Data analysis l10/13
1/75
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
76 Terms
What is a covariate?
A continuous independent variable (e.g. age, temperature, size).
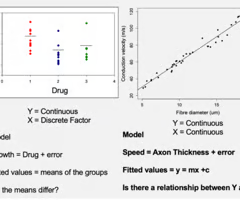
What is a factor?
A categorical independent variable with discrete levels.
Give examples of covariates
Body size, temperature, age, hormone levels, nutrient availability, light intensity.
What is regression?
Regression = relationship between X and Y; Model: Y=bX+c
What type of variable is the dependent variable (Y) in regression?
Continuous.
What is the purpose of regression?
To quantify the relationship between two continuous variables.
What new type of question does regression answer?
How a continuous dependent variable changes with a continuous independent variable.
What is the regression model equation?
Y = bX + c + error.
What does b (slope) represent?
The change in Y for a unit change in X.
What does c (intercept) represent?
The value of Y when X = 0.
What is the main goal of regression analysis?
To test if there is a significant relationship between X and Y.
What to interpret with regression
If slope is positive → Y increases with X; If slope is negative → Y decreases with X
How does a factor-based model differ from a covariate-based model?
Factor models estimate group means, covariate models fit a line.
Why covariates help analyse factors
Covariates remove extra variation → fairer comparison of groups
What does a one-factor GLM estimate?
Separate means for each group.
What does a one-covariate GLM estimate?
A line describing the relationship between X and Y.
What is the key similarity between regression and one-factor GLMs?
They use the same statistical framework (GLM).
One factor vs covariate
One factor = categorical; covariate = continuous
What assumptions do regression and GLMs share?
Same assumptions (random sampling, independence, homogeneity, normality).
What is the first step in both one-factor and regression models?
Calculate the total sum of squares (total variation).
What does total sum of squares represent?
Total variation in the data.
How is total sum of squares calculated?
Difference between each value and the grand mean, squared and summed.
What is error sum of squares in regression?
Variation between data points and the fitted line.
What does error sum of squares represent?
Unexplained variation.
What is covariate sum of squares?
Variation explained by the covariate.
How are sums of squares partitioned in regression?
Total SS = covariate SS + error SS.
What is the goal when fitting a regression line?
Minimise the error sum of squares.
What does the F-statistic compare in regression?
Covariate SS (explained variation) vs error SS (unexplained variation).
What is used to determine significance in regression?
F-statistic and p-value.
What does a significant p-value in regression indicate?
Evidence of a relationship between X and Y.
What is the key conceptual difference between regression and ANOVA?
Regression tests relationships, ANOVA tests differences between groups.
What is ANCOVA?
A model that includes both factors and covariates.
What is the purpose of ANCOVA?
To test factor effects while accounting for a covariate.
Why include a covariate in a model with a factor?
To explain additional variation and improve accuracy.
What does ANCOVA allow you to control for?
The effect of a continuous variable when comparing groups.
What is the overall structure of all GLMs?
Partition variation into explained and unexplained components.
What is the key takeaway about GLMs?
All GLMs use the same logic (partitioning variation and comparing it).
How do you interpret data from ANCOVA?
Assess the effect of the covariate (relationship with Y), the effect of the factor (differences between groups), and whether the covariate influences these comparisons, interpreting factor effects while accounting for variation explained by the covariate
What is a mixed effects model?
A model that includes both fixed effects and random effects.
What are fixed effects?
Independent variables with a few predefined levels that are of direct interest.
Give examples of fixed effects
Treatment, sex, diet, species, altitude.
What do fixed effects estimate?
Specific differences between the levels of that factor.
How are fixed effects interpreted?
Using only data from each level to estimate its value.
What are random effects?
Variables with many levels sampled from a larger population.
Give examples of random effects
Family, individual, litter, cage, population.
What do random effects estimate?
Variation among groups, not differences between specific groups.
What is a key feature of random effects?
Their levels are randomly sampled from a larger population.
What is the main goal of including random effects?
To estimate variance or account for non-independence.
How are random effects interpreted?
Using information from all levels to estimate each level.
What happens to extreme values in random effects?
They are "shrunk" towards the overall mean.
Why does shrinkage occur?
Because information is shared across all levels.
What is the key difference between fixed and random effects?
Fixed effects compare specific levels, random effects model variation among levels from a population.
When should you use a random effect?
When levels are sampled from a population or data are non-independent.
What is pseudo-replication?
Treating non-independent data as independent.
How do mixed models help with pseudo-replication?
They account for non-independence using random effects.
Why are mixed models useful?
They allow analysis of non-independent data.
What is an example of non-independent data?
Multiple measurements from the same individual or group.
What is a randomised block design?
An experiment where groups (blocks) are included to account for variation.
What happens if you treat a random effect as a fixed effect?
Results only apply to those specific levels.
What happens if you treat a variable as a random effect?
Results can be generalised to a larger population.
Why do random effects allow generalisation?
Because levels are assumed to be sampled from a population.
What is the key interpretation difference (fixed vs random)?
Fixed = specific groups; random = population-level inference.
What is the main advantage of mixed models over simple GLMs?
They handle non-independence and allow broader conclusions.
Mixed effects models involve both 'fixed' and 'random' effects. Fixed effects:
c) Are often used to compare groups of specific interest.
The following are common examples of fixed effects except
b) Individual subject
Mixed effects models: which is NOT typical of a random effect
c) Included in a model to compare groups of specific interest.
The following are common examples of random effects except
c) Treatment
When estimating a fixed effect, info comes from
a) The focal level
When estimating a random effect, info comes from
b) The focal level and other levels of the factor
Interpretation of random effects
a) The results apply to the population from which the levels were sampled
Interpretation of fixed effects
b) The results only apply to the levels of the fixed effect included in the model.
Which analysis: genotype + sex (independent data)?
c) Multi-factor (fixed effect) GLM
Which analysis: simple independent data?
a) 1-Factor (fixed effect) GLM
Which analysis: repeated measures over time?
e) Combination of fixed and random ('mixed') effects
Which analysis: repeated within individuals?
e) Combination of fixed and random ('mixed') effects
Which analysis: tissue + individual variation?
a) 1-Factor GLM OR e) mixed effects model (better power)