Séance 2
1/22
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
23 Terms
Qu’est ce qu’on veut découvrir
how do we move from simple correlations to genuine causal conclusions in empirical corporate finance?
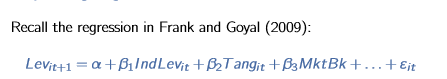
Comment on interprete les coefficients de la regression
vous devez clarifier si cette relation vient d'une variation temporelle (plus convaincante) ou simplement d'une corrélation statique entre entreprises (corrélation brute).
Effets fixes (within-firm) : Compare chaque entreprise à elle-même dans le temps
Variation transversale pure : Compare les différences permanentes entre entreprises
This distinction is crucial — the first hints at causality, the second is pure correlation across firms.

C’est quoi la difference entre econometric et machine learning

Pourquoi la corrélation est importante
En recherche empirique, on ne veut pas juste dire "A est corrélé avec B." On veut pouvoir dire "A cause B", parce que cela permet de :
Tester des théories financières
Faire des expériences contrefactuelles
Mesurer l'impact d'un changement (ex. réforme fiscale)
Formuler des recommandations de politique
La condition clé pour identifier un effet causal dans y = β₀ + β₁x₁ + ... + ε est que le terme d'erreur ε soit non corrélé avec les x (condition d'indépendance conditionnelle, CMI).
In empirical research we want to say "A causes B", not just "A is correlated with B", because causal statements allow us to test theories, run counterfactual experiments, measure the impact of events, and make policy recommendations.
The key technical requirement for identifying a causal effect in y = β₀ + β₁x₁ + ... + ε is that the error term ε must be uncorrelated with the regressors x — this is called the Conditional Mean Independence (CMI) assumption.
Quels sont les 3 causes que le cmi soit violée
Omitted Variable Bias
Measurement error bias
Simultaneity bias
Explique omitted variable bias (OVB)
Le problème le plus courant. Il survient quand le terme d'erreur ε contient une variable omise z qui
(1) affecte y
(2) est corrélée avec x.
Bias formula:
β̂₁ = β₁ + [cov(x,z) / var(x)] × β₂
The estimated coefficient is biased by an amount that depends on how strongly x and z move together, and how much z affects y.
Concrete example: If you regress CEO salary on experience but omit "ability", the experience coefficient is biased upward — because experience and ability are positively correlated, so part of the ability premium gets absorbed into the experience coefficient.
Magnitude du biais
Donnée par la magnitude de β₂ (effet sur y) et de cov(x,z)/var(x) (corrélation entre z et x).
Direction du biais:
Sign of β₂ (z→y) | Sign of cov(x,z) | Bias direction |
|---|---|---|
Positive | Positive | positif |
Positive | Negative | negatif |
Negative | Positive | negatif |
Negative | Negative | positif |
Solutions OVB:
Si la variable omise est observable, on l’ajoute comme contrôle.
Si c’est une forme fonctionnelle (ex: il manque un carré, un terme interaction), on corrige la spécification et on voit si les β changent beaucoup.
Si c’est inobservable, on peut parfois utiliser des proxies pour déterminer les signes des coefficients (variables qui captent partiellement la chose non observée), mais ça rend la CMI plus exigeante.
![<p><span>Le problème le plus courant. Il survient quand le terme d'erreur ε contient une variable omise z qui </span></p><p><span>(1) affecte y </span></p><p><span>(2) est corrélée avec x.</span></p><p class="my-2 [&+p]:mt-4 [&_strong:has(+br)]:inline-block [&_strong:has(+br)]:pb-2"></p><p class="my-2 [&+p]:mt-4 [&_strong:has(+br)]:inline-block [&_strong:has(+br)]:pb-2"><strong>Bias formula:</strong></p><figure data-type="blockquoteFigure"><div><blockquote><p class="font-claude-response-body break-words whitespace-normal leading-[1.7]">β̂₁ = β₁ + [cov(x,z) / var(x)] × β₂</p></blockquote><figcaption></figcaption></div></figure><p class="font-claude-response-body break-words whitespace-normal leading-[1.7]">The estimated coefficient is biased by an amount that depends on how strongly x and z move together, and how much z affects y.</p><p class="font-claude-response-body break-words whitespace-normal leading-[1.7]"><strong>Concrete example:</strong> If you regress CEO salary on experience but omit "ability", the experience coefficient is biased upward — because experience and ability are positively correlated, so part of the ability premium gets absorbed into the experience coefficient.</p><p class="font-claude-response-body break-words whitespace-normal leading-[1.7]"></p><p class="font-claude-response-body break-words whitespace-normal leading-[1.7]"></p><p><strong>Magnitude du biais</strong></p><p>Donnée par la magnitude de β₂ (effet sur y) et de cov(x,z)/var(x) (corrélation entre z et x).</p><p></p><p class="font-claude-response-body break-words whitespace-normal leading-[1.7]"><strong>Direction du biais:</strong></p><table style="min-width: 75px;"><colgroup><col style="min-width: 25px;"><col style="min-width: 25px;"><col style="min-width: 25px;"></colgroup><tbody><tr><th colspan="1" rowspan="1"><p>Sign of β₂ (z→y)</p></th><th colspan="1" rowspan="1"><p>Sign of cov(x,z)</p></th><th colspan="1" rowspan="1"><p>Bias direction</p></th></tr><tr><td colspan="1" rowspan="1"><p>Positive</p></td><td colspan="1" rowspan="1"><p>Positive</p></td><td colspan="1" rowspan="1"><p>positif</p></td></tr><tr><td colspan="1" rowspan="1"><p>Positive</p></td><td colspan="1" rowspan="1"><p>Negative</p></td><td colspan="1" rowspan="1"><p>negatif</p></td></tr><tr><td colspan="1" rowspan="1"><p>Negative</p></td><td colspan="1" rowspan="1"><p>Positive</p></td><td colspan="1" rowspan="1"><p>negatif</p></td></tr><tr><td colspan="1" rowspan="1"><p>Negative</p></td><td colspan="1" rowspan="1"><p>Negative</p></td><td colspan="1" rowspan="1"><p>positif</p></td></tr></tbody></table><p><br>Solutions OVB:</p><ul><li><p class="my-2 [&+p]:mt-4 [&_strong:has(+br)]:inline-block [&_strong:has(+br)]:pb-2">Si la variable omise est <strong>observable</strong>, on l’ajoute comme contrôle.</p></li><li><p class="my-2 [&+p]:mt-4 [&_strong:has(+br)]:inline-block [&_strong:has(+br)]:pb-2">Si c’est une forme fonctionnelle (ex: il manque un carré, un terme interaction), on corrige la spécification et on voit si les <span style="font-family: KaTeX_Main, "Times New Roman", serif; line-height: 1.2; font-size: 1.21em;">β</span> changent beaucoup.</p></li><li><p class="my-2 [&+p]:mt-4 [&_strong:has(+br)]:inline-block [&_strong:has(+br)]:pb-2">Si c’est <strong>inobservable</strong>, on peut parfois utiliser des <strong>proxies pour déterminer les signes des coefficients </strong>(variables qui captent partiellement la chose non observée), mais ça rend la CMI plus exigeante.</p></li></ul><p></p>](https://assets.knowt.com/user-attachments/3651c53c-76c9-4b71-8f0d-acb0993fc8a7.png)
Explique measurement bias
On mesure mal une variable:
Exemple: rating de défaut, taux de taxe marginal, Tobin’s Q, value des options dans la compensation du CEO
Exemple classique en corporate finance:
Fazzari, Hubbard & Petersen (1988) régressent l’investissement sur Q (opportunités d’investissement) et cash.
Q est mal mesuré; du coup, le coefficient sur cash peut être totalement biaisé.
Erickson & Whited (2000) montrent que corriger la ME fait disparaître l’effet de cash.
En vérité, ME est correlé avec les deux x observé et non observé x
![<p>On mesure mal une variable:</p><ul><li><p class="my-2 [&+p]:mt-4 [&_strong:has(+br)]:inline-block [&_strong:has(+br)]:pb-2">Exemple: rating de défaut, taux de taxe marginal, Tobin’s Q, value des options dans la compensation du CEO</p></li></ul><p>Exemple classique en corporate finance:</p><ul><li><p class="my-2 [&+p]:mt-4 [&_strong:has(+br)]:inline-block [&_strong:has(+br)]:pb-2">Fazzari, Hubbard & Petersen (1988) régressent l’investissement sur Q (opportunités d’investissement) et cash.</p></li><li><p class="my-2 [&+p]:mt-4 [&_strong:has(+br)]:inline-block [&_strong:has(+br)]:pb-2">Q est mal mesuré; du coup, le coefficient sur cash peut être totalement biaisé.</p></li><li><p class="my-2 [&+p]:mt-4 [&_strong:has(+br)]:inline-block [&_strong:has(+br)]:pb-2">Erickson & Whited (2000) montrent que corriger la ME fait disparaître l’effet de cash.</p></li></ul><p></p><p>En vérité, ME est correlé avec les deux x observé et non observé x</p>](https://assets.knowt.com/user-attachments/3142e1b1-1803-4ef0-a5ce-6f551e88b09b.png)
Measurement error vs proxies

Explique simultaneity bias

comment on traite l’endogène? OVB (Heterogéneité non observé)
Avec Le panel data permet de contrôler l'hétérogénéité non observée invariante dans le temps — c'est-à-dire toute variable omise qui ne change pas dans le temps pour une firme (ou CEO, ou pays) donnée.
Définition
Données de panel = plusieurs observations par unité i (ex : 5 000 firmes observées sur 20 ans). N = dimension cross-sectionnelle, T = dimension temporelle. Si chaque unité est observée T fois : panel balancé.
Plus précisément
Avec fixe effects pour enlever les valeurs fixes qui ne sont pas dans l’erreur (e)
Avec des données de panel, tu peux éliminer l’effet de facteurs cachés qui ne changent pas dans le temps.
Intuition:
Au lieu de comparer :
firme A vs firme B (problème : elles sont différentes)
👉 tu compares :
la même firme dans le temps
Donc :
tout ce qui est constant (culture, talent, etc.)
👉 disparaît automatiquement
C'est exactement ce que font les effets fixes.à
![<p>Avec <strong>Le panel data</strong> permet de contrôler l'hétérogénéité non observée <em>invariante dans le temps</em> — c'est-à-dire toute variable omise qui ne change pas dans le temps pour une firme (ou CEO, ou pays) donnée. </p><p><strong>Définition</strong></p><p><strong>Données de panel</strong> = plusieurs observations par unité i (ex : 5 000 firmes observées sur 20 ans). N = dimension cross-sectionnelle, T = dimension temporelle. Si chaque unité est observée T fois : panel <em>balancé</em>.</p><p></p><p>Plus précisément</p><p>Avec fixe effects pour enlever les valeurs fixes qui ne sont pas dans l’erreur (e)</p><p></p><p><strong>Avec des données de panel, tu peux éliminer l’effet de facteurs cachés qui ne changent pas dans le temps.</strong></p><p></p><p><strong>Intuition:</strong></p><p>Au lieu de comparer :</p><ul><li><p>firme A vs firme B (problème : elles sont différentes)</p></li></ul><p><span data-name="point_right" data-type="emoji">👉</span> tu compares :</p><ul><li><p><strong>la même firme dans le temps</strong></p></li></ul><p>Donc :</p><ul><li><p>tout ce qui est <strong>constant</strong> (culture, talent, etc.)<br><span data-name="point_right" data-type="emoji">👉</span> disparaît automatiquement</p></li></ul><p></p><p class="font-claude-response-body break-words whitespace-normal leading-[1.7]">C'est exactement ce que font les effets fixes.à</p><p></p>](https://assets.knowt.com/user-attachments/34e9de12-1015-454f-bde9-1347a85ceb5b.png)
Explique le Fixed-effects
LS sur les données transformées → β consistant
Avec l'hypothèse d'exogénéité stricte, (xᵢₜ - x̄ᵢ) est non corrélé avec (εᵢₜ - ε̄ᵢ). L'estimateur FE est consistant.
Exogénéité stricte
Le FE requiert corr(xᵢₜ, εᵢₛ) = 0 ∀s,t — les erreurs passées, présentes et futures sont non corrélées avec x. C'est plus fort que la condition habituelle ! En particulier, si xit est affecté par les y passés, cette hypothèse est violée.

Avantages et inconvénients Fixed-effects
4.5 — Limitations of fixed effects
Time-invariant regressors cannot be estimated. If x doesn't vary over time within a firm (e.g. a CEO's gender), its coefficient is absorbed by the firm FE and cannot be separately identified. Statistical packages will often silently drop collinear variables — watch out for this.
Measurement error bias is amplified. The within transformation dramatically reduces the signal in x (you're left with only its time variation). If x is measured with noise, the ratio of noise to signal rises sharply, worsening attenuation bias.
Computational cost with multiple FEs. When combining firm and industry×year fixed effects on a dataset like Compustat, memory requirements can reach ~40GB. Specialised packages (e.g.
fixestin R,reghdfein Stata) use algorithms that handle this efficiently.

Quelle est l’autre alternative que FE?

LSDV vs FE
L'analogie
C'est comme vouloir peser uniquement tes vêtements :
LSDV : tu te pèses avec les vêtements, tu te pèses sans, tu soustrais. Tu mesures explicitement ton poids nu (fif_i fi).
Within : tu portes les mêmes vêtements tous les jours et tu regardes uniquement les variations quotidiennes. Ton poids nu s'annule dans la comparaison sans jamais être mesuré.
Même résultat. Méthode différente.
Différence pratique:
FE (within estimator)
R² "within" = proportion de la variation intra-groupe de y expliquée par x. Généralement plus bas.
LSDV
R² plus élevé (car les dummies "expliquent" une grande partie de la variation). Mêmes estimateurs β et erreurs standard. L'interprétation de la constante est délicate.
Quels sont les types d’erreurs standards
homoskedastic, robust, cluster
Homoskedastic vs robust
Ce que ça change concrètement
SE classiques
SE robustes (Huber-White)
Suppose
V(ε∥x)= constant (homoscédasticité)
V(ε∥x)= σ2i peut varier librement (hétéroscédasticité)
Si hypothèse vraie
Optimales (plus petites possibles)
Légèrement moins efficaces
Si hypothèse fausse
Biaisées — souvent trop petites
Valides asymptotiquement
t-stats si fausses
Trop grandes → faux positifs
Correctes en grand échantillon
2. Ce que ça change concrètement ✅ Si l’hypothèse est vraie (pas d’hétéroscédasticité)
SE classiques :
👉 optimales (les plus précises)SE robustes :
👉 un peu moins efficaces (un peu plus grandes)
🔵 SE classiques
👉 Donc elles estiment UNE seule chose :
une variance moyenne
➡ simple → stable même avec peu de données
🟢 SE robustes
Elles supposent :
👉 Donc elles doivent estimer :
une variance différente pour chaque observation
➡ beaucoup plus d’information à estimer
❌ Si l’hypothèse est fausse (hétéroscédasticité)
SE classiques :
👉 ❌ biaisées (souvent trop petites)SE robustes :
👉 ✅ correctes asymptotiquement
🚨 Conséquence sur les t-stats
Rappel :
t=β/SE
👉 Si SE trop petites :
t-stat trop grande
p-value trop petite
➡ faux positifs (tu crois qu’il y a un effet alors qu’il n’y en a pas)
🧠 Intuition simple
SE classiques sous-estiment le risque → tu es trop confiant
⚠ 3. Le piège des petits échantillons
C’est là que ça devient subtil 👇
🧠 En grand échantillon
👉 SE robustes :
convergent vers la vraie valeur
donc fiables ✅
😬 En petit échantillon 🔴 SE classiques
toujours biaisées si hétéroscédasticité
souvent trop petites
🟠 SE robustes
👉 problème plus subtil :
elles doivent estimer une structure complexe
mais avec peu de données → estimation instable
➡ elles peuvent :
être trop grandes
ou trop petites
🚨 Le point contre-intuitif
👉 Les SE robustes peuvent être plus petites que les SE classiques
⚠ MAIS :
ce n’est pas parce que l’incertitude est plus faible
c’est parce qu’elles sont mal estimées
🧠 Intuition
Tu essaies de mesurer quelque chose de compliqué avec peu d’info → résultat bruité
Pourquoi la dépendance dans les erreurs pose problème ?
Les SE classiques et robustes supposent l'indépendance des observations. Or en finance, les erreurs sont souvent corrélées :
En corporate finance, ce n’est pas réaliste:
Corrélation cross-sectionnelle
Le ROA de la firme A et celui de la firme B dans la même industrie sont corrélés (même choc de demande). Les observations ne sont pas des tirages indépendants.
Corrélation temporelle (sérielle)
La taille d'une firme en t est corrélée avec sa taille en t+1. Les erreurs εᵢₜ et εᵢₜ₋₁ sont corrélées — violation de l'indépendance.
Pourquoi les SE sont-elles trop basses ?
Si on double le nombre d'observations en répliquant les données existantes, les SE classiques diminuent (de moitié !) même si on n'a aucune information supplémentaire. Le logiciel ne réalise pas que les observations ne sont pas indépendantes. Le biais de la corrélation en séries temporelles peut facilement doubler ou tripler les SE !
![<p>Les SE classiques et robustes supposent l'indépendance des observations. Or en finance, les erreurs sont souvent corrélées :</p><p class="my-2 [&+p]:mt-4 [&_strong:has(+br)]:inline-block [&_strong:has(+br)]:pb-2">En corporate finance, ce n’est pas réaliste:</p><p class="font-claude-response-body break-words whitespace-normal leading-[1.7]"><strong>Corrélation cross-sectionnelle</strong></p><p>Le ROA de la firme A et celui de la firme B dans la même industrie sont corrélés (même choc de demande). Les observations ne sont pas des tirages indépendants.</p><p><strong>Corrélation temporelle (sérielle)</strong></p><p>La taille d'une firme en t est corrélée avec sa taille en t+1. Les erreurs εᵢₜ et εᵢₜ₋₁ sont corrélées — violation de l'indépendance.</p><p></p><p><strong>Pourquoi les SE sont-elles trop basses ?</strong></p><p>Si on double le nombre d'observations en répliquant les données existantes, les SE classiques diminuent (de moitié !) même si on n'a aucune information supplémentaire. Le logiciel ne réalise pas que les observations ne sont pas indépendantes. Le biais de la corrélation en séries temporelles peut facilement doubler ou tripler les SE !</p>](https://assets.knowt.com/user-attachments/73263f0c-a30d-4003-9ef2-30432e1efeed.png)
C’est quoi la solution:
La solution : choisir le bon niveau de clustering
Clustering → Corrige les erreurs standard (inférences)
Même avec FE firme, εᵢₜ peut être corrélé avec εᵢₜ₋₁ (autocorrélation résiduelle). Le FE firme supprime fᵢ mais pas cette corrélation sérielle → cluster firme pour SE correctes.
L'idée centrale du clustering est simple :
On autorise les erreurs à être corrélées à l'intérieur d'un groupe, mais on suppose qu'elles sont indépendantes entre groupes.
Le groupe, c'est le cluster. Entre clusters, tu as de vraies informations indépendantes. À l'intérieur d'un cluster, tu as des observations redondantes.
Comment choisir le niveau de clustering
Le principe est : cluster au niveau le plus agrégé où ta variable clé varie.
Contexte | Niveau de cluster recommandé | Raisonnement |
|---|---|---|
Régression cross-sectionnelle firmes-industries | Industrie | Une variable varie au niveau industrie → cluster à ce niveau |
Panel firmes-années (variable industrie-année) | Industrie (pas industrie-année !) | Les chocs sectoriels persistent dans le temps → cluster industrie permet la corrélation temporelle |
Panel firmes-années (variable firme-année) | Firme | La taille, levier etc. ont une forte autocorrélation → cluster firme |
Variable variant au niveau état/pays | État / pays | Cluster au niveau le plus agrégé de variation du régresseur clé |
même industrie bougent ensemble.
![<p>La solution : choisir le bon niveau de clustering</p><p></p><p><strong><br>Clustering → Corrige les erreurs standard (inférences)</strong></p><p>Même avec FE firme, εᵢₜ peut être corrélé avec εᵢₜ₋₁ (autocorrélation résiduelle). Le FE firme supprime fᵢ mais pas cette corrélation sérielle → cluster firme pour SE correctes.</p><p><br></p><p class="font-claude-response-body break-words whitespace-normal leading-[1.7]">L'idée centrale du clustering est simple :</p><p></p><figure data-type="blockquoteFigure"><div><blockquote><p class="font-claude-response-body break-words whitespace-normal leading-[1.7]">On autorise les erreurs à être corrélées <strong>à l'intérieur</strong> d'un groupe, mais on suppose qu'elles sont indépendantes <strong>entre</strong> groupes.</p></blockquote><figcaption></figcaption></div></figure><p></p><p class="font-claude-response-body break-words whitespace-normal leading-[1.7]">Le groupe, c'est le <strong>cluster</strong>. Entre clusters, tu as de vraies informations indépendantes. À l'intérieur d'un cluster, tu as des observations redondantes.</p><p></p><div data-type="horizontalRule"><hr></div><p>Comment choisir le niveau de clustering</p><p class="font-claude-response-body break-words whitespace-normal leading-[1.7]">Le principe est : <strong>cluster au niveau le plus agrégé où ta variable clé varie</strong>.</p><p></p><table style="min-width: 75px;"><colgroup><col style="min-width: 25px;"><col style="min-width: 25px;"><col style="min-width: 25px;"></colgroup><tbody><tr><th colspan="1" rowspan="1" style="box-sizing: border-box; margin: 0px; padding: 6px 10px; font-weight: 500; text-align: left; border-bottom: 0.909091px solid rgba(31, 30, 29, 0.15);"><p><strong>Contexte</strong></p></th><th colspan="1" rowspan="1" style="box-sizing: border-box; margin: 0px; padding: 6px 10px; font-weight: 500; text-align: left; border-bottom: 0.909091px solid rgba(31, 30, 29, 0.15);"><p><strong>Niveau de cluster recommandé</strong></p></th><th colspan="1" rowspan="1" style="box-sizing: border-box; margin: 0px; padding: 6px 10px; font-weight: 500; text-align: left; border-bottom: 0.909091px solid rgba(31, 30, 29, 0.15);"><p><strong>Raisonnement</strong></p></th></tr><tr><td colspan="1" rowspan="1" style="box-sizing: border-box; margin: 0px; padding: 6px 10px; border-bottom: 0.909091px solid rgba(31, 30, 29, 0.15);"><p>Régression cross-sectionnelle firmes-industries</p></td><td colspan="1" rowspan="1" style="box-sizing: border-box; margin: 0px; padding: 6px 10px; border-bottom: 0.909091px solid rgba(31, 30, 29, 0.15);"><p>Industrie</p></td><td colspan="1" rowspan="1" style="box-sizing: border-box; margin: 0px; padding: 6px 10px; border-bottom: 0.909091px solid rgba(31, 30, 29, 0.15);"><p>Une variable varie au niveau industrie → cluster à ce niveau</p></td></tr><tr><td colspan="1" rowspan="1" style="box-sizing: border-box; margin: 0px; padding: 6px 10px; border-bottom: 0.909091px solid rgba(31, 30, 29, 0.15);"><p>Panel firmes-années (variable industrie-année)</p></td><td colspan="1" rowspan="1" style="box-sizing: border-box; margin: 0px; padding: 6px 10px; border-bottom: 0.909091px solid rgba(31, 30, 29, 0.15);"><p>Industrie (pas industrie-année !)</p></td><td colspan="1" rowspan="1" style="box-sizing: border-box; margin: 0px; padding: 6px 10px; border-bottom: 0.909091px solid rgba(31, 30, 29, 0.15);"><p>Les chocs sectoriels persistent dans le temps → cluster industrie permet la corrélation temporelle</p></td></tr><tr><td colspan="1" rowspan="1" style="box-sizing: border-box; margin: 0px; padding: 6px 10px; border-bottom: 0.909091px solid rgba(31, 30, 29, 0.15);"><p>Panel firmes-années (variable firme-année)</p></td><td colspan="1" rowspan="1" style="box-sizing: border-box; margin: 0px; padding: 6px 10px; border-bottom: 0.909091px solid rgba(31, 30, 29, 0.15);"><p>Firme</p></td><td colspan="1" rowspan="1" style="box-sizing: border-box; margin: 0px; padding: 6px 10px; border-bottom: 0.909091px solid rgba(31, 30, 29, 0.15);"><p>La taille, levier etc. ont une forte autocorrélation → cluster firme</p></td></tr><tr><td colspan="1" rowspan="1" style="box-sizing: border-box; margin: 0px; padding: 6px 10px; border-bottom: none;"><p>Variable variant au niveau état/pays</p></td><td colspan="1" rowspan="1" style="box-sizing: border-box; margin: 0px; padding: 6px 10px; border-bottom: none;"><p>État / pays</p></td><td colspan="1" rowspan="1" style="box-sizing: border-box; margin: 0px; padding: 6px 10px; border-bottom: none;"><p>Cluster au niveau le plus agrégé de variation du régresseur clé</p></td></tr></tbody></table><p class="font-claude-response-body break-words whitespace-normal leading-[1.7]">même industrie bougent ensemble.</p>](https://assets.knowt.com/user-attachments/f5cb427a-43f1-4639-a06d-da0f0b878b07.png)
Voici un exemple de cluster par industrie
Exemple concret — chocs dans l'industrie pharmaceutique Le contexte
Tu étudies 6 firmes sur 3 ans. Elles appartiennent à deux industries.
Firme | Industrie |
|---|---|
Pfizer, J&J, Novartis | Pharma |
Tesla, BMW, Toyota | Auto |
Un choc arrive en 2021
En 2021, les gouvernements imposent une nouvelle réglementation sur les essais cliniques. Ça frappe toutes les firmes pharma en même temps. Leurs résidus ε de 2021 sont tous négatifs, pour la même raison.
La même année, rien d'exceptionnel dans l'automobile. Tesla, BMW et Toyota ont des résidus normaux, indépendants les uns des autres.
Ce que ça donne dans les données
2020 | 2021 | 2022 | |
|---|---|---|---|
Pfizer | ε = +0.1$ | ε = -0.8$ | ε =-0.6$ |
J&J | ε = -0.1$ | ε = -0.7$ | ε = -0.5$ |
Novartis | ε = +0.2$ | ε = -0.9$ | ε = -0.6$ |
Tesla | ε = +0.3$ | ε = +0.1$ | ε = -0.2$ |
BMW | ε = -0.2$ | ε = +0.3$ | ε = +0.1$ |
Toyota | ε = +0.1$ | ε = -0.1$ | ε = +0.2$ |
Tu vois immédiatement :
Les 3 firmes pharma bougent ensemble — corrélées à l'intérieur du cluster pharma
Les 3 firmes auto bougent indépendamment des pharma — indépendantes entre clusters
Le choc de 2021 persiste en 2022 pour les pharma — corrélation temporelle aussi
Pourquoi OLS sans clustering se trompe
OLS voit 18 observations (6 firmes × 3 ans) et suppose 18 informations indépendantes. Mais en réalité :
Les 3 observations pharma de 2021 ne font qu'une seule information — même choc, même direction
Les 3 observations pharma de 2022 ne font qu'une seule information — même persistance du choc
OLS croit avoir beaucoup de données. En vérité, pour identifier l'effet de la réglementation, il n'a que quelques variations vraiment indépendantes. Il sous-estime donc l'incertitude → SE trop petites.
Ce que le clustering corrige
En clusterisant par industrie, tu dis :
À l'intérieur du cluster pharma : j'autorise Pfizer, J&J et Novartis à avoir des erreurs corrélées — je sais qu'elles subissent les mêmes chocs
Entre clusters pharma et auto : j'suppose qu'ils sont indépendants — un choc réglementaire pharma n'affecte pas Toyota
L'estimateur ne compte plus 18 informations indépendantes. Il en compte 2 — le cluster pharma et le cluster auto. Les SE sont recalculées en conséquence, et sont plus grandes, plus honnêtes.
La règle retrouvée par l'exemple
Ta variable clé ici, c'est la réglementation — elle s'applique au niveau de l'industrie. Toutes les firmes pharma ont exactement le même x. Il faut donc clusterer au niveau industrie, pas au niveau firme. Clusterer par firme ici ne suffirait pas — tu corrigerais la corrélation temporelle au sein de Pfizer, mais tu ignorerais que Pfizer et J&J bougent ensemble.
Voici un cluster par firme
Le problème dans cet exemple
Le choc de 2021 frappe Pfizer, J&J et Novartis en même temps et pour la même raison. Leurs erreurs de 2021 sont donc fortement corrélées entre firmes.
En clusterisant par firme, tu corriges la persistance temporelle au sein de Pfizer — c'est bien. Mais tu ignores que Pfizer et J&J bougent ensemble cette année-là. Tu traites leurs erreurs de 2021 comme deux informations indépendantes alors qu'elles reflètent le même choc sectoriel.
Résultat : tes SE sont mieux que sans clustering, mais toujours sous-estimées. Tu crois avoir plus d'informations indépendantes que tu n'en as vraiment.
Quand clusterer par firme est correct
Clusterer par firme est le bon choix quand les chocs sont propres à chaque firme — pas partagés entre firmes du même secteur. Par exemple :
Pfizer perd un brevet en 2021 → choc spécifique à Pfizer, qui persiste dans le temps
J&J a un scandale produit en 2020 → choc spécifique à J&J
Ces chocs ne se propagent pas aux autres firmes
Dans ce cas, la corrélation importante est temporelle au sein de la firme, pas cross-sectionnelle entre firmes. Clusterer par firme capture exactement ça, et c'est suffisant.
![<p>Le problème dans cet exemple </p><p class="font-claude-response-body break-words whitespace-normal leading-[1.7]">Le choc de 2021 frappe Pfizer, J&J et Novartis <strong>en même temps et pour la même raison</strong>. Leurs erreurs de 2021 sont donc fortement corrélées entre firmes.</p><p> </p><p class="font-claude-response-body break-words whitespace-normal leading-[1.7]">En clusterisant par firme, tu corriges la persistance temporelle au sein de Pfizer — c'est bien. Mais tu ignores que Pfizer et J&J bougent ensemble cette année-là. Tu traites leurs erreurs de 2021 comme deux informations indépendantes alors qu'elles reflètent <strong>le même choc sectoriel</strong>.</p><p> </p><p class="font-claude-response-body break-words whitespace-normal leading-[1.7]">Résultat : tes SE sont mieux que sans clustering, mais toujours sous-estimées. Tu crois avoir plus d'informations indépendantes que tu n'en as vraiment.</p><p> </p><div data-type="horizontalRule"><hr></div><p> Quand clusterer par firme est correct </p><p class="font-claude-response-body break-words whitespace-normal leading-[1.7]">Clusterer par firme est le bon choix quand les chocs sont <strong>propres à chaque firme</strong> — pas partagés entre firmes du même secteur. Par exemple :</p><p> </p><ul><li><p>Pfizer perd un brevet en 2021 → choc spécifique à Pfizer, qui persiste dans le temps</p></li><li><p>J&J a un scandale produit en 2020 → choc spécifique à J&J</p></li><li><p>Ces chocs ne se propagent pas aux autres firmes</p></li></ul><p> </p><p class="font-claude-response-body break-words whitespace-normal leading-[1.7]">Dans ce cas, la corrélation importante est <strong>temporelle au sein de la firme</strong>, pas <strong>cross-sectionnelle entre firmes</strong>. Clusterer par firme capture exactement ça, et c'est suffisant.</p>](https://assets.knowt.com/user-attachments/0f5cc3b8-06d0-4ccc-8f76-60011caa0965.png)
FE vs clusters
Tool | What it fixes |
|---|---|
Firm FE | Removes time-invariant omitted variable bias |
Firm cluster | Corrects standard errors for serial correlation in residuals |
Clustering alone does not fix bias — it only adjusts SEs. FE alone removes the permanent component of the error but does not account for the remaining time-series dependence in εᵢₜ. Both together cover the two main problems simultaneously.
![<table style="min-width: 50px;"><colgroup><col style="min-width: 25px;"><col style="min-width: 25px;"></colgroup><tbody><tr><th colspan="1" rowspan="1"><p>Tool</p></th><th colspan="1" rowspan="1"><p>What it fixes</p></th></tr><tr><td colspan="1" rowspan="1"><p>Firm FE</p></td><td colspan="1" rowspan="1"><p>Removes time-invariant omitted variable bias</p></td></tr><tr><td colspan="1" rowspan="1"><p>Firm cluster</p></td><td colspan="1" rowspan="1"><p>Corrects standard errors for serial correlation in residuals</p></td></tr></tbody></table><p class="font-claude-response-body break-words whitespace-normal leading-[1.7]">Clustering <em>alone</em> does not fix bias — it only adjusts SEs. FE <em>alone</em> removes the permanent component of the error but does not account for the remaining time-series dependence in εᵢₜ. Both together cover the two main problems simultaneously.</p>](https://assets.knowt.com/user-attachments/5472f5f5-fcdb-4237-bb30-fceed1c8de89.png)
Pooled OLS vs FE

Explique double clustering
On peut être tenté de cluster par deux dimensions (firm et année). Petersen (2009) en parle:
Utile en asset pricing où les erreurs sont corrélées à la fois par firm et par time (beta communs, chocs de marché).
En corporate finance, c’est moins évident; double clustering n’est pas toujours nécessaire.