Kaarten: H10: Lineaire regressie met nominale predictoren | Quizlet
1/43
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
44 Terms
Met welke variabelen kan lineaire regressie gerbuikt worden?
- afhankelijke variabele (Y) van ratio of intervalniveau
- onafhankelijke variabele / predictoren (X) van ratio of intervalniveau of als ze dichotoom (0-1) zijn
MAAR: er bestaat een truc om lineaire regressie toch te knn gebruiken met nominale predictoren
Lineaire regressie met dichotome predictoren
-> Één dichotome predictor
-> adoptievoorbeeld: we willen nagaan of duur van adoptieprocedure (Y) verklaard kan worden door de conditie: hoe kunnen we dat model herschrijven?
Klassieke vergelijking van het lineaire model.
Variabele conditie kan slechts 2 waarden aannemen: 0 of 1. Dit heeft een aantal consequenties voor de interpretatie van het model.

Lineaire regressie met dichotome predictoren
-> Één dichotome predictor
-> adoptievoorbeeld: wat is de corresponderende voorwaardelijke verwachting?
De formule van de voorwaardelijke verwachting is altijd het lineair model, zonder de foutterm.
- de v.verwachting voor de controle conditie is gewoon gelijk aan het intercept, nl. β₀.
- de v.verwachting voor de exp. conditie is gelijk aan β₀ + β_conditie.
Het verschil tussen de 2 condities is gewoon ' β_conditie. '.
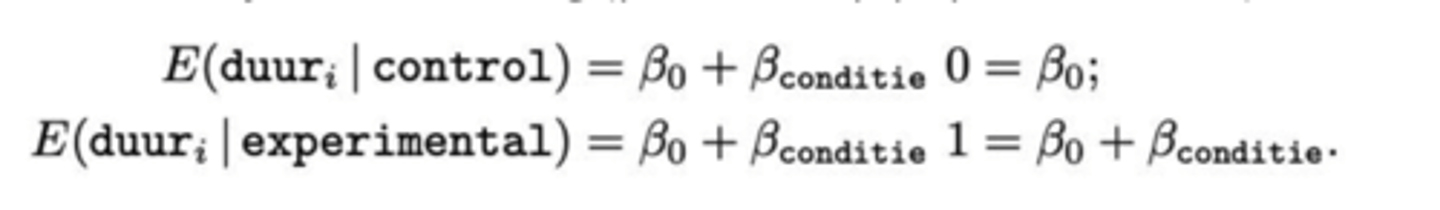
Lineaire regressie met dichotome predictoren
-> Één dichotome predictor
-> adoptievoorbeeld: lineair model maakt eenvoudige predicties: waaraan zijn de predicties in de controlegroep gelijk? Waaraan zijn de predicties in de experimentele groep gelijk?
(hernoemen)
controlegroep: β₀ -> μ_control
(de predicties van de controle groep zijn allemaal gelijk aan een vast getal β₀)
experimentele groep: β₀ + β_conditie -> μ_experimental
(de predicties van de exp. groep zijn allemaal gelijk aan een ander vast getal β₀ + β_conditie)
Lineaire regressie met dichotome predictoren
-> Één dichotome predictor
Hoe luidt de alternatieve hypothese voor het adoptievoorbeeld?
Ha: μ_experimental ≠ μ_control
Lineaire regressie met dichotome predictoren
-> Één dichotome predictor
Hoe kunnen we de 4.900 interpreteren onder 'Coefficients'?
Remember: de v.verwachting binnen de controle groep = β₀
-> 4.900 = de verwachting binnen de controlegroep = een duur van 4.9 jaar

Lineaire regressie met dichotome predictoren
-> Één dichotome predictor
Hoe kunnen we de -0,4992 interpreteren onder 'Coefficients'?
Dat is het verschil met de controle conditie.
Het betekent dat in de experimentele conditie de duur ongeveer een halfjaar korter (0.5 jaar) is.

Lineaire regressie met dichotome predictoren
-> Één dichotome predictor
Wat is de p-waarde en hoe kunnen we deze interpreteren?
p-waarde = 0.415 > 0.05 -> H₀ aanvaarden
Dit betekent: Het verschil tussen de 2 groepen (controle en experimenteel) is niet sterk genoeg om te beslissen dat de experimentele procedure sneller is.

T-toets VS meervoudige lineaire regressie
- t-toets kan je uitvoeren wnr je slechts één predictor hebt
- t-toets kan je niet meer gebruiken wanneer je meer dan één predictor hebt, dus je moet meervoudige lineaire regressie gebruiken
! Welsh t-toets is vr 2 groepen, en als je 2 predictoren hebt, heb je meer dan 2 groepen.
Lineaire regressie met dichotome predictoren
-> Één dichotome predictor
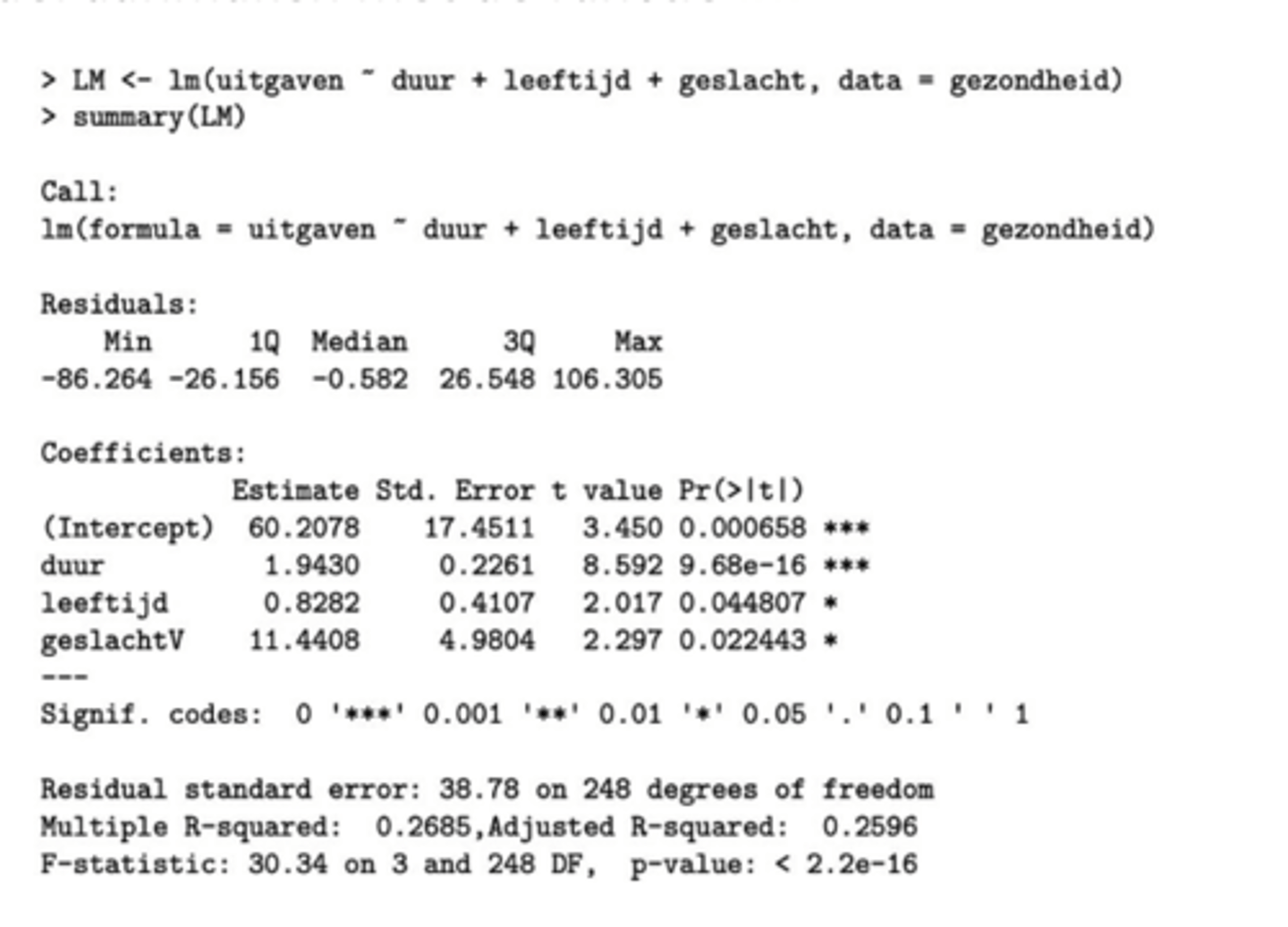
Toepassing: gezondheidsuitgaven
Wat is de interpretatie van het getal 11.4408 bij 'Coefficients'?
Dat is het verschil qua uitgaven tussen mannen en vrouwen. (ongeveer €11.40)
Er staat 'geslachtv' -> vrouwen spenderen €11.40 meer.

Lineaire regressie met dichotome predictoren
-> Één dichotome predictor
Toepassing: gezondheidsuitgaven
Wat betekenen de getallen 1.9430 en 0.8282?
β_duur: per extra maand werkloos, €1.9430 meer
β_leeftijd: per jaar ouder, €0.8282 euro meer
Lineaire regressie met dichotome predictoren
-> Één dichotome predictor
Toepassing: gezondheidsuitgaven
Wat is de p-waarde voor het geslacht en hoe kunnen we deze interpreteren?
p-waarde = 0.022443 < 0,05 -> H₀ verwerpen en Ha aanvaarden.
Interpretatie: het geslacht is een predictor voor de uitgaven, rekening houdend met de 2 andere variabelen (duur en leeftijd).

Lineaire regressie met nominale predictoren: wat zijn hulpveranderlijken?
Stel dat we een model willen analyseren waarbij een predictor nominaal is, met meer dan twee niveaus -> we gaan die nominale predictor vervangen door meervoudige 0-1 predictoren = hulpveranderlijken.
Lineaire regressie met nominale predictoren: hoe moeten we een nominale predictor met I niveau's hercoderen?
tot I-1 nieuwe hulpveranderlijken (0-1 variabelen) die we vervolgens in het regressiemodel kunnen stoppen
Lineaire regressie met nominale predictoren: we willen 4 types behandelingen vergelijken (A, B, C, D), waarom kunnen we hier geen t-toets voor gebruiken?
+ hoe moeten we de variabele dan hercoderen?
Geen t-toets omdat deze enkel de verwachtingen van twee groepen kan vergelijken (niet meer dan twee) & hier zitten we met 4 groepen!
We moeten de variabele behandeling hercoderen tot 3 (4-1 -> komt van I-1 hulpveranderlijken coderen) nieuwe hulpveranderlijken met 2 niveaus: 0 en 1.
Hercodering
Dummy-codering: hoe gaat dat in zijn werk?
we kiezen hierbij één van de I niveau's als referentieniveau en de andere niveau's worden via een 0-1 variabele gecodeerd
Hercodering
Dummy-codering: welke codering bekomen we als we behandeling D als referentieniveau beschouwen?

Hercodering
Dummy-codering: hoe kunnen we het effect van de behandeling op de verwachting van reactietijd Y modelleren?
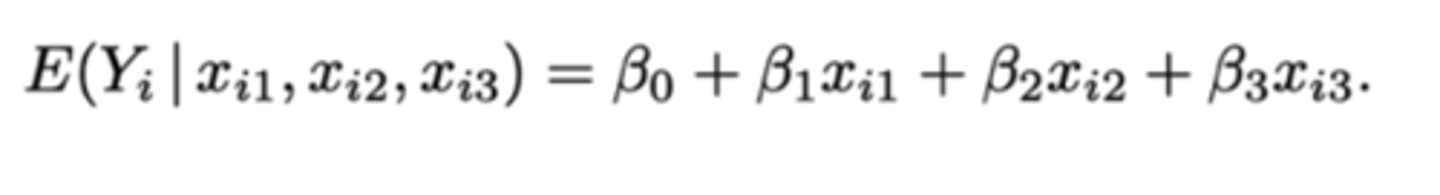
Hercodering: dummy-codering
Lineaire regressie met nominale predictoren: naargelang de codering van het regressieschema hebben de regressieparameters een andere betekenis
β₀ = de verwachting van de referentiegroep = behandeling D
β₁ = A-D
β₂ = B-D
β₃ = C-D
Elke β (behalve β₀) representeert een verschil t.o.v. de referentiegroep.
(ben nie zeker of dit klopt?)
Hercodering: dummy-codering
Waaraan is de voorwaardelijke verwachting van participanten in groep D gelijk?
β₀
We kunnen de termen β₁xi1, β₂xi2, β₃xi3 allemaal schrappen, want ze zijn gelijk aan 0 -> β₀ blijft over.
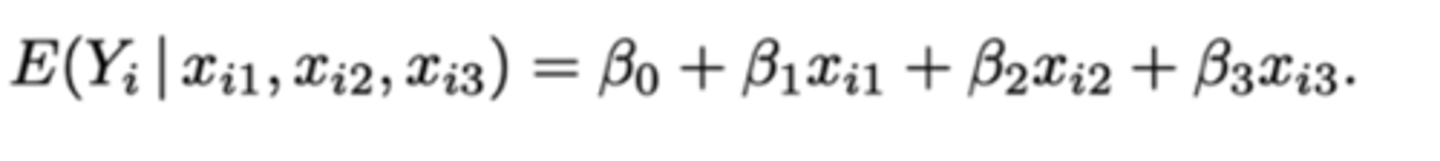
Hercodering: dummy-codering
Waaraan is de voorwaardelijke verwachting van participanten in groep A gelijk?
β₀ + β₁
We kunnen de termen β₂xi2 en β₃xi3 schrappen, want deze zijn gelijk aan 0.
β₁xi1 behouden we, omdat deze gelijk is aan 1.
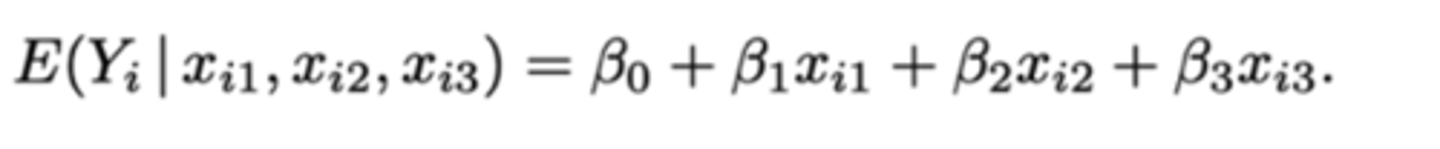
Hercodering: dummy-codering
Waaraan is de voorwaardelijke verwachting van participanten in groep B en D gelijk?
groep B: β₀ + β₂
groep C: β₀ + β₃
Hercodering: effect-codering: hoe gaat dit in zijn werk?
Bij dit soort codering wordt ook een groep gekozen, maar ipv 0 gebruiken we -1 om te hercoderen.
! deze groep wordt niet als referentie beschouwd
Hercodering: effect-codering: welke codering bekomen we?
β₀ = 'marginale gemiddelde' = het gemiddelde van de voorwaardelijke voorwachtingen in de 4 groepen (correspondeert met geen enkele specifieke groep)
β₁ = verschil tussen groep A en het gemiddelde van alle groepen (marginale gemiddelde)
β₂ = verschil tussen groep B en het gemiddelde van alle groepen
β₃ = verschil tussen groep C en het gemiddelde van alle groepen
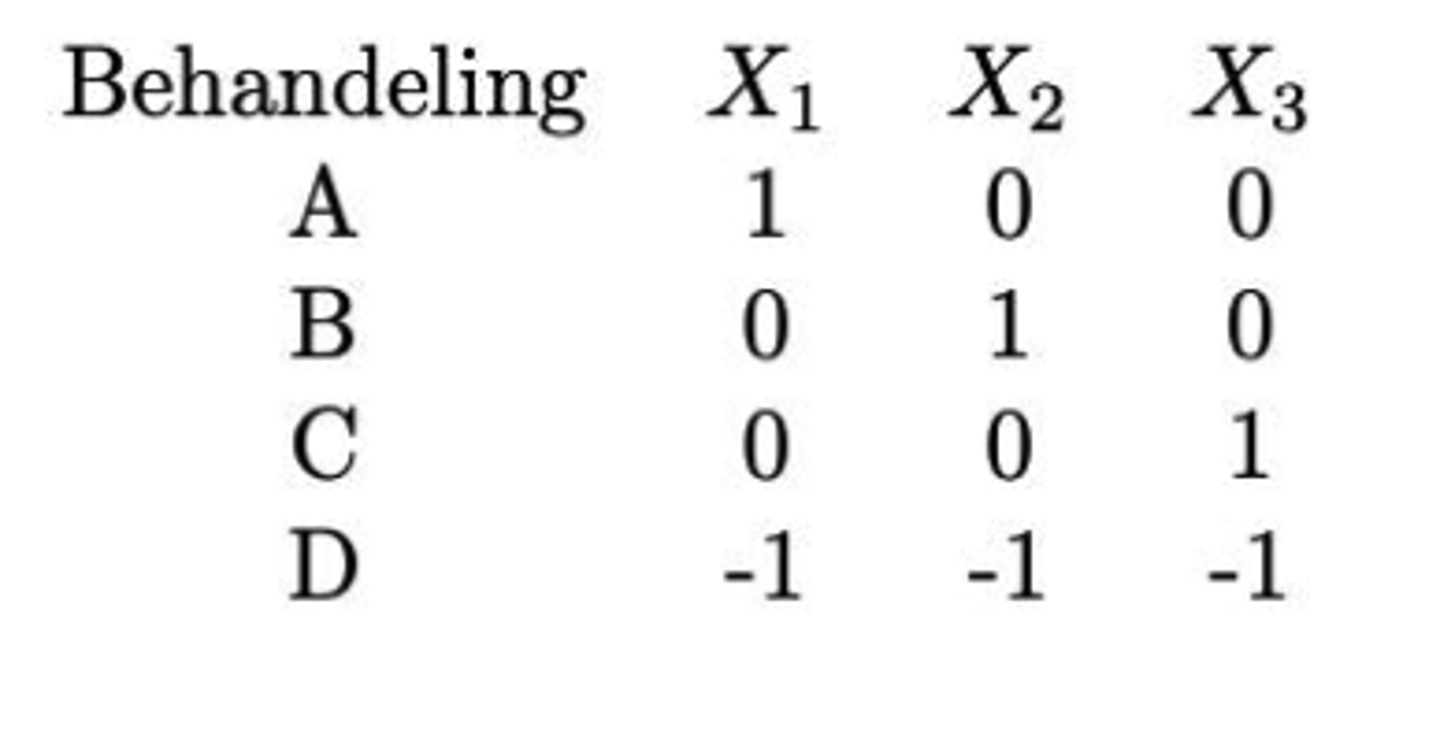
Hercodering: effect-codering: naargelang het coderingsschema dat gehanteerd wordt, hebben de regressieparameters een andere betekenis.
Waaraan is de verwachting van groep A, groep B, groep C en groep D gelijk?
groep D: β₀ - β₁ - β₂ - β₃
groep A: β₀ + β₁
groep B: β₀ + β₂
groep C: β₀ + β₃
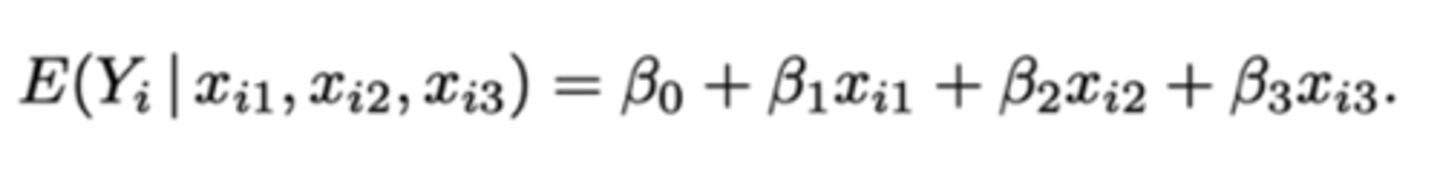
Hercodering: effect-codering: hoe kunnen we het effect van de behandeling op de verwachting van de reactietijd Y modelleren?
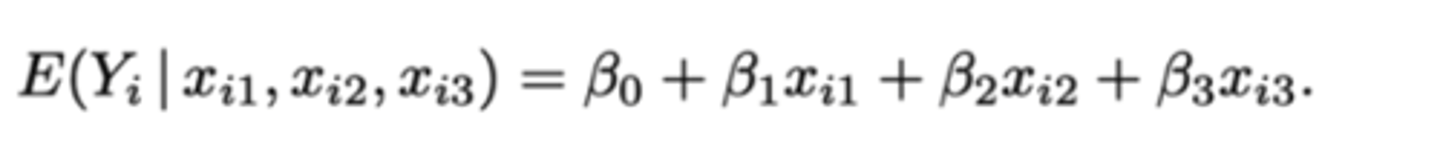
Welke hypothese gaan we nooit toetsen en waarom niet?
De variabele Xi heeft geen betekenis in zich, stel dat we weten dat x1i = 0 bij individu i -> geeft ons geen duidelijke informatie over dat individu. We hebben de score op alle hulpveranderlijken nodig om te weten tot welke groep een individu behoort!
-> we gaan dus nooit toetsen of βj al dan niet 0 is.
Als we modellen vergelijken, wat gaan we nooit vergelijken met elkaar?
NOOIT een model beschouwen met de hulpveranderlijke X1 en zonder de hulpveranderlijke X2
-> indien we willen toetsen of een nominale variabele predictor is van Y, dan gaan we het model met alle hulpveranderlijken vergelijken met het model zonder de hulpveranderlijken, a.d.h.v een F-toets (resultaat van deze toets is onafhankelijk van het gehanteerde coderingsschema: dummy- en effectcodering geven dezelfde resultaten + onafhankelijk van het gekozen referentieniveau)
Wat gaat R automatisch doen als we de functie lm gebruiken en wnr één (of meerdere) predictor(en) nominaal is (zijn)?
- R gaat automatisch kiezen voor dummy-codering, met het eerste niveau als referentieniveau
- R gaat ook zelf hulpveranderlijken definiëren
Berekeningen met R
Waarom gaan we de p-waarden van de predictoren hier niet apart bekijken? Waarnaar dienen we wel te kijken?
Deze p-waarden zijn niet relevant, omdat 1 hulpveranderlijke in zich geen betekenis heeft.
We moeten wel kijken naar de F-statistic, aangezien enkel de vergelijking van de modellen (met hulveranderlijken vs. zonder) relevant is!

Berekeningen met R
Waarom gaan we het intercept 24.97628 hier niet interpreteren?
De correcte interpretatie zou zijn: het intercept is de schatting van μ_tijd bij individuen die aan een andere sport doen en waarbij de variabelen lengte en sport nul zijn (we plaatsen de andere variabelen op 0). Zulke individuen bestaan uiteraard niet en het intercept heeft dus geen concrete en intuïtieve betekenis.

Berekeningen met R
Hoe moeten we het getal -0.04436 (lengte) interpreteren?
De coëfficiënt van lengte is 0.04436 = schatting van β.
Het betekent dat twee individuen met een verschil van één cm lengte en met identieke scores op alle andere variabelen, een verschil van -0.00436 seconde zullen ervaren op tijd.
-> OF: de tijd zal -0.00436 seconde lager zijn bij een individu dat 1cm groter is, maar gelijk op alle andere variabelen.
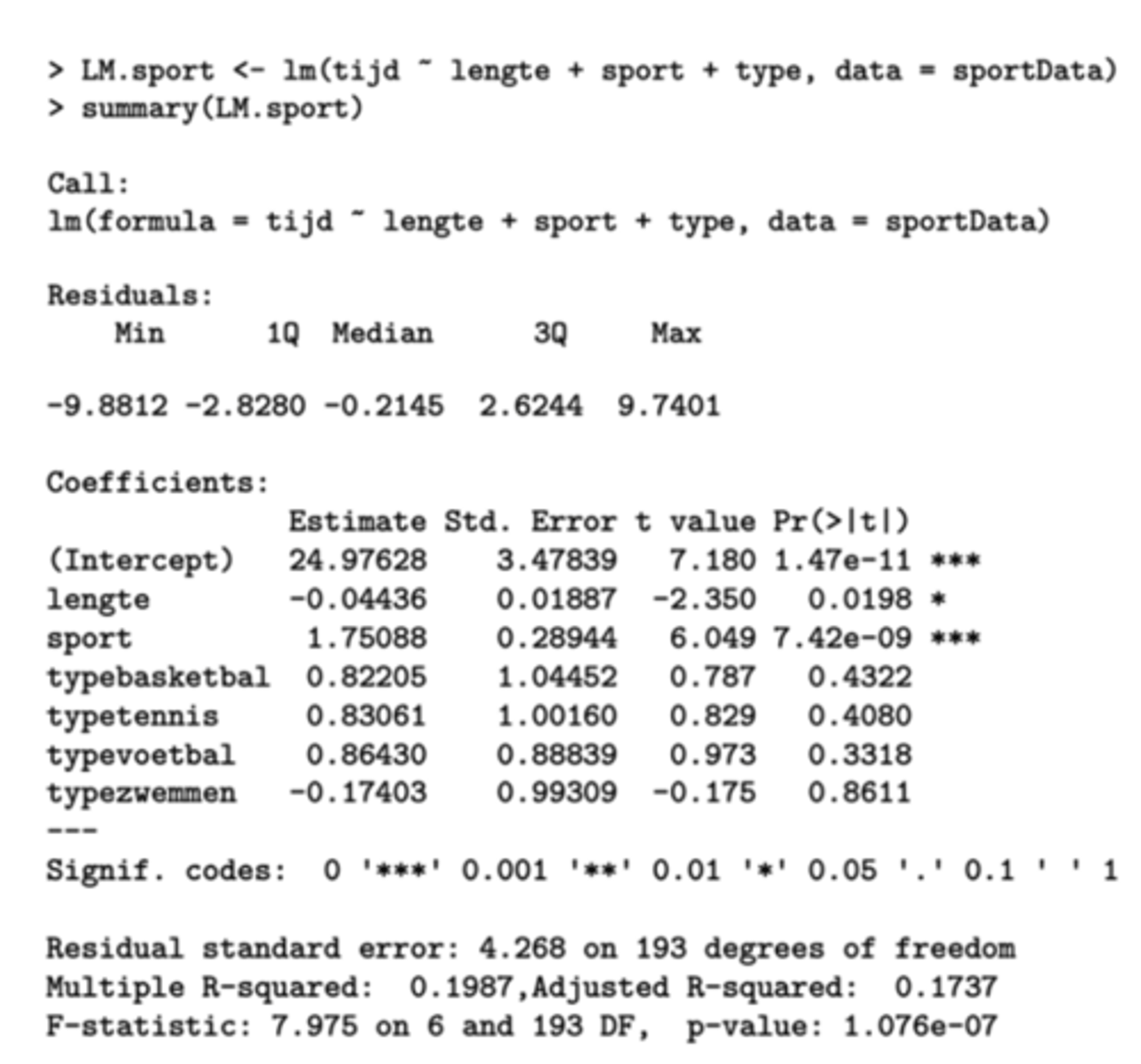
Berekeningen in R
Hoe kunnen we de coëfficiënt van typebasketbal interpreteren?
De coëfficiënt van typebasketbal representeert het gemiddelde tijdsverschil tussen een individu die aan basketbal doet en een individu die aan "andere" doet, indien ze identieke scores hebben op de andere variabelen.
Analoge interpretatie geldt voor de andere coëfficiënten.

welke R-functie gebruiken we om de gemiddelden van drie groepen apart te krijgen?
aggregate
Wat betekent het argument FUN in R?
Waarvoor gebruiken we: FUN = mean
- het is de afkorting van functie
- FUN = wordt gebruikt om aan te geven dat we het gemiddelde willen berekenen
Wat maakt het argument formula duidelijk?
Dat we wensen de variabele inkomenswijziging (afhankelijke variabele Y) te voorspellen mbv de predictor groep (onafhankelijke variabele X)
Anova
Was initieel t-toets om twee verwachtingen te vergelijken, maar is veralgemeend om verwachtingen in p groepen te vergelijken.
Wanneer spreken we van one-way anova?
Indien de groepen bepaald worden op basis van één nominale variabele.
Vb. de verwachte scores op het examen statistiek in de groepen psychologie studenten, pedagogie studenten en sociaal werk studenten. Variabele van belang = opleiding.
Wanneer spreken we van two-way anova?
Indien de groepen bepaald worden op basis van 2 nominale variabelen.
Vb. de verwachte scores op het examen statistiek, waarbij de nominale variabelen opleiding en geslacht zijn.
Wat wordt nagegaan bij een variantie-analyse (anova)?
Of de verschillen tussen twee groepen het effect van het toeval kunnen zijn of niet.
Wat laat lineaire regressie toe in vergelijking tot anova?
Lineaire regressie laat ook toe om continue predictoren van ratio of interval meetniveau te gebruiken -> lineaire regressie is dus algemener. Drm opteren we om geen variantie-analyse te gebruiken.
Waarvan spreken we bij variantie-analyse in de plek van: SSmod?
SSbetween
Waarvan spreken we bij variantie-analyse in de plek van SSRes
SSwithin
Wordt de determinatiecoëfficiënt bij variantie-analyse en lineaire regressie op dezelfde manier berekend?
Ja.