Kaarten: STAT II: H8: enkelvoudige lineaire regressie | Quizlet
1/74
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
75 Terms
Het enkelvoudig lineair model: kansrekenen
Wat stellen X in Y voor bij enkelvoudige lineaire regressie?
X = de onafhankelijke variabele / de predictor
Y = de afhankelijke variabele
-> we willen Y voorspellen aan de hand van predictor X OF we willen Y verklaren aan de hand van X
dus: Y ~ X (de afhankelijke variabele wordt voorspeld door de predictor)
Het enkelvoudig lineair model: kansrekenen
Hoe moeten we de formule voor de regressielijn opstellen als we rekening willen houden met toeval?
Y = β₀ + β₁X + ε
let op: Griekse letters, want het gaat om een beschrijving van een POPULATIE
Het enkelvoudig lineair model: kansrekenen
Wat representeert ε?
Dit representeert het toeval, het effect van alle variabelen (behalve X) op Y, het effect van meetfouten
= error/fout
Het enkelvoudig lineair model: kansrekenen
Is ε een toevalsvariabele of niet?
Waarmee moeten we opletten!?
JA, het is een toevalsvariabele. Opgelet: wordt aangegeven door een kleine letter.
(toevalsvariabelen worden normaal aangegeven door een grote letter)
Het enkelvoudig lineair model: kansrekenen
Wat betekent het precies dat ε een toevalsvariabele is?
Het betekent dat een bepaalde waarde van X niet altijd zal leiden tot een unieke waarde van Y, omdat de waarde van ε kan variëren.
Het enkelvoudig lineair model: kansrekenen
Hoe herschrijven we de vergelijking van de regressierechten voor individu i?
+ HOE NOEMT MEN DEZE VERGELIJKING? + WAAROM?
Yi = β₀ + β₁xi + εᵢ
= ENKELVOUDIG LINEAIR MODEL
WAAROM:
-> enkelvoudig omdat er maar 1 predictor is.
-> lineair omdat de parameters (β0 en β1 niet in een niet-lineaire vorm voorkomen)
Het enkelvoudig lineair model: kansrekenen
- Wat representeert Y?
- Wat representeert Yi?
- Y representeert de score van een willekeurig individu
- Yᵢ representeert de score van het i'de individu in een steekproef (en die score varieert van steekproef tot steekproef)
Assumpties
Het lineair model bevat enorm veel parameters, wat heeft dus elke fout εᵢ?
- Elke fout εᵢ heeft een eigen verwachting en variantie (dus 2 parameters per individu)
- Elke fout εᵢ kan correleren met εⱼ (dus n(n-1)/2 parameters)
- Er zijn ook nog de twee parameters β₀ en β₁
DUS: in totaal hebben we 2 + 2n + n(n-1)/2 parameters
-> bij een steekproef van 20 individuen zijn er 232 parameters die geschat moeten worden. Zo'n complex model = onbruikbaar (berekeningen moeilijk + geen predictieve waarde)
Wat zijn de drie Gauss-Markov assumpties?
1. E(εᵢ) = 0 voor alle i: de verwachting van de fout hangt niet af van het individu
2. V(εᵢ) = V(εⱼ) voor alle i, j: de variantie van de fout hangt niet af van het individu = homoscedasticiteit
-> er is een constante variantie: σ²ε (underscore)
3. COV(εᵢ, εⱼ) = 0 voor alle i, j: de fout bij individu i is niet gecorreleerd met de fout bij individu j
Hiermee is het aantal parameters fors gereduceerd.
we hebben er nog 3: β0 en β1 en σ²ε
De voorwaardelijke verwachting
= de verwachting bij een deelverzameling van de populatie
= de verwachting van Y onder voorwaarde dat X gelijk is aan 10 (voorbeeld)
-> wordt aangeduid door: E(Y/X=x)
hier: E(Y/X=10)
(vb. de verwachting van de gezondheidsuitgaven definiëren bij alle individuen die 10 maanden werkloos zijn geweest)
Hoe wordt de voorwaardelijke verwachting vaak afgekort indien de context duidelijk is?
E(Yᵢ/Xᵢ)
De voorwaardelijke verwachting
Yᵢ - β₀ - β₁xᵢ = εᵢ
-> wat is dan εᵢ?
εᵢ
= de afwijking tussen de toevalsvariabele Yi en de predictie (foutterm)
= de verticale afwijking tussen een punt en de regressielijn
= het residu van het lineair model bij de score xi
= het equivalent van de residuen in de beschrijvende statistiek
De voorwaardelijke verwachting
Wat betekent σ²ε?
het is de variantie van de populatie-residuen (de residuele variantie)
De voorwaardelijke variantie
- hoe definiëren we deze?
- definiëren als: V(Y/X=x)
- het betekent: de variantie van Y onder voorwaarde dat X gelijk is aan een bepaalde waarde x
- V(Yi/Xi = xi) = σ²ε (het is onafhankelijk van xᵢ)
De correlatiecoëfficient
Wat is het verband tussen het lineair model en de correlatiecoëfficiënt?
β₁ = ρXY . σY/σX
(!!)
deze formule komt overeen met:
b1 = rxy . sy/sx uit de beschrijvende statistiek
Afsluiter: We hebben het lineair model bekeken vanuit een kansrekenen-perspectief. Het heeft betrekking op ... in ... (niet in een ...)
Het heeft betrekking op toevalsvariabelen (i.t.t. geobserveerde variabelen) in populaties (niet in een specifieke steekproef).
Afsluiter: welke 3 parameters bevat het lineair model?
-> zijn deze parameters meestal bekend of onbekend?
- β₀
- β₁
- σ²ε
! deze parameters zijn meestal onbekend
! daarom moeten ze geschat worden obv een steekproef
Puntschatting van β₁
- wat is de beste schatter van β₁? is deze zuiver en efficiënt?
- wat mogen we gebruiken als schatting van β₁?
- de beste schatter van β₁ is gewoon B₁ (de toevalsvariabele die in elke steekproef gelijk is aan b1)
-> B₁ (de schatter) = zuiver en efficiënt.
- we mogen b₁ gebruiken als schatting van β₁ in de populatie
Puntschatting van β1
- schatter van de variantie: steekproefgrootheid in formule (zie formularium)
zie formularium
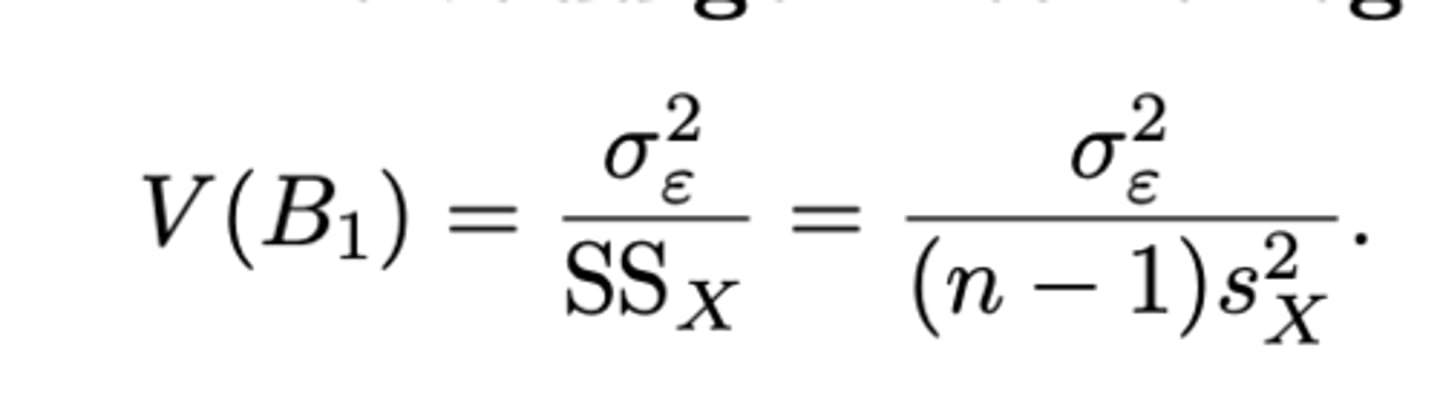
Wat hebben we nodig om goede schattingen van β₁ uit te komen?
een goede schatter: een schatter waarvan de variantie zo klein mogelijk is
- σ²ε moet zo klein mogelijk zijn: ε representeert het toeval, dus we willen het effect van het toeval zo klein mogelijk houden
- n moet zo groot mogelijk zijn: hoe groter de steekproef, hoe beter de schatting
- s²x moet zo groot mogelijk zijn: dit kan door een brede range van X-waarden te kiezen
-> X moet veel spreiding vertonen!
Puntschatting van β1: wat is het probleem van range restriction?
indien s²x te klein is (we hebben een smalle range aan X-waarden) hebben we een te beperkte steekproef (= range restriction)
-> DAARDOOR: zullen de schattingen misschien toevallig goed zijn, MAAR als je meerdere steekproeven trekt met dezelfde beperking dan zullen de schattingen sterk variëren en zullen ze vaak slecht zijn (de standaardfout wordt dus groter)
Puntschatting van β₀
- wat is de beste schatter van β₀? is deze zuiver/efficiënt?
- welke steekproefwaarde mogen we gebruiken als schatting van β0 in de populatie?
- de beste schatter van β₀ is gewoon B₀ (de toevalsvariabele die in elke steekproef gelijk is aan b₀ )
-> zuiver en efficiënt
- we mogen de steekproefwaarde b₀ gebruiken als schatting van β₀ in de populatie
Puntschatting van β₀
- schatter van β₀ in formule (zie ook formularium)
formularium
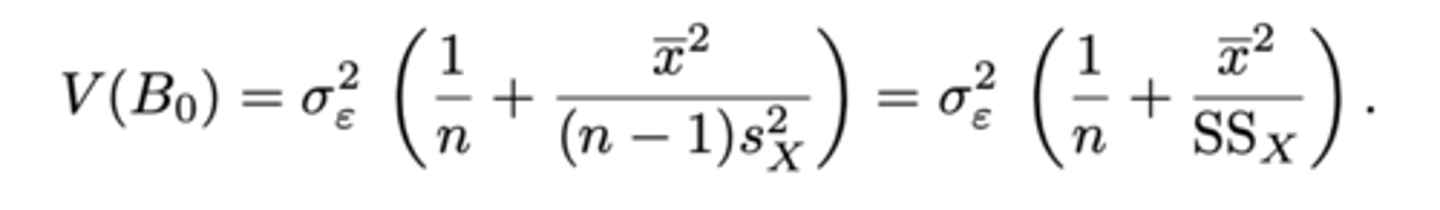
Puntschatting van β₀
Om goede schattingen van β₀ uit te komen, waarvoor moeten we dan zorgen? (3)
- σ²ε zo klein mogelijk
- n zo groot mogelijk
- s²x (de spreiding van X) zo groot mogelijk (indien te klein: restriction of range)
De predicties
- in de praktijk kennen we β₀ en β₁ niet
- om predicties te maken gebruiken we dus ...?
- het resultaat daarvan is niet meer een predictie, maar de ... van een predictie
- hoe moeten we dan onze formule van het lineair model aanpassen? waarvoor moeten we opletten?
- om een predictie te maken gebruiken we dus de schatters B₀ en B₁ ipv parameters
- het resultaat daarvan is de schatter van een predictie (en niet meer een predictie), gedefinieerd door B₀ + B₁xᵢ en aangeduid door symbool Y^ᵢ
- formule lm aanpassen naar: ^Yᵢ = B₀ + B₁xᵢ
(pas op, dit is een slechte notatie want het verwijst nr een schatter maar door het ^ zou je denken dat het een schatting is.
De predicties
Wat zijn de schattingen van de predicties?
In een specifieke steekproef kunnen we de realisaties b₀ en b₁ van de schatters B₀ en B₁ berekenen. We bekomen dan de schattingen van de predicties.
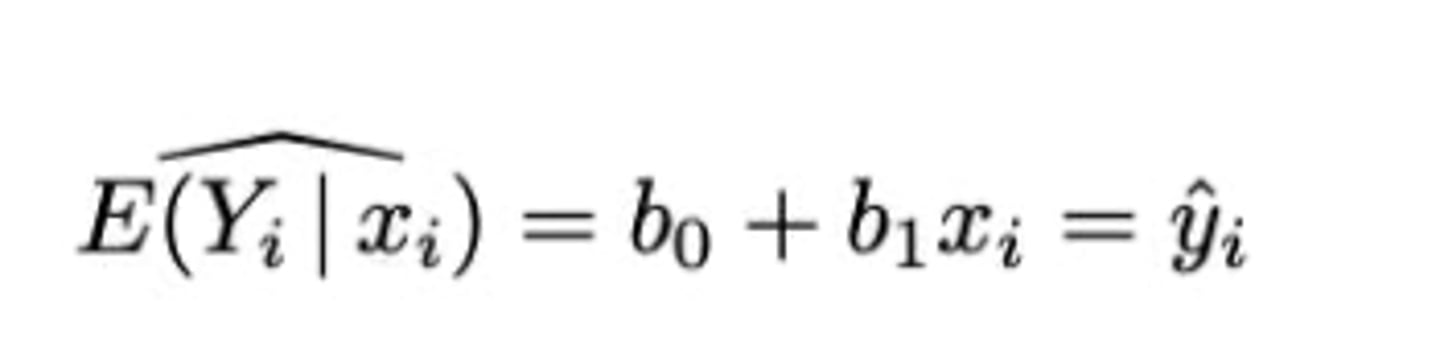
De predicties
Wat is de variantie van de schatter Y^ᵢ? (zie formularium)
+ Waardoor wordt deze variantie beïnvloed? (4)
door:
- σ²ε
- n
- s²x
net zoals V(B₀) en V(B₁)
MAAR ook door: (xᵢ - xˉ)^2
-> hoe dichter xᵢ bij het gemiddelde (x̄ ) ligt, hoe kleiner de variantie en bijgevolg hoe beter de predicties
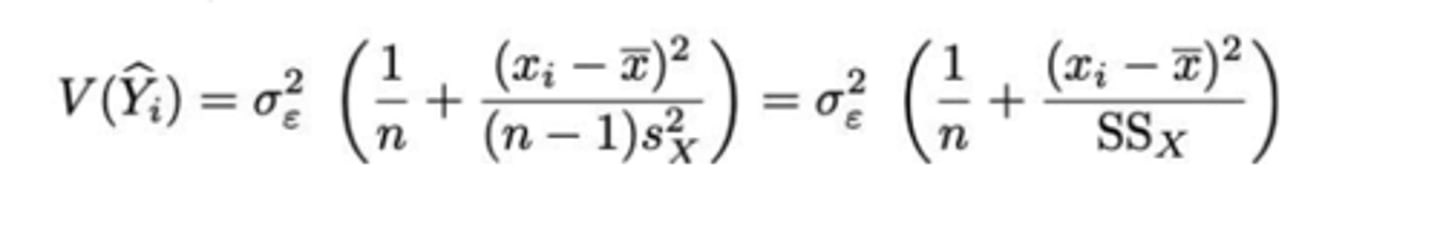
De predicties
- wat is de variantie van deze schatter: Y^ = B₀ + B₁x? (de predictie voor een score die niet in de steekproef voorkomt)
(zie formularium)
Dezelfde als bij een predictie voor een score die wel in de steekproef voorkomt.
-> de predicties voor nog niet geobserveerde waarden zijn dus ook beter als x niet te ver van het gemiddelde ligt
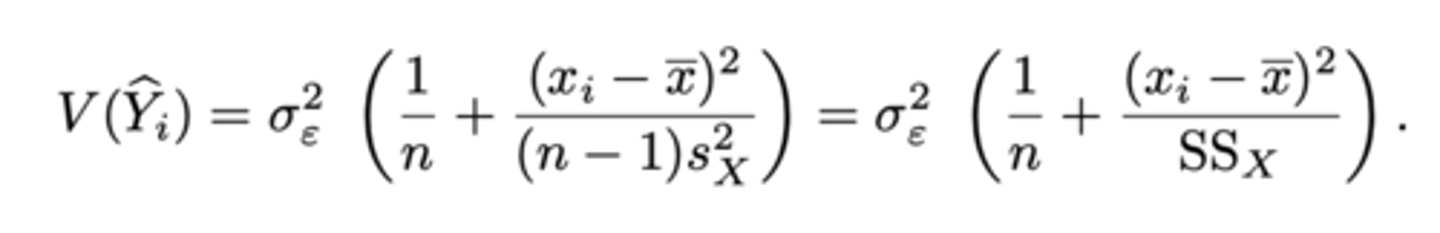
Predicties: punten op de regressierechte. Predicties voor ... punten zijn betrouwbaarder dan voor deze aan ... van de grafiek.
Predicties voor centrale punten zijn betrouwbaarder dan voor deze aan de zijkanten van de grafiek.
Puntschatting van σ²ε (de variantie van de fouten = populatie-residuen)
-> Wat is de beste schatter van σ²ε? Is deze zuiver/efficiënt?
schatter = zuiver en efficiënt
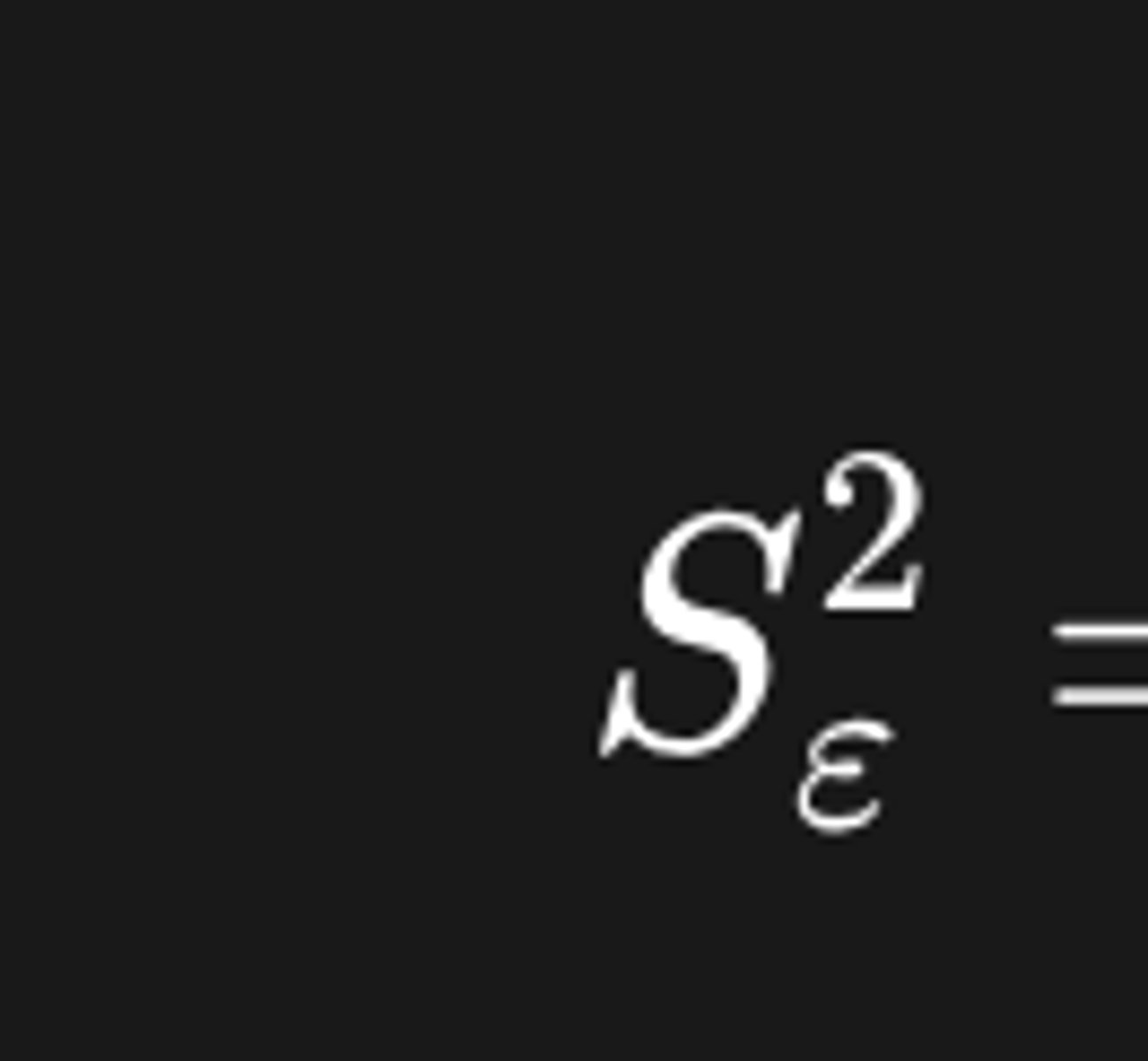
Puntschatting van σ²ε
-> Wat is de schatting van σ²ε? (zie formularium)
zie formularium
s²ε
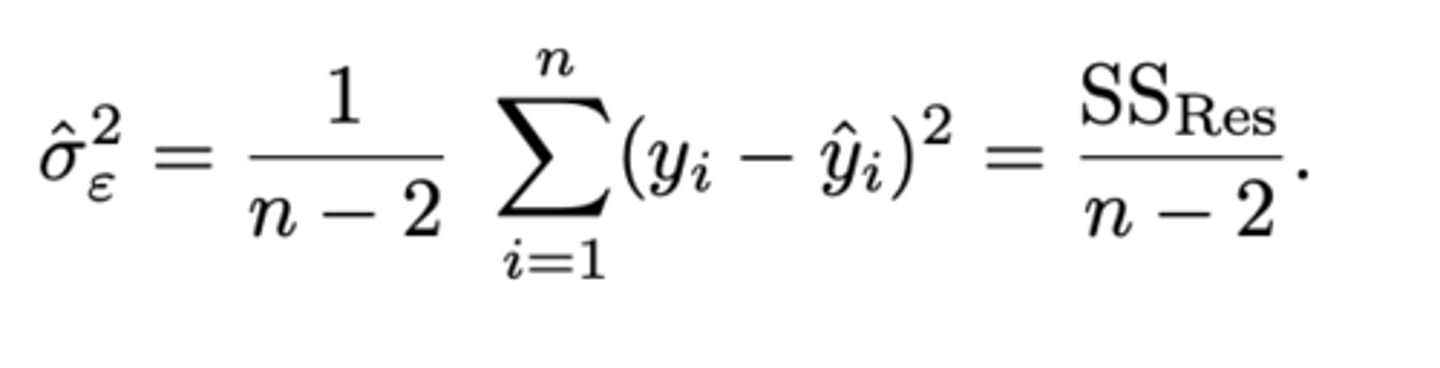
Punschatting van σ²ε
Waarvoor staat SSres?
sum of squares residuals
Vanuit het idee van SSres, wat kan dus een equivalente formule zijn voor de puntschatting van σ²ε?
σ̂²ε = SSres/n-2
(sigma hoedje)
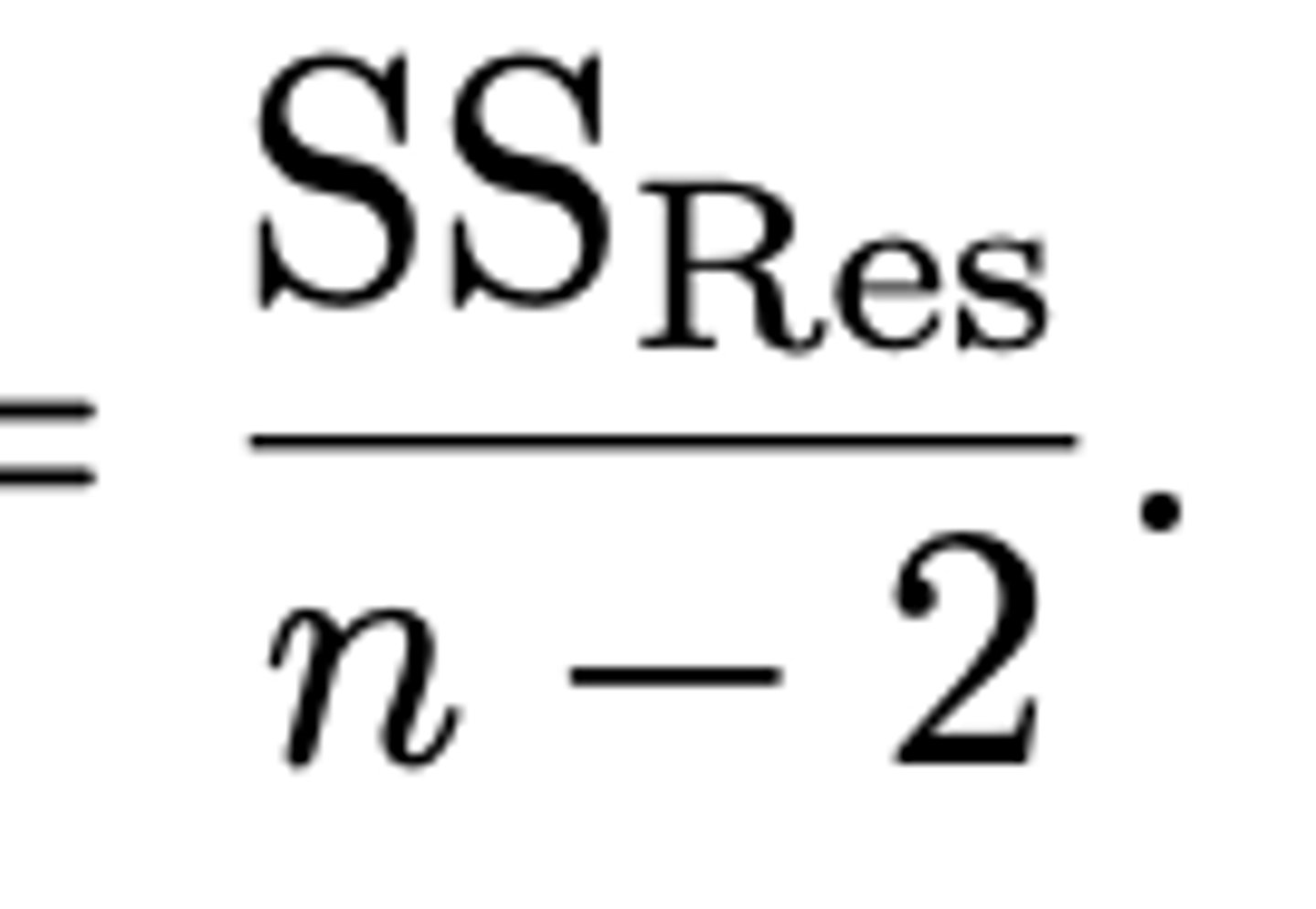
Puntschatting van ρXY
- Wat is de beste schatter van ρXY? Zuiver/efficiënt?
- Wat is de schatting van ρXY?
- de beste schatter = Rxy = zuiver en efficiënt
- de realisatie (schatting) ervan in een steekproef = rxy
Wat is de functie 'fitted' in R?
Wat is de functie 'residuals' in R?
Fitted = predicties ŷᵢ
Residuals = verschil tussen de geobserveerde waarde en de predictie (verticale afwijking tussen een geobserveerde waarde en de voorspelde waarden) yᵢ- ŷᵢ
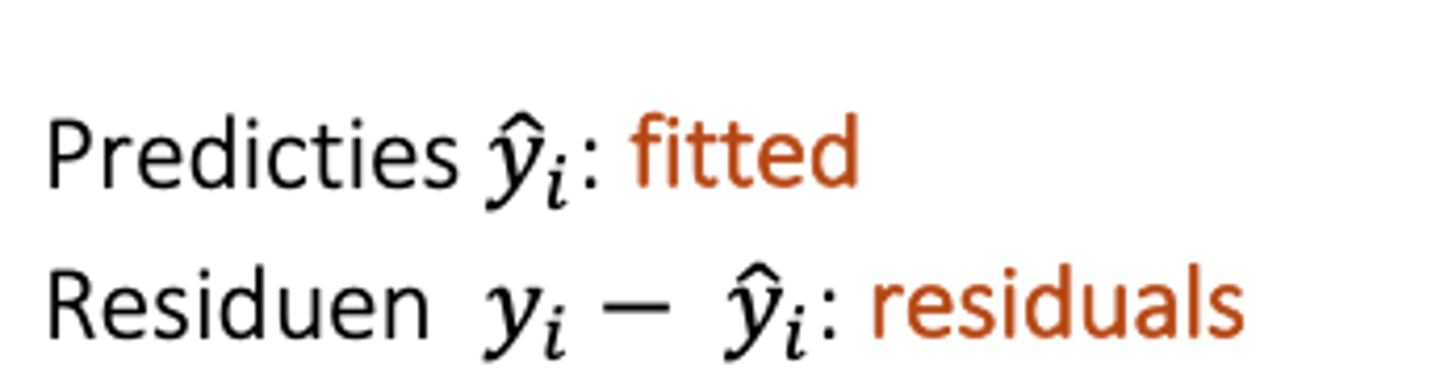
Hoe kunnen we de σ²ε (variantie van de fouten) berekenen in R?
zie formuleblad: σ²ε = SSRes/n-2

Intervalschatting
- wat veronderstellen we, naast de Gauss-Markov assumpties?
dat de fouten normaal verdeeld zijn (geldt niet zomaar vr de variabelen X en Y)
-> leidt tot: εᵢ ~ N (0, σ²ε) voor alle i
Betrouwbaarheidsinterval voor β₁ met betrouwbaarheid 1-α: hoe berekenen? (zie formularium)
zie formularium
Het betrouwbaarheidsinterval zal smal zijn indien V(B₁) klein is.
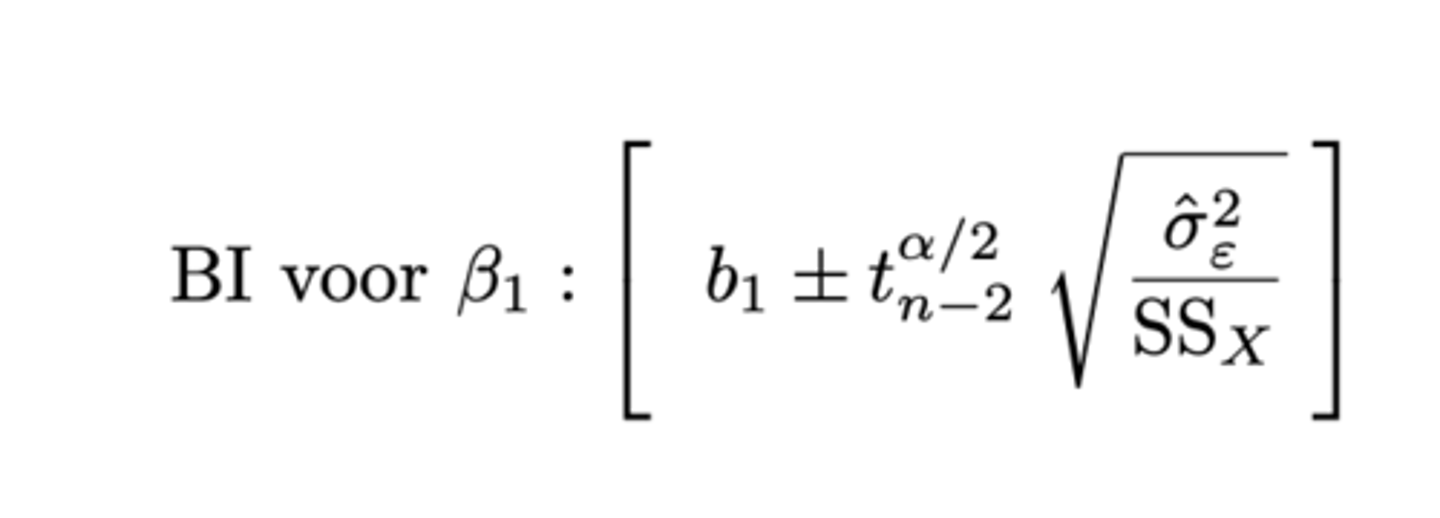
Betrouwbaarheidsinterval voor β₀ met betrouwbaarheid 1-α: hoe berekenen? (zie formularium)
zie formularium
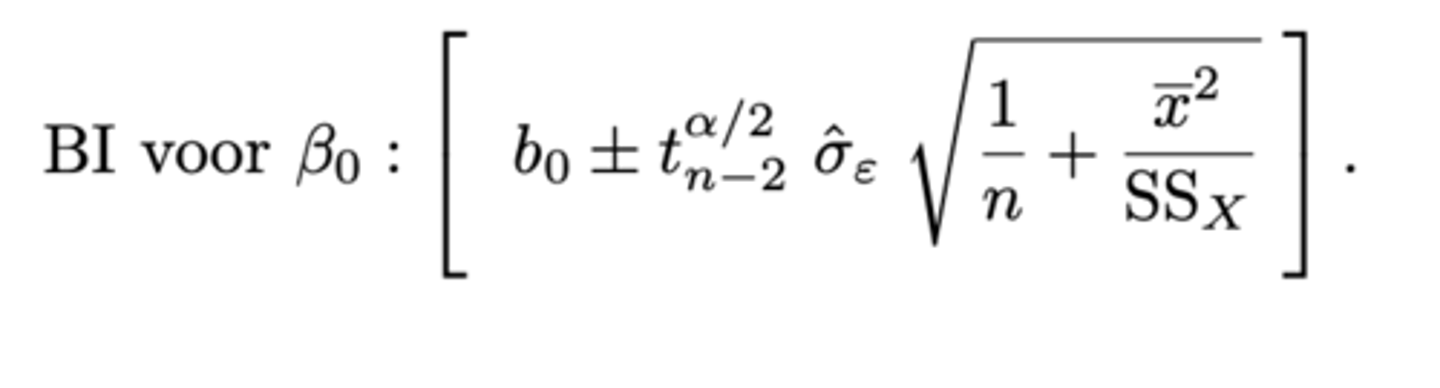
Hoe kunnen we de betrouwbaarheidsintervallen voor β₀ of β₁ berekenen in R?
met de functie: confint
Let op! welk argument gebruikt de functie confint?
level (in de plaats van sig.level of conf.level) = 0.95 (! niet 0.05)
De voorlaatste regel = het betrouwbaarheidsinterval van B0
De laatste regel = het betrouwbaarheidsinterval van B1

Toetsing: waarom zijn deze twee equivalent aan elkaar?
- H0: ρXY = 0
- H0: β₁ = 0
Omwille van het verband tussen ρXY en β₁, uitgedrukt in de volgende formule:
β₁ = ρXY . σY/σX
Merk op: als het linker lid gelijk is aan 0, dan moet het rechterlid dat ook zijn, en omgekeerd. Het toetsen van de ene of de andere maakt dus geen verschil.
VOORWAARDEN voor het toetsen (4)
1. de afhankelijke variabele (Y) moet continu zijn en van interval of ratiomeetniveau zijn
2. De onafhankelijke variabele (X) moet van interval of ratiomeetniveau zijn of moet 0-1 zijn
3. De fouten εᵢ moeten normaal verdeeld zijn (qq-plot) of de steekproef moet groot zijn
4. Er moet voldaan zijn aan de G-M assumpties
Toetsen van het lineair model via de T-verdeling.
-> Aan de hand van welke toetsingsgrootheid wordt H0: β₁ = 0 getoetst? (zie formularium)
zie formularium
Met een T-verdeling met n-2 vrijheidsgraden!!
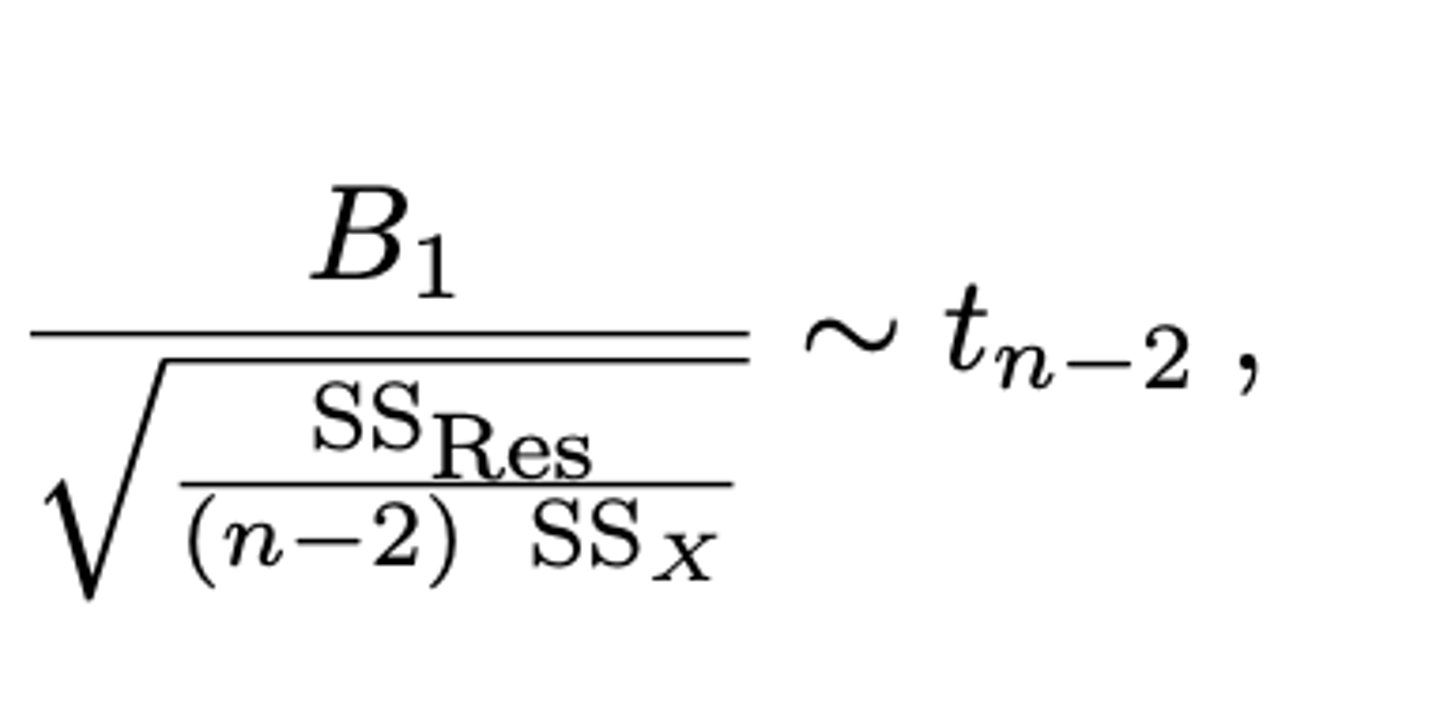
Toetsen van het lineair model via de F-verdeling
Wat is het nulmodel?
- een speciaal geval/beperkte versie van het lineair model
-> deze beperking: β₁ = 0
- het kan ook worden gezien als een lineair model zonder predictor, we zeggen dat het nulmodel genest is in het model met 1 predictor.
Toetsen van het lineair model via de F-verdeling
Hoe wordt het nulmodel weergegeven in symbolen?
Yᵢ = β₀ + εᵢ
Toetsen van het lineair model via de F-verdeling
-> nulmodel: waarvan is de predictie onafhankelijk?
-> waaraan is de fout gelijk?
- van xᵢ, omdat het model veronderstelt dat er geen verband is tussen X en Y
-> dus de predictie is voor alle individuen hetzelfde
- de fout: Yᵢ - β₀ = εᵢ
Wat is formule voor de gekwadrateerde populatie-residuen?
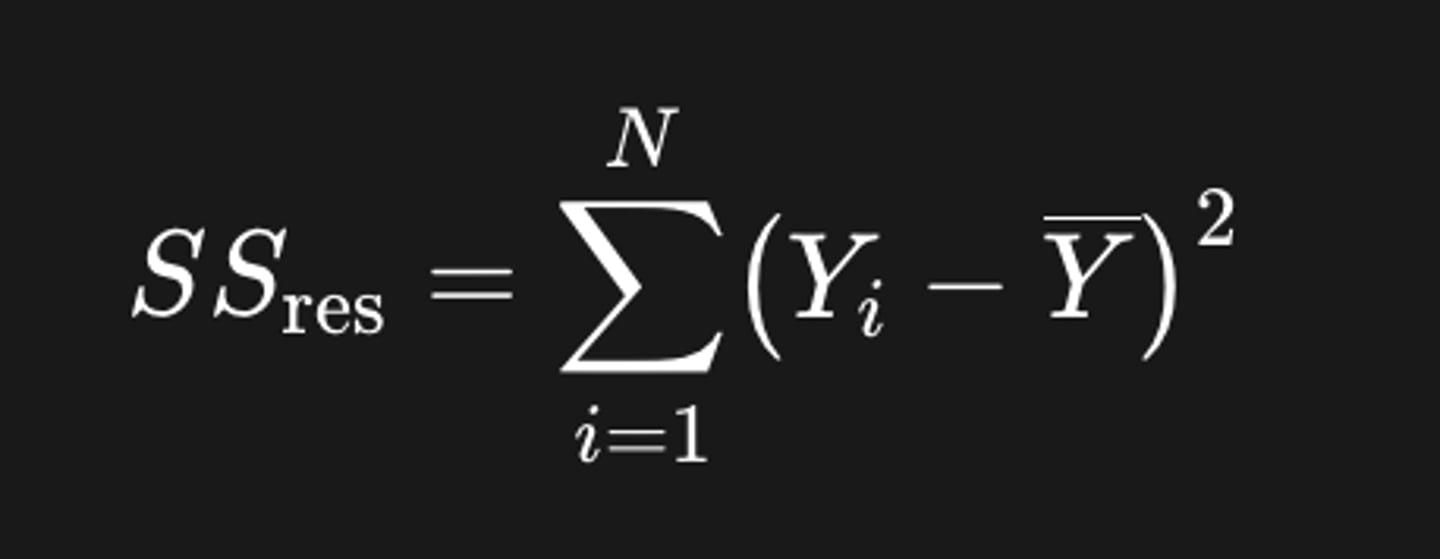
Vergelijking van de modellen:
-> welk model is flexibeler: het nulmodel of het model met één predictor?
Het model met één predictor is flexibeler dan het nulmodel en zal de gegeven ook beter kunnen fitten of passen in de puntenwolk
Want: met een schuine rechte kan je de puntenwolk beter passen dan met een horizontale rechte
Vergelijking van de modellen:
-> voor welk model is de som van de gekwadrateerde residuen kleiner?
-> welke vraag moeten we ons hierbij stellen?
SSres1 zal kleiner zijn voor het model met 1 predictor (want de rechte past beter bij de puntenwolk dus zullen de afwijkingen ook kleiner zijn)
de vraag daarbij: of het een klein beetje kleiner is of veel kleiner?? -> is het verschil groot genoeg om te knn beslissen dat het niet toevallig is?
Vergelijking van de modellen:
Verschil tussen SSres1 en SSres0 analyseren.
-> klein verschil VS groot verschil
- klein verschil: wijst aan dat de residuen van het lineair model met één predictor bijna even groot zijn als de residuen van het nulmodel -> kan dus aan toeval toegeschreven worden
- groot verschil: kan niet aan toeval toegeschreven worden (lineair model geldt dan)
Waarvan is de gekwadrateerde som van de residuen afhankelijk?
van de:
- meeteenheid
- steekproefgrootte
- aantal parameters van de modellen
-> dus het is onmogelijk om het verschil SSres0 en SSres1 rechtstreeks te interpreteren.
-> daarom: invloeden neutraliseren door het berekenen van de verhouding:
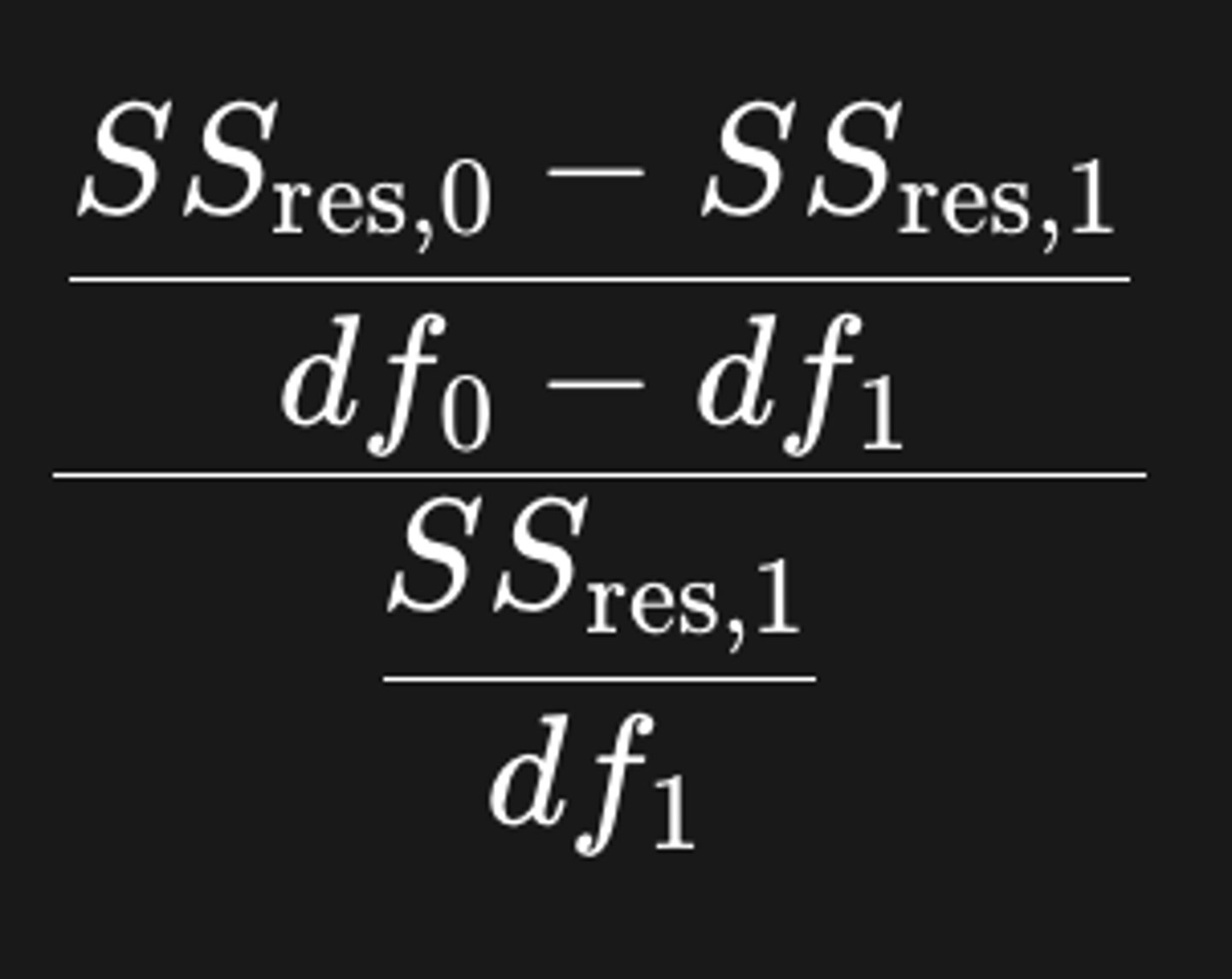
Vergelijking van de modellen:
waarvoor staat: df0 en df1?
- df0: aantal vrijheidsgraden van het nulmodel: n-1
- df1: aantal vrijheidsgraden van het lineair model met één predictor
df0-df1 = n - 1 - (n-2)
= n - 1 - n +2
= 1
Wat doen we met de F-waarde?
je vergelijkt hoe groot de verbetering is van het model met één predictor in vergelijking met het nulmodel (zonder predictor)
of: Om te kunnen beslissen of SSres0 - SSres1 groot genoeg is, moeten we de kans (p-waarde) berekenen dat F toevallig (onder H₀) groter is dan de realisatie van de verhouding in de steekproef
indien F veel groter is dan 0 -> we verwerpen H0: β1 = 0
indien F ongeveer 0 is -> we aanvaarden H0: β1 = 0
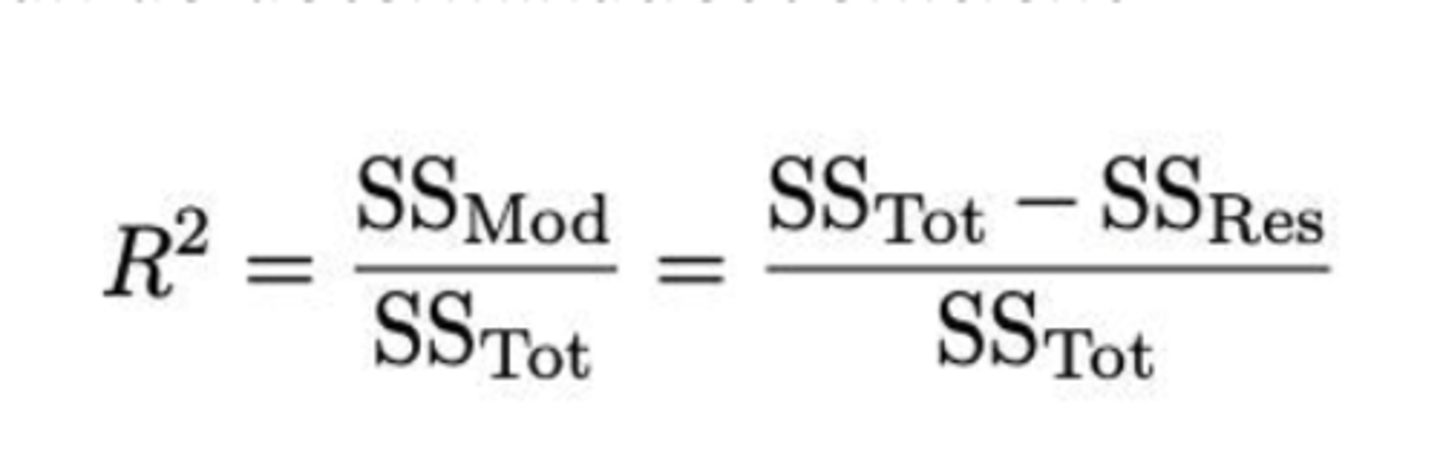
De determinatiecoëfficiënt R²
-> Wat betekent SSY?
-> In welke twee termen kunnen we SSY opsplitsen?
SSY = de totale hoeveelheid variatie die we proberen te verklaren met ons regressiemodel
-> omdat SSy uit 2 delen bestaat, wordt het ook SStot genoemd (total sum of squares)
SSY = SSMod + SSRes
(bestaande uit een deel dat het model verklaart, en een deel dat het model niet verklaart)
De determinatiecoëfficiënt R^2
-> Waarvoor staat SSMod?
SSMod (sum of squares predicted by the model): de som van de afwijkingen die verklaard of voorspeld worden door het lineair model met één predictor.
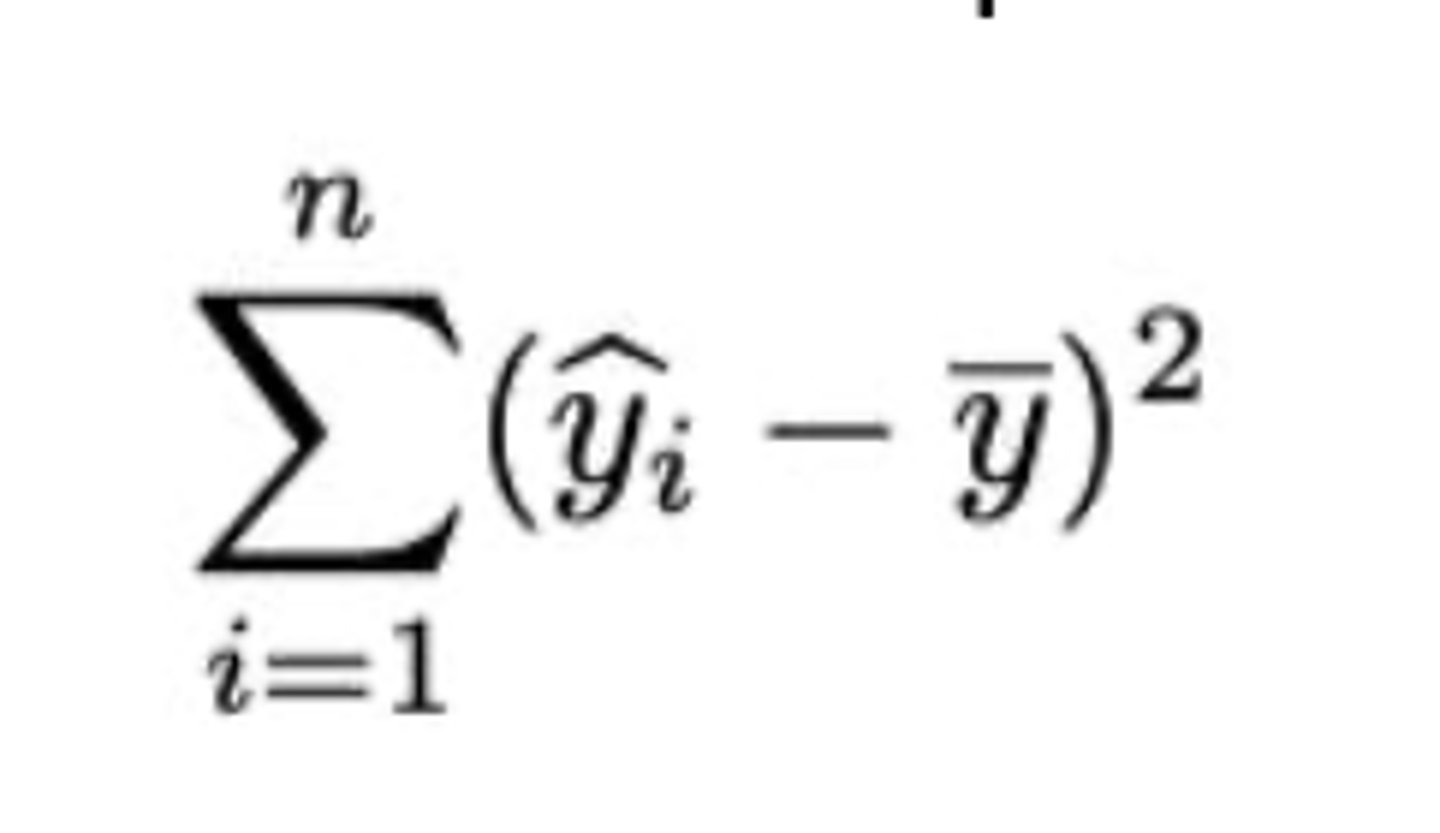
De determinatiecoëfficiënt R^2
-> Waarvoor staat SSRes?
- SSRes (sum of squared residuals): wat het lineair model met één predictor niet verklaart.
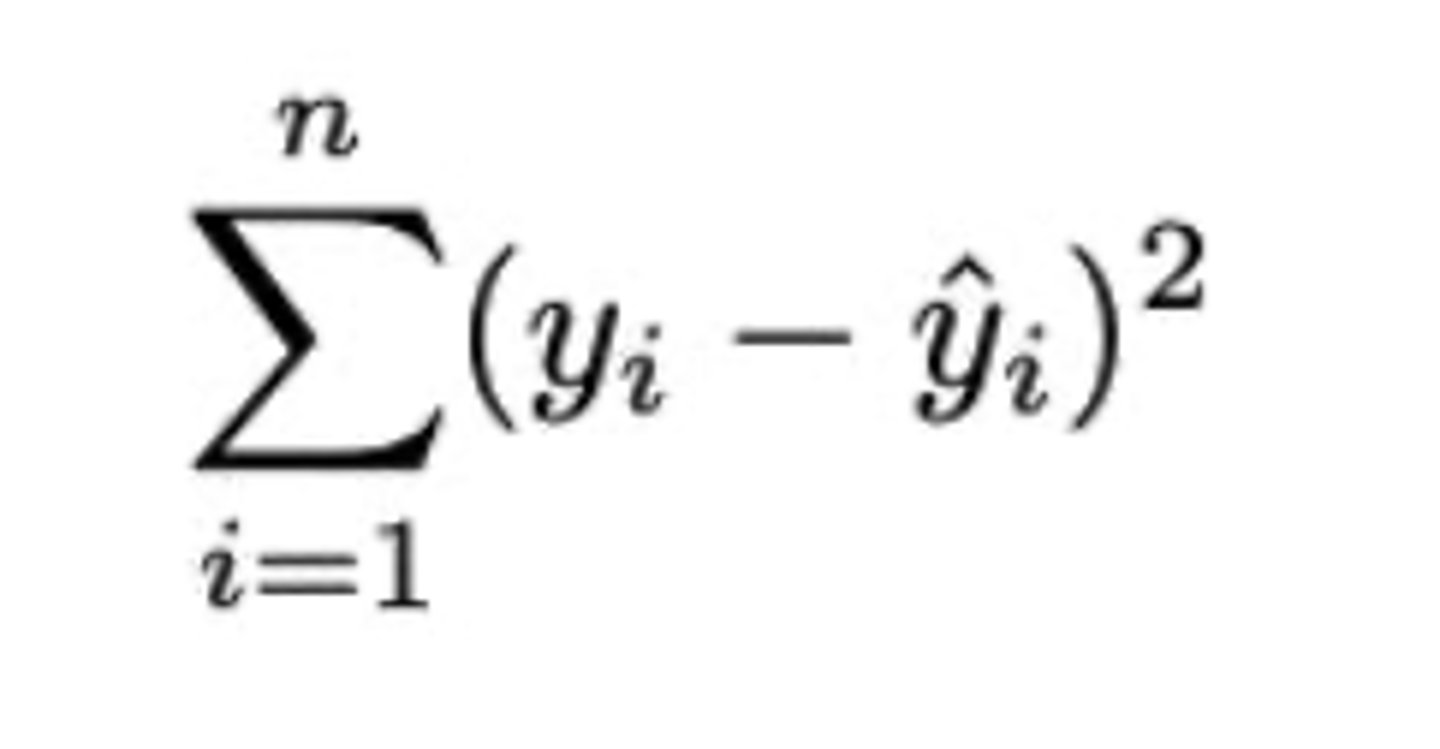
Grafiek SSTot
We kijken naar de afwijkingen tussen yᵢ en ȳ.
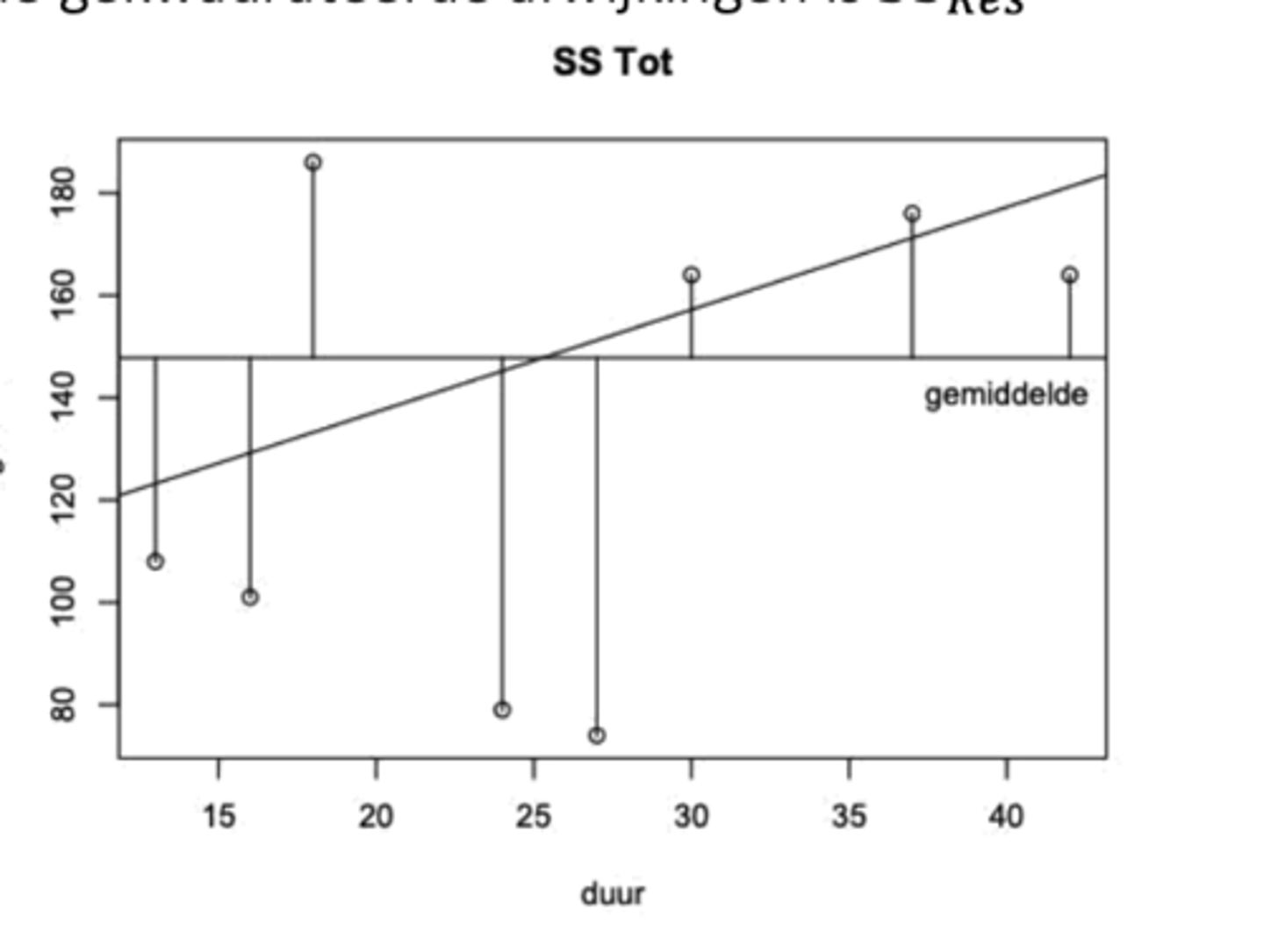
Grafiek SSMod
We kijken naar de afwijkingen tussen ŷᵢ en ȳ.
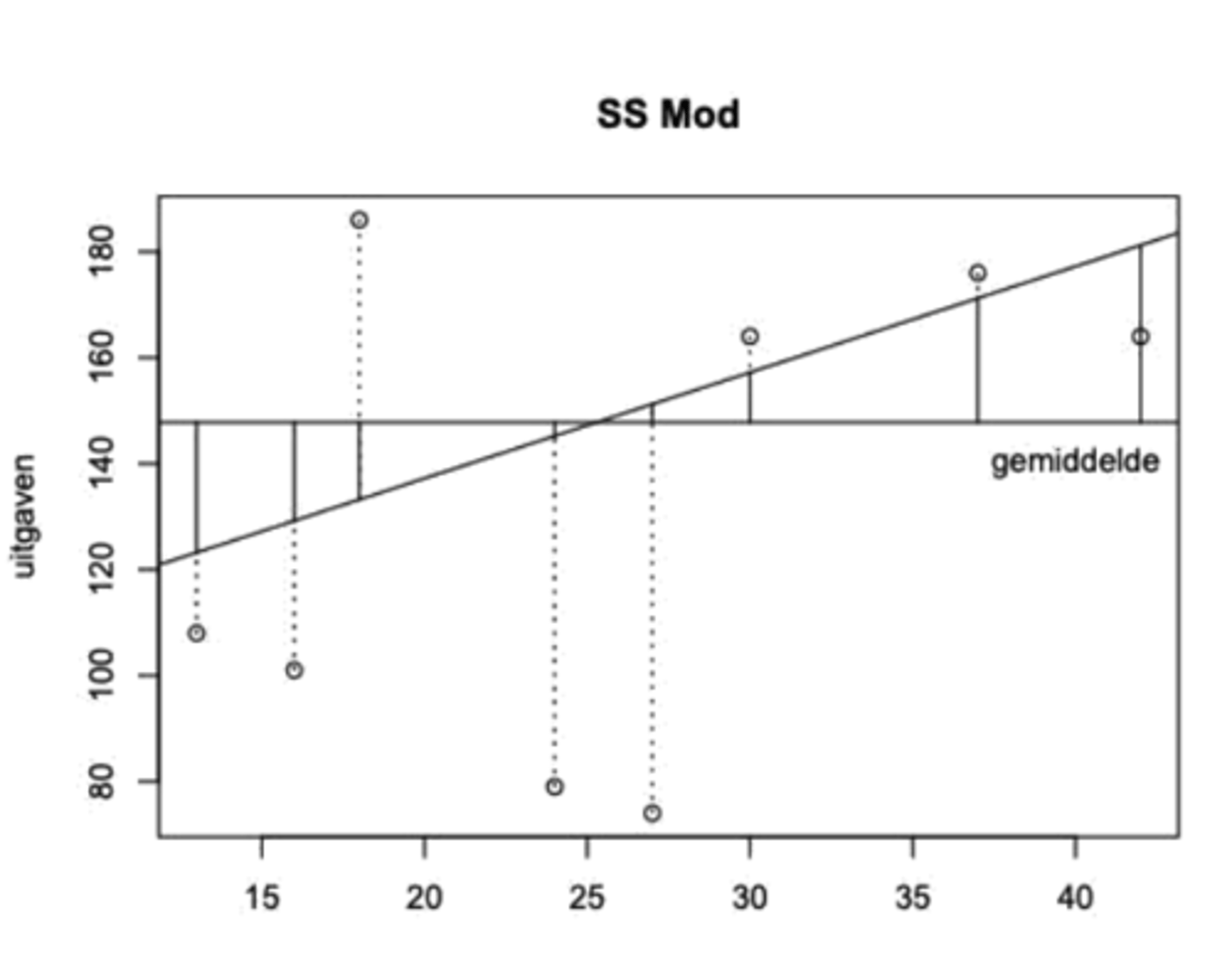
Grafiek SSRes
We kijken naar de afwijkingen tussen yᵢ en ŷᵢ.
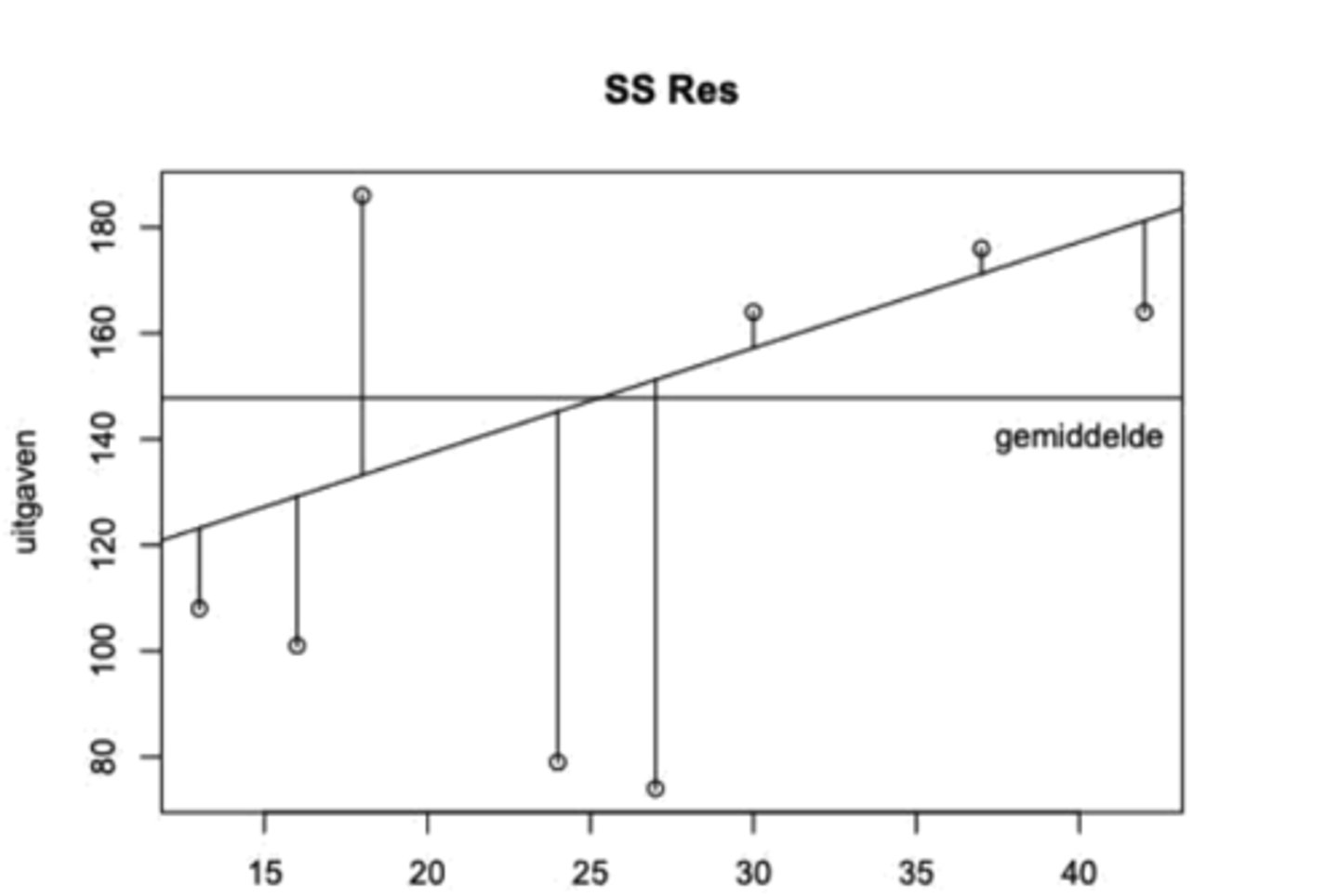
Formule determinatiecoëfficiënt R² (zie eerste helft formule op formularium)
Dezelfde notatie (met hoofdletter) en dezelfde formule wordt gebruikt voor de steekproefgrootheid en voor zijn realisatie in een specifieke steekproef. Er is geen corresponderend symbool voor de populatieparameter.
Eigenschappen van de determinatiecoëfficiënt R² (2)
- altijd positief of 0 (omdat we werken met de som van de kwadraten)
- altijd < of = 1 (omdat SSMod < of = SSTot)
dus 0 ≤ R² ≤ 1
De determinatiecoëfficiënt R²
ENKELE GEVALLEN:
- R² = 1
- R² = 0
- R² ligt tussen 0 en 1
- R² = 1: Bijgevolg: SSMod = SSTot en SSRes = 0
=> alle punten liggen op de regressielijn, dus het verband is perfect
- R² = 0: Bijgevolg: SSMod = 0 en SSRes = SSTot
=> de regressielijn = horizontaal, er is geen lineair verband tussen de variabelen X en Y
- R² ligt tussen 0 en 1: Een deel van SSTot wordt verklaard door het lineair model, maar niet alles.
=> Er is een lineair verband in de steekproef, tussen variabelen X en Y.
Wat is mogelijk om aan te tonen over de determinatiecoëfficiënt R² in het geval van een lineair model met één predictor (enkelvoudige lineaire regressie)
Dat R² = r² (het kwadraad van de correlatiecoëfficiënt r)
ENKEL BIJ ÉÉN PREDICTOR!!
In dit geval bevatten beide coëfficiënten dus exact dezelfde informatie, behalve dat R² geen informatie geeft over het teken van het verband (stijgend of dalend)
De aangepaste determinatiecoëfficënt
De waarde R² is gebaseerd op een steekproef van n observaties. Om een betere schatting van de corresponderende populatie R2 te bekomen maakt men gebruik van de volgende formule die gebaseerd is op een zuivere schatter. (zie formularium)
DE VRAAG: welke formule krijgen we in het geval van een lineair model met 1 predictor?
zie formularium
met p: het aantal predictoren
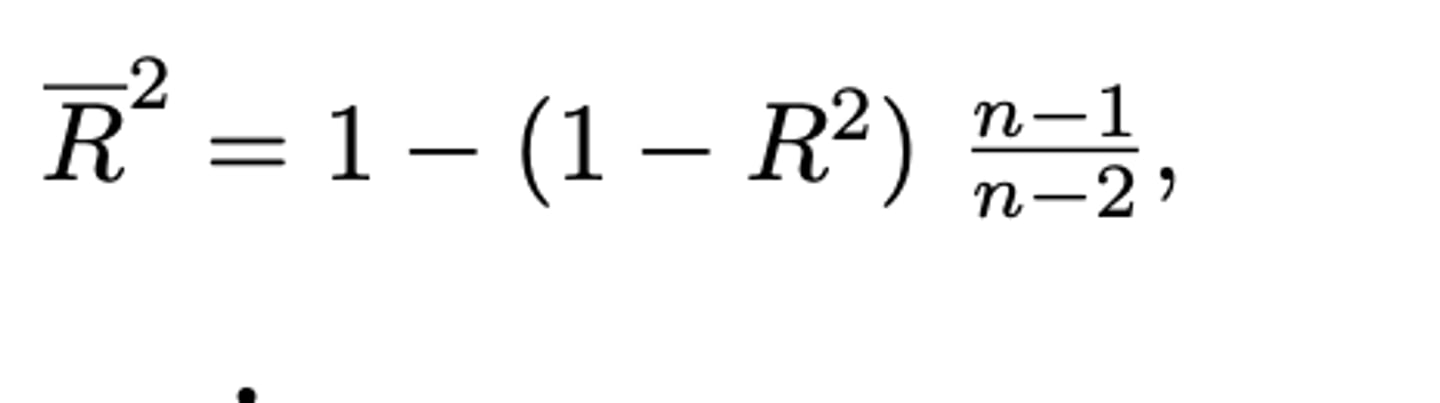
De aangepaste determinatiecoëfficiënt is altijd kleiner/groter/gelijk dan/aan R².
kleiner dan of gelijk aan
De R-functie 'summary': waarvoor staat 'Call'?
de input die je geeft
De R-functie 'summary'
- intercept
- rij onder intercept vb. gezondheid$duur
- estimate
- std.Error
- t-value
- Pr(>∣t∣)
- Multiple R-squared en Adjusted R-squared
- F-statistic
- intercept: geeft informatie omtrent β₀
- gezondheid$duur: info omtrent β₁
- estimate: schatting van de corresponderende parameter
- Std.Error: standaardfout (standaarddeviatie van de corresponderende schatter)
- t-value: waarde van de t-verdeelde statistiek die we gebruiken om de corresp hypothese te toetsen
- Pr(>∣t∣): corresponderende p-waarde
(significante waarden worden aangeduid met een *, waarden rond 0 worden aangeduid met ***)
- Multiple R-squared: de standaard R²
- Adjusted R-squared: de aangepaste R²
- F-statistic: resultaat van de modelselectie (de realisatie f* van de F-toetsingsgrootheid)

De power van de toets van H₀: β₁ = 0
-> hoe kunnen we de power van de toets berekenen?
-> wat is een belangrijk argument bij deze functie?
via de functie pwr.r.test
Als je de power wilt weten=> pwr.r.test( n =…, r =…, sig.level=…)
Als je de grootte van de nodige steekproef wilt weten => pwr.r.test( power = …, r = …, sig.level=…
let op: r = b1 (sx / sy )
dus niet gewoon b1 invullen bij r
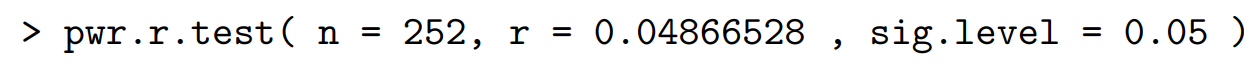
De validiteit van de Gauss-Markov Assumpties
-> wat stelt de 2de/homoscedasticiteitassumptie?
Dat de variantie V(εᵢ) onafhankelijk van xᵢ is
-> = σ²ε (een constante)
-> gevolg: de voorwaardelijke variantie V(Yi/Xi) is ook constant, onafhankelijk van xᵢ
DUS: V(εᵢ) = V(εⱼ) voor alle i, j. m.a.w. de variantie van de fout hangt niet af van het individu. deze constante variantie wordt aangeduid door σ²ε .
Hoe kunnen we de homoscedasticiteitassumptie visueel analyseren?
Door "sneden" van het spreidingsdiagram te bekijken (de sneden corresponderen met 3 x-intervallen)
We zien drie omkaderde sneden op de figuur. Ze corresponderen met drie x-waarden (of eerder drie smalle x-intervallen).
De spreiding van de punten parallel aan de verticale as is ongeveer dezelfde in de 3 sneden -> de drie geobserveerde voorwaardelijke varianties zijn dus ongeveer identiek aan elkaar. Wijst aan dat de drie voorwaardelijke populatievarianties ook gelijk zijn aan elkaar.
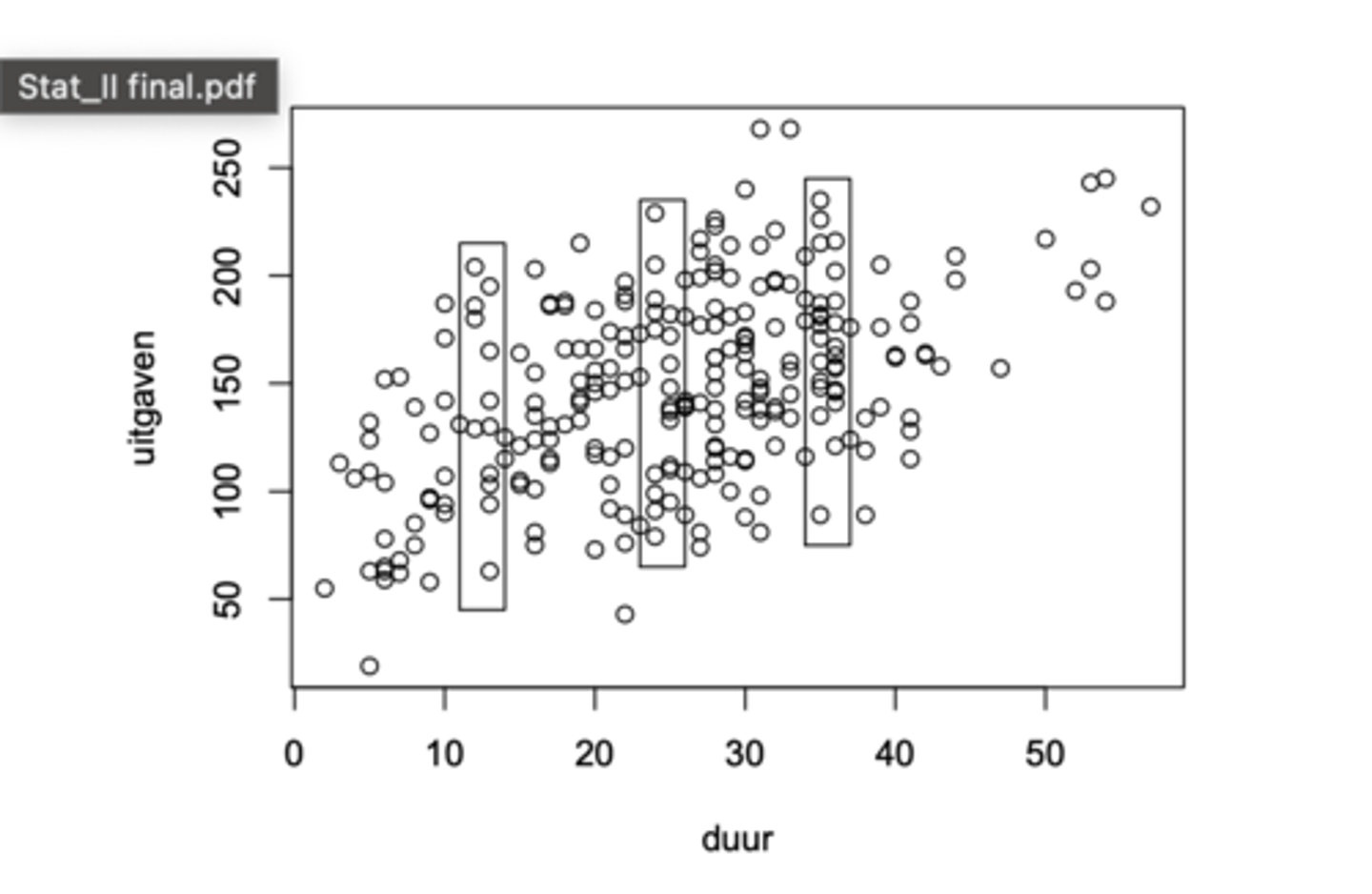
Is er op de afbeelding voldaan aan de homoscedasticiteitassumptie?
Neen, de variantie in de linker sneden is kleiner dan die van de rechter snede.
eenvoudig te verklaren: kinderen hebben meestal ongeveer dezelfde lengte, vanaf de adolescentie worden de verschillen in lengte groter tussen mensen
-> we mogen het lineair model hier dus niet gebruiken om het verband te analyseren (we komen dit probleem vaker tegen wnr afhankelijke variabele van ratio meetniveau is)
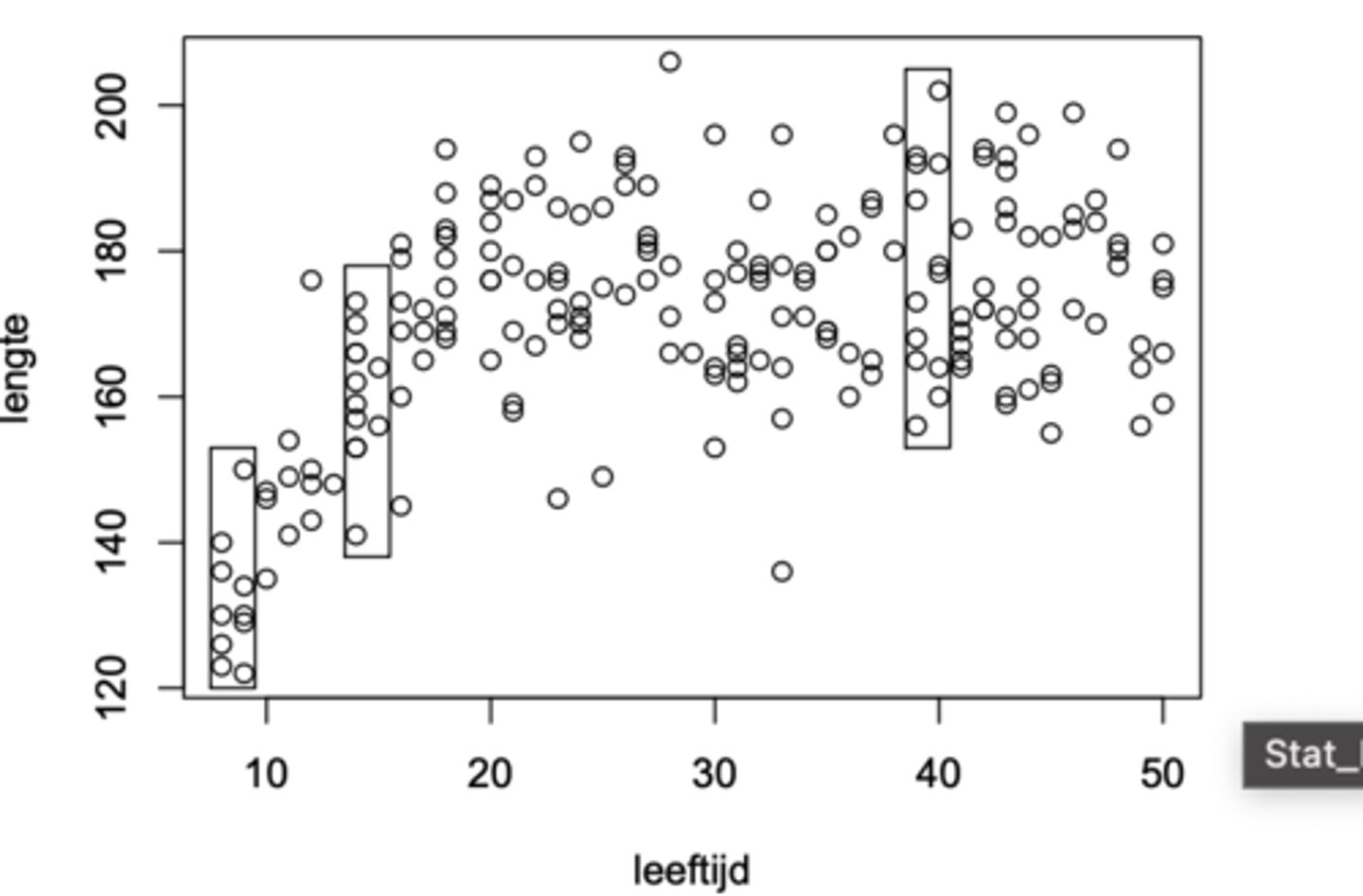
De validiteit van de Gauss-Markov assumpties
-> wat stelt de 1ste GM-assumptie?
dat de verwachting E(εᵢ) = 0, ze is dus onafhankelijk van xᵢ
E(εᵢ) = 0 voor alle i, m.a.w. de verwachting van de fout hangt niet af van het individu
Wat is de belangrijkste oorzaak voor de schending van de eerste GM-assumptie?
non-lineariteit van het verband tussen X en Y.
Is de eerste GM-assumptie geschonden of niet op deze afbeelding? zo ja/nee waarom niet/wel?
Ja, ze is geschonden.
- in de linkersnede liggen alle punten boven regressielijn; alle corresponderende residuen zijn positief
- in de rechtersnede zien we ook dat de verwachtingen groter zijn dan 0
- in de middensnede liggen de punten meer onder de regressielijn, de verwachtingen liggen dus onder 0
-> Deze schending is het gevolg van een niet-lineair verband tussen X en Y. Moest het verband lineair zijn, dan zouden de drie rechthoeken min of meer gecentreerd zijn om de regressielijn en zou E(εi) = 0 zijn voor alle individuen.