VL VI - Training Neural Networks
1/17
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
18 Terms
Properties L2 Loss:
Sum of squared differences
Prone to outliers
Compute-efficient optimization
Properties L1 Loss
Sum of absolute differences
Robust
Costly to optimize
Different learning rate decays
Step decay (linear decay)
Exponantional decay
What is learning DL
Generalization to unkown dataset
optimized parameters give similar result
What is the validation set used for
Hyperparameter optimization
Check generalization progress
Whats underfitting
Training and validation losses decrease even at the end of training
Whats overfitting
Training loss decreases and validation loss increases
Ideal training
Small gap between training and validation loss
Bad signs during training
Training error not going down
validation error not going down
Performance on validation better than on training
Tests on train set different than during training
Bad practice
use test data during training
Possible Hyperparameters
Number Layers
Number of iterations
Learning rate
Regularization
Batch size
Methods for Hyperparameter tuning
Manual search
Grid search
Use grid to search hyperparameters
Random search
Like grid but no structure
Whats a good learning rate
use training data with small weight decay
Makes loss drop significantly within 100 iteration
How to check if data loading is correct
Overfit to a single training sample
loss should go to 0
Increase training samples gradually
How to Debug Network
Train and Val Curves necessary
only make one change at a time
most common neural net mistakes
didn’t overfit single batch
toggle train/eval mode
forgot zero_grad() in pytorch
passed softmax outputs to a loss
didnt use bias false
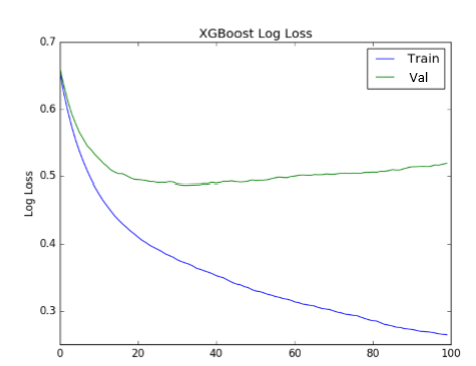
What can be said about this graph
Parameters are overfitted
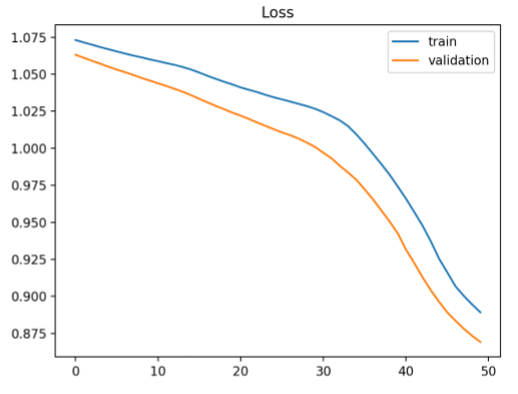
What can be said about this curve
Underfitting, because loss still decreasing