Data mining
1/44
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
45 Terms
Modelowanie predykcyjne obejmuje:
a) analizę asocjacji, sieci neuronowe, analizę regresji
b) analizę skupień, analizę regresji, sieci neuronowe
c) analizę regresji, SVM, sieci neuronowe
c) analizę regresji, SVM, sieci neuronowe
Data mining skierowany obejmuje:
a) SVM, sieci neuronowe, drzewa decyzyjne
b) analizę skupień, sieci neuronowe, drzewa decyzyjne
c) analizę asocjacji, regresję logistyczną, SVM
a) SVM, sieci neuronowe, drzewa decyzyjne
Data mining nieskierowany obejmuje:
a) SVM, analizę asocjacji, sieci samoorganizujące się
b) analizę skupień, sieci neuronowe, drzewa decyzyjne
c) analizę asocjacji, analizę skupień, sieci samoorganizujące się
c) analizę asocjacji, analizę skupień, sieci samoorganizujące się
Losowe braki danych (MAR):
a) dotyczą sytuacji, w której prawdopodobieństwo wystąpienia braku wartości zmiennej w rekordzie nie zależy ani od zaobserwowanych danych ani od brakującej wartości
b) dotyczą niedostępności respondenta wynikających lub skorelowanych z cechami respondenta
c) dotyczą sytuacji, w której prawdopodobieństwo wystąpienia braku w rekordzie może zależeć od obserwowanych danych, ale nie od brakującej wartości
c) dotyczą sytuacji, w której prawdopodobieństwo wystąpienia braku w rekordzie może zależeć od obserwowanych danych, ale nie od brakującej wartości
Próbkowanie stosujemy, gdy:
a) chcemy wybrać zmienne tylko statystycznie istotne
b) mamy zbyt wiele rekordów
c) mamy zbyt wiele zmiennych
b) mamy zbyt wiele rekordów
Oversampling polega na
a) zwiększeniu liczby rekordów w mniej licznej klasie poprzez powielanie lub generowanie nowych danych
b) usunięciu rekordów z nadreprezentowanej klasy tak, aby liczba przypadków w każdej z klas była zbliżona
c) usunięciu odpowiednich zmiennych tak, aby liczba przypadków w każdej z klas była zbliżona
a) zwiększeniu liczby rekordów w mniej licznej klasie poprzez powielanie lub generowanie nowych danych
W modelu regresji logistycznej, ciągłe zmienne objaśniające:
a) wprowadzenie ich nie wymaga podjęcia żadnych działań przygotowawczych
b) muszą być poddane transformacji
c) muszą być poddane dyskretyzacji
a) wprowadzenie ich nie wymaga podjęcia żadnych działań przygotowawczych
Przycinanie drzewa decyzyjnego stosuje się w przypadku, gdy:
a) mamy zbyt dużo obserwacji
b) model jest przeuczony
c) model zbyt słabo odzwierciedla próbę uczącą
b) model jest przeuczony
Do oceny jakości podziału drzew w przypadku porządkowej zmiennej celu stosuje się:
a) kryterium entropii, kryterium Giniego
b) kryterium entropii, statystyka Chi-Kwadrat
c) kryterium Giniego, statystyka Chi-Kwadrat
a) kryterium entropii, kryterium Giniego
W modelach lasów losowych Breimana:
a) stosuje się przycinanie w celu uproszczenia modelu
b) do klasyfikacji ostatecznej wykorzystywana jest metoda głosowanie
c) każde drzewo konstruuje się wykorzystując ten sam zestaw zmiennych, losuje się jedynie podzbiory obserwacji
b) do klasyfikacji ostatecznej wykorzystywana jest metoda głosowanie
Funkcja aktywacji:
a) musi być zawsze taka sama w warstwie ukrytej i warstwie wyjściowej
b) może być inna w warstwie ukrytej, niż w warstwie wyjściowej
c) łączy sygnały wyjściowe z poprzedzających neuronów
b) może być inna w warstwie ukrytej, niż w warstwie wyjściowej
Funkcja aktywacji zawarta jest w sztucznych neuronach:
a) tylko w warstwie ukrytej sieci neuronowej
b) tylko w warstwie wejściowej sieci neuronowej
c) zarówno w warstwie ukrytej jak i wyjściowej sieci neuronowej
c) zarówno w warstwie ukrytej jak i wyjściowej sieci neuronowej
Warstwa wejściowa modelu sztucznej sieci neuronowej zawiera:
a) co najmniej tyle elementów, ile jest zmiennych objaśniających
b) dokładnie tyle elementów, ile jest zmiennych objaśniających
c) ustaloną przez użytkownika liczbę elementów, niezależną od ilości zmiennych objaśniających
a) co najmniej tyle elementów, ile jest zmiennych objaśniających
Na czym polega uczenie sztucznych sieci neuronowych:
a) na zmianie wartości wag
b) na zmianie liczby neuronów
c) na zmianie postaci funkcji kombinacji i aktywacji
a) na zmianie wartości wag
Dwudzielny problem klasyfikacyjny dotyczy:
a) przypadku pojedynczego neuronu wyjściowego z uprzednio ustawioną wartością progową oddzielającą dwie klasy
b) przypadku pojedynczego neuronu wyjściowego dla kilku kategorii jednoznacznie uporządkowanych
c) przypadku dwóch neuronów wyjściowych
a) przypadku pojedynczego neuronu wyjściowego z uprzednio ustawioną wartością progową oddzielającą dwie klasy
Grupowanie bez nadzoru dotyczy:
a) metody k-najbliższych sąsiadów
b) metody SOM – Kohonena
c) drzew decyzyjnych
b) metody SOM – Kohonena
W procesie rywalizacji sieci samoorganizujących:
a) wyznaczane są wartość odległości pomiędzy danymi wejściowymi a wagami neuronów
b) modyfikowane są wagi tylko dla neuronu wygrywającego
c) modyfikowane są wagi tylko dla neuronów sąsiadujących z neuronem wygrywającym
a) wyznaczane są wartość odległości pomiędzy danymi wejściowymi a wagami neuronów
W analizie asocjacji dla reguły "A to B" wsparcie reguły, to:
a) prawdopodobieństwo, że wystąpi B, gdy występuje A
b) prawdopodobieństwo, że wystąpi A, gdy występuje B
c) prawdopodobieństwo wystąpienia obu tych zdarzeń
c) prawdopodobieństwo wystąpienia obu tych zdarzeń
W analizie asocjacji dla reguły "A to B" ufność reguły, to:
a) prawdopodobieństwo, że wystąpi A, gdy występuje B
b) prawdopodobieństwo, że wystąpi B, gdy występuje A
c) prawdopodobieństwo wystąpienia obu tych zdarzeń
b) prawdopodobieństwo, że wystąpi B, gdy występuje A
Opisz krótko proces weryfikacji modeli predykcyjnych w data mining.
Zbiór danych dzieli się na próbę uczącą, walidacyjną i testową. Model buduje się na próbie uczącej, dostraja na walidacyjnej, a ostateczną ocenę jakości przeprowadza na próbie testowej
Na czym polegają metody sekwencyjne postępowania z brakami danych? Podać przykład.
Polegają na uzupełnianiu braków, zmienna po zmiennej, wykorzystuje się wartości zmiennych uzupełnionych we wcześniejszych krokach. Przykład: sekwencyjna imputacja regresyjna
Wymień dwie metody doboru liczby głównych składowych.
Kryterium Kaisera, wykres osypiska
Wymień trzy metody weryfikacji, czy model drzewa decyzyjnego został przeuczony.
a) Porównanie błędu na próbie uczącej z błędem na próbie walidacyjnej/testowej
b) Walidacja krzyżowa
c) Analiza krzywej błędu w funkcji złożoności drzewa
Do czego służy zbiór testowy i jaką część zbioru danych wybiera się do zbioru testowego? Odpowiedź uzasadnić.
Zbiór testowy służy do ostatecznej oceny jakości modelu na danych, które nie brały udziału w jego budowie. Wybiera się zwykle ok. 20–30% danych. Uzasadnienie: musi być niezależny od próby uczącej, aby ocena mocy predykcyjnej nie była zawyżona.
Co należy rozumieć pod pojęciem: brak losowy (MAR)?
Brak danych, którego prawdopodobieństwo wystąpienia może zależeć od wartości zaobserwowanych, ale nie zależy od samej brakującej wartości.
Co należy rozumieć pod pojęciem: brak całkowicie losowy (MCAR)?
Brak danych, którego prawdopodobieństwo wystąpienia nie zależy ani od wartości zaobserwowanych, ani od wartości brakującej.
Podaj dwie różnice w przeprowadzaniu klasyfikacji: regresja logistyczna a drzewo decyzyjne.
Regresja wymaga przygotowania danych, jest wrażliwa na obserwacje odstające; drzewo jest nieparametryczne, automatycznie wychwytuje interakcje
Przeprowadzenie podziału przestrzeni cech przy konstrukcji modelu drzewa decyzyjnego wymaga:
Wyboru zmiennej dzielącej oraz punktu podziału
Na czym polega różnica pomiędzy metodą bagging a boosting budowy klasyfikatora?
Bagging buduje wiele modeli równolegle. Boosting buduje modele sekwencyjnie.
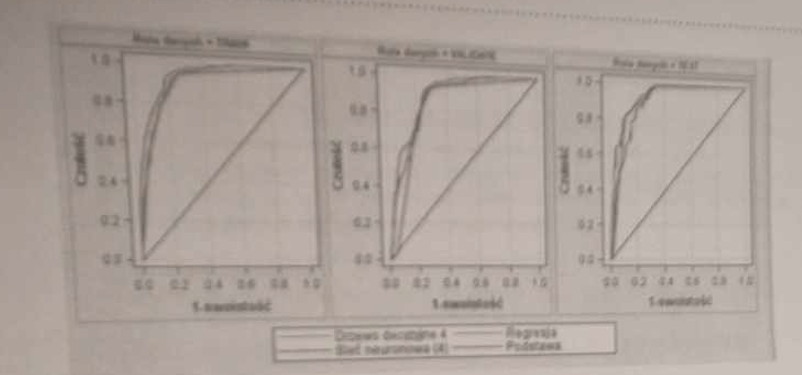
Zinterpretować poniższy rysunek otrzymany dla pewnego klasyfikatora (krzywe ROC).
Im krzywa bardziej wygięta w stronę lewego górnego rogu, tym lepszy model. Krzywe leżące blisko przekątnej oznaczają słabą zdolność dyskryminacyjną.
Na czym polega uczenie sztucznych sieci neuronowych, wymień jeden algorytm uczenia.
Uczenie polega na iteracyjnej zmianie wartości wag połączeń Przykładowy algorytm: wsteczna propagacja błędów (backpropagation)
W jaki sposób możemy poprawić moc predykcyjną modelu sieci neuronowej?
Przez zwiększenie/oczyszczenie danych uczących, selekcję i transformację zmiennych.
Jak interpretujemy miarę Lift w analizie asocjacji?
Lift > 1 oznacza dodatnią zależność, Lift = 1 — niezależność zdarzeń, Lift < 1 — zależność ujemną.

Oceń moc predykcyjną modelu (tabela AUC/MISC).
AUC wartości bliskie 0,85–0,88 świadczą o dobrej zdolności dyskryminacyjnej modelu. Niewielki spadek AUC i wzrost MISC błędu od próby uczącej do testowej wskazują na lekkie przeuczenie, ale różnice są małe — model jest stabilny i ma dobrą moc predykcyjną.
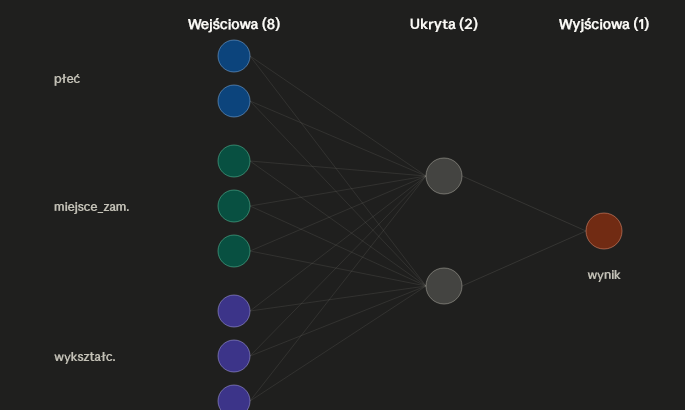
Narysuj schemat MLP (jedna warstwa ukryta z dwoma neuronami; płeć – 2 poziomy, miejsce_zamieszkania – 3 poziomy, wykształcenie – 3 poziomy; jeden neuron wyjściowy).
Czy zmienne do analizy skupień (klasteryzacji) powinny być wystandaryzowane?
a) niekoniecznie, jeśli zbiór jest mało liczny to nie muszą być wystandaryzowane
b) tak, ponieważ rozkłady będą wówczas miały taki sam rozkład
c) tak, powinny być wystandaryzowane ponieważ wykorzystujemy odległości pomiędzy obserwacjami
c) tak, powinny być wystandaryzowane ponieważ wykorzystujemy odległości pomiędzy obserwacjami
Co daje nam w budowie drzew decyzyjnych podział binarny?
a) mniej rozbudowane drzewo decyzyjne
b) lepszą jakość podziału w przypadku dużej liczby zmiennych
c) lepsze dopasowanie modelu do danych
b) lepszą jakość podziału w przypadku dużej liczby zmiennych
Czym jest ufność i wsparcie w analizie koszykowej?
a) wsparcie to częstość występowania badanej reguły wśród wszystkich przypadków, natomiast ufność to częstość występowania reguły wśród transakcji zawierających pierwszy produkt
b) wsparcie to częstość występowania badanej reguły wśród przypadków zawierających drugi produkt, natomiast ufność to częstość występowania reguły wśród transakcji zawierających pierwszy produkt
c) wsparcie to częstość występowania badanej reguły wśród wszystkich przypadków, natomiast ufność to częstość występowania reguły wśród transakcji zawierających przynajmniej drugi produkt
a) wsparcie to częstość występowania badanej reguły wśród wszystkich przypadków, natomiast ufność to częstość występowania reguły wśród transakcji zawierających pierwszy produkt
Jaki cel ma tworzenie zbioru testowego?
a) zbiór testowy to zbiór do niezależnej oceny wybranego modelu
b) zbiór testowy to zbiór do przycinania drzew decyzyjnych
c) zbiór testowy służy do oceny dopasowania modelu
a) zbiór testowy to zbiór do niezależnej oceny wybranego modelu
W jaki sposób w oparciu o kryterium Entropii wybierany jest podział drzewa decyzyjnego?
a) im mniejsza wartość Entropii tym lepsza jakość podziału
b) im większa wartość Entropii tym lepsza jakość podziału
c) jakość podziału nie zależy od wartości Entropii
a) im mniejsza wartość Entropii tym lepsza jakość podziału
Jakie jest zadanie funkcji aktywacji w modelu sztucznego neuronu?
a) agregacja informacji na wejściu do neuronu
b) przekształcenie informacji na wyjściu z neuronu
c) przekształcenie informacji na wejściu do neuronu
b) przekształcenie informacji na wyjściu z neuronu
Jaką największą wadę mają sieci neuronowe, jak można sobie z nią radzić?
a) sieci neuronowe bardzo często bywają przeuczone, zbytnio dopasowują się do zbioru walidacyjnego, należy usunąć zbędne zmienne z modelu i oszacować model ponownie
b) największą wadą sieci neuronowych jest brak interpretacji zależności między zmienną zależną a zmiennymi objaśniającymi, można przybliżyć interpretację za pomocą drzewa decyzyjnego na wyniku sieci neuronowej
c) największą wadą sieci jest skomplikowana architektura która powoduje że oszacowanie modelu jest bardzo czasochłonne i wymaga bardzo dużego zbioru danych
b) największą wadą sieci neuronowych jest brak interpretacji zależności między zmienną zależną a zmiennymi objaśniającymi, można przybliżyć interpretację za pomocą drzewa decyzyjnego na wyniku sieci neuronowej
W jaki sposób w oparciu o kryterium Chi-kwadrat wybierany jest podział drzewa decyzyjnego?
a) wybierany jest podział o najniższej wartości statystyki Chi-kwadrat
b) wybierany jest podział o najwyższej wartości p-value dla Chi-kwadrat
c) wybierany jest podział o najwyższej wartości logworth dla Chi-kwadrat
c) wybierany jest podział o najwyższej wartości logworth dla Chi-kwadrat
Czy w modelu regresji logistycznej zmienne objaśniające mogą być ciągłe? Jakie jest ograniczenie na liczbę zmiennych objaśniających?
a) nie mogą być ciągłe, zmienne ciągłe muszą zostać zdyskretyzowane przed włączeniem do modelu, nie ma ograniczenia na liczbę zmiennych objaśniających
b) mogą być ciągłe, ograniczeniem na liczbę zmiennych objaśniających jest liczba obserwacji w zbiorze
c) mogą być ciągłe, nie ma ograniczenia na liczbę zmiennych objaśniających
b) mogą być ciągłe, ograniczeniem na liczbę zmiennych objaśniających jest liczba obserwacji w zbiorze
Czym się różnią sieci radialne od standardowych sieci neuronowych?
a) sieci radialne wykorzystują tylko dyskretne zmienne objaśniające
b) sieci radialne wymagają standaryzacji zmiennych wejściowych do modelu
c) sieci radialne wykorzystują funkcje radialne zamiast liniowej funkcji kombinacji
c) sieci radialne wykorzystują funkcje radialne zamiast liniowej funkcji kombinacji