Datenbanken 1
1/44
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
45 Terms
Strukturierung
Strukturiert
Tabellarisch
Semistrukturiert
XML (nutzt Auszeichnungen)
Unstrukturiert
Texte, Bilder und Videos
Dauerhaftigkeit
Transient
Flüchtige Daten
Persistent
dauerhaft gespeicherte Daten
Anwendungsdaten
Stammdaten
Wenig Veränderung über die Zeit
Wird oft genutzt
Langfristige Speicherung
Bewegungsdaten
Viele Veränderungen
Wird deutlich weniger genutzt
Kurz- und mittelfristige Speicherung
Bestandsdaten
Viele Veränderungen
Wird deutlich weniger genutzt
Langfristige Speicherung
Beziehungen in Daten
Tabellarisch
Hierarchisch
Netzwerkartig
Dateiformat
Das Dateiformat legt die Codierung und Strukturierung fest.
Um herauszufinden, welches Dateiformat einer Datei zugrunde liegt gibt es 3 Ansätze:
Dateiendung → Spezielle Endung der Datei (.png) wird deutlich gemacht, welches Dateiformat die Datei hat
Besondere Dateiinhalte → Besondere Zeichen am Anfang einer Datei, welche das verwendete Dateiformat angeben (Magic Number)
Zusätzliche Meta-Daten → Geben zusätzliche Informationen über das Dateiformat
Strukturierung von Dateien — Feste Positionen
Dateiformat legt fest…
…was sich
…wo in der Datei befindet
… und wie es codiert ist.
Typisch für Binärdateien
Strukturierung von Dateien — Trennzeichen
Elemente durch vereinbarte Zeichen getrennt
bspw. durch: Zeilenumbruch, Comma, Tab usw.
Typisch für Textdateien
Beispiele: CSV, Text Tab-getrennt
Strukturierung von Dateien — Auszeichnungen
Hervorheben von Elementen und Eigenschaften durch besondere Syntax (v.a. Tags)
Nutzung in Textdateien
Beispiele: XML, LaTeX
Structured Query Language (SQL)
Abfragesprache für rationale Datenbanken
Enthält Befehle für 4 Bereiche:
DRL (Data Retrieval Langage) → Um Inhalte einer Datenbank abzufragen (SELECT)
DML (Data Manipulation Language) → Um Inhalte einer Datenbank anzulegen, zu verändern oder zu löschen (INSERT, UPDATE, DELETE)
DDL (Data Definition Language) → Um den Aufbau einer Datenbank zu beschreiben (CREATE TABLE, ALTER TABLE usw.)
DCL (Data Control Language) → Um den Betrieb einer Datenbank zu steuern (GRAT, REVOKE, usw.)
Zeilenweise mit Skalarfunktionen rechnen
Bsp:
SELECT SUBSTRING(username, 0,3)
AS usr
FROM users;Skalarfunktionen werden auf die Werte desselben Datensatzes angewendet.
Es gibt bspw. (mit WERT ist Spaltenname gemeint):
Teilstring = SUBSTRING([WERT], [Anfangs-char], [LÄNGE])
Betrag (absolut wert) von Zahl = ABS([WERT])
Runden = ROUND([WERT])
Anzahl der Zeichen = LENGTH([Wert])
NULL ggf. ersetzen = COALESCE([Wert])
Gruppieren und auswerten
Gruppierungen erlauben es, umfangreiche Daten zu verdichten
Gruppierung bedeutet dabei, dass die Attributwerte dieser Spalte bestimmt und von Duplikaten befreit werden.
Dann werden in der in “FROM” angegeben Tabelle diejenigen Datensätze gesucht, die zu den jeweiligen Attributwerten gehören
Auf diese Datensätze werden dann die sog. Aggregatsfunktionen angewendet. Zu diesen gehören u.a.:
COUNT, um Datensätze zu zählen
SUM, um Attributwerte zu summieren
AVG, um den Mittelwert der Attributwerte zu bestimmen
MIN und MAX, um den kleinsten bzw. größten Attributwert zu ermitteln
Beispiel:
SELECT region,
COUNT(*) AS nrusers
FROM users
GROUP BY region
ORDER BY nrusers DESC,
regionErläuterung:
Hier wird ermittelt, wie viele Benutzer je Region vorhanden sind. Nach den ermittelten Anzahlen lässt sich mithilfe von ORDER BY sortieren (DESC = descending (absteigend))
Wichtig:
In der Feldliste von SELECT dürfen neben der Aggregatfunktionen nur diejenigen Spalten auftreten, die auch in GROUPY BY verwendet werden!
Abfragen verbinden
Die Ergebnisse zweier Abfragen lassen sich mithilfe von UNION vereinen.
Dabei ist zwingend, dass sie dieselben Spalten besitzen, außerdem dürfen die jeweiligen Abfragen kein ORDER BY enthalten
UNION eliminiert Duplikate; bei UNION ALL ist dies nicht der Fall.
Cross-Join
Nimmt man in die FROM Klausel zwei Tabellen auf, so wird zunächst das kartesische Produkt beider Tabellen berechnet. Das heißt, jeder Datensatz der linken Tabelle wird mit jedem Datensatz der rechten Tabelle verbunden.
Die bezeichnet man als Cross-Join. Deswegen schreibt man eher
FROM l CROSS JOIN rVon Cross-Join zu Equi-Join
Läge zwischen lid und rid eine Fremdschlüsselbeziehung vor, so entstünde bei einem Cross-Join Datensätze, bei denen lid und rid nicht übereinstimmen (was nicht beabsichtigt ist und auch nicht erwünscht ist).
Deshalb ergänzt man den impliziten Cross-Join mit einer WHERE Klausel um nur die Datensätze zu selektieren/anzuzeigen, bei denen rid und lid gleich sind.:
SELECT l.lid, l.lval, r.rid, r.rval
FROM l, r
WHERE l.lid = r.rid
Inner-Join
Diese (gängigste) Join Methode nutzt anstatt der WHERE Bedingung, das Schlüsselwort JOIN (oder INNER JOIN). Mit ON gibt man an, welche Bedingung für die Datensätze der Ergebnismenge erfüllt sein müssen.
Beispiel:
SELECT l.lid, l.lval, r.rid, r.rval
FROM l
JOIN r ON l.lid = r.ridLeft-Outer-Join bwz. Right-Outer-Join
Sollen in der Ergebnismenge nicht nur diejenigen Datensätze enthalten sein, für die die Join-Bedingung zutrifft, sondern auch alle übrigen Datensätze der linken (bei Right-Outer-Join von der rechten) Tabelle so spricht man von einem Left-Outer-Join / Right-Outer-Join.
In SQL entweder:
LEFT JOIN (LEFT OUTER JOIN)
oder
RIGHT JOIN (RIGHT OUTER JOIN)
Die Felder der anderen Tabelle (Bei Left-Outer-Join von der rechten Tabelle) werden auf NULL gesetzt, wenn die Join-Bedingung nicht erfüllt ist.
Diese Art der Joins wird verwendet, wenn die rechte (bei einem Right-Outer-Join die linke) Tabelle optionale Angaben enthält
Full-Outer-Join
Mischform von Left- und Right-Outer-Join.
Neben den Datensätzen mit erfüllter Join-Bedingung werden sowohl die zusätzlichen Datensätze/Zeilen der linken und rechten Tabelle in die Ergebnismenge übernommen.
Unterabfragen
Da das Ergebnis einer Abfrage selbst auch tabellarisch ist, kann man Abfragen auch als sog. Unterabfragen nutzen.
Das Ergebnis der Unterabfrage wird dabei wie eine Tabelle verwendet - auch erhält sie ein Alias.
Drei typische Einsatzgebiete sind:
Ergebnisse gruppierter Abfragen weiter auswerten (siehe Beispiel)
Ermitteln von Mengen oder Werten, die für Bedingungen benötigt werden (z.B. wert IN (<Unterabfrage>))
Joins zwischen kleinen Teilmengen sehr großer Tabellen (wenn sinnvoll)
Beispiel:
SELECT u.*,
CASE WHEN u.nrusers > 0 THEN 1
ELSE 0 END as status
FROM
(
SELECT region,
COUNT(*) as nrusers
FROM users
GROUP BY region
) u
ORDER BY u.regionUnterabfragen können Abfragen vereinfachen und beschleunigen, können aber auch überflüssig sein oder die Abfragen verlangsamen.
Die Unterabfrage selbst muss einige Anforderungen erfüllen. Bspw.
Kein ORDER BY verwenden
Schlüsselwort Reihenfolge (SELECT)
SELECT → Gewünschte Spalten, ggf. Aggregate oder Aliase
FROM → Tabellen oder Unterabfragen, ggf. Join mit Bedingung, bei Bedarf mit Alias
WHERE → Auswahl der gewünschten Zeilen (Operatoren: BETWEEN, IN, LIKE usw.)
GROUP BY → Felder, nach denen gruppiert wird
HAVING → Auswahl der Gruppen
ORDER BY → Felder, nach denen sortiert wird
Date einfügen, ändern und löschen
Einfügen → INSERT INTO
Bsp.
INSERT INTO users
VALUES (8, 'ada', NULL, 'US')Ändern → UPDATE
Bsp.
UPDATE users
SET username = 'car1'
company = 'Starmax'
WHERE userId = 7Löschen → DELETE FROM
Bsp.
DELETE FROM users
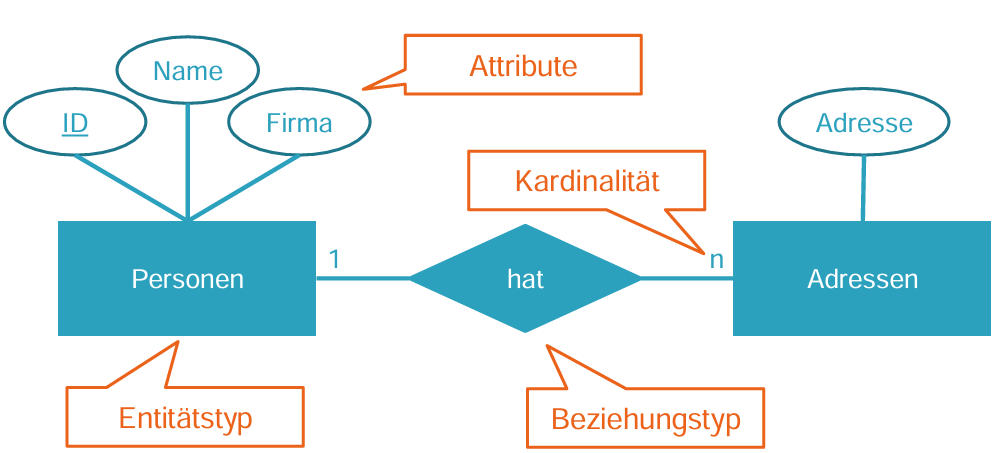
WHERE userId = 7Entity-Relationship-Modellierung (ER-Modelle)
Beschreiben semantische Beziehungen der betrachteten Daten
Dafür betrachtet man Entitäten und ihre Beziehungen
Als Entität bezeichnet man Objekte der Wirklichkeit
1.Normalform (1NF)
Atomare Attribute (Einzelwerte) → Keine verschachtelten Relationen
Grundlegende Normalform für rationale Datenbanken
Gegen diese wird in verschiedenen Fällen absichtlich verstoßen:
Objektrationale Datenbanken
JSON/XML-Code wird für komplexe Inhalte in einem Feld abgelegt
Solche Verstöße gegen die 1NF werden oft dann genutzt wenn:
Struktur sehr aufwendig ist
Keine sichere Aufteilung der Inhalte gebraucht wird
2.Normalform (2NF)
Relation muss in 1NF vorliegen
+
Sollte möglichst schlanke Schlüssel haben
Besteht der Primärschlüssel nur aus einem Feld , ist eine solche 1NF-Relatio zugleich auch eine 2NF.
→ Alle Nichtschlüsselattribute sollen voll funktional von jedem Schlüsselkanditen abhängen.
3.Normalform (3NF)
Relation muss in 2NF vorliegen
+
Sie darf keine Entitätsfremden Informationen enthalten
→ Es darf keine Nichtschlüsselattribute geben, die funktional von einem anderen Nichtschlüsselattribut abhängen (also: Nichtschlüsselattribute dürfen nicht transitiv (also in mehreren Schritten) vom Primärschlüssel abhängen)
Denormalisierung
Es gibt Fälle in denen es durchaus sinnvoll sein kann, bewusst gegen Normalformen zu verstoßen
Ziel der Normalformen → Vermeidung von Redundanz, um damit Änderungsanomalien und die damit verbundenen Inkonsistenzen zu verhindern. Der Preis dafür, besteht in der Notwendigkeit von Joins, um die unterschiedlichen Tabellen zusammenzuführen.
Sollen Daten verändert werden? → Normalisierung!
Sollen Daten allerdings nur gelesen werden, z.B. in einer Analyse-Datenbank (Data Warehouse etc.) besteht keine Gefahr von Änderungsanomalien, womöglich kann die Vielzahl an Joins die Performance beeinträchtigen, vor allem bei großen Datenbeständen.
Anlegen von Tabellen
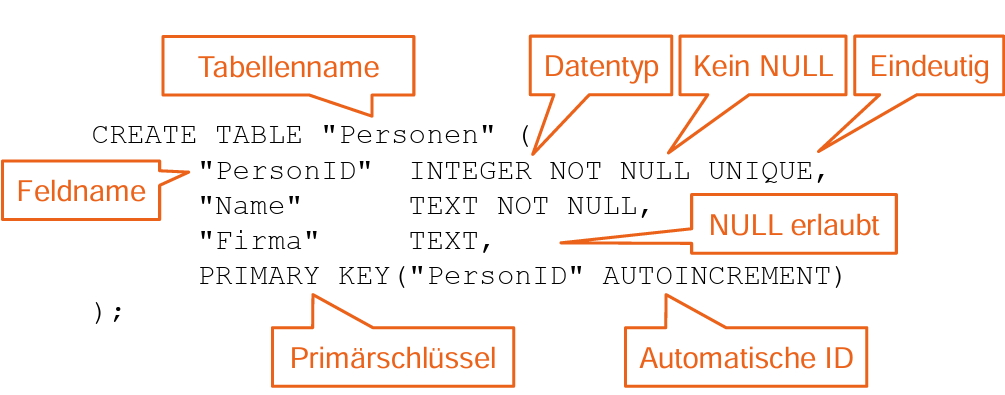
Indizierung
Problem: Beim Anlegen einer Tabelle stellt sich die Frage der Indizierung, d.h. welche Spalten indiziert werden sollen.
Wird ein Wert gesucht, muss man Zeile für Zeile den betreffenden Wert des Feldes und vergleichen. Dieses sequentielle Lesen ist vor allem bei großen Datenbanktabellen sehr aufwendig, da durchschnittlich N/2-Datensätze gelesen und verglichen werden.Grundidee der Indizierung: Einsetzen von zusätzlichen Datenstrukturen, sog. “Indizes”. Ein Index ordnet jedem Feldwert eine (oder mehrere) Datensatzadresse/n zu, um den Wert schneller zu finden nutzt man Bäume oder Hashes.
Primärschlüsselspalten sind automatisch auch immer indiziert. Für Nichtschlüsselspalten kann man zusätzliche Indizes anlegen, wenn in ihnen häufig gesucht wird, wenn sie häufig für Gruppierungen genutzt werden oder wenn sie häufig als JOIN-Kriterium dienen.
Nachteile:
Beim Einfügen neuer Datensätze
Beim Löschen von Datensätzen
Wenn indizierte Felder geändert werden
muss der Index aktualisiert werden, d.h. zu viele Indizes in Verbindung mit häufigen Operationen dieser Art können die Datenbank verlangsamen.
SQL Injection und Lösungen
Damit eine SQL Injection gelingt müssen einige Fehler gemacht werden
Keine Serverseitige Validation von Eingaben
Eingabe direkt mit einem SQL-String verbunden
Unnötig hohe DB-Berechtigungen
Schützen kann man sich durch mehrere Methoden:
Nutzung von Prepared Statements
Nutzung von Quotes (Quote Function), welche Sonderzeichen in Eingaben unschädlichen machen
Nutzung von einem ORM, da diese (meist) die vorherig genannten Methoden schon automatisch nutzen
ORM (Object-Relational Mapping)
Vorteile:
Abstraktion des Datenbankzugriffs
Höhere Sicherheit (da bspw. SQL-Injections automatisch verhindert werden)
Integration von OOP-Konzepte
Nachteile:
Schlechte Optimierung der Abfragen
Oft nur geringe Kontrolle über erzeugtes SQL
Doppelter Cache (ORM + DB)
Massenverarbeitung oft ineffizient
Datenbankunabhängigkeit verhindert spezifisches Tuning und weiterführende Features
Tücken des gleichzeitigen Zugriffs
Lost Update
2 Clients versuchen gleichzeitig auf die DB zu schreiben (einen Wert verändern)
Es kann dazu kommen, dass A die Änderung von B überschreibt oder umgekehrt
Dirty Read
A verändert Wert
B liest den Wert von DB
A macht die Änderung rückgängig oder bricht den Vorgang ab
Falsche Aggregate
A möchte ein Aggregat berechnen
B verändert währenddessen einen der zu verarbeitenden Werte
Lösung:
Transaktionen
Transaktion = Zusammengehörige Operationen fest miteinander Verbinden
Eine neue Transaktion kann erst gestartet werden, wenn die jetzige/alte fertig ist
ACID der Transaktionen
Der SQL-Standard definiert Transaktionen mit diesen ACID Eigenschaften:
ACID
Atomic → Transaktionen sind unteilbar
Consistent → Führen von einem konsistenten Zustand in den nächsten konsistenten Zustand
Isolated → Transaktionen beeinflussen sich nicht gegenseitig, sie sind abgegrenzt
Durable → Führen zu dauerhaften Änderungen der Daten, Änderungen sind persistent
GROUP BY vs. Window Function
Auf den ersten Blick sehr ähnlich, arbeiten allerdings sehr unterschiedlich
GROUP BY
Verdichtet die Zeilen jeder Gruppe zu einer Ergebniszeile je Gruppe
Window Function
Datensätze bleiben erhalten
Funktionsergebnisse werden jeder Ergebniszeile hinzugefügt
GROUP BY hat die Funktionen:
COUNT
SUM
AVG
MIN, MAX
STDDEV (Standardabweichung)
Window Function hat diese Funktionen alle auch und zusätzlich:
MEDIAN
RANK (um den Rang zu ermitteln)
NTH_VALUE (um den N-ten Wert zu erhalten)
LEAD (Nachfolger)
LAG (Vorgänger)
Ein Nachteil der Window Function ist allerdings, dass sie sich nur in SELECTs verwenden lassen, aber z.B. nicht in WHERE.
Gleitenden Mittelwerte — Moving Average
Ohne Zukunft (Letze N Werte)
SELECT ts, close,
AVG(close) OVER (ORDER BY ts
ROWS BETWEEN 719 PRECEDING
AND CURRENT ROW ) as movavg
FROM bitcoin
ORDER BY tsMit Zukunft (N Werte symmetrisch)
SELECT ts, close,
AVG(close) OVER (ORDER BY ts
ROWS BETWEEN 360 PRECEDING
AND 359 FOLLOWING ) as movavg
FROM bitcoin
ORDER BY ts→ Die Moving-Average-Filterung unterdrückt das Rauschen, beeinträchtigt auch kurzzeitige Änderungen oder Sprünge in der Zeitreihe.
Duplikate finden
Berücksichtigenden Spalten gruppieren und die so gruppierten Zeilen zählen.
Um nur noch die Datensätze zu selektieren/anzuzeigen, die mehr als einmal vorkommen kann man HAVING COUNT(*) > 1 nutzen
Beispiel:
SELECT col1, col2,
COUNT(*) as cnt
FROM tab
GROUP BY col1, col2
HAVING COUNT(*) > 1Mit Datumswerten rechnen
Tage zwischen zwei Daten
DATEDIFF([Bis], [Von])
Bsp.:
DATEDIFF( '2022-01-02', '2022-01-01' ) Addition von Zeiträumen
+ INTERVAL
DATEADD() INTERVAL
'2022-01-01' + INTERVAL 1 DAY
'2022-01-01' + INTERVAL 1 WEEK
'2022-01-01' + INTERVAL 1 MONTH
'2020-02-29' + INTERVAL 1 YEAR Nach Kalenderwoche gruppieren
DATE_FORMAT()
DATE_FORMAT( '2022-01-03', '%x-%v' )Common Table Expressions (CTE)
Nichtrekursive CTE
WITH substaff AS
(
SELECT * FROM staff WHERE manager_id IS NOT NULL
)
SELECT * FROM substaffRekursive CTE
WITH RECURSIVE substaff AS
(
SELECT …
UNION
SELECT … FROM substaff …
)
SELECT * FROM substaffCTE sind bekannte Unterabfragen, die mehrfach in einer Abfrage oder ihren Unterabfragen verwendet werden können.
Rekursive CTEs werden genutzt um z.B. hierarchische Daten zu durchlaufen
Beispiel (siehe Bild):
Es wurde eine CTE geschrieben um herauszufinden welche Mitarbeiter Alice als direkte oder indirekte Vorgesetzte haben.
Die rekursive CTE nutzt den Datensatz von Alice als Verankerung. Die Rekursion besteht darin, die Mitarbeiter anhand von manager_id mit der CTE zu joinen.
Views
Views sind die Ergebnisse gespeicherter Abfragen (“Virtuelle Tabelle”)
Views können in anderen Abfragen genutzt werden
Anlegen von views mit “CREATE VIEW”
Wenig Speicherplatz, da nur die Abfrage selbst gespeichert wird
Führt zu einer besseren Übersichtlichkeit und Lesbarkeit, da man die Unterabfragen hinter einem Namen verbergen
Abstrahieren also sehr viel komplexere Abfragen und führen dies in einer virtuellen Tabelle ein
Stored Routine
Stored Procedures
Kein Rückgabewert
Können IN- und OUT-Parameter verwenden (also auch Werte durch Parameter zurückgeben)
Werden mit CALL aufgerufen
Können dementsprechend nicht in SLECECT etc. verwendet werden
Können Tabelleninhalte lesen, aber auch verändern und Transaktionen steuern
Stored Functions
Rückgabewert
Können nur IN-Parameter verwenden
Lassen sich in SELECT, WHERE etc. verwenden
Dürfen keine Tabelleninhalte verändern oder Transaktionen steuern
Beiden werden als Objekt in der Datenbank gespeichert.
Trigger
Anweisungen bei Events in einer Tabelle werden automatisch ausgeführt
Event ergibt sich aus:
Operation (INSERT, UPDATE, DELETE)
und
Zeitpunkt (BEFORE, AFTER)
Stored Routines & Trigger als Imperative Konstrukte in SQL (Vor- und Nachteile)
SQL als deklarative Sprache fokussiert sich mehr auf das “WAS”, anstatt das “WIE”.
Vorteile:
Konsistenz auf DB-Ebene
Verteilung mit DB
Übersichtlichkeit in Abfragen
Nachteile:
Schwieriges Debugging
Vermischung von Geschäftslogik und Datenhaltung
Schwierige Migration
Keine Versionierung
Performance-Nachteile
Von der Abfrage zu den Daten
SQL Befehl (bspw. SELECT …)
Parsing und Preprocessing → Syntaxanalyse usw.
Query Optimization → Erstellung eines Query Plans
Zugriffsgeschwindigkeit:
Index
Cache
Dateien
Query Execution → Daten in Tabelle
CAP-Theorem
Man geht von 3 grundlegenden Zusicherungen des Systems aus:
Consistency → Alle Knoten verwenden stets denselben Datenbestand
Availability → Jede Anfrage an das System wird beantwortet, entweder mit der entsprechenden Antwort oder einer Fehlermeldung
Partition tolerance (Robustheit) → Auch bei Ausfall einzelner Knoten oder Verlust von Nachrichten zwischen den Knoten kann das Gesamtsystem weiterarbeiten
BASE in Datenbanken
BAsically available → System ist so weit wie möglich verfügbar, aber unter Umständen nur eine Fehlermeldung oder inkonsistente Daten liefert
Soft-State → Wegen vorübergehender Inkonsistenzen nicht mit Sicherheit sagen können, in welchem Zustand sich die Daten befinden
Eventually consistent → Vorübergehende Inkonsistenzen werden in Kauf genommen. Nach einem Schreibvorgang kann es also einige Zeit dauert, bis dahin aber immer derselbe Wert gelesen wird.
ACID vs. BASE
Vorübergehende Inkonsistenz und unklare Zustände sind letztlich der Preis für die verteilte Architektur und die damit einhergehenden Vorteile
Es geht also nicht darum, ob ACID oder BASE richtig oder besser ist, sondern welche Anforderungen im konkreten Fall bestehen und womit sie sich besser erfüllen lassen.
Rationale DBMS bieten durch ACID hohe Konsistenz und mit SQL eine mächtige Abfragesprache, zeigen aber Nachteile bei Leistung und Skalierbarkeit
NoSQL-DBMS verzichten auf starre Datenmodelle, zugunsten von Leistung und Robustheit auf Konsistenz durch BASE; sind meist besser für verteilte Architekturen geeignet.
Typische NoSQL-DBMS sind:
Key-Value-DB
Spaltenorientierte DB
Dokumentenorientierte DB
Graphen DB
Zeitreihen DB
Pseudonymisierung und Anonymisierung
Pseudonymisierung (Umkehrbar)
Daten lassen sich ohne zusätzliche Informationen nicht mehr der betroffenen Person zuordnen
Bsp.:
Patient 4711 hat einen positiven HIV-Test.
→ Daten sind weiterhin einer Person zuordenbar
Anonymisierung (Nicht Umkehrbar)
Daten lassen sich der betroffenen Person nicht mehr zuordnen, auch nicht mit zusätzlichen Informationen
Bsp.:
Jemand hat einen positiven HIV-Test
→ Daten lassen sich nicht mehr einer Person zuordnen