cse 330 final exam ASU 2026
1/63
Earn XP
Description and Tags
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai | Chat |
|---|
No analytics yet
Send a link to your students to track their progress
64 Terms
What is the primary purpose of the base register in base-and-bounds relocation?
To translate virtual addresses to physical addresses
What hardware component is responsible for performing base-and-bounds relocation?
Memory Management Unit (MMU)
What is the main drawback of the base-and-bounds memory management approach?
It wastes memory for large address spaces
In a base-and-bounds memory management system, what happens when a process attempts to access a memory location beyond its bounds?
An interrupt is generated
Which memory management approach is a generalized version of base-and-bounds?
Segmentation
What problem does the use of paging aim to address in memory management?
To mitigate the effects of fragmentation
T or F? On-demand paging is a mechanism where OS' only allocate pages to a program, when the program tries to access the page for the first time. This approach can help reduce memory utilization of a computer.
True
T or F? A process’ address space cannot exceed 100 times the size of the computer's physical memory (DRAM) size.
False
A CPU has 3-level page tables (L0 - L2) and 32KB pages. L0 is the bottom-level page table, while L2 is the top-level. L0 holds 256 page table entries, L1 holds 2048 entries, and L2 holds 16 entries. Using the information provided, please answer the following questions.
Useful information: 32 is 5 bits, 512 is 9 bits, 2048 is 11 bits, 4096 is 12 bits.
What is the number of bits required for page offset? (1)
How many bits do you need to index
L0 page table? (2)
L1 page table? (3)
L2 page table? (4)
What is the total address space size? 2^ (5)
1: 15
2: 8
3: 11
4: 4
5: 38
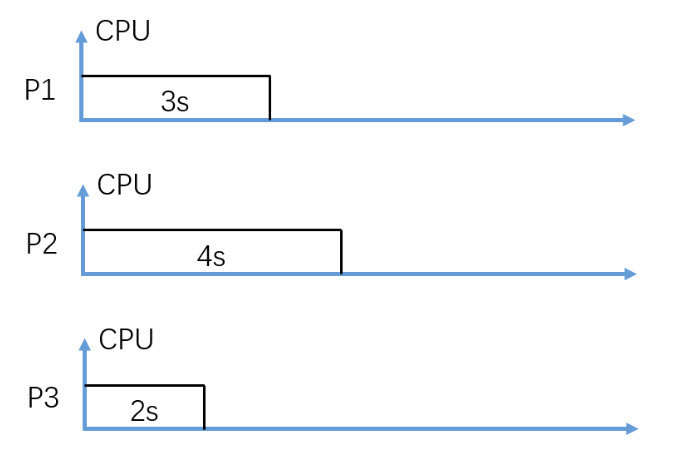
(Fig. 1) Assume P1, P2, and P3 arrive in order and at almost the same time.
In figure 1, consider Non-Preemptive FIFO CPU scheduling, what is the average waiting time in seconds?
Round to two decimal digits, e.g. 3.14
3.33
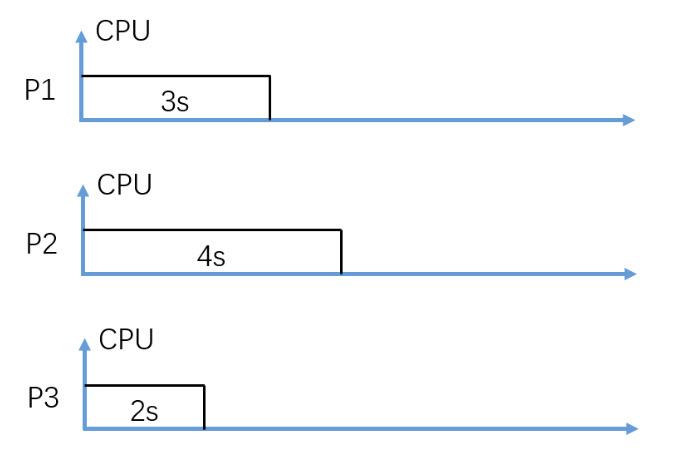
(Fig. 1) Assume P1, P2, and P3 arrive in order and at almost the same time.
In figure 1, consider Non-Preemptive FIFO CPU scheduling, what is the average turnaround time in seconds?
Round to two decimal digits, e.g. 3.14
6.33
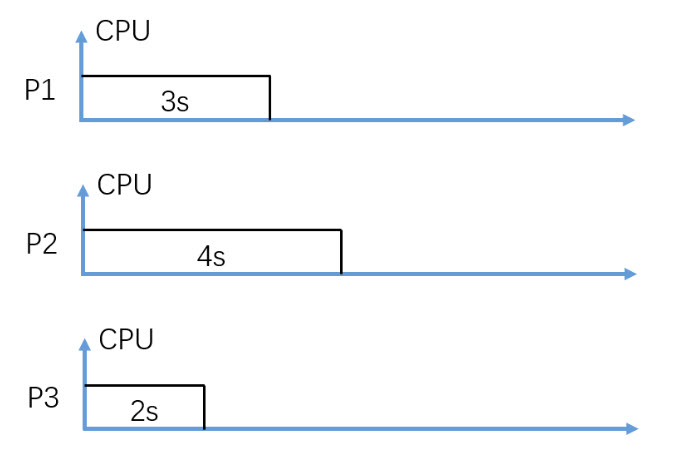
(Fig. 1) Assume P1, P2, and P3 arrive in order and at almost the same time.
In figure 1, consider Non-Preemptive SJF (Shortest-Job-First) CPU scheduling, what is the average waiting time in seconds?
Round to two decimal digits, e.g. 3.14
Note: Assuming P3 is scheduled and executed first.
2.33
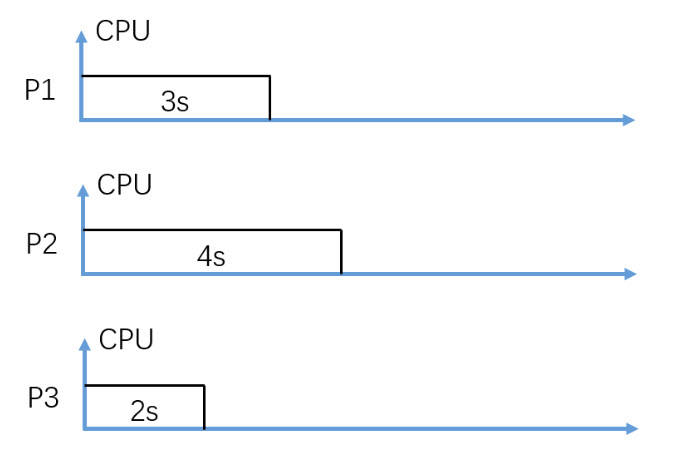
(Fig. 1) Assume P1, P2, and P3 arrive in order and at almost the same time.
In figure 1, consider Non-Preemptive SJF (Shortest-Job-First) CPU scheduling, what is the average turnaround time in seconds?
Round to two decimal digits, e.g. 3.14
Note: Assuming P3 is scheduled and executed first.
5.33
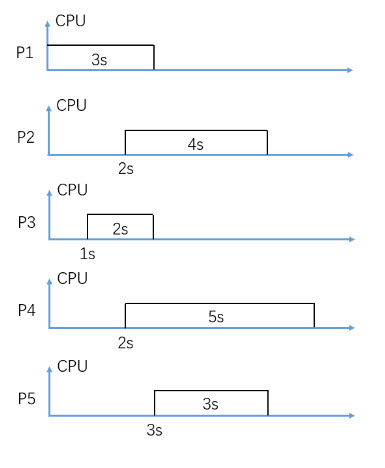
In figure 2, consider Non-Preemptive FIFO CPU scheduling (P2 is scheduled earlier than P4), what is the average waiting time in seconds?
Round to two decimal digits, e.g. 3.14
4.6
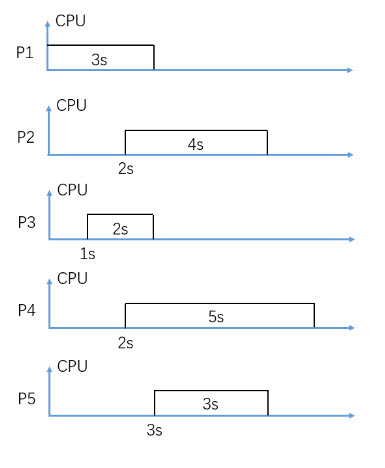
In figure 2, consider Non-Preemptive FIFO CPU scheduling (P2 is scheduled earlier than P4), what is the average turnaround time in seconds?
Round to two decimal digits, e.g. 3.14
8
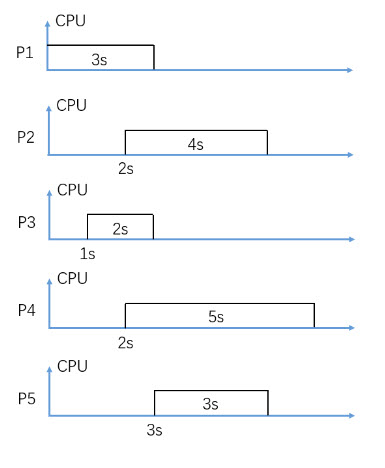
In figure 2, consider Non-Preemptive SJF (Shortest-Job-First) CPU scheduling, what is the average waiting time in seconds?
Round to two decimal digits, e.g. 3.14
4
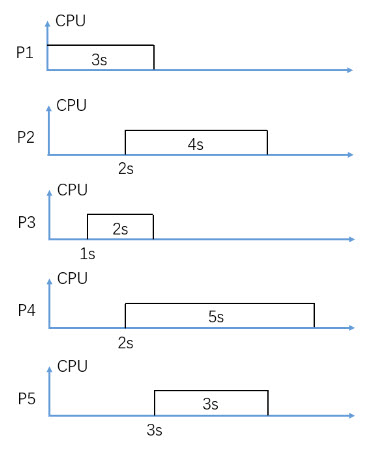
In figure 2, consider Non-Preemptive SJF (Shortest-Job-First) CPU scheduling, what is the average turnaround time in seconds?
Round to two decimal digits, e.g. 3.14
7.4
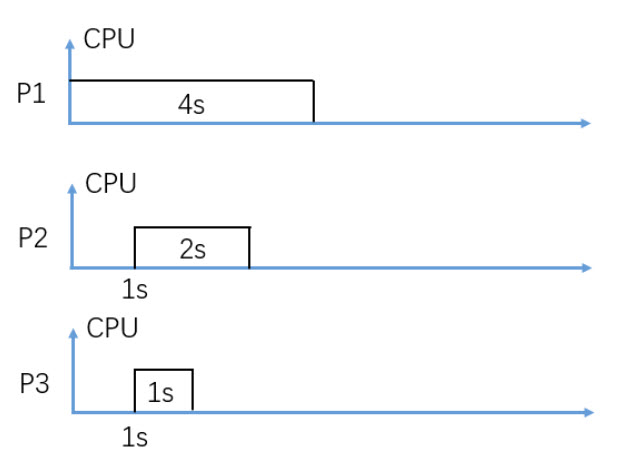
In figure 3, consider Non-Preemptive FIFO CPU scheduling (P2 is scheduled earlier than P3), what is the average waiting time in seconds?
Round to two decimal digits, e.g. 3.14
2.67
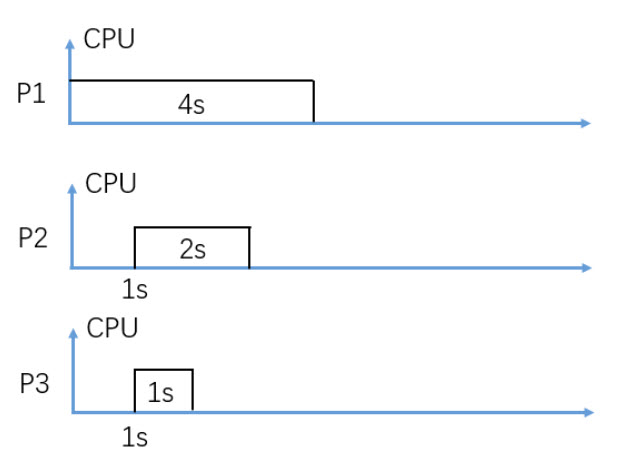
In figure 3, consider Non-Preemptive FIFO CPU scheduling (P2 is scheduled earlier than P3), what is the average turnaround time in seconds?
Round to two decimal digits, e.g. 3.14
5
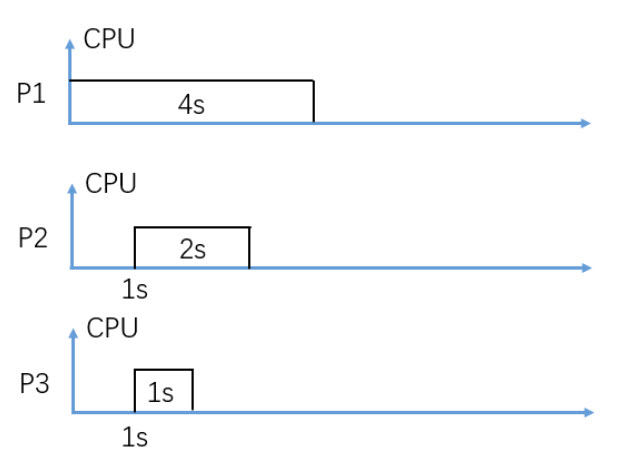
In figure 3, consider Non-Preemptive SJF (Shortest-Job-First) CPU scheduling, what is the average waiting time in seconds?
Round to two decimal digits, e.g. 3.14
2.33
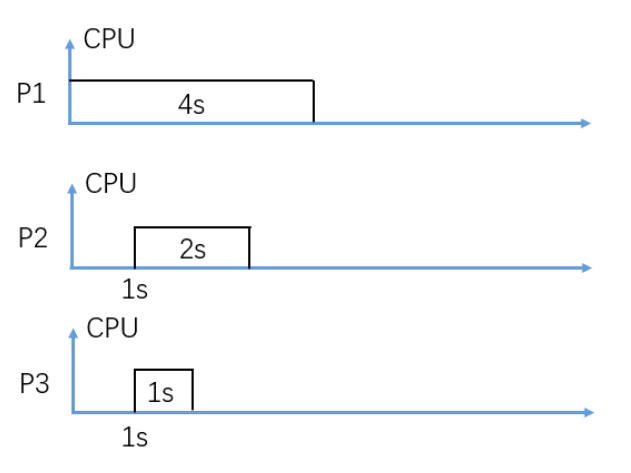
In figure 3, consider Non-Preemptive SJF (Shortest-Job-First) CPU scheduling, what is the average turnaround time in seconds?
Round to two decimal digits, e.g. 3.14
4.67
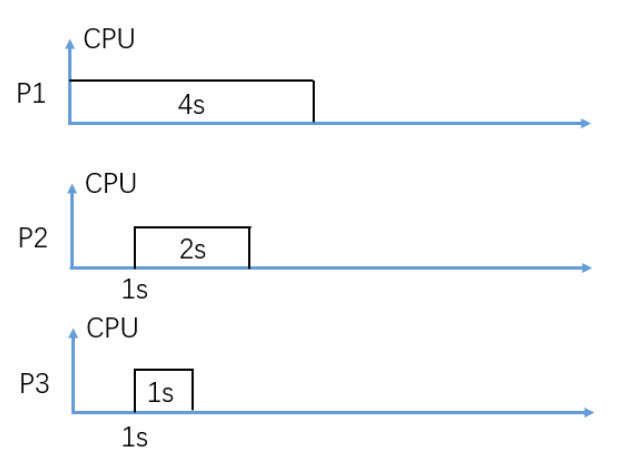
In figure 3, consider Preemptive SJF (SRTF) CPU scheduling, what is the average waiting time in seconds?
Round to two decimal digits, e.g. 3.14
1.33
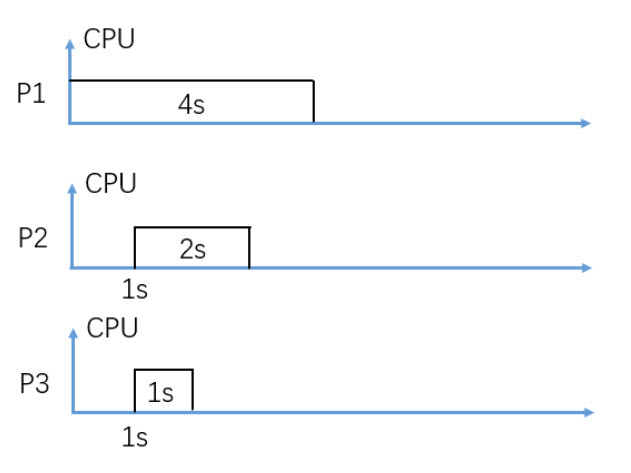
In figure 3, consider Preemptive SJF (SRTF) CPU scheduling, what is the average turnaround time in seconds?
Round to two decimal digits, e.g. 3.14
3.67
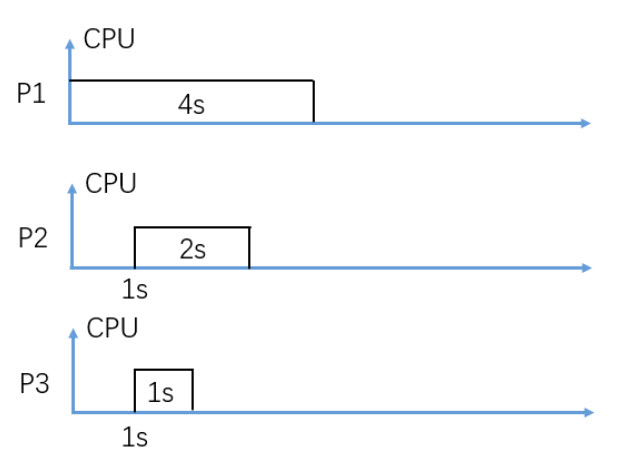
In figure 3, consider Preemptive SJF (SRTF) CPU scheduling, what is the average response time in seconds?
Round to two decimal digits, e.g. 3.14
0.33
T or F? A data race cannot happen in a single-threaded environment.
True
T or F? Two threads can simultaneously hold a mutual-exclusion (mutex) lock.
False
T or F? The reason behind why mutex locks address data race problems is that only a single thread is allowed to acquire the lock, and all other threads wait for 3 seconds.
False
T or F? Imagine you have a single variable (object) that you want to change from 0 to 1 atomically (i.e., no data races). You cannot use a test-and-swap instruction to achieve this.
False
T or F? One reason why Inconsistent lock usage leads to data races is because developers may use different locks to access an object.
True
T or F? A deadlock cannot occur in a single core system.
False
T or F? A spinlock is an efficient way to ensure atomicity in long-running code.
False
T or F? Using a mutex lock hurts the performance of the system because it makes computations run sequentially instead of in parallel.
True
T or F? Apart from the stack and the register state, all other segments (e.g., heap) of a process are shared between threads.
True
T or F? Each process thread must create and keep track of its own stack in the stack pointer register without relying on the OS.
False
T or F? Distributed applications that require strong isolation between components should rely on the multi-process approach.
True
T or F? Ordering violations in concurrently-executing threads can be addressed using mutual exclusion (mutex) locks.
False
Which of the following is NOT true regarding the block layer (abstraction)?
There is no use for a block layer without a filesystem
Which of the following is the order of the three steps taken by a hard disk drive (HDD)?
Seek, Rotate, Transfer
The reason why sequential workloads are better suited to storage devices like the HDD is because of the following:
Sequential workloads minimize the seek and rotation of the mechanical arm within an HDD
First-In-First-Out disk scheduling tries to read/write to disk in the order of requests.
What is the main cause of bad performance in FIFO-based disk scheduling for Hard Disk Drives (HDDs)?
The head movement may be random, which is a slow operation in disks
Imagine an SSD block comprising 8 pages is completely clean (programmable). At a certain time, you receive the following requests to program the block: 1,3,4,4,6,6,7,5.
How many program operations do you require? ____
How many erase operations would you need to perform in FIFO scheduling? ____
What would be the last 2 requests you handle if your goal is to minimize erase operations? ____, _____
8
2
4, 6
T or F? The size of the "block" in a block abstraction and the size of a "block" in the block cache must be the same.
TrueT
T or F? A "virtual" file is used to expose a kernel module to programs because it enables reusing the filesystem abstraction that users are already familiar with.
True
Sharing the page table between a user process and the kernel is beneficial for performance. For instance, with such sharing, on a system call, you don't need to change page tables.
Which of the following is a potential security problem with this approach?
User programs can corrupt each other's memory
In your projects, what function did you use to copy data structures sent by the user programs into kernel memory?
copy_from_user
T or F? Writes to consoles are not made using files in Linux.
False
Which of the following must be unique in filesystems?
inodes and paths
Assume the following C code executes:
int fd = open("hello.txt", O_CREAT); // returns 3
int ret = write(fd, buf, 1024);
What is the value of the file offset after these operations?
1024
Which of the following is a reason that the following operation may fail?
int fd = open("hello.txt", O_WRONLY); // returns -1
"hello.txt" does not exist, "hello.txt" is only writable by a root user, and "hello.txt" is not writable by the current user
Which of the following is FALSE about ordering violations?
They cannot lead to concurrency bugs.
T or F? The main reason why we require multi-level page tables is that a single-level page table incurs a high performance overhead during address translation.
False
Which of these is FALSE regarding filesystem logging?
Changes to inodes may be made directly on-disk, while remaining write operations must be written to the log first, and then synchronized
Consider the following specifications of your HDD:
(a) rotations-per-minute = 7200
(b) average seek = 3 ms
(c) average sequential transfer = 200 MB/s
(d) average random transfer = 3 MB/s
Use the following formulas:
- average latency = (average seek) + (average rotation) + (average transfer)
- average rotation = 0.5*(1000ms/rotations-per-second)
How long (in ms) does
(1) a sequential 4KB read take? ___ (1) + 0.5*(1000/ ___ (2) ) + ( ___ (3) /( ___ (4) * 1024)) * 1000
(2) a random 4KB read take? ___ (5) + 0.5*(1000/ ___ (6) ) + ( ___ (7) /( ___ (8) * 1024)) * 1000
3
120
4
200
3
120
4
3
Which of the following is NOT a benefit of using multiple processes over multiple threads?
If you want your system to conserve the memory utilization of your system.
T or F? Imagine there is a sensitive cryptographic key stored in a user-space process on my system. Since I am a paranoid android, I worry that an untrusted USB might steal this key using DMA attacks. To mitigate DMA threats, I can enable the I/O memory management unit (IOMMU).
True
Which of the following will only sometimes cause a context switch to the kernel?
A process accesses a heap object
Which of the following are the three typical device registers?
Status, Command, Data
T or F? Is the following I/O communication protocol correct?
while (STATUS == BUSY)
; // spin
Write data to DATA register
Write command to COMMAND register
while (STATUS == BUSY)
; // spinTrue
T or F? The "spin" in the I/O communication protocol (described in the previous question) would require a spinlock.
False
Which of the following is true regarding the use of spinning versus interrupts in I/O communication?
Interrupts do not waste CPU cycles, but can lead to more frequent context switches in some scenarios
T or F? Imagine a device requires very fast communication with your system. You should connect this device to the peripheral bus.
False
T or F? You wrote a device driver that is tasked with sending data to a device. Once an IOCTL command is sent to the driver, it should only return back after the data has been completely sent to the device. This device driver cannot use interrupt-based I/O communication.
False
Which of the following is TRUE regarding the use of DMA controllers?
A CPU programs a DMA controller, and resumes background tasks. The DMA controller sends an interrupt when the DMA operation is complete.
T or F? Memory-Mapped I/O (MMIO) is better for short-length device communication.
True