Search Engines Final
1/86
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
87 Terms
Search Engine Synonymns
Information retrieval, document retrieval, text retrieval
Come Back to Web Search Engine Architecture
Federated Search
allows a user to search multiple independent, often disparate, data sources simultaneously through a single search interface; data comes in a standard interface
Meta Search
sends a user's query to several other major search engines or directories, aggregates the results, removes duplicates, and presents them in a single list
Come back to enterprise search
How Google delivers fast results with lots of information
Parallelizes search with >1000 machines
Document
a long string of characters contained in a single file
Index
a list of important keywords from the documents, stored in some efficient file structure
Query
boolean (A and B or C), list of words, natural language
Relevance Feedback
try “similar pages” in Google
Zeroth-Generation Search (1960)
keyword based, search on fields, boolean logic, adding statistics to Boolean
First-Generation Search Engines (1993)
Statistical keyword match, spider/crawler to download web pages
Second-Generation Search Engines (1997)
Keyword matching, relying heavily on link analysis, using links to measure the quality of web page
Third-Generation Search Engines (2001)
Incorporate advanced search features, e.g., automatic categorization
Search Engine Licensing
sell SE software to companies to support their intranet and/or internet web search
Search Service
Provide search to portals
ASP/Cloud Business Model
provider acts as an ASP (Application Service Provider), and search engine provider is responsible for the hardware and software infrastructure and keeps the index up-to-date; the client handles a search page to submit queries
Keyword Based Ads
Advertisements are associated with keywords; when query contains a keyword, associated advertisement(s) will be displayed
Google Adwords
Search engine pulls up ads with users’ keywords and return them with the regular search results; advertisers submit ads and buy keywords for the ads
Google Adsense
analyzes web page content and extract keywords; advertisers submit ads and buy keywords for the ads
Boolean Model
A document is represented as a set of keywords; queries are expressed as a Boolean expression of keywords, connected by AND, OR, and NOT, including brackets; a document is retrieved based on whether or not its keywords satisfy the Boolean query
Precision
Percentage of retrieved results that are relevant to the queries
Recall
Percentage of relevant results that are retrieved
Statistical Models
Keyword based plus statistical information about the keywords; retrieval based on similarity between query and documents
Document Terms and Weights
tfi,j = frequency of term j in document i
dfj = document frequency of term j = number of documents containing term j
idfj = inverse document frequency of term j= log2 (N/ dfj) (N: number of documents in collection) (an indication of a term’s ability as a document discriminator.)
wij = tfi,j• idfj = tfi,j• log2 (N/ dfj)
A term occurs frequently in the document but rarely in the remainder of the collection has a high weight
Term Frequency Normalization
tf’i,j = tfi,j / tfmaxi where tfmaxi is the term frequency of the most frequent term in document
OR
tf’i,j = tfi,j / |Di| where|Di| is the number of unique words in document
TF and IDF Weights
When tf increases, number of documents decreases exponentially
When idf increases, number of documents increases exponentially
tfxidf is maximized when tf and idf have medium values
Vector Space Model
Vector space is comprised of the vocabulary; A collection of N documents can be represented as a document-term matrix where document is a term vector and an entry in the matrix corresponds to the “weight” of a term in the document (vocab of 2 means 2D space, vocab of 3 means 3D space)
Similarity Measure
Computes the degree of similarity between a pair of vectors
Inner Product Similarity
sim(Di, Q) = sumk=1t(dikqk) where dik is the weight of term k in document i and qk is the weight of term k in the query (this favors long documents)
Cosine Similarity
sumk=1t(dikqk) / doc_length*query_length
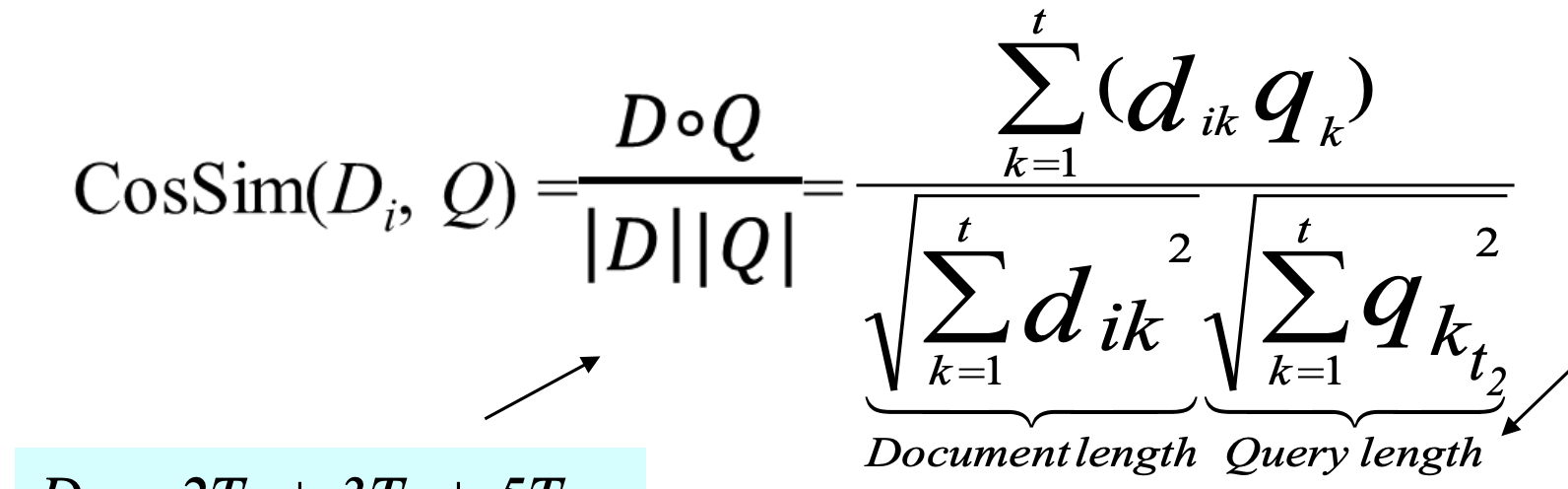
Jacquard Coefficient
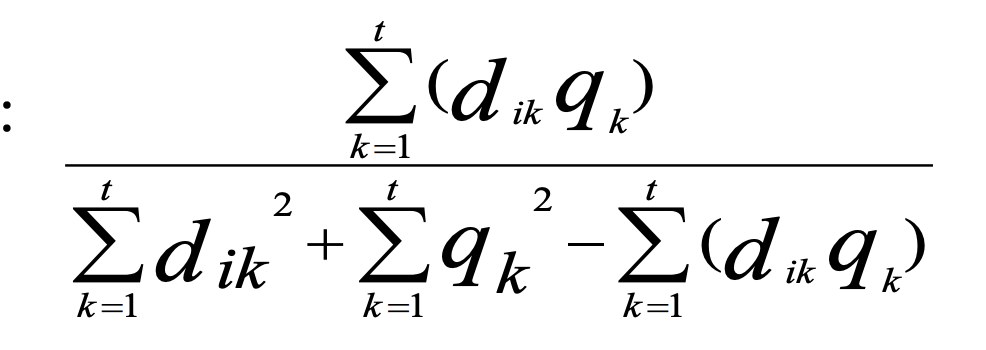
Dice Coefficient
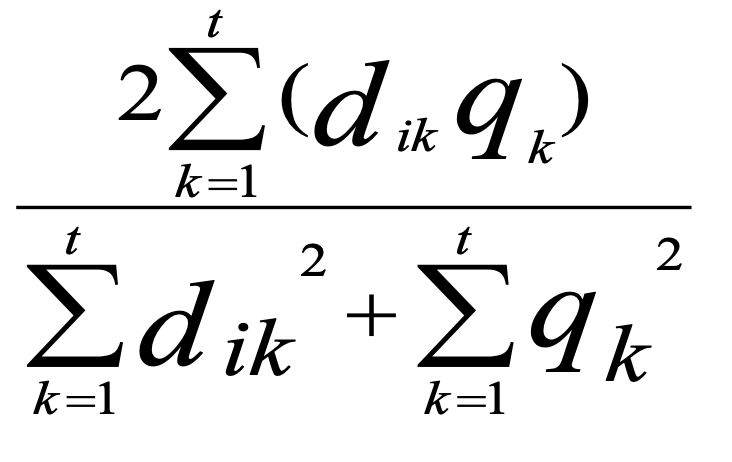
Document Centroid
To compute the similarity of the three documents, we can compute the similarityof each document to the centroid instead of all possible document pairs (add each and take average)
Term Independence Assumption
Vector space model assumes term independence; we can judge term independence by checking whether or not two terms frequently co-occur in a document
Unbalanced Property of Vector Space Model
Multi-step filtering: filter out all documents containing both x and y, rank them higher, and filter out all documents containing either x or y, rank them lower
Compute similarity as usual but weight the similarity by the number of query terms matched: Sim’(D, Q) = Sim(D, Q) * [ | D ∩ Q | / | D ∪ Q | ]
Combining Boolean and Vector Space Model
Boolean and vector space models can be combined by doing Boolean filtering first followed by ranking:
– First evaluate the Boolean query as usual
– Collect all documents satisfying the Boolean query
– Rank the result using the vector space query
Inverted Files
A document index (inverted file) tells you which documents contain a query term (implemented as a hash file, B-tree, etc); it is a list of words, where each word points to a list of the documents that contain it; storage overhead = size of index / size of text * 100%
Query Optimization on Inverted Indexes
start with AND on the shortest lists
Distance Constraint Extension on Inverted Index
Inverted index keeps locations of keywords within documents, and document components; Retrieval algorithm has to correlate location information and check document components
Term Truncation
comput* : computer, computing, computation, etc.
Overhead for Inverted Index Changes
For insertion, when the document contains n words, insertion needs to update n postings lists;
For deletion, a “forward index” is maintained to record words contained in a document, find the Doc ID of the document to be deleted, obtain the words contained in the document from the forward index, delete the postings entries for the Doc ID from the inverted file
Batch Insertion
System temporarily groups newly discovered documents into a small, fast-access memory index and periodically merges them into the massive main disk index all at once to drastically reduce slow read/write operations
Soft Boolean Operators
Conjunctive Query: returns documents containing both x and y, x only, and y only; but documents containing x only or y only are penalized heavily in ranking
Disjunctive Query: returns documents containing both x and y, x only, and y only; but documents containing both x and y are given a small bonus in ranking
OR in Extended Boolean Model
Unlike the standard Boolean model, which only gives a strict yes/no (1 or 0) match, the extended model allows for partial matches by ranking documents based on how relevant they are to the query.
wx,j = (tfx,j / maxl tfl,j) * (idfx / maxi idfi)
sim(qor, dj) = [ (x2 + y2)/2 ]0.5 where x =wx,j and y = wy,j
AND in Extended Boolean Model
Ranks documents by measuring their distance from the "most desirable" state (1,1), penalizing documents that fall short of perfectly matching both terms.
sim(qand, dj) = 1 − { [ (1− x)2 + (1− y)2 ]/2 }0.5
P-norm Model
sim(qor, d) = [ (x1p + x2p + ... + xmp ) / m ]1/p
sim(qand, d) = 1 − { [ (1− x1)p + (1− x2)p + ... + (1− xm)p ] / m }1/p
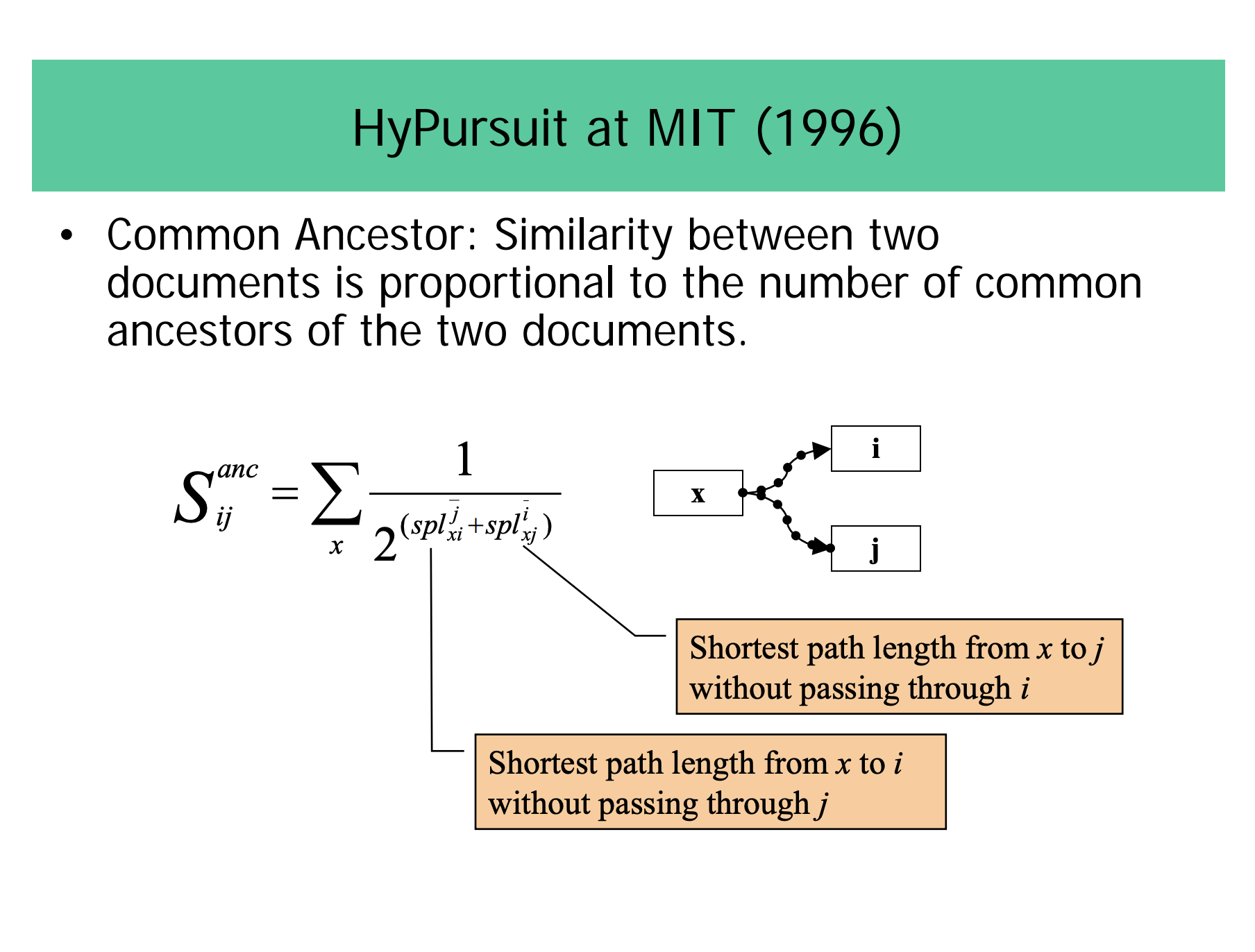
HyPursuit
Direct Path: Similarity between two documents varies inversely with the shortest path length (spl) between the two documents Si,jspl = 1/2splij +1/2splji
Common Ancestor: Similarity between two documents is proportional to the number of common ancestors of the two documents.
Common Descendants: Similarity between two documents is proportional to the number of common descendants of the two documents
The final link-based similarity is a combination of the shortest path, common parent and common child similarities
WISE
links are used to pass term-based similarity from one page to another; page score is the weighted sum of its own score based on keyword matching and scores inherited from its parents
Google PageRank
Page Rank: Compute quality/authority of a page
Anchor Text: Short description from third parties of a page
It has location information for all hits and so it makes extensive use of proximity in search
words in a larger or bolder font are weighted higher than other words
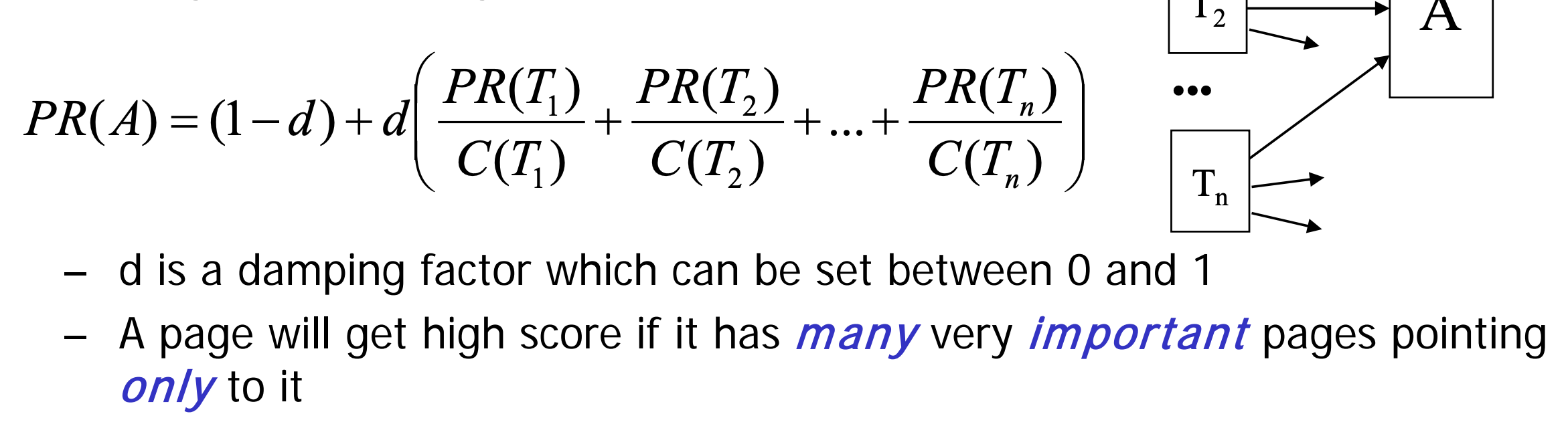
Synchronous vs Asynchronous Iteration
Synchronous iteration means: in iteration i, all PR values are computed using PR values in iteration i-1
In asynchronous iteration, recomputed values are used if available
The Rank Sink Problem
When two pages pointing to each other but not to any other pages, their PageRank values will increase indefinitely
SEO Link Boosting
Given the same content, split the content on as many pages as possible; limit the number of links to other websites to avoid PageRank leaks; if you must have the external out-links, place the links on pages with a large number of internal out-links; add links to break the sink
Authority and Hub Weights of a Page
Pages with High Authority weights: contain high quality information on the topic
Pages with High Hub Weights: contain links to high quality pages on the topic
HITS: Hyperlink-Induced Topic Search
Each page has an authority weight and a hub weight
Authority weight of p is the sum of hub weights of all pages q where q → p
The weights are recursively computed as in PageRank
Adjacency Matrix (A): This matrix records outgoing links. If page D1 links to page D2, the matrix gets a 1 at that specific row and column (A[i,j] = 1). Otherwise, it's 0.
Transposed Matrix (AT): Transposing the matrix flips the rows and columns. This effectively records incoming links. If page D2 is linked to by page D1, the transposed matrix gets a 1 at AT[i,j].
In a synchronous update, you calculate the new Authority and Hub vectors for iteration k using the values from the previous iteration (k-1)
The Asynchronous Update Rule: Instead of using only the old values, you use the newly calculated Authority score to immediately calculate the Hub score in the same step
HITS Normalization
The weights obtained in each iteration are typically normalized to:
– Avoid overflow in power iteration since many iterations are needed
– Align with theoretical model (see below for some normalization factors)
L1 norm: summation of the vector elements
L2 norm: magnitude of the vector: sqrt(∑ element2)
Clever Architecture
Given a topic (a set of keywords), query a searchengine to obtain a root set of pages
Expand the base set to form the topical subgraph, which includes parents and children of the base set
Compute Hub and Authority weights by iteration
Re-rank result: main results are ranked by authority weights; separate list of resource pages is ranked by hub weights
Explicit vs Behavioral Evaluation
Explicit: performed by human judges: given a set of queries, the judges examine the pages and decide if the pages are relevant or non-relevant
Behavioral: examine real life user behavior logged by the search engine; Query -> ranked result set -> clicks + timestamp of each action
Fallout
number of non-relevant items retrieved/ total number of non-relevant items in the collection
can be viewed as the inverse of recall
Interpolated Precision-Recall
smooths jagged performance curves by defining the precision at a given recall level as the maximum precision achieved at any equal or higher recall level. This creates a step-graph that allows different search algorithms to be easily compared across the standard 11 recall levels (0.0 to 1.0)
F1-Score
F= 2PR/ (P+R)
Top-K Precision
Number of relevant documents / k
Average Precision
computes the area under the precision-recall curve

Other Metrics
Novelty Ratio: the proportion of items retrieved and judged relevant bythe users of which they had not been aware prior to receiving the search output
Coverage Ratio: the proportion of relevant items retrieved out of the total relevant documents known to users prior to the search
Sought recall: the total number of documents examined by the user following a search, divided by the total number of relevant documents which the user would like to examine.
Reciprocal Rank (RR): Reciprocal of the rank at which the first relevant document was retrieved RR=1/(rank_first_rel)
Discounted Cumulative Gain (DCG)

Benchmark Collection
A set of standard documents and queries; A list of relevant documents for each query
TREC Benchmarking
Participants are given parts of a standard set of documents and queries in different stages for testing and training
Participants submit the P/R values on the final document and query set and present their results in the conference
Ad hoc - new questions are being asked on the static set of data. (library catalog searching)
Routing - same questions are being asked, but the new information is being searched. (news clipping, library profiling)
Relevance Judgement
Polling: Combine the retrieved documents from each system under test and perform relevance judgment on the combined documents
Document Indexing
1. Tokenize documents into words
2. Remove stop words
3. Stem words
4. Replace words by term ID
5. Count occurrence of words (tf)
6. (optional) add related terms for low
frequency terms
7. (optional) form phrase for high
frequency terms
8. Compute weight for all single terms,
phrases and thesaurus classes
9. Create inverted and forward indexes
for single terms, phrases, and related
terms with proper weights
Query Indexing
1. Tokenize query into words
2. Remove stop words using the same
dictionary as in indexing
3. Stem words using the same
algorithm as in indexing
4. Replace words by term IDs
5. Compute weights of all query
terms (binary/non-binary weights)
6. Form the query vector
7. Compute similarity between query
and document vectors
8. Return ranked list of documents
Stemming Methods
Table Lookup (term, stem)
Affix Removal: Longest matching resulting in minimum stem length (can be iterative)
Context free -- remove the suffixes according to the suffix list (or set of rules)
Context sensitive -- consider the other characters in the word
Corpora Based Statistical Stemming — Based on statistical analysis of a collection of documents
Word Segmentation
cut off method: boundary is determined by the cutoff value of successor variety; segment when successor variety >= threshold
peak and plateau method": break at the character whose successor variety is greater than both its preceding and following character
entropy stemming: entropy of a letter sequence α is defined as: – Probability that char “j” follows α = number of strings with prefix αj (denoted as |Dαj |) / number of strings with prefix α (denoted as |Dα|); Entropy sums up the probabilities for all characters that follow α
Select Stem: complete word method or heuristics to if the first one is more likely a prefix, select second, else pick first
Approximate Match - Shared Bigram Stemming: similarity of two terms are measured by Dice’s coefficient S=2C/(A+B) where A and B are the number of unique bigrams in two terms, respectively, and C is the number of unique bigrams shared by the two terms.
Query Reformulation
Modifies a bad query into a better one (manual or through relevance feedback)
Terms in relevant results are used to reinforce the original query vector
Terms in nonrelevant results are used to weaken the original query vector (add with negative weight)
Use smaller weight for γ than for β.
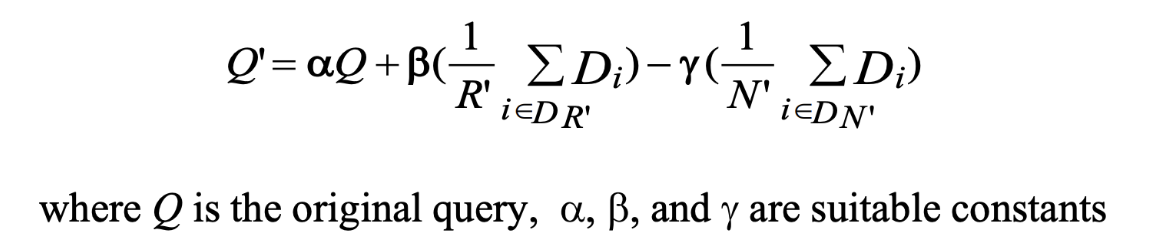
Implicit vs Explicit Feedback
Explicit: Users explicitly identify which documents are relevant and which are not relevant
Implicit: Guess user's preferences purely based on their actions (clicks)
Optimal Query

Document Modification
Documents designated as relevant must be rendered more similar to query Q:
– A query term not present in the document is added to the document with a weight factor α.
– A query term present in the document receives increased importance by incrementing its weight by a factor β.
– A document term not present in the query is decreased in weight by -γ
Documents designated as non-relevant must be rendered less similarity to
the query
– Document terms also present in the query are rendered less important by decreasing their weight by a factor of -δ.
– Document terms absent from the query are increased in weight by a factor of ε.
Search Engine Personalization
Logging clicks
Eye tracking for fixation
Preference Mining
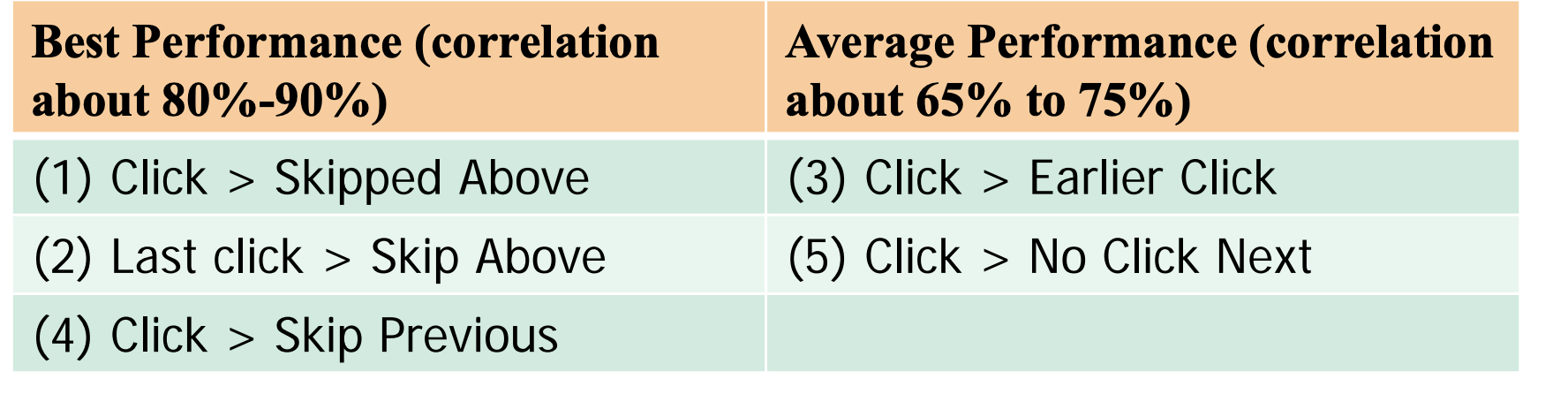
Click > Skip Above: Preferences are generated only when user decided not to trust the search engine and skip over a higher ranked link
Last Click > Skip Above: Later clicks are more informed decisions than earlier clicks (users learn as they examine more results and click more carefully
Click > Earlier Click: Later clicks are more relevant than earlier clicks
Click > Skip Previous: Users likely have examined the snippet above a clicked snippet carefully, so if a link is clicked but the link above is not clicked, the link above must have been judged to be irrelevant
Click > No-Click Next: When user clicks on a link, very often he/she would also read the snippet below it; if a link immediately below a clicked link is not clicked by the user, it is likely irrelevant
Applying User Preferences to Ranking
𝑞 : the input query (a set of keywords)
𝑟 : the ranked list of returned search items
𝑐 : the set of links a user clicked on, which conveys implicit user’s preference
𝑟 − 𝑐 : the set of unclicked links
Middleware is used to do reranking and query reformulation
Zipf’s Law
People act so as to minimize their probable average rate of work (order words in decreasing order of their frequencies f in the corpus)
Can be used to determine stop words
“the rich gets richer”
Three Views of a Term
Content point of view: A term partially reflects the content of a document
Index point of view: A term is indexed in search engine to tell which documents contain the term
Search point of view: A term is used for identifying the documents to be returned
Ideally, a term should be able to separate relevant documents from non-relevant documents (that would make it an important term)
Discrimination Value
Good index terms have positive dv values dvj = Q-Qj where Q is the similarity of the two documents before adding term j
In general, small df yields positive dv
Discrimination value of term j, dvj increases from zero to positive as
the document frequency of the term increases, and then decreases as the document frequency becomes still larger.
Find the centroid C of the document space and Compute Q as the similarity between each document and the centroid
wi,j = tfi,j • dvj
Phrase Extraction
Phrases can be extracted using a standard phrase dictionary; Phrases could be too inflexible for search (high precision, low recall)
N-Grams for Phrases
Improve recall but hurt precision
Need to filter (prefer nouns to adjectives and verbs; filter out n-grams that are infrequent; remove n-grams with stop words)
Collocation (co-occurrence)
Two or more words are collocated if they are used together conventionally; collocation relaxes consecutiveness to consider words “near” each other
Pointwise Mutual Information
PMI considers both co-occurrence frequencies and frequencies of individual terms
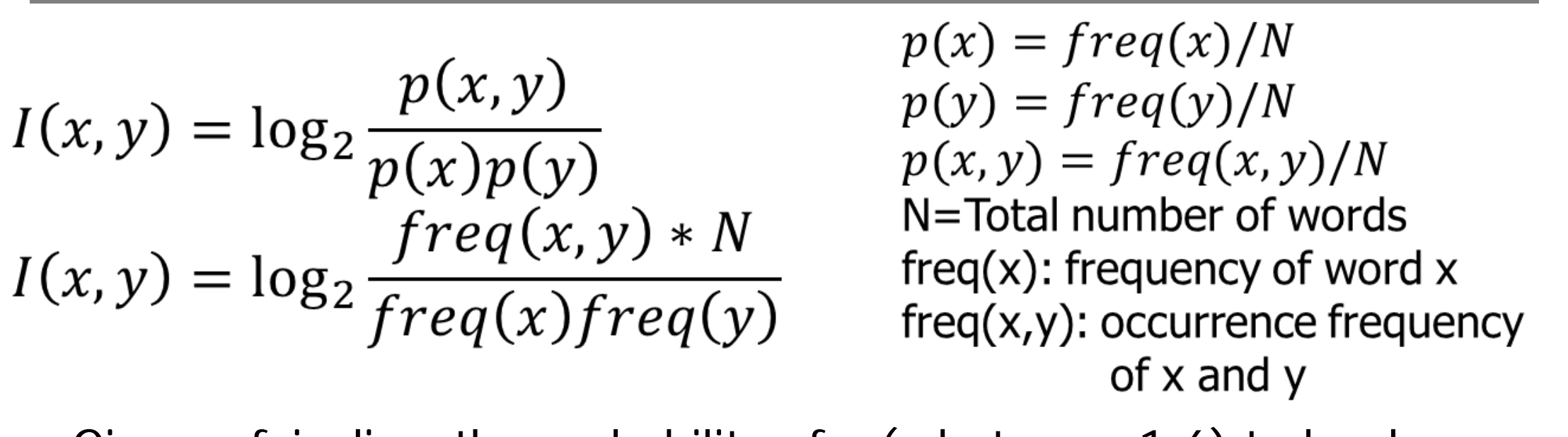
Enterprise Seach
Enterprise users are more critical, demanding and mission critical (page rank does not work; formats are pdf and docx)