stat 4
1/342
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
343 Terms
boxplot: wat is het hoogste en laagste punt niet outlier, En vanaf wanneer wel een outlier.
En IQA
-het einde van de whiskers is het hoogste/laagste niet outlier.
-vanaf 1.5 interkwartiel onder P25 en boven P 75 outlier. ( zwarte bolletje) indien extreme outlier *
P75- P25
scatterplot. groepeerde scatterplot hoe ziet dit eruit
Waarom hebben we soms missing data en wat is de impact hiervan
-Onafhankelijk van respondent: bv door de procedure ( ga naar vraag 6 indien X) of codeerfouten (sureys, niet goed ingescand,.. )
-afhankelijk van respondent: niet willen invullen , vergeten
-Kan een impact hebben op de steekproefgrootte indien je bv listwise deletion doet. Maar niet altijd goed idee ( denk aan vb antartica )
-Ook kan je bias creeren bij somige missing data technieken
-verwaarloosbare missing data
—>data van individuen die niet in je steekproef zitten. Of factoren die je niet hebt gemeten
—>skip patrone
—>censored data:Censored data is een vorm van missing data waarbij de exacte waarde onbekend is, maar wel gedeeltelijke informatie beschikbaar is over waar die waarde ligt. Bij right censoring weten we dat de waarde groter is dan een bepaalde grens (bv. nog geen herval op het einde van de studie), bij left censoring(bv wnr begon iemand te roken ) dat ze kleiner is dan een grens, en bij interval censoring(Bv je meet elke maand corona test, februari neg, maart postief; dus valt ergens tussen die grenzen) dat ze tussen twee tijdstippen ligt. Hierdoor is censored data informatiever dan gewone missing data.
niet verwaarloosbare missing data
=non random missiingness
-Indien data niet verwaarloosbaar is ga naar volgende stappen
-gekende: te wijten aan procedurele factoren, codeer fouten, weinig controle over, je kan achterhalen waarom iets mis ging
-onbekende : je weet niet waarom, miss gevoelig item voror respondent,.
stap 2: missing data, omvang bepalen en wat wanneer doen. vuistregels
<10% cases missing per variabele
: alle methoden oke, list wise deletion minst aangewezen
-10, 20% (missing ness ondezoeken)
MCAR: listwise deletion, ot-deck case substitution, , regressie imputatie geschikt
MAR:modelgebazeerde technieken noodzakelijk
>20%
MCAR: regressiemethode aangeraden.
MAR: modelgebazeerde technieken
-Veeeel meer dan 20% data ontbruikbaar.
MCAR vs MAR en MNAR
Mcar: oorzaak missingess hangt met niets samen. De kans op missing data is gelijk voor iedereen in de sample , Bv computercrash waardoor perongleuk % data verwijderd is. hangt niet samen met iets anders.
MAR: oorzaak missingness hangt samen met andere variabele, binnen subgreoepen ( bv geslacht, leeftijd) zijn ze niet random, bv item neit invevuld door oude mensen, of mensen met een hoog loon.
MNAR: oorzaak missingness hangt samen met ontbrekende waarde zelf, bv inkomensgegeven mssing bij hoogste inkomens, mensen met derpressie vulllen depressie items niet in ( valt niet te testen )
remedieringen missing data : verwijdertechnieken en imputateietechnieken
-listwise deletion ( complete respondent verwijderen)
-pairwise dleetion: per analyse alle beschikbare data gebruiken, n kan daardoor verschillen per analyse,
-variabelen verwijderen.
imputatietechniekn
-hot deck imputatie: waarde overnemen van geljkaardige respondent ( bv zelfde leeftijd, geslacht, … )
-cold-deck imputatie: vanuit externe bron een te verwachte waarde overnemen
-regressie-imputatie: waarde voorspellen via regressiemodel
-last observation carreid forward: laatst beschikbare meting invullen ( bij whithin subjercts designs)
-lineaire interpolatie: tussenliggende waarde schatten uit 2 punten rond missing data
-data bindne: meetmomenten samenvoegen
model gebazeerde technieken: maximul likelyhood
Omgekeerde van kansberekening: normaal vertrek je van een verdeling met gekende parameters en bereken je de kans op bepaalde data. Bij Maximum Likelihood vertrek je van de geobserveerde data en zoek je welke parameters (bv. μ en σ) die data het meest waarschijnlijk maken.
Je kent de meeste waarden in je dataset en gaat ervan uit dat ze uit een bepaalde verdeling komen. Het algoritme probeert dan verschillende parameterwaarden uit en zoekt degene waarvoor de kans op jouw geobserveerde data maximaal is (= de maximum likelihood).
Bij missing data gebruikt ML alle beschikbare informatie om die parameters te schatten. Het algoritme berekent daarbij impliciet wat plausibele waarden zouden zijn voor de missende observaties, maar schrijft die niet echt in de dataset weg.
Daardoor kan je nog steeds gemiddelden, correlaties, regressies, SEM-modellen, ... schatten zonder de ontbrekende waarden expliciet te reconstrueren. Je krijgt dus correcte parameterschattingen zonder eerst een volledig ingevulde dataset te moeten make
multiple imputation.
Stel dat je missing data hebt in variabelen A, B en C.
Eerst worden de missende waarden voorlopig ingevuld met eenvoudige startwaarden (bv. random of het gemiddelde).
Daarna wordt voor elke variabele met missende data een voorspellingsmodel gebouwd:
A voorspellen uit B en C
B voorspellen uit A en C
C voorspellen uit A en B
De nieuw voorspelde waarden worden opnieuw gebruikt om de andere variabelen te voorspellen. Dit proces wordt meerdere keren herhaald (iteratief) (via machine learning technieken;random forest ) waardoor de schattingen steeds beter worden.
Belangrijk is dat dit niet één keer gebeurt, maar meerdere keren. Daardoor krijg je bijvoorbeeld 5 of 10 verschillende volledig ingevulde datasets. In elke dataset zijn de ingevulde waarden licht verschillend, zodat de onzekerheid over de ontbrekende waarden behouden blijft.
Vervolgens voer je dezelfde analyse uit op elke dataset afzonderlijk en combineer je de resultaten. Hierdoor krijg je stabielere en minder vertekende (unbiased) parameterschattingen dan bij één enkele imputatie.
-zie illustatie WPO
Hoe opsporen of data mcar zijn of niet
-visuele inspectie,
-diagnostische tests:
1:bv variabele y is inkomen met veel missing en je vermoedt dat leeftij dmee te maken heeft. Je splits de leeftijd variabele op in 1 groep met missings en 1 groep met geen missing. Dan kijken of leeftijd verschilt tussen die groepen
2:stel inkomen veel missing, je maakt een nieuwe variabele met inkomen ingevuld =1 en inkomen niet ingevuld is 0. Dan ga je kijken of er een correlatie is tussen die variabele en leeftijd. Indien correlatie waarschijnlijk niet random.
3:little Mcar test: verschillen gemiddelden tussen verschillende missingness patronen.Lijken de mensen met missing data op de mensen zonder missing data?
Bv je splits je data op in: greoep 1 geen missingness, groep 2 missings op slaap en inkomen en groep 3 missing op depressieschaal.
Mcar test gaat kkijken of de gemiddelden van die groepen, op de verschillende variabelen waarvan we wel gegeves hebben.
signnicant: geen mcar, niet random
outliers :wat best doen, waar over nadenken?
kunnen grote impact hebben op analyse
-soms geen je voor missiing data in spss een absurd hoge waarde in, zodat je kan zien welke missing zijn, wel belangrijkd dat spss dit ziet als missing waarde en niet oulier ( aangeven)
-indien 1 case door meerdere varaibele als outlier wordt gezien: overweeg om als missing op te geven
-soms is een heel hoge waarde juist interesssant, hangt wat af van je onderzoeksvraag of je behoud of niet, bv je onderzoekt extreme gevallen tegenover algemene patronen.
-senstiviteitsanalyse: je doet je anlayse een keer met of zonder de outlier enkijkt naar de impact op je analyse.
-denk ook altijd na is het een relastische waarde? bv 1000 j oud zijjn.
-je kan ook ouliers behouden maar wees altijd tansparante en doe miss je analyse twee keer ( met en keer zonder)
outliers detectie
-univarieaat: frequentieverdeling, histogram, boxplot, Best boxplot
indien n<80 vanaf z scores groter dan 2.5
indien n >80 , vanaf z scores 3 of 4
-bivarieaat
: spreidingsdiagram ( scatterplot) en beoordeel op zicht
-multivarieaat: melancholisch D² gebruiken ( is afstand van observatie tot midden van alle observaties) en dan doe je D² / df en kijk je naar de t(df) verdeling. en je kijkt of kans kleiner is dan 0.001 ( alpha)
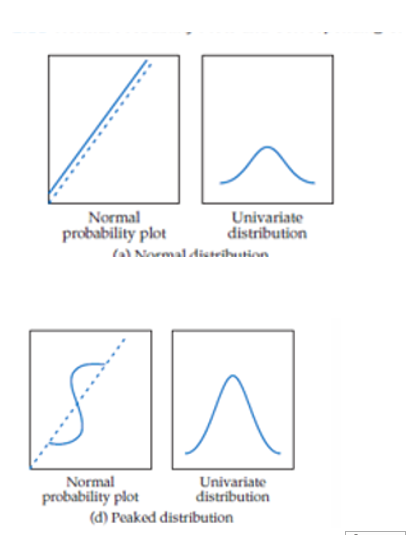
normaliteit
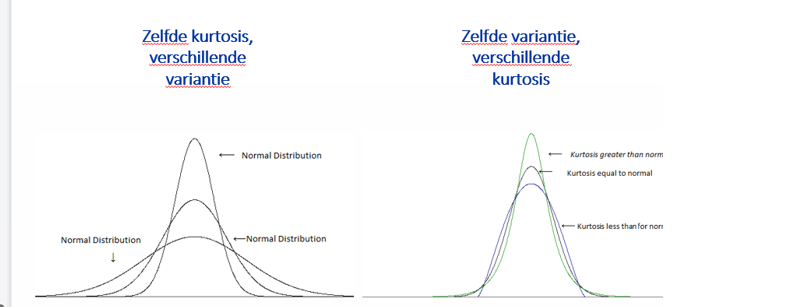
kurtosis en scheefheid zijn niet signicant afwijkend van nul. Let op kurtosis meet ook outlliers, dus kan interperatei beinvloeden.
-kurtosis is platheid , let op veschil tussen andere kuttosis en ander varieantie ( zie afbeelding)
-Kolomogrov smirnoff test: indien signicant, niet normaal verdeeld. Maar bij grote n heel gevoelig dus dan niet vertrouwen.
-grafisch : PP plot, vergelijk cumulatieve verdeling geobserveerde data vs cumulatieve verdeling vd normaalvedeling
-QQ plot: vergelijkt kwantielen van geobserveerde data met kwantielen van verdeling
-
hoe ziet QQ plot eruit
QQ plot gaat Xi (geobserveerde waarden ) uitzettent tegenover genormalizeerde z-scores
-indien mooie rechte lijn: normaal verdeelid en het midden van je punten wolk ligt op gemiddelde zi
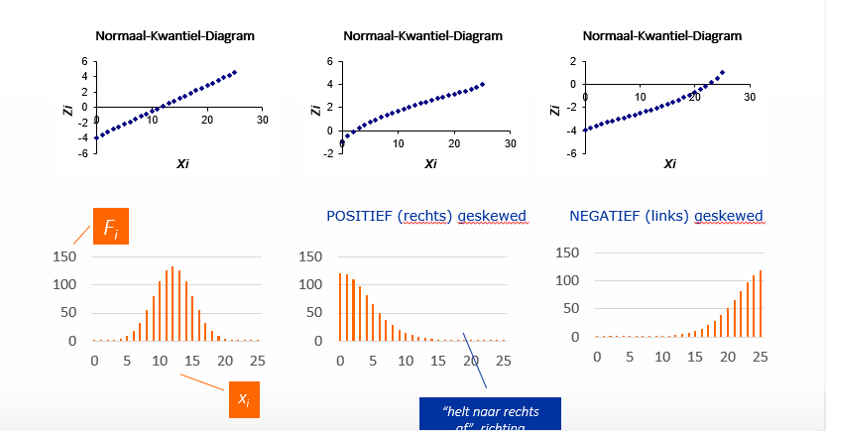
PP plot : ergelijk cumulatieve verdeling geobserveerde data vs cumulatieve verdeling vd normaalvedeling
hoe zit normaal verdeling eruit op deze plot.
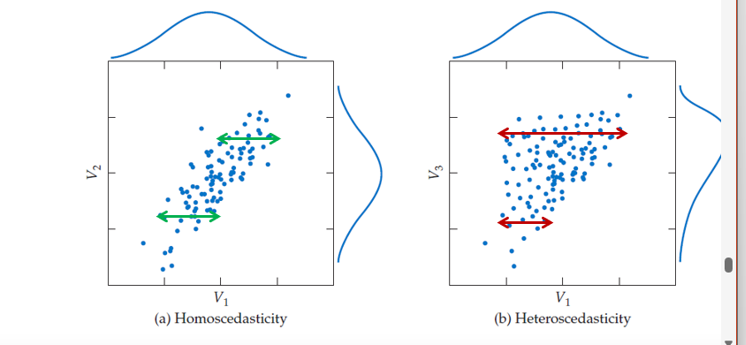
homoscedasticiteit
-of de varienatie in de waarde van de AV ongeveer gelijk zijn voor elke waarde van de OV, dus voor elke waarde van de X-as bijhorende
—>zoneit hetroscedasticiteit,
BV
Bij 2 uur studeren varieert de score ongeveer tussen 8 en 12.
Bij 10 uur studeren varieert de score ongeveer tussen 14 en 18.
Dus de spreiding is telkens ongeveer 4 punten breed.
-checken met scatterplots
lineariteit
verband tussen 2 variabelen is ongeveer een rechte lijn
-diagnose: s hatterplots
-onderwep van discussie: hoe lineair moet iets zijn om nog methode te gebruiken
-in praktijk bijna nooit perfect lienair, maar geneog lineair?
data trasnformatie:
kan remedie zijn indien assumpties niet voldaan zijn;
soms wel moeilijker te interpreten bv stress = 5+2x leeftijd,
-na transformatie stress= 5+2x log ( leeftijd)
machts ladder
-indien gegevens rechts scheef zijn gan je onder op de ladder, indien links scheef naar boven.
-om de macht te vinden waarmee je best transformeert om normaal verdeling te krijgen kanje een box-cox transforamtie doen:
De Box-Cox transformatie doet eigenlijk hetzelfde, maar dan automatisch.
In plaats van zelf te kiezen tussen log(X), √X, X², ... laat je een algoritme zoeken welke macht het beste werkt om je data zo normaal mogelijk te maken.
Die macht noemen ze λ (lambda).
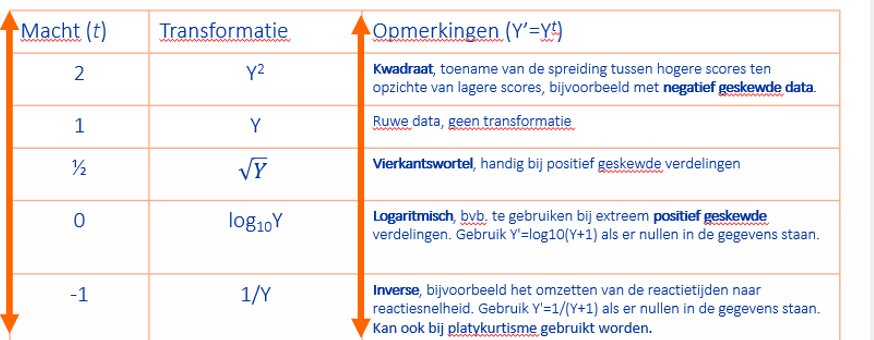
wat is een logaritme en inverse.
-inverse: indien extreem rechts geskwed is of indien playkurtisch ( normaal maat plat) , Bv erge scheefheid rechts is heel typisch bij reactie tijd data. Pas op wel indien je dan inverse pakt dan betekend hoog score nu trager ( zoals bij snelheden ) .
formule is 1/Y maar indien 1 van je y waarde nul is gebruik je 1/Y+1.
Logaritme: tot welke macht moet ik het grontal verheeffen op x te krijgen. die macht is je logaritme.
log-lineair vs log-log

wat is centrering?
-het aftrekken van de gemiddelde waarde vandie variabele van de werkelike waarde voor elke waarde.
-grafiek schuift gewoon op maar varieatie blijft behouden.
-gemiddelde wordt nul.
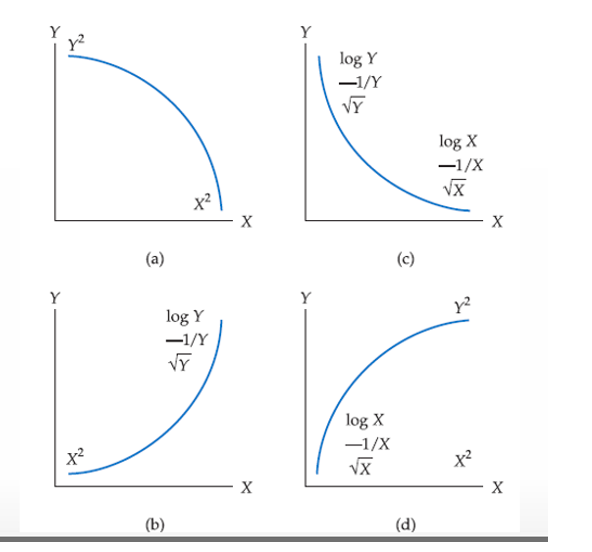
welke trassformatie om een verband terug lineair te krijgen
Mogelijke transformatie |
|---|
Sterk stijgende kromming | X2X^2X2, Y2Y^2Y2 |
Sterk dalende kromming | X2X^2X2, Y2Y^2Y2 |
Afvlakkende kromming | log(X)\log(X)log(X), X\sqrt{X}X, 1/X1/X1/X |
Afvlakkende daling |
dummy-codering
Y=β0+β1D1+β2D2
Dus je hebt:
β₀ = gemiddelde van C (referentie)
β₁ = verschil tussen A en C
β₂ = verschil tussen B en C

WPO Creëer een rangvariabele op basis van populatie (van groot naar klein). Gebruik deze om de 10 landen met de grootste populatie uit je dataset te halen. ( pop: continue variabele ) Hoe zou syntax eruit zien?
RANK VARIABLES=pop_2023 (D) /RANK /PRINT=YES /TIES=MEAN.
▸ (D) = descending (groot → klein)
▸ Nieuwe variabele heet automatisch Rpop_202
▸ /TIES=MEAN → gelijke waarden krijgen gemiddelde rank
TEMPORARY.SELECT IF (Rpop_202 <= 10).
▸ TEMPORARY zorgt dat de filter automatisch vervalt na de eerstvolgende procedure
▸ SELECT IF houdt enkel landen met rank 1–10
▸ Rangvariabele Rpop_202 is aangemaakt in stap 1
TEMPORARY.SELECT IF (Rpop_202 <= 10).CTABLES /VLABELS VARIABLES=country pop_2023 DISPLAY=LABEL /TABLE country BY pop_2023 [MEAN] /CATEGORIES VARIABLES=country ORDER=D KEY=MEAN(pop_2023) EMPTY=EXCLUDE /CRITERIA CILEVEL=95.
▸ KEY=MEAN(pop_2023) = sorteren op gemiddelde bevolking
Geef de totale bevolking weer per continent ( continent = categorisch) en bevolking continue. vizualizeer dit met een staafdiagram.
-( in je dataset heb je per land, telkens pop, in 2023, welk continent ,..)
je gaat gewoon weer Ctales: pop[SUM] by world_4 regions.
-Graph is gewoon BAR(simple) SUM(pop2023) By world 4 regegions.
-je had dit ook kunnen doen via de aggregratie functie kunnen doen
/break=world 4 region /pop2023_SUM(pop 2023)
-zo krijg je een nieuwe variabele die achter elk rij met bv belgie eupra, frankrijk europa al de som gaat zeten van populatie. En dan ook voor bv china asia, india, asia, achter elker rij nieuwe variabele met sum pop voor dat continent. Je krijgt dus meerdere keren zelfde sum in je kolom.
-break betekend: splits dataset op op basis van continent, dan de volgende regel zegt weke berekening je moet doen en die doet die dus apart voor elke niveau van de variabele die je gebroken hebt.
![<p>je gaat gewoon weer Ctales: pop[SUM] by world_4 regions. </p><p></p><p>-Graph is gewoon BAR(simple) SUM(pop2023) By world 4 regegions. </p><p></p><p>-je had dit ook kunnen doen via de aggregratie functie kunnen doen</p><p></p><p>/break=world 4 region /pop2023_SUM(pop 2023) </p><p></p><p>-zo krijg je een nieuwe variabele die achter elk rij met bv belgie eupra, frankrijk europa al de som gaat zeten van populatie. En dan ook voor bv china asia, india, asia, achter elker rij nieuwe variabele met sum pop voor dat continent. Je krijgt dus meerdere keren zelfde sum in je kolom. </p><p></p><p>-break betekend: splits dataset op op basis van continent, dan de volgende regel zegt weke berekening je moet doen en die doet die dus apart voor elke niveau van de variabele die je gebroken hebt. </p>](https://assets.knowt.com/user-attachments/3d46b2b5-1afe-4554-9e8f-1650937cbc71.png)
zijn de geluksscors in lande met hoge ses, lage ses of gemiddelde ses gelukkige, geluksxcore is continue gemeten. inkomen heeft 4 categorien, je moet dit ook ngo recoden naar 3 categorien maak een plot en geef de gemiddelden
-eerst een recode doen
-en dan boxplot hap_2023 by inkomenscategorei.
-dan krijg je een side by side boxplot per inkomenscategorie.
voor gemidelde: means table=hap_2023by inkomenscategorie.
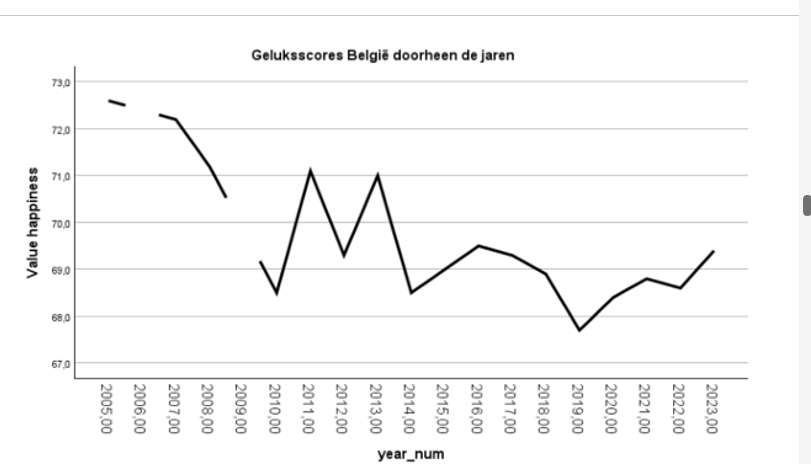
hoe is de geluksscore in belgie geevolueerd doorheen de tijd? je hebt categorische varaible land, en dan verscillende variabelen hap 2023, hap 2022,…
welke grafiek en hoe doe je dat?
-lijn grafiek. maar is moeilik als de variabelen zo staan
want spss ziet geen 1 variabele jaar maar gewoon hap 2005, hap 2006,..
-die keep country zorgt ervoor dat inhet nieuwe databestand enkel country krijgt en niet al de andere variabelen ook
-je kunt best ook miss op voorhand belgie filteren dan krijg je minder lang bestand.
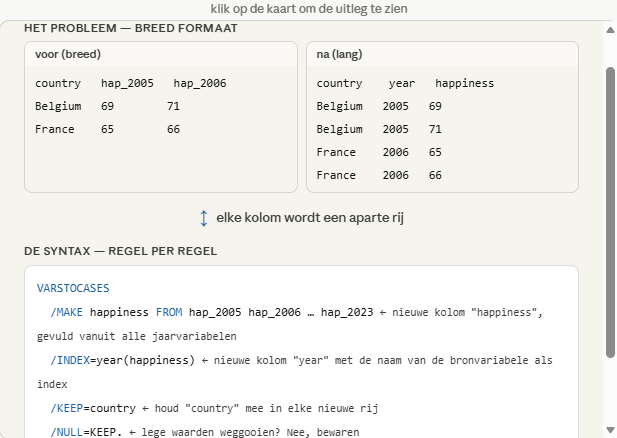
ander voorbeeldje long format
dus nadat je dan die data hebt omgezet in long format voor lijn plot te maken. Hoe ziet syntax eruit voor zo een lijnplot?
De syntax bestaat uit 2 grote blokken:
Blok 1 — GGRAPH: welke data gebruik je?
/GRAPHDATASET VARIABLES=year_num happiness
→ Dit zegt: gebruik enkel deze twee variabelen voor de grafiek. Alles wat niet hier staat, wordt genegeerd.
Blok 2 — BEGIN GPL: hoe ziet de grafiek eruit?
Dit zijn de 4 belangrijkste lijnen:
① X-as:
GUIDE: axis(dim(1), label("Jaar"))
→ dim(1) = eerste dimensie = x-as. Label ervan is "Jaar"
② Y-as:
GUIDE: axis(dim(2), label("Geluksscore"))
→ dim(2) = tweede dimensie = y-as. Label ervan is "Geluksscore"
③ Titel:
GUIDE: text.title(label("Geluksscores België doorheen de jaren"))
→ De titel bovenaan de grafiek
④ Het grafiektype + assen:
ELEMENT: line(position(year_num*happiness))
→ Dit is het belangrijkste. line = lijngrafiek. year_num*happiness = x-as * y-as. Hier lees je dus: "teken een lijn met year_num op x en happiness op y"
Ezelsbruggetje voor het examen:
ELEMENT: line→ type grafiek (line, bar, point...)position(x*y)→ welke variabele op welke asGUIDE: axis(dim(1/2))→ aslabelsGUIDE: text.title→ titel
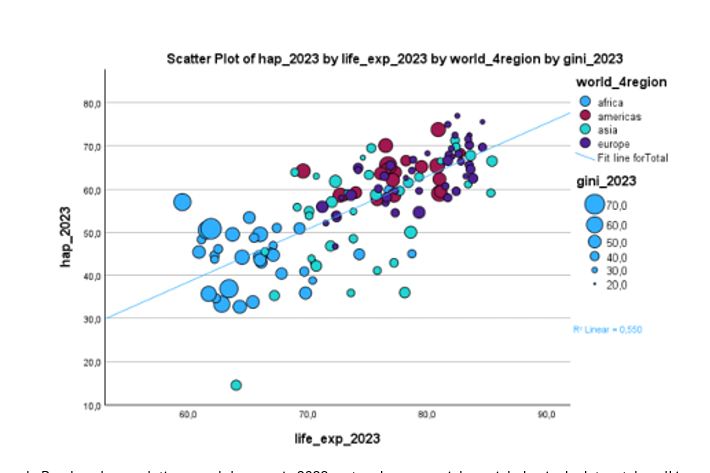
bestudeer de relaties tussen gelukscores 2023 en levensverwachting 2023 ( beide continue) en maak een scatterplot van geluksscores vs levensverwachting. Geef lkeur aan de punten op bais van contintnet ( categorisch) en geef grootte aan de punten op basis van gini index.
je krijgt weer een hele bla bla bla eerst met welke variablen erin zitten
dan weer begin GPL
end an ga je kijken naar
GUIDE: axis ( dim)1: eerste variabele die op x as komt
GUIDE axis (dim) 2: tweede die op y as komt.
Guide: title: welke titel
element: point : scattergrafiek , color inteiro ( world 4 regions), size (gini)
Guide: legend: gewoon hoe legene eruit moet zien.
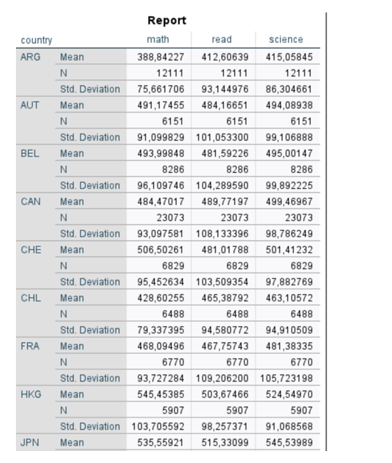
we hebben in een data set pisa scores o pwiskunde lezen en wetenschap, ook staan de landen in de dataset.
geef voor zowel wiskunde, lezen als wetenschap een top 3 van landen die met de hoogste gemiddeld score.
means tables=math read science By country.
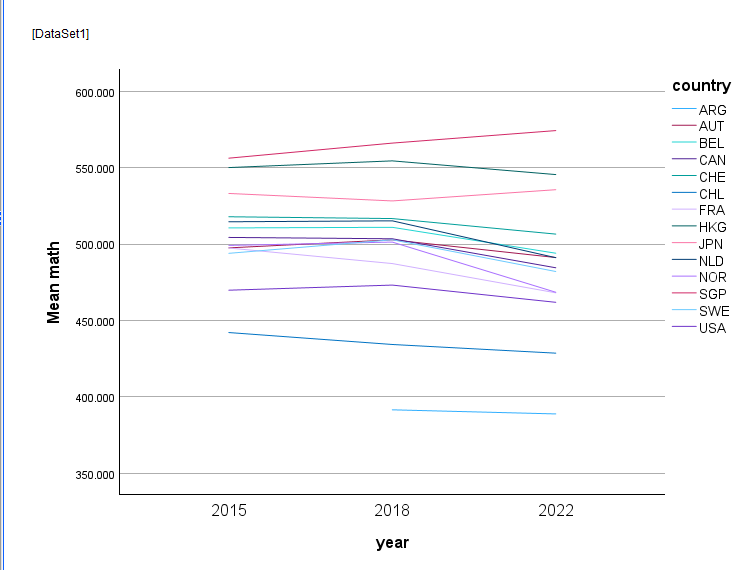
visualizeer de evolutie van gemiddelde wiskunde score ( 1 variabele), over de 3 meetjaren per land
-elke rij in ons bestand is 1 leerling.
-het staat hier dus al in long format
-Graph
/line (multiple)= mean (math) by year by country. !opgelet year moet hier categorisch zijn.
onderzoek het effect van geslacht op leesprestaties in 2022
-eerst filter zetten op 2022.
-T-test groups= gender
/variables = read
dan altijd levene’s test test voor homogeniteit kijken , indien signicant, zijn varieanties niet homogeen.
→dan kijk je naar equel variences not assmpted.
-maar ook altijd na vuistregel kijken deze is belangrijker: indien grootste sdv / klenste sdv <2 dan is het oke.
bij rapportage: t(df) = … , den p : waarde, gemiddeldes. cohens d miss ook.
test of er een daling is in belgie in wiskunde scores van 2015 tot 2022 landen zaijn 1 variabele, wiskunde score is 1 variabele, en jaar is 1 variabele)
-filter op belgie zetten.
-we doen een independatn samples t test want elk jaar worden anderen leerlingen gemeten
Ttest Groups= year ( 2022, 2015)
/variables= math.
vergelijk wiskunde scores uit 2018 met 2022 voor alle landen tesamen ( year 1 variable, land =1 variable , wiskunde scores = 1 variable )
is er een signicante daling.
t test groups ( year 2018 2022)
variables= math
kijk naar de 1 zijdige t toets. En kijk naar de gem
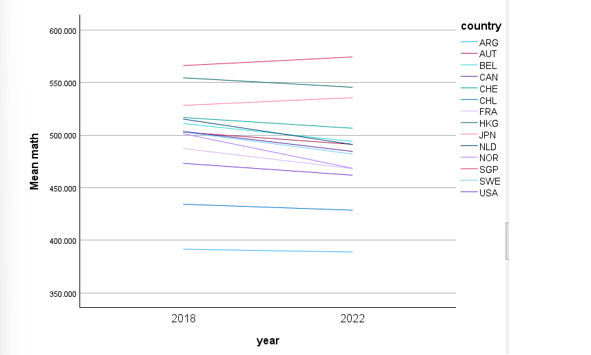
hoeveel landen ( 1 variable) en hoevee llanden laten een stijgng zien in wiskudne scores tussen 2018 en 2022 ( year = 1 variabele)
maak een tabel en vizualizzeer adhv plot
means tables= math BY country BY year
(denk er aan om eerst filter te zetten op year )
/line (multiple) : mean ( math By year BY country
onderzoek de relatie tussen wiskunde scores en en esce visueel ( twee continue variablen )
graph
/scatterplot ( bivar) escs with math.
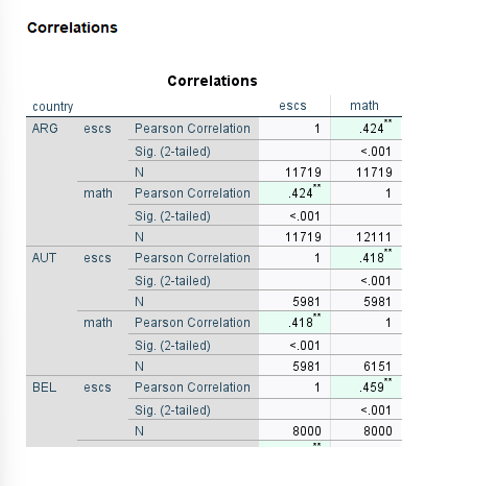
berkeen de correlaties tussen escs enwiskunde prestaties, zijn er landen waar deze correlatie sterke of zwakekr is. twee continue variablee en 1 categorische ( land)
-sort cases By country
( spss gaat nu analyse aprt doen per land)
correlation / variables = escs math
hoe doe je de verschillende transformaties in spss voor het normaliseren van variabelen.
SQRT is wortel

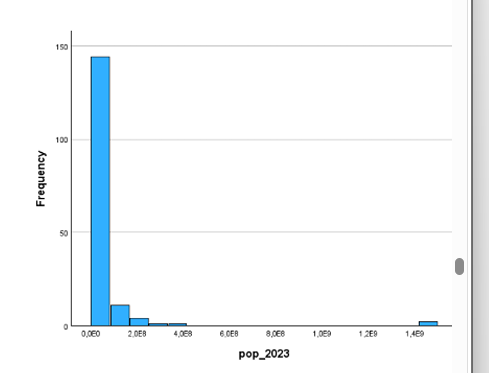
we hadden de variabele: bevolkingsaantal per land. Bevoklingsaantal was scheef verdeeld.welke transoformatie is de beste an waarom?
De kern zit in wat elke transformatie doet met grote waarden.
Het probleem in de grafiek: De meeste landen hebben een kleine bevolking (links gepropt), maar een paar reuzen zoals China/India trekken de staart enorm naar rechts. Dat maakt analyses moeilijk.
Log-transformatie — beste keuze hier
Stel:
België: 11 miljoen → log = 7
China: 1,4 miljard → log = 9,1
Het verschil was 127x groter, na log nog maar 2 eenheden. De reus wordt drastisch ingekrompen, de kleine landen blijven relatief op hun plaats. Scheefheid verdwijnt grotendeels.
Vierkantswortel/derdemachtswortel — matig
België: 11.000.000 → √ = 3316
China: 1.400.000.000 → √ = 37.417
China is nog altijd 11x groter dan België. De staart wordt korter, maar niet genoeg. Werkt beter bij minder extreme scheefheid.
Kwadraat/derdemacht — maakt het erger
België: 11.000.000² = enorm
China: 1.400.000.000² = astronomisch
Grote waarden worden nog groter. De staart wordt langer in plaats van korter. Totaal verkeerde richting.
Vuistregel:
Hoe extremer de uitschieters en hoe schever de verdeling, hoe sterker de transformatie die je nodig hebt. Bij bevolkingsdata met miljarden vs miljoenen is log de enige die sterk genoeg compresseert.
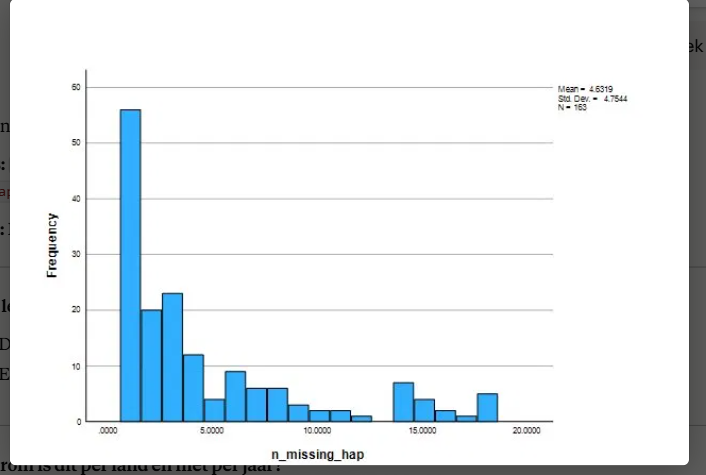
berekend het aantal missings per land ( land 1 variabelen) op de variabele,
-en maak een grafiek en een tabel
compute n_missing/hap= NMISS(hap_2005 TO hap_2023
NMISS is hier een commando
-je bent hier missing data over kolommen heen aan het berkeken dus voor elk land krijg je getal met missing data op de variabelen hap 2005 tpt hap 2023
!je hebt system missing: een cel waar een puntje in staat en user defines missing, wnr je zelf als onderzoekers missing aangeeft door Bv je zegt negeer deze waarneming, behandleing die als missing.
-je krijgt nu een nieuwe kolom met voor elk land het aantal missings.
-dan maak je grafiek via die variabelen graph/histogram=N_missing_hap
-die grafiek toont op de x-as het aantal missings, en op de y- as hoeveel landen.
-stel je zou dit mooi in een tabel willen maken.
dan kan je doen Ctables
/ table country by n_missing (mean )
-die mean maakt hier eigenlijk nie uit want mean van 1 getal is gewoon dat getal.
Maar zo krijg je wel een mooie tabel.
wat zou je doen met 1 uitschieter die exteem onrealistisch is? BV levens verwachting hong kong 0
coderen als missing value
of realistische waarde opzoeken uit andere literatuur.
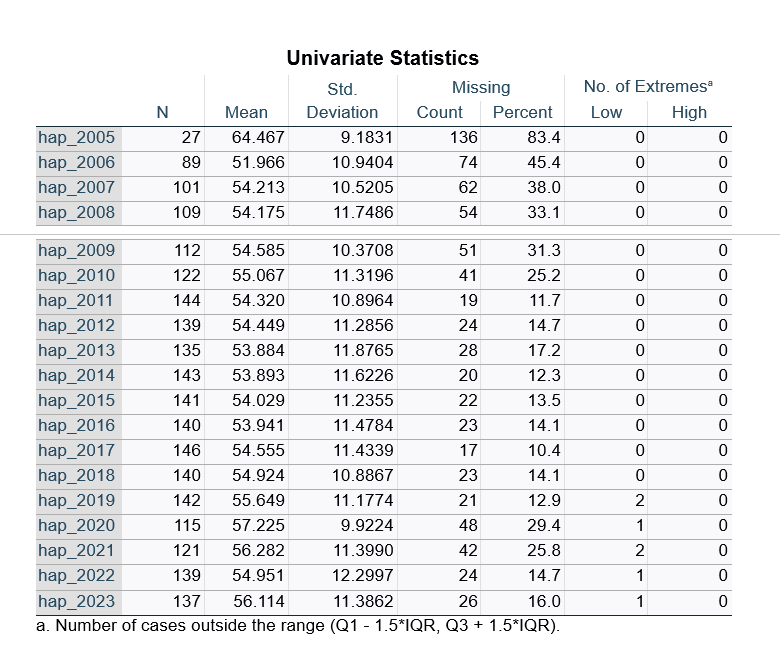
berkeen de missing values per meet jaar
staan in wide format, dus een variable meetjaar 1, meet jaar 2, meetjaar 3,…
MSA variables: hap_2005, HAP_2006, HAPP_2007
→dat is de syntax
—>vervoglens krijg je een MVA tabel.
vizualizeer met een staafdiagram het percentage missings in een jaar.2 manieren, maar 1tje is te omslachtig
probleem, onze hapiness scores staan in wide format ( dus allemaal als aparte variabelen) voor een staafdiagram, moeten we deze dus in 1 variabele krijgen, in long format dus.
—>een gemakkelike manier om dit te doen isdoor gewoon de MVA tabel te kopieren. en te plakken in een nieuw data bestand. Vervolgens kan je dan gemakkelijk met dit databestand een grafiek maken.
-op deze manier moet je geen varcotres doen
: nu stel je zou wel die varcocases, wat je prima kan doen voor in long format om te zetten, dan moet je nadien voor missing data ook nog aggregreen enzo en dat is te omslachter dus coveren we niet in onze cursus
ter herhaling: dit is hoe de varsotocases eruit zou zien
VARSTOCASES /MAKE happiness FROM hap_2005 TO hap_2023 /INDEX=year(happiness) /KEEP=country /NULL=KEEP
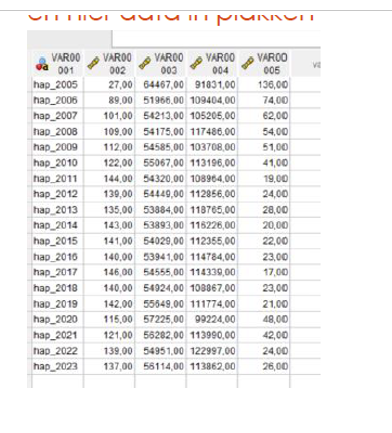
we hebben een data set met verschillende variabelen, we hebben hier een MVA tabel van berekend. Stel dat we nu willen weten, hoeveel observaties hebben complete data op alle variabelen. Je wilt dus niet exact weten oke hoeveel missing data per variable, maar wat zijn de missing ness patronen. Op basis van de tabel die je ziet zou je listwise deletion doen voor iedereen die missing data heeft in smoke?
je typt dan achter de MSA syntex
/Tpattern percent = 1, je krijgt dan een tabel met een overzichtje hoeveel cases missings hebben op geen enkele, hoeveel op bv slaap en BMI,.. door die = 1 tonen ze enkel patronen die bij 1% van de cases voorkomen, en die worden niet getoond, 1% zou voor onze data set 5 cases zijn, indien dat dus maar 5 cases een bepaald patroon hebbben stel dat ze bv missings hebben op BMI en sleep dan worden die dus niet getoond
smoke missiing ness is 14+ 140+ +6 dus smoke variabele heeeft 160 missings, dat is heel veel, listwise deletion zou niet zo een goed idee zij.
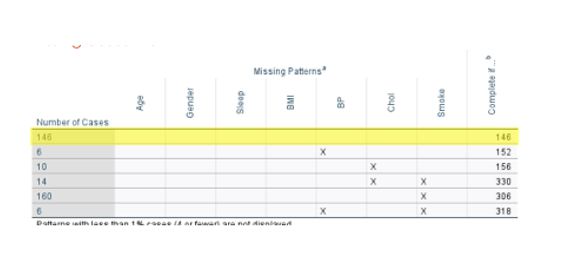
voer de MCAR test op de dataset met variabelen smoke, BMI, Sleep,.. hoe doe je dat, wel enke output krijg je en waar moet je naar kijken. en inzicht in de MCAR test
je typt gwn achter MVA syntax
/EM ( tolerance,… ) Nu ga je weer die MVA tabel zien, summery os estimated means and standard deviatons
-deze tabellen vergelijken het gemiddelde van alle value’s beschikbare data met de schatting expectation maximization. Indien daar weinig verschillen op zijn al indicatie dat missing data weinig impact heeft op gem. ( zelfde voor STD)
-de laatste drie tabellen EM means, EM covarieances en Em correlations zijn geschatte gemiddelden, varieanties en correlaties op basis van alle data inclusief missnigs via Em algoritme.
-maar je gaat bij die Em tabellen vooral kijken naar de foodnote daar staat je MCAR test.
-indien signicant missings zijn niet mCAR maar MAR of MNAR
-ML schat de beste verdeling voor je data en stelt zich dan de vraag als de missings volledig at random zijn , zou de verdeling van mensen met een waarde en mensen met een missing gelik moeten zijn.
concreet: schat de verwachte gem en covarieanties , vergelijkt die met de geobserveerde gem per missing patroon, als die veel van elkaar afwijken —>niet random
wat zijn je volgende stappen indien signicantie of niet signicantie
het is randsignicant dus net niet signicant dus we vertrouwen het toch niet helemaal en gaan dus moeten kijken welke MAR strategei we gaan toepassen.
-Hiervoor gaan we eerst een aantal missings indicatoren maken voor elke varaibele: dus indien missing= 1, indien niet is 0
COMPUTE bp_missing = 0. IF MISSING(BP) bp_missing = 1. COMPUTE chol_missing = 0. IF MISSING(Chol) chol_missing = 1. COMPUTE smoke_missing = 0. IF MISSING(Smoke) smoke_missing = 1. EXECUTE.
-dan gaan de de correlaties tussen al die missing variabelen berkenen en alle gewone variabelen.
waarom doen we dit? hierdoor kunnen we dus gaan kijken welke variabelen mogelijke mar patronen hebben en welke mcar patronen
workflow missing data wpo
-dus eerst ga je altijd kijken naar heoveel missings via mva
-dan voer je de mcar test uit, indien deze signicant is ga je missingness patronen onderzoeken via correlatiematrix en zo kan je besluiten welke strategie je gebruikt
dus op basis van hoeveelheid en of het mar of mcaris kan je dan kiezen welke imputatiestrategie je volgt.
aandachts punt little mcar test
h0:data is consistent met mcar
-dit is een hypothese toets waarbij je hoopt H0 niet te verwerpen, dit is dus een zwakke hypothese toets, waarbij deze extra gevoelig is bij grote steekproeven en ongevoelig bij keline steekproeven voor afwijkingen van MCAR
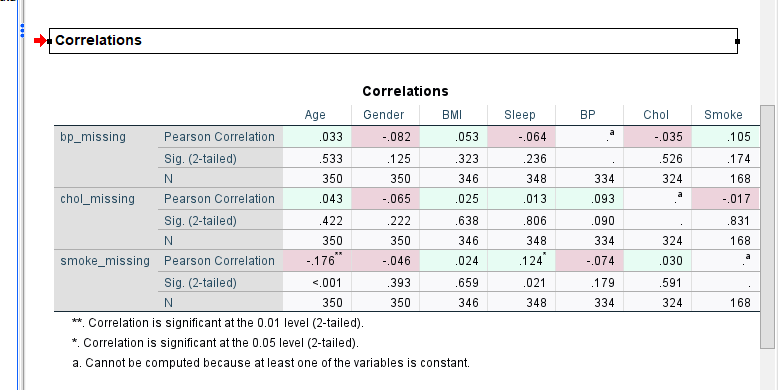
correlatiematrix missingness: wat kan je op basis van dit concluderen? Mnar ?
smoke hangt signicant samen met age en sleep , neg met age en psoitef met slaap .
-dus jongeren zijn minder geneigd te antwoorden op rook vragen en mensen die meer slapen zijn ook minder geneigd om te antwoorden op rook vragen.
-de andere variabelen zij nniet signcant: wat wijst o mcar relaties, maar kan je nooit volledig uitsluiten want miss komt het door variabelen die we niet getest hebben
-Ook kan je niet uitsluiten dan er Mnar patronen zijn want dit kan je niet testen. Aanwijzingen kunnen soms zijn gevoelige items, zelfrapportage met consequenties, rapporteer dit dan ook als liminatie.
Mean imputation: hoe doe je dit ( syntax) en kanttekening
-voor elke variabele ga je
COMPUTE BP_mean_imp = BP.
COMPUTE BP_mean_imp = BP.
IF MISSING(BP_mean_imp) BP_mean_imp = 121.5569.
EXECUTE.
→ Maak een nieuwe variabele BP_mean_imp en kopieer daarin alle waarden van BP. Dus voorlopig zijn ze identiek.
IF MISSING(BP_mean_imp) BP_mean_imp = 121.5569.
→ Als de waarde in BP_mean_imp missing is, vervang die dan door 121.5569 (het gemiddelde van BP).
-het gemiddelde van elke variabele na impuataie blijft hetzelfde maar de spreiding zal veranderen, namelijk kleiner omdat iedereen met missing zelfde waarde krijgt en daardoor minder verspreid.
median impuatatie , hoe en kanttekening
compute is zelfde als bij gem alleen nu mediaan waard ingevuld en gem in med veranderen
-gemiddelde zal wellicht veranderen en spreiding kleiner worden
complete case missing = listwise deletion
hierbij ga je gewoon alle cases met missings verwijderen
regressie imputatie , hoe en kritische kanttrekenin g
hier bij ga je per variabele eigenlijk een voorspelling maken op die variabele met alle andere variabelen.
die voorspelling sla je op
-krijg je bv BP_predicted variabele.
-dan doe je een compute: BP_REG_IMP= BP IF missing (BP_REG_IMP) BP_REM_IMP= BP predicted.
-dit gaat je betere schattingen geven voor mediaan en gem dan de andere methoden.
-Maar het nadeel is wel indien dat die case ook missings heeft op andere variabelen kan voorspelling niet gemaakt worden en ga je soms nog missings overhouden .
multiple imputation
SET SEED = 12345. DATASET DECLARE nhanes_imputed. MULTIPLE IMPUTATION BMI Age Gender Sleep BP Chol Smoke /IMPUTE METHOD = AUTO NIMPUTATIONS =20 MAXPCTMISSING = NONE /MISSINGSUMMARIES NONE /IMPUTATIONSUMMARIES MODELS /OUTFILE IMPUTATIONS =nhanes_imputed . DATASET ACTIVATE nhanes_imputed.
-dus je gaat vragen aan spss om multiple imputation te doen, en hij gaat dit 20 x doen.
Laat me het vereenvoudigen. Bij multipele imputatie in SPSS zijn er eigenlijk maar 3 dingen die je moet doen en bekijken:
Stap 1: Imputeer de dataset Analyze → Multiple Imputation → Impute Missing Data Values → 20 imputaties
Dit maakt een nieuwe dataset nhanes_imputed met een extra kolom Imputation_ (0 = origineel, 1-20 = geïmputeerde datasets).
Stap 2: Voer MEANS uit op die nieuwe dataset
MEANS TABLES=BP Chol Smoke
/CELLS=MEAN COUNT STDDEV SEMEAN SEKURT.
Stap 3: Kijk enkel naar de "Pooled" rij onderaan
Je krijgt een lange tabel met rijen voor imputatie 1, 2, 3... t/m 20. Negeer die allemaal. Scroll naar beneden naar Pooled en kijk enkel naar:
Wat | Waarom |
|---|---|
Mean | het gecombineerde gemiddelde over alle 20 imputaties |
Std. Error of Mean | de gecorrigeerde standaardfout |
De drie extra statistieken zijn bonusinformatie:
Fraction missing info → hoeveel onzekerheid komt door de missings
RIV → hoe sterk verschillen de 20 datasets van elkaar (groot bij Smoke want 52% missing)
Relative efficiency → 0.998 = prima, 0.976 = nog OK maar missingness is hoog
-Je gaat dus net zoals bij de rest een mean en std error of mean kunne bekijken, std ga je wel niet kunnen bekijken.
welke imputatiemethode ondrschat varieantie het meest en waarom?
mean/mediaan imputatie onderschatten het het meest
, dit is problematisch want kleine spreiding, kleinere standaafdfout, type 1 fouten!
-uitzondering bij binarie variabele ( 0/1)
-mediaan= 0, of 1, minder schade
-gemiddelde: bv 0.43 is een onmogelijke waar de dus verkleint uw spreiding enorm.
waarom is regressie-imputatie betere maar niet perect
-beter omdat het de relatie tussen variabelen gebruikt, bv mensen met hoge leeftijd hebben vaker hoger BP, dus realistische schattingen van missing waarden
-maaar residueele varieantie ontbreekt: regressie voorspelt de meest waarschijnlijke waarde, maar echte data heeft nog altijd wat ruis wat hier niet meergenomen wordt. Bv je voorspelt voor iemadn die zo oud is met die BMI, deze waarde, maar de echte waarden kan er altijd nog een beetje rond liggen.SE blijft de klein
—>multiple imputation ishier een oplossing voor.
-modelaannamens kunnen fout zijn: regressie gaat ui van lineariteit en homoscedastciteit , bij smoke 0/1 klopt daarom een regressie voorspelling niet. Eigenelijk zou je logische regressie daarvoor moeten gebruiken.
Waarom is het effect van imputatie op de variantie groter bij Smoke dan bij Chol of BP
Hoofdregel
Hoe groter het % missing → hoe meer kunstmatige waarden geïmputeerd worden → hoe groter de impact op de variantie.
Vergelijking
BP
4.57% missing
klein effect
Chol
7.43% missing
matig effect
Smoke
52% missing
groot effect
Waarom Smoke het ergst?
Bij mean imputatie krijgt meer dan de helft van de cases dezelfde waarde (bv. 0.43) — een onmogelijke waarde voor een 0/1 variabele. De SD daalt naar 69% van het origineel en de SE halveert bijna.
→ Grote kans op vals-positieve resultaten in verdere analyses.
voordleen van multiple imputation
beste van alle methoden, SD blijft vergelijkbaar bij complete case analyse SD.
-de 20 datasets reflecteren verschillende plausibele scneario’s voor missende waarden.
Eerlijke SE: want houdt zowel rekening met vaireatie tussen als binnen dtasets ( rubins poooling-)
-BI’s en P’s zijn niet kunstmatif klein
Bv bij mean imputation was se 0.0184 en bij MI 0.035
—>multiple imputation zorgt voor grotere maar meer correctere SE’s. en dus correcte p’s en BI’s.
-Bij mean imputation is die te klein dus grote kans op vals positieven.
—>MI geef ttoe dat we niet zker weten wat missende warden zijn en past die ondzekrheid toe bij SE.
grenzen van imputatie: variabele 52%, waarom problematisch?
-als je bv 48% missing data hebt dan schat je op basis van minder dan de hleft, meer dan de helft, gaat nooit echt betrouwbaar zijn.
-MI kan wel informatie betrouwbaardere informatie geven maar als je zo weinig informatie hebt gaat het ook geenmagische dingen kunnen voorspellen.
-ook hoe meer je imputeerd hoe meer je vertrouwd op modelaannamens van het is mcar, mar,. Bij 52% missing heeft een kleien fout in die aannamens een enorme impact op je resultaten.
-te onzekerheid wordt extrem groot: zie relative increase in varieance= 102% ( meer verschillen tussen imputatie binnen elke imputatie.) dit kon je zien bij je MI van smoke. De varieantie tussen de imputaties is groter dan de varienaite binnen elke imputatie. Grote onzekrheid.
algemene overwegignen, bij hoge missingness: sensititviteits analyse
-indien een variabele meer dan 20% missing data heeft, best de verschillende imputatie anlayses uitvoeren en kijken hoe ze verschillen, als de conclussies sterk verschillen zijn je resultaten niet robuust en moet je voorzichtig zijn met interpretatie.
-overweeg dan miss varaibele uit te sluiten tenzij die echt belangrijk is voor je onderzoeksvraag of je kunt aantonen dat MAR plausibel is.
anova: fixed vs random OV, welke methode?
-hoeveel interactie effecten bij two way anova? (formule hiervoor) , en wat beinvloed F.
-de categorische OV= fator, deze kan fixed zijn bv 3 niveaus die wij hebben bepaad of random zijn ( Bv vijf willekeurige professoren en elke professor geeft les aan groep studenten, de professor is de random factor, of je trekt bv 4 willekeurig geozen meetmomenten,..)
voor fixed: ordinary least square
-voor random :maximmul likelyhood estimation ( maar gan we niet doen)
-F: toets: hangt af van vaireantie tussen groepen, binnen groepen en steekproef grootte ( bij grote n , kritische f waarde daalt, sneller signicant)
-one way anova: 1 OV
-two way anova: 2 OV, ga je ook interactie effect hebben.
N-way anova: meer dan 2 OV variabelen.
(2^n -n -1= aanal interacties )
side note anova: wat zijn vrijheids graden + 2 voorbeelden.

capitalizing on chanc bij anova
-inflatie type 1 fout, maar soms zijn je correcties zo sterk edat je ook tupe 2 fouten krijgt. dus soms wat afhankleijk van de context. (BV Kankerbehandleing, veel of minder bijwerkingen)
assumpties anova
anova gaat uit van homoscedasticiteit tussen groepen: gelijke varieanties:
-kan je testen adhv levene’s test maar gevoelig voor kleine veschillen bij grote n.
-daarom vuisregel belangrijker: grootste s / kleinse moet kleiner zijn of gelijk aan 2. Indien groter niet oke.
-dit is belangrijk omdat we onze s² gaan poolen waarbij we grote groepen meer laten doorwegen bij de schattinge van s² , En dit kan enkel indien de assumptie van homoscedasticiteit is voldaan.
-en normaliteit AV
-en onafhankleijkheid.
sidenotes formules one way anova.
-SSt in woorden: afwijkingen van elk datapunt tot de grand mean
(y00: grand mean, ,yi0: groepsgemiiddeld, )
SSB: afwijkingen van elk groepsgem tot grand mean, gewogen met groepsgrootte.
SSW: elk individuele score in dataset gekwadrateerd en optellen - voor elke groepsgem gewogen met groepsgroootte.
schatter voor µi ( pop gemiddelde) is Ystreep ( groepsgem steekrpeofà
indien je geen ruwe data hebt is grand mean: n1xgroepsgemiddelde+n2x groepsgemiddelde2 +n3x Groepsemiddelde3 / N
s²=elke kwadratische afwijkingen tot het gemiddelde.gewogen volgens groepsgrootte.
contrasten:indien je op voorhand al verwachting had van waar het verschil zou liggen.
Wat is een contrast?
Een contrast is een gewogen combinatie van groepsgemiddelden. Je kent aan elke groep een gewicht (a) toe, en telt alles op.
Twee belangrijke regels voor die gewichten:
Ze moeten samen optellen tot 0
Groepen die je niet wil betrekken krijgen gewicht 0
Voorbeeld: je hebt 3 groepen (controle, behandeling A, behandeling B) en je wil groep A vergelijken met groep B, en controle buiten beschouwing laten:
Controle → gewicht 0
Behandeling A → gewicht +1
Behandeling B → gewicht −1
Som: 0 + 1 + (−1) = 0 ✓
Orthogonale contrasten
Twee contrasten zijn orthogonaal als ze totaal verschillende vragen stellen en elkaar niet overlappen. Je test dit door de gewichten van de twee contrasten per groep te vermenigvuldigen en op te tellen — dat moet 0 geven.
Waarom belangrijk? Orthogonale contrasten zijn onafhankelijk van elkaar, dus je hebt geen overlap in wat je test.
anders kans type 1 fout, de contrasten staan loodrecht op elkaar.
Hoe toets je een contrast?
Je berekent de contrastwaarde en toetst die met een t-toets om te zien of het verschil significant is.
—>je kan zelf contrasten maken of voor gepecifieerde contrasten gebruiken.
soorten contrasten
-deviatie contrasten: elke groep vs gemiddelde van andere groepen. 3, -1, -1 ,-1 (en dat voor elke groep)
!deze contrasten zijn eigenlijk niet orthogonaal: je kan niet verwachten dat 1 groepp beter is dan de rest en dat groep 2 beter is dan de rest.
-eenvoudige contrasten: verelijk groep 1( 1) met groep 2 (-1) , de rest krijgt nul.

herhaalde/verschl contrasten ,helmert contrasten, plynomianle contrasten
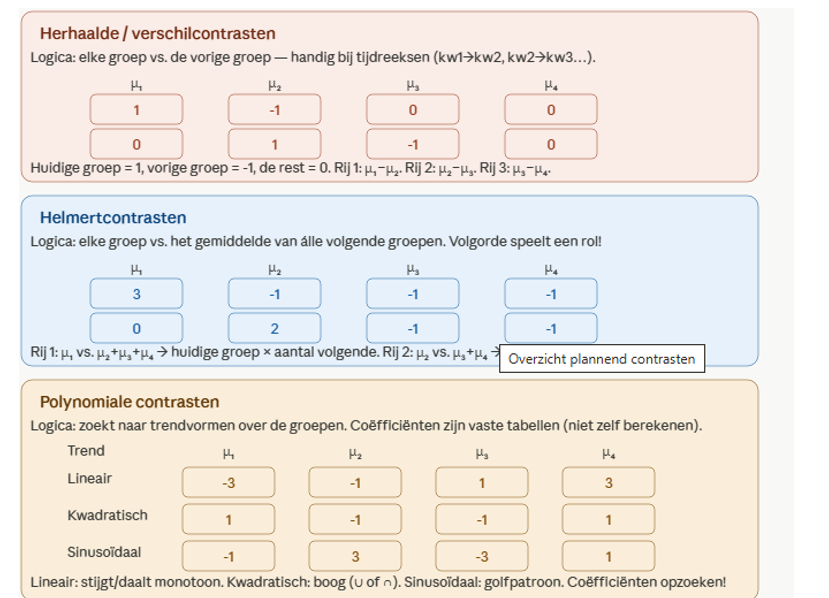
onderzoeksvraag vs contrasten om de logica te zien
-deviatie: wikt groep 4 af van al de rest ( die krijgt cijfer 3 de rest -1)
eenvoudige contrasten: elke groep vs een vase referentie groep. groep die je test krijg 1, de andre -1, rest 0
herhaalde : is de stress van studenten veranderd van t1 tegenover t2, van t 2 tegenover t3, .. je schuift telkens de 1 en -1 op
-lalle groepen vs alle volgende groep: eerst vs rest, tweede vs rest: is reactie bij 0 cafeien lager dan 100, 200 en 300. en is 100 lager dan bij 200 en 300.
meervoudige vergelijkingen.
-je ehbt een basis formule voor de t toets
-maak je gaat wat correcties doorvoeren.
LSD: least signicant difference: geen correctie gewoon alpha gebruiken zoals het is ( bv bij pilot studies)
-bonferonni: alpha dleen door aantal vergelijkingen. BV 4 groepen, 6 vergelijkingen.
( is zeer streng)
meervoudige vergelijkingen tukeys HSD
bij geljke gropeen gewone tukey, bij ongelijke groepen turkey kramer ( hierbij wordt n een harmonsiche n)

bonferonni holm
is een goede balans tussen bonferonni en LSD
-dus je ordend al je p waarden van klein naar groot
-stel je hebt 6 paren, dus 6 pwaarden. Bij eerste paar doe je p/6.
Bij het volgende paar p/5.
vanaf het moment dat iets niet meer signicant is stop je.

rappporteren anova.
F(df_between, df_whithin)
en de effectgroote: verklaarde e varieantie is de n²partila
n²partial is analoog aan R² bijregressie.
-zie formule formularium.
-0.01 (klein), 0.06(medium) 0.14 groot) : hoeveel je model verklaard.
bootstrapping , jackniving , permutatie
Bootstrapping is de meest gebruikte. Het idee is: je hebt één steekproef van bijvoorbeeld 50 personen, maar je wil weten hoe betrouwbaar je gemiddelde (of F-waarde) is. Wat doe je? Je trekt duizenden keren een nieuwe steekproef van 50 personen — maar dan uit je eigen data, mét terugleggen. Dat betekent dat sommige personen twee of drie keer kunnen opduiken in een nieuwe steekproef, en anderen helemaal niet. Zo bouw je een verdeling op van je statistiek, en daaruit bereken je betrouwbaarheidsintervallen of p-waarden. Je ziet dit ook terug bij mediatie in JASP.
Jackknifing is eenvoudiger maar ouder. Je laat telkens één persoon weg en herberekent je statistiek. Met 50 personen doe je dat dus 50 keer. Daarna kijk je hoeveel je uitkomst fluctueert afhankelijk van wie je weglaat. Dit vertelt je vooral hoe stabiel je resultaat is en of er invloedrijke uitschieters zijn. Het is eigenlijk een robustheidscheck.
Permutatie is conceptueel het meest elegant. De vraag is: als er echt geen effect is en groepslidmaatschap niets uitmaakt, wat verwacht je dan? Je gooit alle groepslabels door elkaar, herbereken je F-waarde, en doe dat duizenden keren. Zo bouw je een exacte nulverdeling op die specifiek bij jouw data past — geen aannames over normaliteit nodig. Je echte F-waarde vergelijk je daarna met die verdeling.
Binnen ANOVA gebruik je deze methoden vooral als je kleine steekproeven hebt, je normaliteitsaanname geschonden is, of je mediatie-effecten wil testen (daar is bootstrapping standaard
niet parametische methoden.
Stel je hebt drie groepen en je wil weten of hun gemiddelden verschillen, maar je data is scheef verdeeld of de varianties zijn ongelijk — dan mag je eigenlijk geen gewone ANOVA gebruiken.
Kruskal-Wallis is de oplossing. In plaats van te rekenen met de ruwe scores, zet je eerst alle scores om naar rangnummers. De laagste score in je hele dataset krijgt rang 1, de op-één-na-laagste rang 2, enzovoort. Daarna doe je de ANOVA gewoon op die rangen. Omdat rangen altijd netjes verdeeld zijn, hoef je je geen zorgen meer te maken over scheefheid of ongelijke varianties.
Het nadeel is dat je iets van gevoeligheid verliest, want je weet niet meer hoe groot de verschillen tussen scores precies zijn — alleen wie hoger of lager scoort.
Het belangrijkste praktische advies van deze slide: voer altijd beide uit en vergelijk. Als gewone ANOVA en Kruskal-Wallis tot dezelfde conclusie leiden, is je resultaat betrouwbaar. Wijken ze af, dan klopt er iets niet met je data. want ze testen gewoon eens shift in je data.
ancova: Bv kan leeftijd stukje van verschil in loon tussen mannen en vrouwen verklaren. (miss zijn de mannen gewoon ouder en daardoor hoger loon)
-is een anova+1 of meer continue covariaten waarvoor je controleert. Je zuivert de AV van de invloed van je covariaat, waradoor je foutvarieantie kleiner wordt en je meer powerk rijgt.
SSt= SSB+SS_covarieaat+SS_nnieuw
(ss-COVARIEAAT =( voorspelde loon adhv van leeftijd - grand mean) opgeteld en gekwadrateerd. (wat de covarieaat verklaard )
SS_nieuw( voorspelde loon adhv van leeftijd-werkleijke loon ) opgeteld en gekwadrateerd. Het stukje dat de covarieaat niet verklaard.
-effectgrootte: SSB/SSB+SS_nieuw.
-model: intercept+biB (effect van covarieaat op leesvaardigheid), b2A(effect van leesmethode op leesvaardigheid) +e ( resterende fout)
voorbeeld ancova uitwerking : is er nog steeds een loonverschil tussen mannen en vrouwen, rekening houdend met leeftijd.
-je berekend een regressie van leeftijd op loon.
dus bv loon= 2000+50xleeftijd ( elk jaar ouder 50 euro meer )
je berekend de residuen tussen werkelijk loon van een persoon en voorsppelde loon= residu= loon gezuiverd van leeftijd
-je neemt al die residuen er terug bij en gaat ze terug onderverdleen in je groepen. En daar het gemiddelde van nemen. (residuen zijn het stukje dat leeftijd niet voorspeld krijgt)
-je doet opnieuw een anova op die residuen.
-wat zeggen die gemiddelde residuen: bv voor vrouwen -83,3 vrouwen verdienen gemiddelde 83, 3 euro minder dan verwacht op basis van leeftijd. En mannen resdiuen 250 verdienen gemiddeld 250 meer dan verwacht op basis van leeftijd.
hiervoor was het verschil tussen mannen en vrouwen 600 euro heel veel.
Na correctie voor leeftijd zien we dat het verschil (250-(-83)= 333 is. Nog altijd een verschil maar nu gecorrigeerd voor leetijd.
two way anova
je hebt hier 2 OV factoren.
je kan zo interacties ontdekken: is leesmethod anders bi meisjes dan jongen.
-als je een factor niet opneemt die wel een effedct zo kunnen hebben valt dat onder ons residu.
-factor A met r niveaus
facotr B met s niveau’s.
r x s anova: Bv 2 × 3 anova.
N= optel som van elke n binnen elk vakje. ( denk aan RMT)
statistisch model two way anova
Yijk: waaneming voor deelnemer k in cel (i ,j )
= µ +hoofeffect factor A op niveau i, +hoofdeffect factor B op niveau j+ interactie effect a x b + residue.
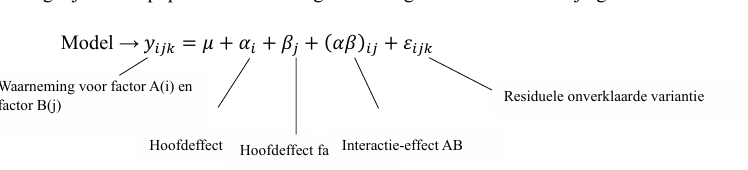
two way anova tabel: en de verschillende effecten
-en hoe zit dat bij een 2 × 3 design?
-hoofdeffect A: verschillend de marginale gemiddelde signicant
-hoofdeffect B: verschillende de marginale verschillen signicant?
-interactie effect: berkeen verschil tussen de eenvoudige effecten van 1 niveau a(meisjes) en het ander niveau van A (jongens) , is dat verschil signicant?
-bij bevoorbeeld een 2 ×3 design moet minstens 1 verschil binnen de eenvoudige effecten verschillend zijn van de rest. (zelfde voor hoofdeffect)
is een 2 ×3 design between of whithin ?
-dat weet je niet notatie zegt eit hoe de data verzameld is , bij between subnjects zit elke persoon in 1 cel bij whithin kan die in meerder cellen zitten.
varieantie ontbinding anova. : de formules in woorden en notaties
y000
y0j0
yi00
yij0
yijk
r, s , n
-globaal gemiddelde, cmarginaal gemiddelde A, marginaal gemiddelde B,
, celgemiddelde,
score van persoon k in niveau i van A en niveau j van B
r= aantal niveau factor A, s aantal niveau factor B,
n aanta personen per cel. ( let op in die cellen staat nie de n, dat is gemiddelde van die groep)
SST= ssa+ssb+SSaxb +SSwhitin
SST: kwadraten som van alle waarnemingen rond yijk rond de grand mean
SSA/ kwadratensom van de afwijkingen van de gemiddelde van de niveau ( dus de marginal means ) rond gemiddelde grand mean
-SSAXB: hoeveel cel gemiddelden afwijken van de gran dmean met de varieantie verklaard door en b verwijderd.
-SSW/ varientie van de waarnemingen yijk rond hun specifiek groepsgemiddelde.
formules ssa, ssab en sse , pak formularium erbij en probeer in woorden om te zetten.
SSA meet het hoofdeffect van factor A. Je neemt het gemiddelde van elke rij van A (ȳᵢ₀₀) en trekt daar het totaalgemiddelde van af. Als A geen effect heeft, liggen alle rijgemiddelden dicht bij het totaalgemiddelde en wordt SSA klein. De s·n vooraan is er gewoon omdat elk rijgemiddelde gebaseerd is op s×n personen — je vermenigvuldigt om terug te schalen naar de totale som.
SSAB meet de interactie tussen A en B. Het idee is: het celgemiddelde (ȳᵢⱼ₀) minus wat je zou verwachten op basis van alleen het hoofdeffect van A en het hoofdeffect van B. Als er geen interactie is, kun je een celgemiddelde perfect voorspellen uit de rijgemiddelden en kolomgemiddelden samen — dan is SSAB nul. Is er wél interactie, dan wijken de celgemiddelden af van die verwachting, en wordt SSAB groot.
SSE meet de residuele variatie — de ruis binnen elke cel. Je neemt elke individuele score (yᵢⱼₖ) en trekt het gemiddelde af van de cel waar die persoon in zit (ȳᵢⱼ₀). Dit is variatie die niet door A, B of hun interactie verklaard wordt — gewoon individuele verschillen binnen dezelfde conditie.
De F toets two way anova
-je gaat telkens delen door MSE.
je krijgt dus ook 3 ftoetsen 1, voor hoofd effect A, 1 voor B en intteractieeffect.
grafieken waar op letten,
-probeer altijd een denkbeeldige lijn te trekken tussen punen op A1 n punten op A2. pak het middne daarvan, liggen die op zelfde hoogte Y-as ? geen hoofdeffect A
Voor B pak het midden van de ene sttreep en het midden van de andere streep liggen die o pzelfde hoogte y -as? geen effect B
-indien niet parralel interactie effect.
wat als je een continue variabele dus je AV, geskweded is? wat is het effect van transformeren, hoe lossen we het op?
dit is een voorwaarde voor anova, dat di normaal veredeeld is
-daarom transformeren: je kan bv inverse bereken
-belangrij k je doet dat op al je ruwe scores.
-nadien ga je dan zo terug de celgemiddeldes berekenen.
Maar probleeem zonder transformaitie vinden we interactie maar mett niet.
-beide zijn wiskundig correct op hun eigen schaal
-waarom verdwijnt die interactie na transformatie?
omdat inverse comprimeert voor grote waarde, dus verschillen tussen de eenvoudige effecten worden kleiner
-daarom best niet-parametische tes gebruiken om dit probleem te voorkomen.
one way repeated measured: wat is het en varieantie ontbinding
-je hebt weer 1 factor maar iedereenkrijgt hier alle conditiees, dus whithin subjects design
-SStotal= ss effects+SSsubjects+ SSleftovererror
-SS error wordt kleiner want je meet jan nu in alle condities en je ziet dat jan altijd hoog scoort, peit altijd laag, je kan dus de personenvaraibliteit eruit halen, dus error term verminderen
-Ook heb je grotere N en grotere power.
asssumpties
-bij gewone anova is onafhankleijk observaties heel belangrijk, maar bij repeated measured zijn die nie onafhankleijk , daarom vereistt het een extra assumtpei spherecity
Sfericiteit betekent dat de variantie van de verschillen tussen meetmomenten overal even groot moet zijn — dus het verschil tussen moment 1 en 2 mag niet veel … niet veel grilliger zijn dan het verschil tussen moment 2 en 3. Het is een assumptie die je nodig hebt bij repeated measures ANOVA, omdat je dezelfde personen meerdere keren meet en die metingen dus niet onafhankelijk zijn van elkaar.
-waarom is dit een probleem? als spheritcity geschonden is wordt de foutterm van de F toets onderschat, dus grotere F, sneller signicant, type 1 fout.
-Maunchly test of spherecity kijkt hier naar: indien signicant: correctie nodig, sphericiteit geschonden.
-episolon meet hoe sterk die schending is ( 1= perfecte sphrecity, 0.5 is maximale schending)
die epislon gaat bepalen hoe we df corrigeren,
df gecorrigeerd is = df maal epsilon
—indien spherecity geschonden maakt die df dus kleiner waardoor we strenger zijn en f waarde niet te snel signicant is.
2 soorten correcties: greenhouse geisner en huyn feld, wnr gebruiken we welke ?
bij sterke schending, dus lager dan 0.75 meestl greenhouse geisner
bij milde schending dus tussen 0.75 en 1 kunnen we huy-feldt gebruiken.
wat betekend het als in je between subjects effects bij repeated measures je intercept signicant is?
:elke plaat waar de deelnemers de y-as kruist verschilt waarschijnlijk heel erg
mixed anova
hierbij heb je zowel between subjects factoen als whithin subjects factoren
bv 3 groepen muizen leren een doolhof doorlopen. Bij elke groep luistren ze naar een andere muziekje, en dit is gemeten over 4 weken.
-je gaat dan eenhoof effect hebben van groep, een hoof effect van week en een interactie efect.
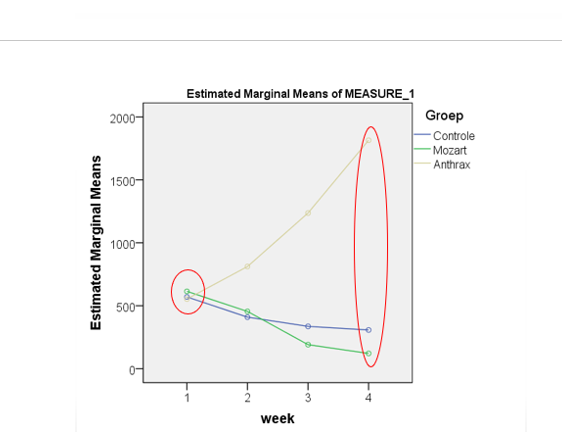
grafiek bij mixed anova , hoe kijk je daar naar?
1. Hoofdeffect van tijd (within-subject factor)
Kijk of de lijnen over het algemeen stijgen of dalen over de weken heen.
Hier: Controle blijft ongeveer stabiel, Mozart daalt licht, Anthrax daalt sterk. → Er is een algemeen tijdseffect.
2. Hoofdeffect van groep (between-subject factor)
Kijk of de lijnen op een ander niveau liggen, los van de tijd. Je vergelijkt de gemiddelde hoogte van elke lijn.
Hier: Anthrax start en eindigt op een heel ander niveau dan de andere twee → er is een groepsverschil.
3. Interactie-effect (het belangrijkste!)
Kijk of de lijnen parallel lopen of niet.
Parallel → geen interactie → het tijdseffect is hetzelfde voor alle groepen
Niet parallel → interactie → het tijdseffect verschilt per groep
Hier: de lijnen lopen duidelijk niet parallel — Anthrax daalt dramatisch, Controle blijft stabiel, Mozart daalt licht. → Er is een sterke interactie tussen tijd en groep.
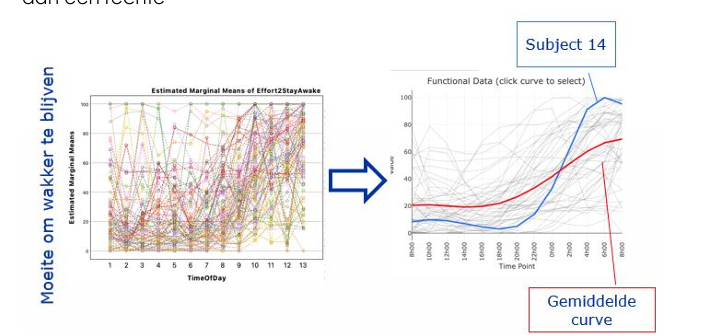
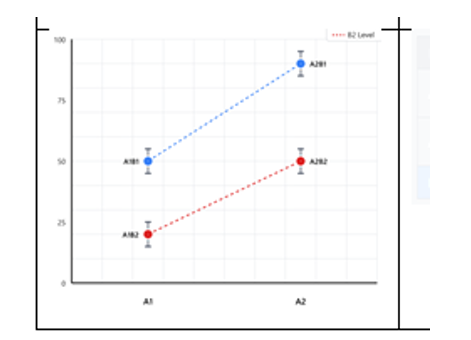
functionele anova : voorbeeldje slaapapneu , controle s en professionele chauffeurs.
et voorbeeld uitgelegd:
Ze meten bij drie groepen hoe moeilijk het is om wakker te blijven, op verschillende momenten van de dag (tijdspunten 1 tot 13, bijv. elk uur).
Slaapapneupatiënten:
Hun curve is stabiel slecht — de moeite om wakker te blijven is de hele dag hoog en verandert nauwelijks. Ze hebben constant weinig energie, ongeacht het tijdstip.
Professionele chauffeurs:
Hun curve ligt consistent lager dan die van de patiënten — ze hebben dus minder moeite om wakker te blijven. Waarschijnlijk zijn ze gewend aan onregelmatige uren en hebben ze daar strategieën voor ontwikkeld.
Controle (gezonde mensen):
Hun curve is het meest dynamisch — overdag doen ze het goed, maar 's nachts stijgt de moeite om wakker te blijven sterk. Dit is eigenlijk het normale bioritme — mensen worden 's nachts slaperig.
Wat voegt de functionele aanpak toe?
Bij gewone mixed ANOVA zou je zien: "er is een tijdseffect en een groepseffect." Maar de functionele aanpak toont je ook wanneer de groepen het meest van elkaar verschillen — op welk tijdstip is het groepsverschil het grootst? Dat zie je in de puntsgewijze F-functie.
functioenel anova, wnr gebruik je het.
-elke persoon wordt dus voorgesteld als een curve maar het is wel belangrijk dat je voldoende meetmoemnten hebt andrs kan je niet echt een functie daarvan maken.
-enke gebruiken als je denkt dat variabele zich als een functie gedraagd.
In het slaapvoorbeeld: waakzaamheid doorheen de dag gedraagt zich duidelijk als een functie — het bioritme is een vloeiend biologisch proces. Het heeft dus zin om curves te fitten.
In het Anthrax-voorbeeld: vier wekelijkse metingen zijn gewoon losse tijdspunten — er is geen reden om aan te nemen dat de scores tussen week 1 en week 2 een vloeiend patroon volgen. Dus gewone mixed ANOVA.
model functionele anova

functinele anova: waarom niet gewoon puntgewijs testen?
-heel veel punten ! heel groot kans op type 1 fout
oplossing: L² norm test: berekend de gekwadrateerde verschil tussen twee curves over het hele tijdsverloop en integreert het tot 1 enkele toetsingrootheid
De kern van de vraag is: zijn twee curves significant verschillend van elkaar?
Stel je hebt de gemiddelde curve van slaapapneupatiënten en de gemiddelde curve van controles. Je wil weten of die twee curves echt van elkaar verschillen, over het hele tijdsverloop heen.
Wat de L² norm test doet is eigenlijk heel intuïtief:
Op elk tijdstip bereken je het verschil tussen de twee curves. Dat verschil kwadrateer je (zodat negatieve en positieve verschillen niet tegen elkaar wegvallen). Dan tel je al die gekwadrateerde verschillen op over het hele tijdsverloop — dat is de integraal in de formule.
Het resultaat is één getal dat zegt: hoe ver liggen deze twee curves gemiddeld uit elkaar over de hele tijd?
Groot getal → curves liggen ver uit elkaar → significant verschil
Klein getal → curves liggen dicht bij elkaar → geen significant verschil
functionele anova : smoothing , wat als je teveel of te weinig smooth?
Het probleem is dit: je meet op discrete tijdspunten, maar de onderliggende werkelijkheid is een vloeiend proces. Als je die punten gewoon verbindt met rechte lijnen, krijg je een hoekige, onrealistische curve.
Smoothing fit er een vloeiende curve doorheen die het onderliggende patroon beter weergeeft.
Denk aan het als een soort gemiddelde over naburige tijdspunten — in plaats van exact door elk punt te gaan, trek je een vloeiende lijn die de algemene trend volgt.
De trade-off:
Te weinig smoothing → je curve volgt elk meetpunt exact → je vangt ook ruis op
Te veel smoothing → je curve is te glad → je mist echte variabiliteit die er wel degelijk is
In het slaapvoorbeeld zie je dat links in de grafiek — een chaotische wirwar van lijnen per persoon. Na smoothing (rechtergrafiek) zie je vloeiende individuele curves en één duidelijke gemiddelde rode curve. Die gemiddelde curve is dan wat je gebruikt in de L² norm test