ISYS 42903 Mid Term
1/81
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai | Chat |
|---|
No analytics yet
Send a link to your students to track their progress
82 Terms
What is CRISP-DM
Cross Industry Standard Process for Data Mining
What are the 6 stages of CRISP-DM
1. Business/Research Understanding Phase
2. Data Understanding Phase
3. Data Preparation Phase
4. Modeling Phase
5. Evaluation Phase
6. Deployment Phase
What is the Business/Research Understanding Phase
- first stage in CRISP DM
- Clearly enunciate the project objectives and requirements in terms of the business or research unit as a whole
- Translate goals and restrictions into formulation of data mining problem definition
- prepare a preliminary strategy for achieving these objectives
Which CRISP DM stage: Chief Analyst meets with CIO, who says that she would like to investigate and scope out how analytics can be used in HR hiring projects?
Business/research Understanding Phase
What is the Data Understanding Phase
- second stage in CRISP DM
- Collect the data
- use exploratory data analysis to familiarize yourself with the data and discover initial insights
- Evaluate the quality of the data
- select interesting subsets that may contain actionable patterns
What is the data preparation phase
- The third stage in CRISP DM
- labor intensive phase covers all aspects of preparing the final data set from the raw, dirty, data.
- perform transformations on certain variables if needed
- clean the raw data so it is ready for modeling tools
What is Modeling Phase
- The fourth stage in CRISP DM
- select and apply appropriate modeling techniques
- calibrate model settings to optimize results
- several different techniques may be used for the same problem
- may require looping back to data preparation phase
What CRISP DM stage?: A data analyst meets with superiors to discuss whether to use kNN or Association on the data ?
Modeling Phase
What is Evaluation Phase?
-The fifth stage in CRISP DM
- Models must be evaluated for quality and effectiveness before deployment
- determine if model achieves objectives set in first stage
- establish whether sine important facet of the business or research problem has not been sufficiently accounted for
- come to a decision regarding the use of the data mining results
What is Deployment Phase?
- sixth stage in CRISP DM
- Model creation does not signify completion of the project
- single deployment: generate a report
- Complex deployment: implement a parallel data mining process in another department
- for businesses: the customer often carries out the deployment based on your model
6 data mining tasks
1. description
2. estimation
3. classification
4. prediction
5. clustering
6. association
What data mining task?: Estimate the amount of money a randomly chosen family of 4 will be shopping given a time and date?
Estimation or prediction
What is the data mining task?: Forecast the stock price of Microsoft for next year?
Prediction
What data mining task? Identify whether or not a certain financial transaction happened today is a possible criminal behavior ?
Classification
Treu or False? Data mining process is autonomous and requires little oversight.
False
What is Description?
A data mining task aimed to describe patterns and trends lying within the data.
What is estimation?
A data mining task that approximates the value of a numeric target variable using a set of numeric and/or categorical predictor variables
Example: Estimating the amount of money a random family of 4 will spend on back-to-school shopping this fall
What is prediction?
A data mining task that’s results lie in the future
example: predicting the price of a stock 3 months into the future
What is classification?
A data mining task that has a categorical target variable that can be split into different “classes” (income bracket for example).
example: diagnosing whether or not a particular disease is present
What is clustering?
A data mining task that groups records, observations, or cases into classes of similar objects. There is no target variable.
example: target marketing of a niche product for a small business which does not have a large marketing budget
What is association?
A data mining task that finds which attributes go together. It seeks to uncover rules for quantifying the relationship between two or more attributes. “if the antecedent then consequent”
Example: examining the proportion of children whose parents read to them who are themselves good readers.
What is the z-score equation?
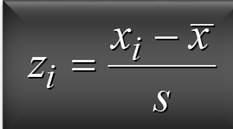
If z-score is less than the sample mean then the z-score is ___ than zero
z-score is less than zero
When skewness is positive then mean __ median?
mean is greater than the median
What is the use of standardizing variables?
Convert variables to a same scale
When Handling Missing Data, one could?
-Replace Missing Values with User-defined Constant
– Replace Missing Values with Mode or Mean/Median
– Replace Missing Values with Random Values
True or False? IQR is more robust that Z-score method for outlier detection, however, it is highly sensitive to mean and standard deviation
False
In data mining tasks, one could reduce the margin of errors by…
Increasing the sample size
True or False? In Forward Regression, you start with all variables of interest in the model and then at each step, the least significant variable is dropped, assuming it’s p-value is above a pre-set level (α = .05 or .10)
False

Select all appropriate options
A. No. of observations is 76
B. R square is 70.0
C. Each addition milligram (unit) of sodium, the estimated decrease in nutritional rating is 0.06057, when sugars is held constant
D. Rating = 2.37 – .20 Sugars – 0.01 Sodium + error
A and C
Before running a k-nearest neighbor model it is required to…
set the number of neighbors to compare instances to
In kNN, distance for non numerical variable can be computed by
different function
Euclidean distance formula
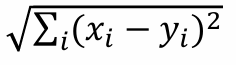
Calculate the E-distance for the following: Patient A is 20-years-old and has a Na/K ratio = 12, and Patient B is 30 years-old and has a Na/K ratio = 8
10.77
A sample of 1000 data items has a mean of 100 and a standard deviation of 2 with a range of 94 to 107.
a. Compute Z-score the following two values: 104, 98
b. Compute Min-Max range the following: 104, 98
a. 2, -1
b. 0.769, 0.308
What are the supervised data mining tasks?
Description, estimation, prediction, and classification
(they all have a target variable)
What are the unsupervised data mining tasks?
Clustering and association
(No target variable)
Normality vs Normalization
Normality deals with the distribution of data
Normalization deals with unskewing data
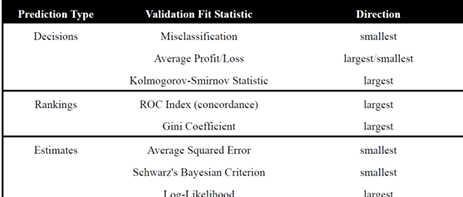
Choose appropriate fit statistics for estimation model selection:
Average Squared Error (ASE)
Schwarz’s Bayesian Criterion (SBC)
Log Likelihood
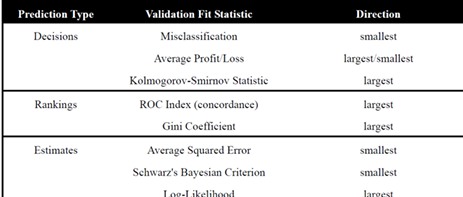
Choose appropriate fit statistics for decision model selection:
Misclassification and average profit/loss
Which is true when modeling a Decision Tree?
• Each variable is evaluated at each node to determine the splitting variable
• The same variable may be used for splitting at different locations in the Decision Tree
• CART (Phi) / information gain criteria can be used for selecting candidate splits
• If not pruned, a stopping criterion in creating a Decision Tree is when the tree reaches the leaf nodes
• All of the above
All of the above
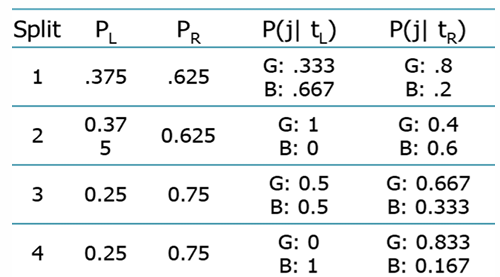
Compute the goodness of fit for candidate split 3
equation: 2PL*PR * |P(j|tL)-P(j|tR)|
0.125
What is data mining?
The process of discovering useful patterns and trends in large data sets
Is automation a substitute for human input in data mining?
No, humans need to be actively involved at every phase of the data mining process.
Why do we need to preprocess data?
missing values, outliers, data in a form not suitable for mining models, inconsistent values, obsolete or redundant fields.
Data cleaning and data transformation are associated with?
preprocessing
Ways to handle missing data
- replace missing value with some constant
- replace with the field mean (numerical) or mode (categorical)
- replace with a value generated at random from the observed distribution of the variable
- replace with imputed value based on the other characteristics of the record
What is an outlier
extreme values that go against the trend of the remaining data
What are measures of center
mean, median, mode
measures of location
percentiles and quantiles
Measures of variability
range, standard deviation, mean absolute deviation, and IQR
Equation for sample std dev
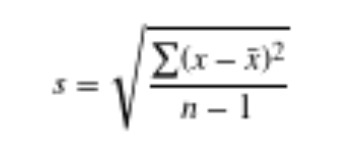
Why should data miners normalize their numeric variables?
to standardize the scale of effect each variable has on the results.
What is Min-Max Normalization
Looks at how much greater the field value is than the min and scaling this difference by the range. Values will range 0-1.
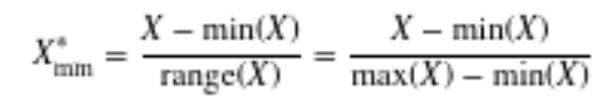
What is z-score standardization?
takes the difference between the field value and field mean and scales this difference by the std deviation of the field values.
What is decimal scaling?
ensures that every normalized value lies between -1 and 1
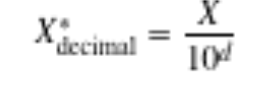
A data value is an outlier if (IQR)
it is located 1.5 IQR below Q1 or 1.5 IQR above Q3
equation to see: Q1 - 1.5(IQR) and Q3 + 1.5(IQR)
What is a dummy(flag/indicator) variable?
a categorical variable that only has two values (0 or 1). This is used during regressions when one wants to use categorical predictors (gender). Regression requires predictors to be numeric.
What is an unary variable?
takes on only a single value, so more like a constant
How to calculate confidence interval
point estimate ± margin of error
What is margin of error
it indicates the range within which the true population parameter is expected to lie, based on a sample estimate
What is standard error of the estimate?
accuracy of predictions made by a regression model.
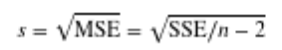
What is r squared
a measure of how closely the linear regression model fits the data
What is cross validation
a technique for insuring that the results uncovered in an analysis are generalizable to an independent, unseen, data set.
two types: Two fold and k-fold
What is meant by overfitting?
this results when the provisional model tries to account for every possible trend or structure in the training set.
What is the most often used algorithim for classification?
kNN/k-nearest-neighbor
What is an example of instance based learning?
kNN
What is simple unweighted voting
1. before running the algorithm, decide on the value of k
2. then compare new record to k nearest neighbors
3. once the k records have been chosen, the distance no longer matters. one record, one vote.
What is weighted voting?
closer neighbors have a larger voice in the classification decision than do more distant neighbors. Weighted voting also makes it much less likely for ties to arise.
What is a decision tree?
a collection of decision nodes, connected by branches, extending downward from the root node until terminating in leaf nodes
- target variable must be categorical
Requirements that must be met before decision tree algorithm may be applied?
1. Decision tree algorithms represent supervised learning, and as such require preclassified target variables. A training data set must be supplied which provides the algorithm with the values of the target variable.
2. This training data set should be rich and varied, providing the algorithm with a healthy cross section of the types of records for which classification may be needed in the future. Decision trees learn by example, and if examples are systematically lacking for a definable subset of records, classification and prediction for this subset will be problematic or impossible.
3. The target attribute classes must be discrete. That is, one cannot apply decision tree analysis to a continuous target variable. Rather, the target variable must take on values that are clearly demarcated as either belonging to a particular class or not belonging.
Two algorithms for constructing decision trees?
CART (classification and regression trees) & C4.5
What is CART?
The decision trees produced are strictly binary, containing exactly two branches for each decision node. It recursively partitions the records in the training data set into subsets of records with similar values for the target attribute.
What is C4.5?
- is not restricted to binary splits.
- produces a tree of more variable shape.
- For categorical attributes, ___ by default produces a separate branch for each value of the categorical attribute. This may result in more “bushiness” than desired, since some values may have low frequency or may naturally be associated with other values.
- uses the concept of information gain or entropy reduction to select an optimal split
What are decision rules?
“if antecedent, then consequent”
What is VIF and what does it measure?
Variance Inflation Factor; measures multicollinearity
What are 4 assumptions of linear regression?
1. linearity
2. independence
3. Homoscedasticity
4. normality of residuals
Skewness and Kurtosis cutoff values?
Skewness: -12 to +2
Kurtosis: -10 to +10
Methods for normality of data
natural log, square root, inverse square root
statistical inference
Methods for estimating and testing hypotheses
about population characteristics based on
information contained in a sample
Data can be split into three components
Training, validation and testing
What is association analyses
Also called market basket analysis (MBA) and affinity analysis. Study of what goes with what. “customers who purchased x also purchased Y”