous base)
Phosphate groups
ATP = adenine + ribose + 3 phosphate groups
ADP = adenine + ribose + 2 phosphate groups
ATP can be hydrolysed to ADP + Pi, releasing energy.
ADP can be phosphorylated to form ATP, storing energy, via respiration
DNA structure
DNA (deoxyribonucleic acid) consists of two polynucleotide strands.
Each strand has a sugar-phosphate backbone linked by phosphodiester bond
The strands run antiparallel (opposite directions)
complementary base pairing:
Adenine (A) ↔ Thymine (T) (2 hydrogen bonds)
Guanine (G) ↔ Cytosine (C) (3 hydrogen bonds)
The two strands twist around each other to form a double helix.
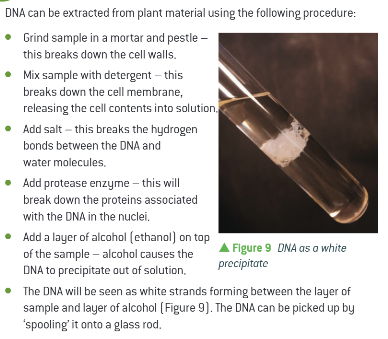
DNA extraction
Salt breaks hydrogen bonds, therefore less soluble and clumps (precipiates easier)
Semi conservative DNA replication
Helicase unwinds DNA double helix and breaks hydrogen bonds between complementary bases, seperating two strands
DNA polymerase adds nucleotides 3’ so it synthesis nucleotides on the template strand 5’ to 3’ direction and synthesis phosphodiester bonds
The 3′ → 5′ template strand is copied continuously to form the leading strand, while the 5′ → 3′ template strand is copied discontinuously as Okazaki fragments on the lagging strand, because DNA polymerase can only synthesise DNA in the 5′ → 3′ direction.
Semi conservative because the knew strand contains half a strand from parent and half added
Accuracy DNA replication
Complementary base pairing (A–T, C–G) and DNA polymerase proofreading ensure DNA is copied accurately.
This high accuracy allows genetic information to be passed on with minimal change, enabling growth, repair, and reproduction.
However, random spontaneous mutations can still occur due to rare copying errors.
These mutations create genetic variation, which can be harmful, neutral (silent due to multiple codons for the same amino acid), or beneficial.
Mutations can change DNA sequence via subsitution, addition, deleteion or matching the wrong bsae so its not complemtary
Genetic code
The genetic code is a triplet code, meaning each amino acid is coded for by three bases (a codon) in DNA.
It is non-overlapping, so each base is read only once in a sequence, in groups of three.
The code is degenerate, meaning most amino acids are coded for by more than one codon.
The code is universal, meaning the same codons code for the same amino acids in almost all organisms.
A gene determines the sequence of amino acids in a polypeptide, and this sequence forms the primary structure of a protein.
Protein synthesis, transcription
Transcription occurs in the nucleus, where RNA polymerase binds to a non-coding region of DNA called the promoter. The DNA double helix unwinds and unzips to expose the template strand.
RNA polymerase binds to the template strand (antisense strand) and moves along it in the 3’ to 5’ direction. As it does so, it synthesises a complementary mRNA strand in the 5’ to 3’ direction by forming phosphodiester bonds between RNA nucleotides.
Once transcription is complete, the mRNA molecule detaches from the DNA and leaves the nucleus through a nuclear pore, entering the cytoplasm for translation
Translation
Translation occurs in the cytoplasm at ribosomes, where the mRNA sequence is used to synthesise a polypeptide (protein).
The ribosome (formed by rRNA) binds to the mRNA and moves along it in the 5’ to 3’ direction. Translation begins at a start codon.
Transfer RNA (tRNA) molecules carry specific amino acids to the ribosome. Each tRNA has an anticodon that is complementary to an mRNA codon (3 bases)
As the ribosome moves along the mRNA, it links amino acids together by forming peptide bonds catalysed by rRNA, creating a growing polypeptide chain.
Translation continues until a stop codon
Aminoacid chain dettaches and folds into specific 3d shape