Lecture 7: Shallow Neural Networks
1/79
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
80 Terms
How do AWS define a NN?

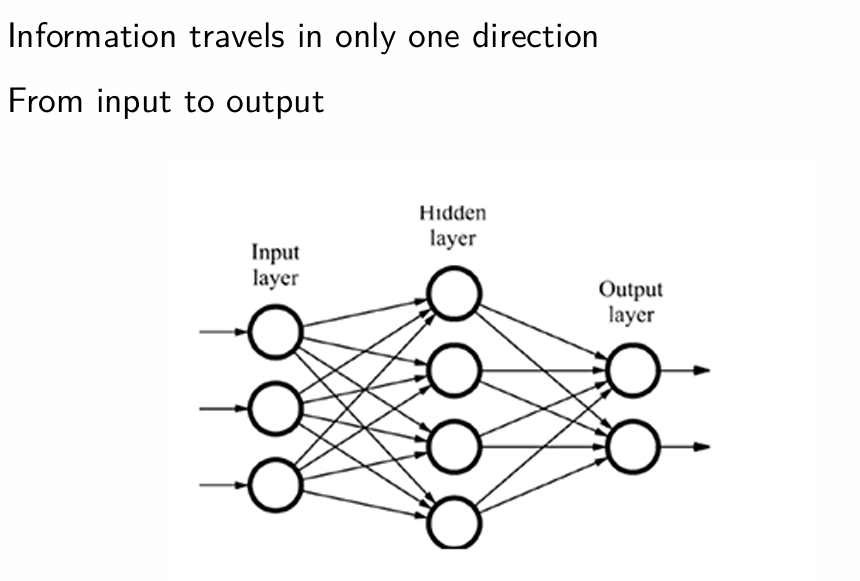
How do Feedforward NN work?
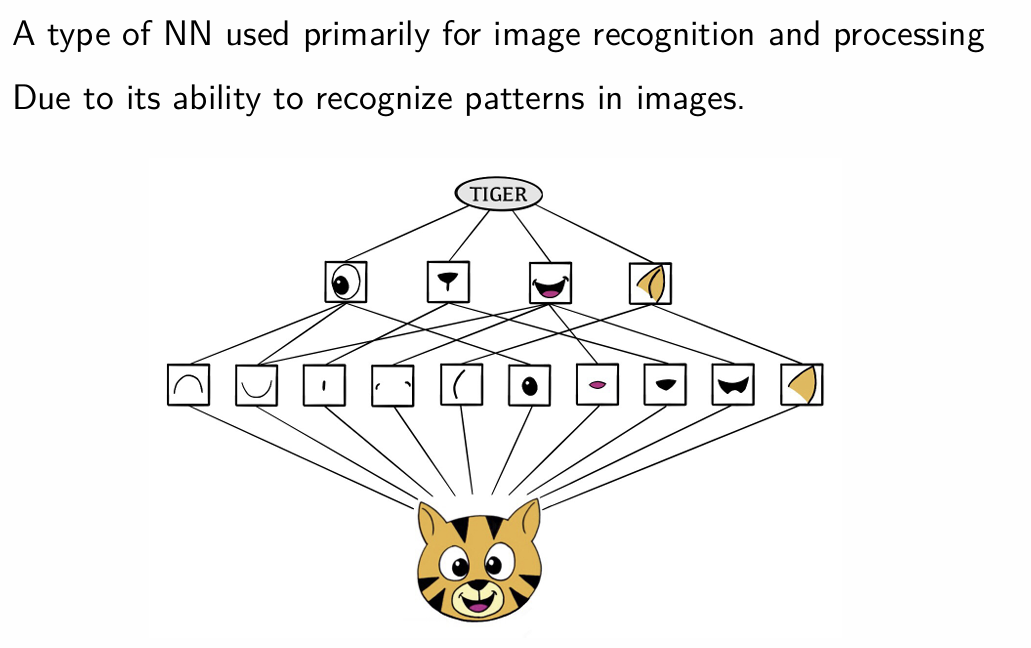
How do Convolutional NN work?
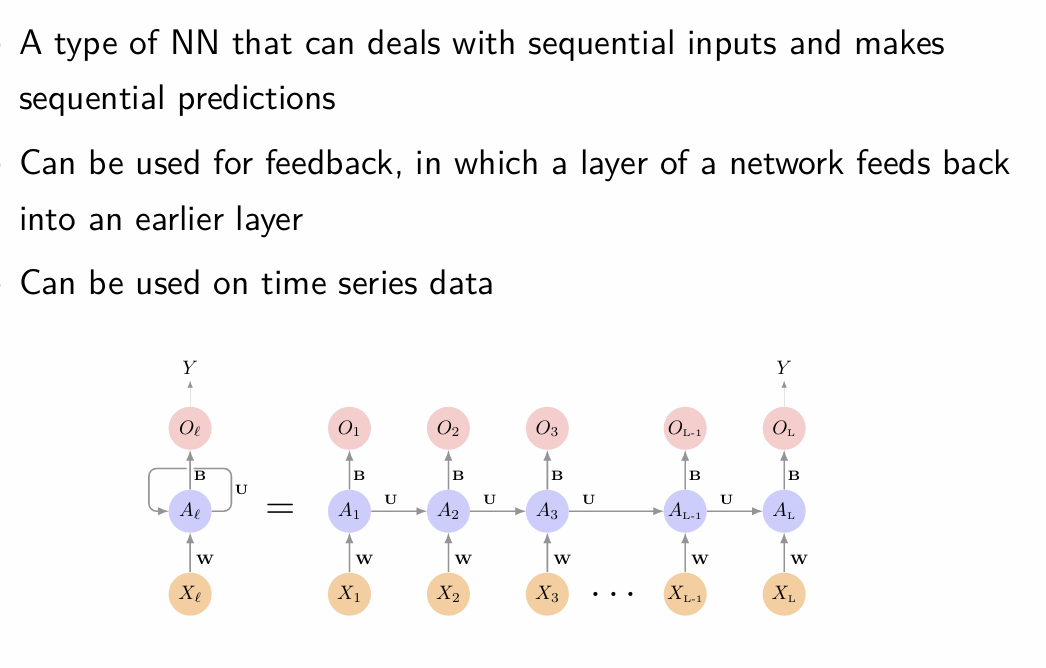
How do Recurrent NN work?
What are the two types of Feedforward NN?
Shallow and Deep
In a SNN, what are the input and output layer connected by?
Single Hidden Layer; single layer makes it shallow
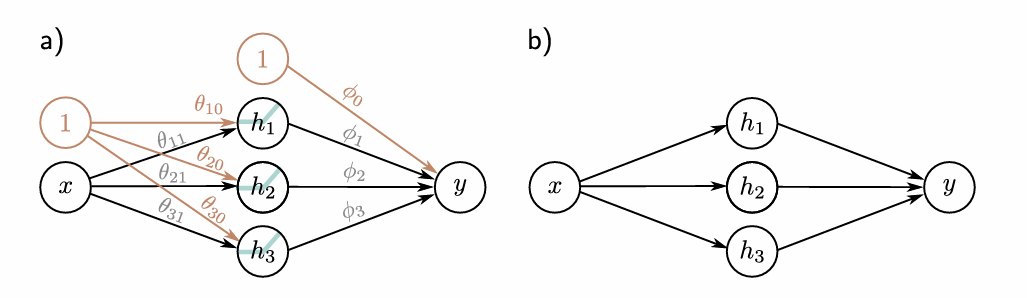
How many units does this Hidden Layer have?
Three units (h1, h2, h3)
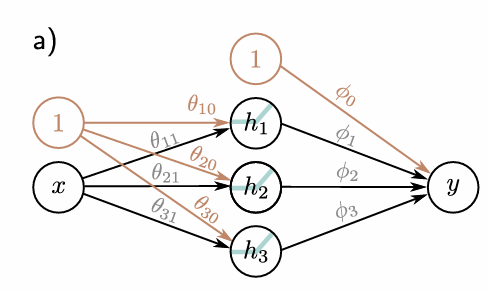
What are the inputs into the hidden layer?

What are the inputs in the hidden layer then subjected to?
Activation Function, a()

What does the Activation Function then give?

Where are the outputs from the hidden layer then fed to?
The output layer, giving the final output
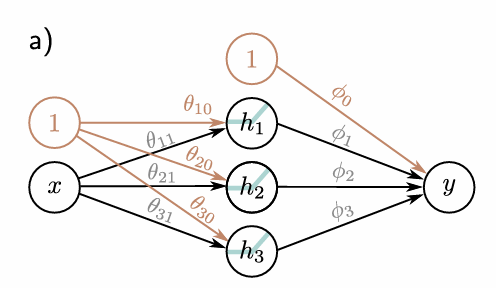
What is the final output?
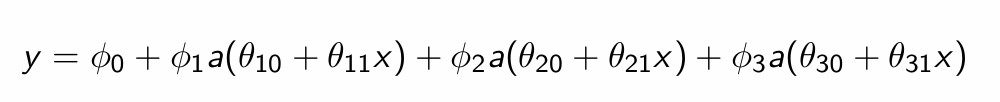
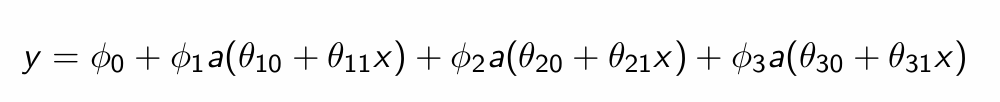
How many parameters does this NN have?
10
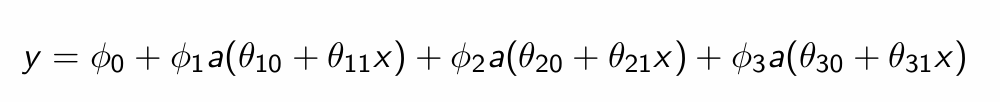
What do those parameters represent?
What Activation Function do we use?
Rectified Linear Unit (RELU)
What does the RELU do?
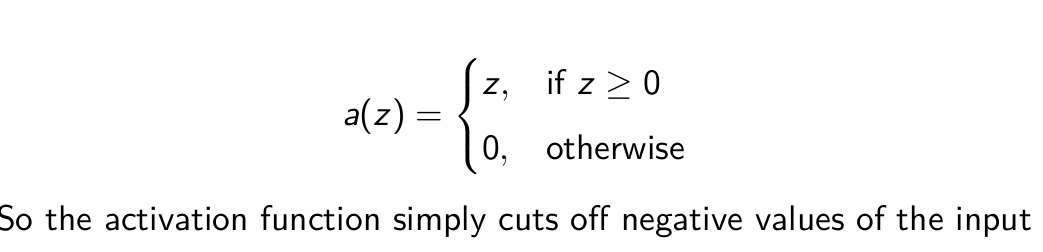
How can do we define the RELU function in R?

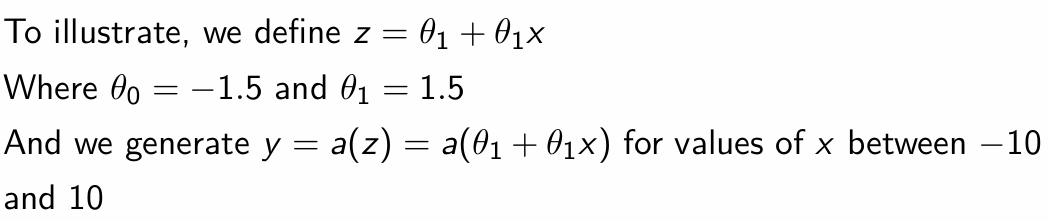
How would this look with RELU?
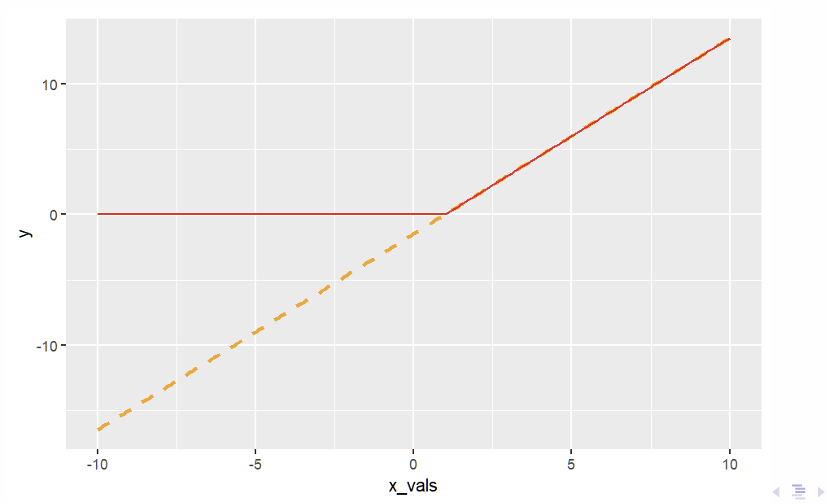
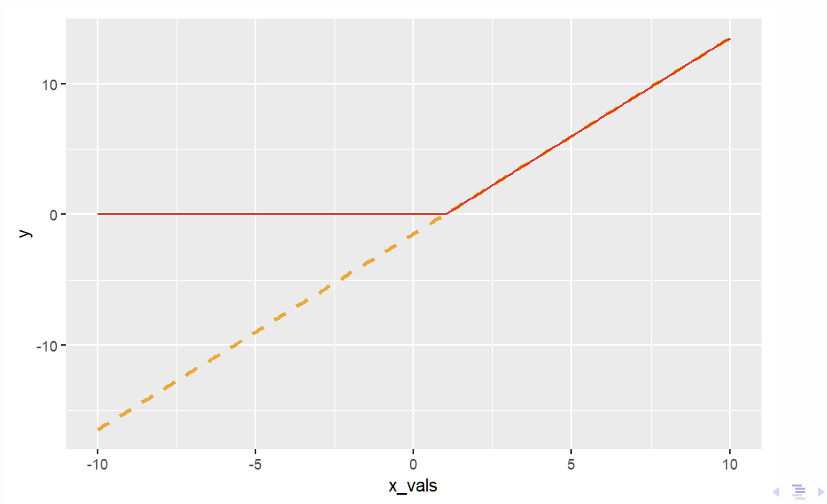
What does this plot show and how do we plot it in R?

What is a combination of RELUs known as and why is it useful?

How does the Universal Approximation Theorem look graphically?
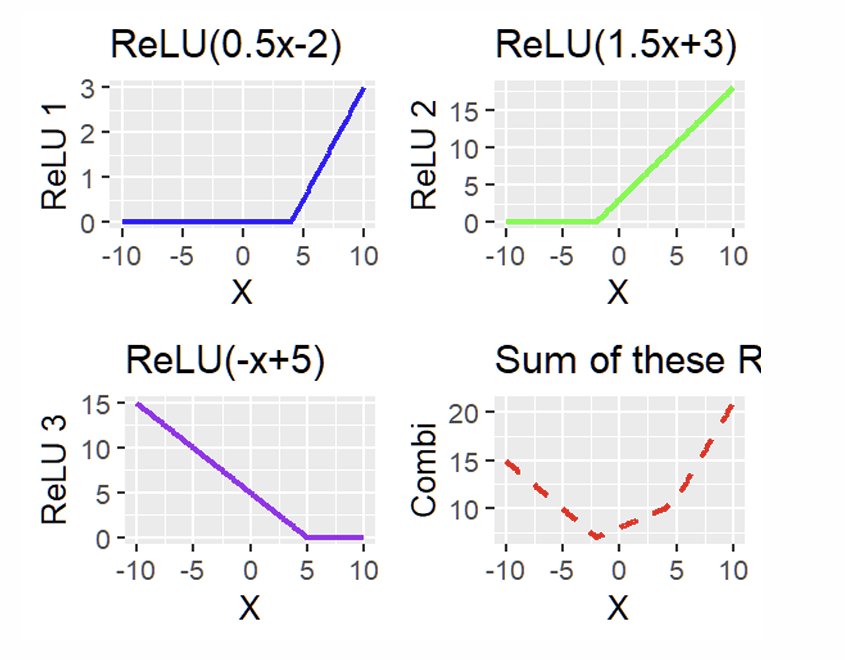
What other Activation Function do we use?
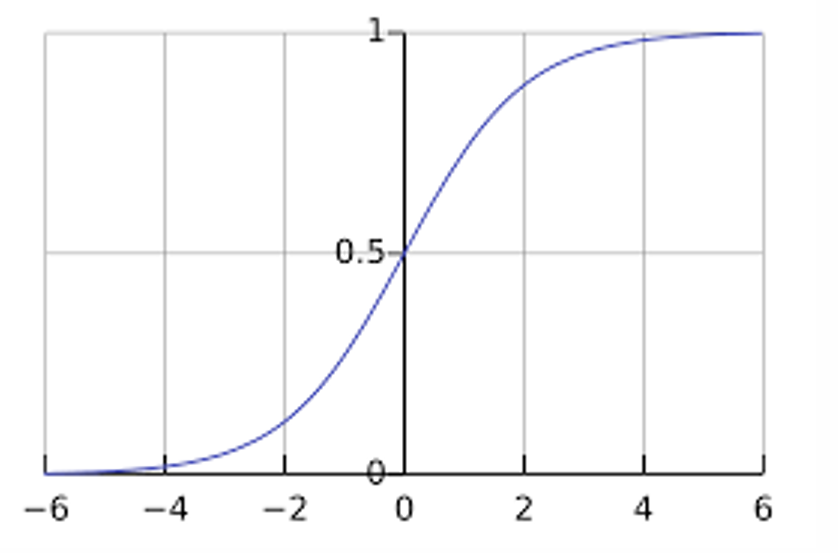
Sigmoid
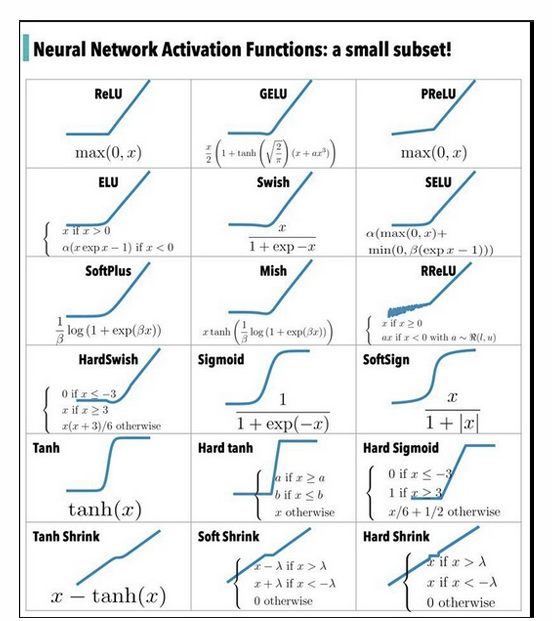
What other Activation Functions exist?
What does the algorithm that selects the value of the parameters do?

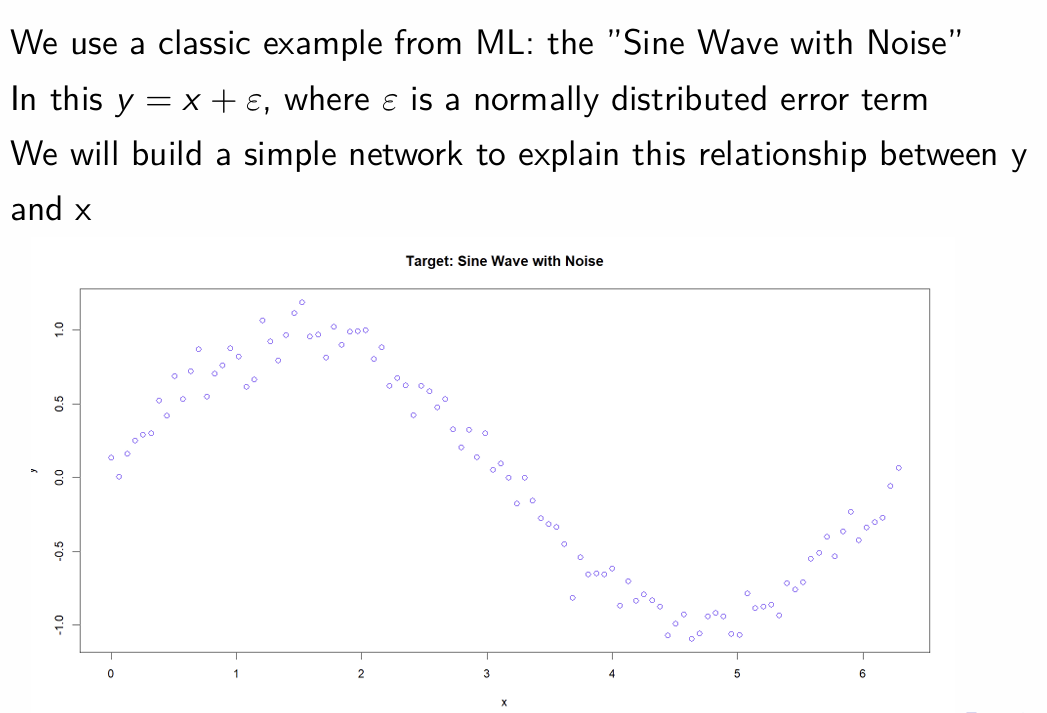
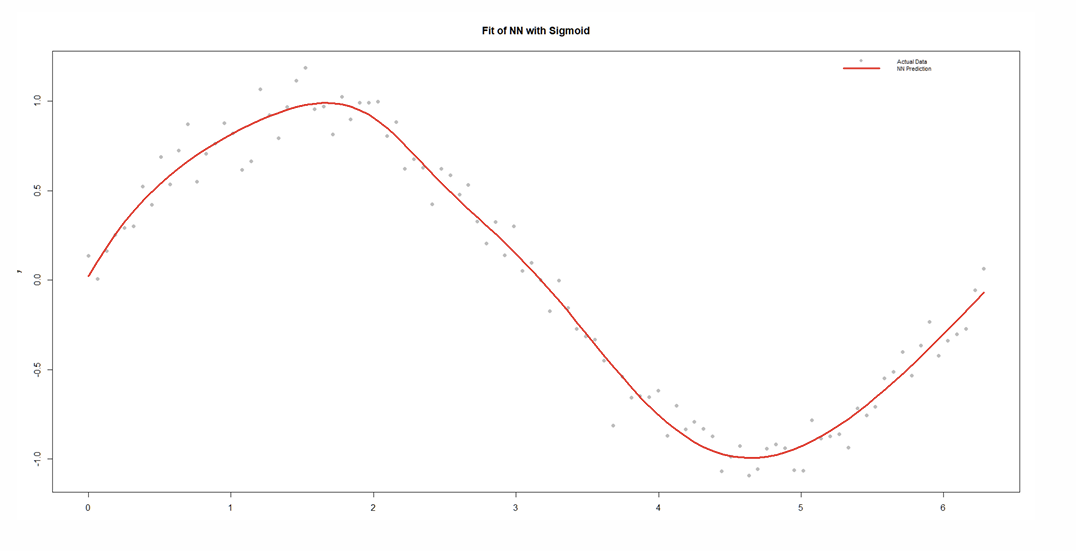
What is the “Sine Wave with Noise” example?
What code is used in R to train the NN?


What do each of the hyperparameters do?


What does the estimated network look like?
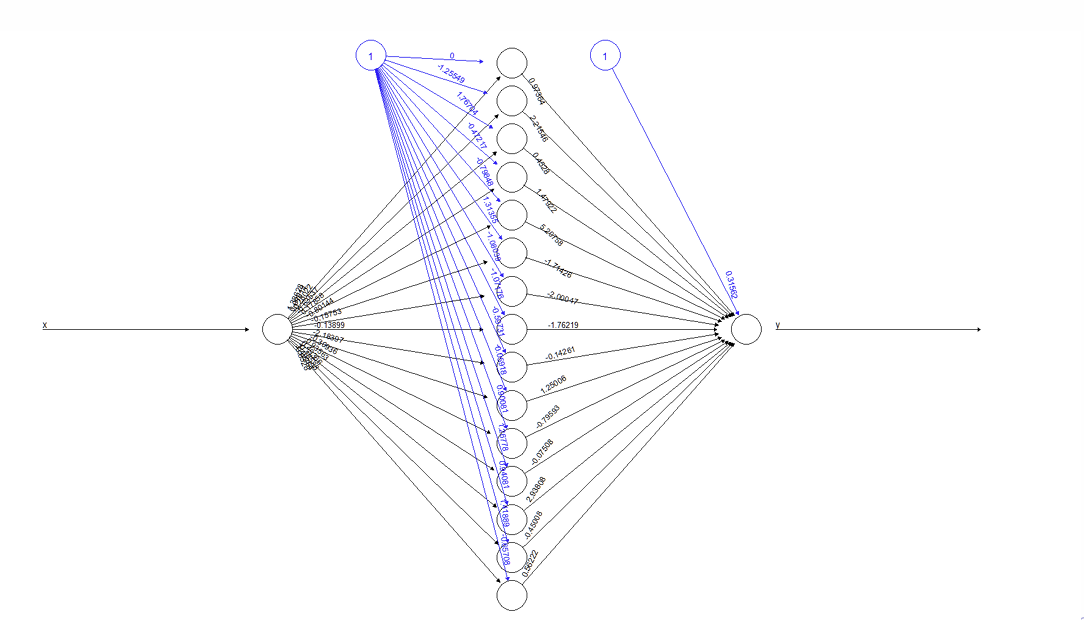
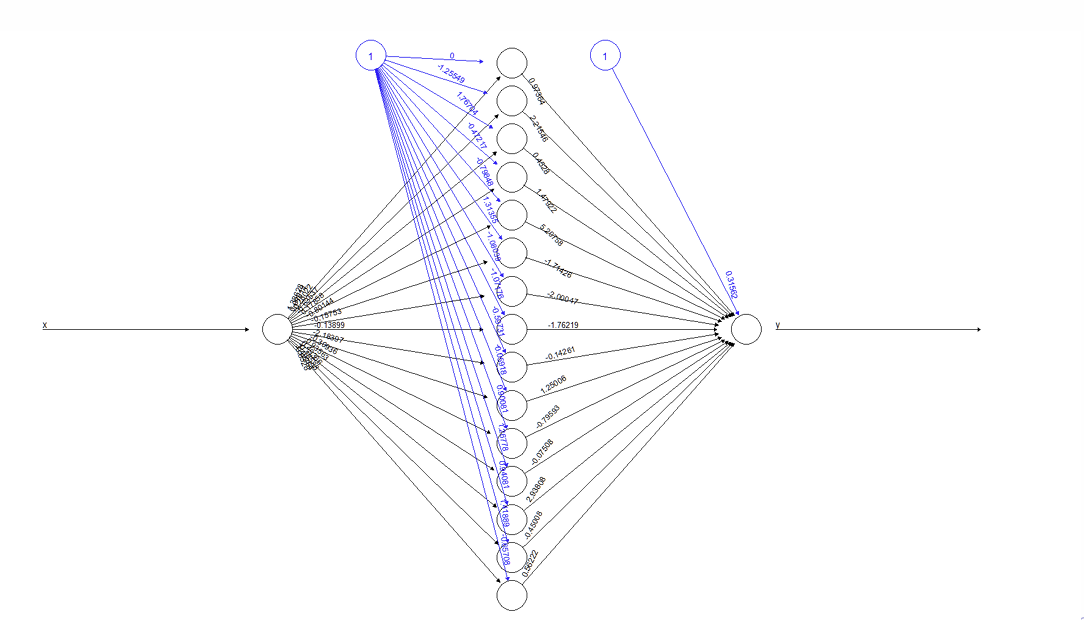
How many weights and offsets are there when the input feeds into each unit in the hidden layer?
15 weights and 15 offsets
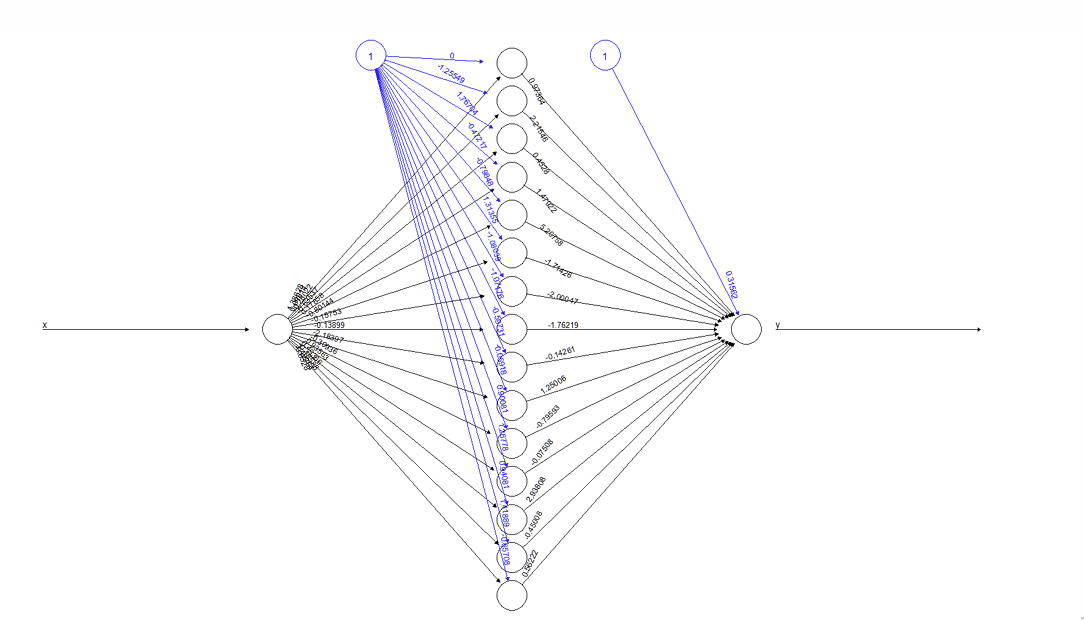
How many weights and offsets are there when each unit in the hidden layer feeds into the output layer?
The algorithm then estimates values for both sets
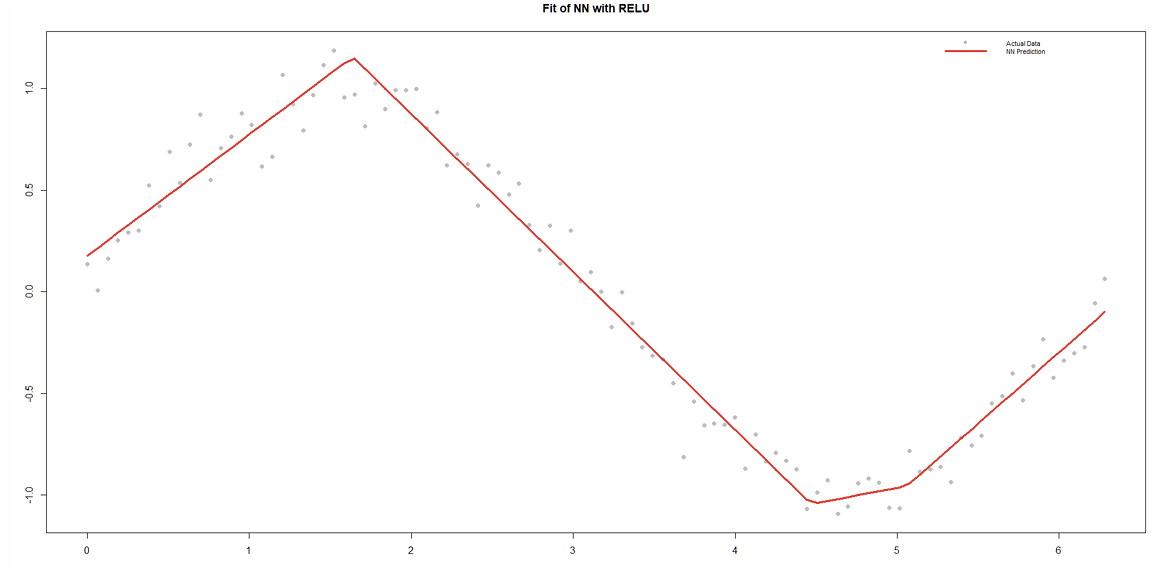
What does the estimated NN plot with RELU look like?
What is the Sigmoid Activation Function also known as?
Logistic Activation Function
In this context, how are the Sigmoid and Logistic functions related?
The same
How do the Sigmoid and RELU Activation Functions compare?
Smoother fit than RELU
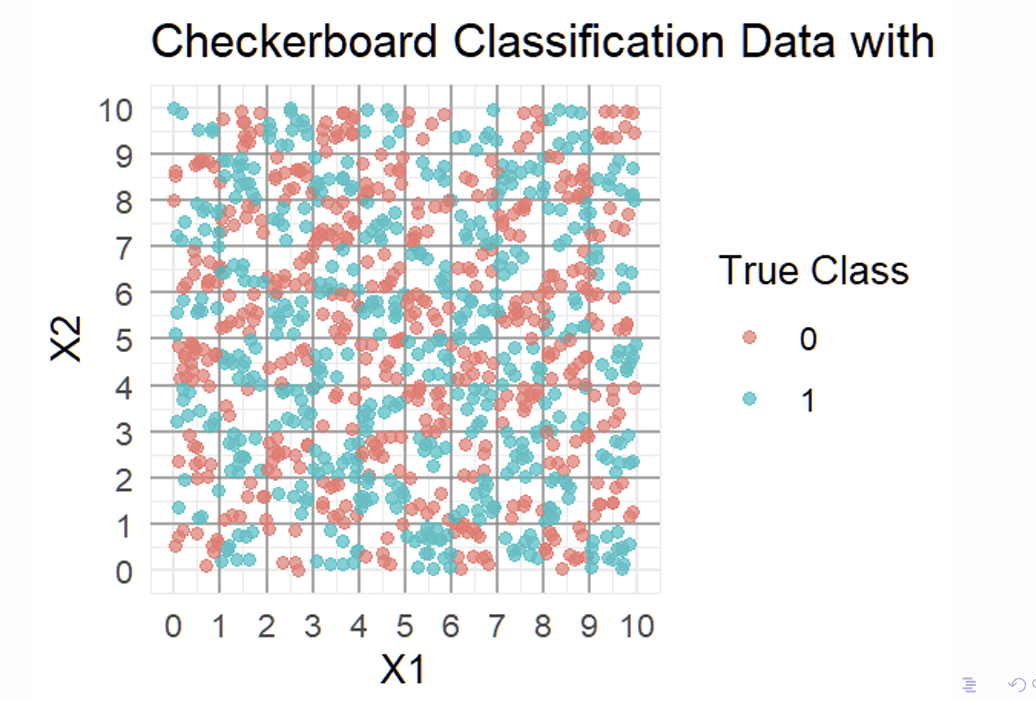
How does the NN going to recognise the pattern that generates these data?

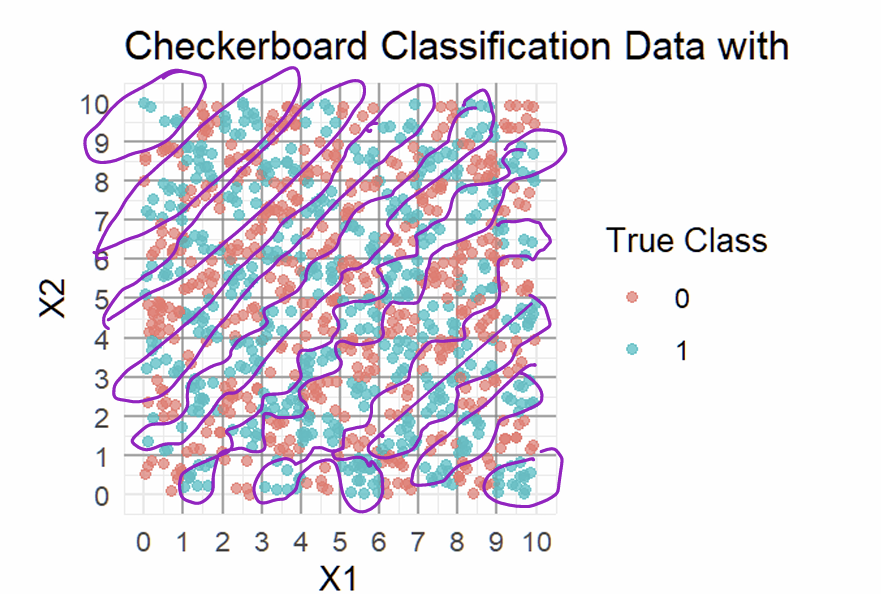
What decision boundaries is the NN trying to form?
What is the first step in establishing the pattern?

What do the hyperparameters represent?
Decay sets the value of δ

What does the trained network look like?
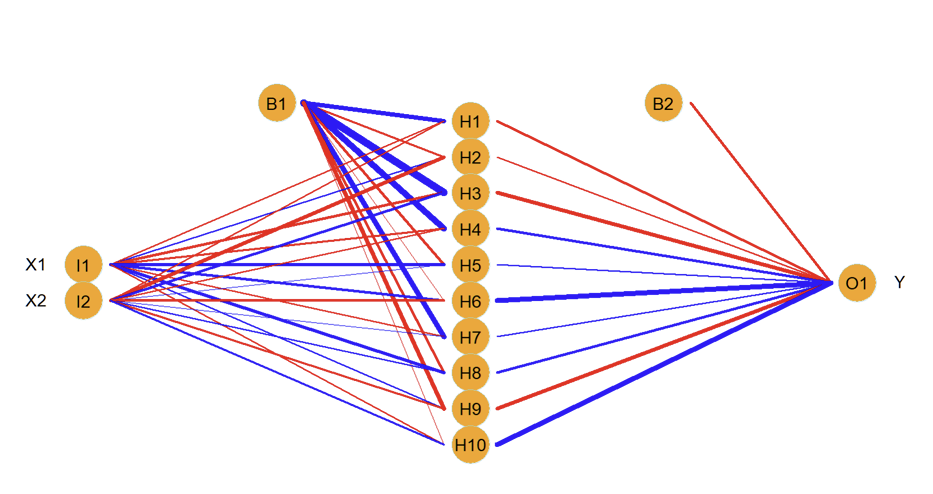
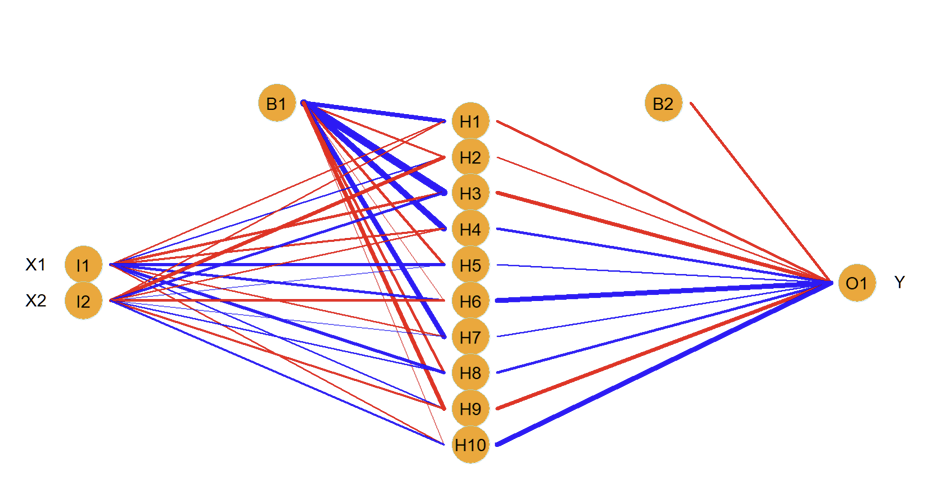
What do we mean by the network being “fully-connected”?
Each of the inputs (two in this example) are connected to each of the 10 units in the hidden layer
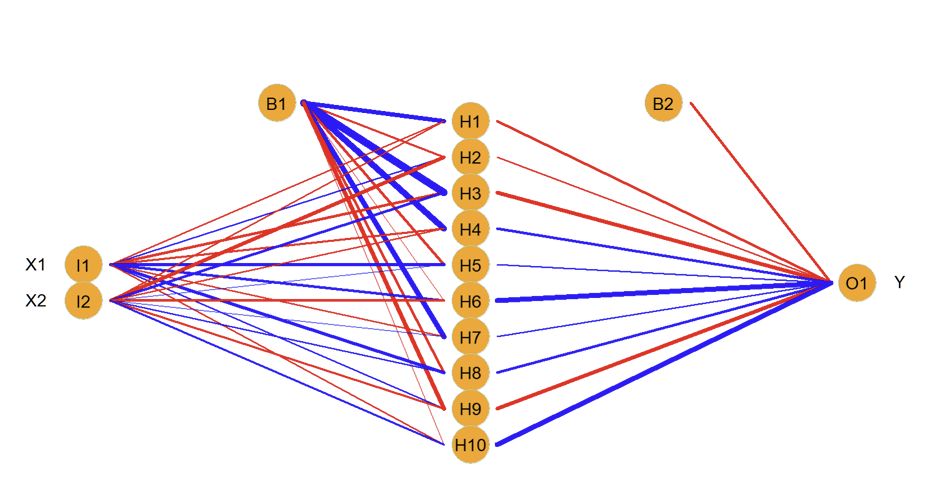
What are the weights in this example?
Each unit in the hidden layer is connected to the single unit in the output layer: this gives another set of weights

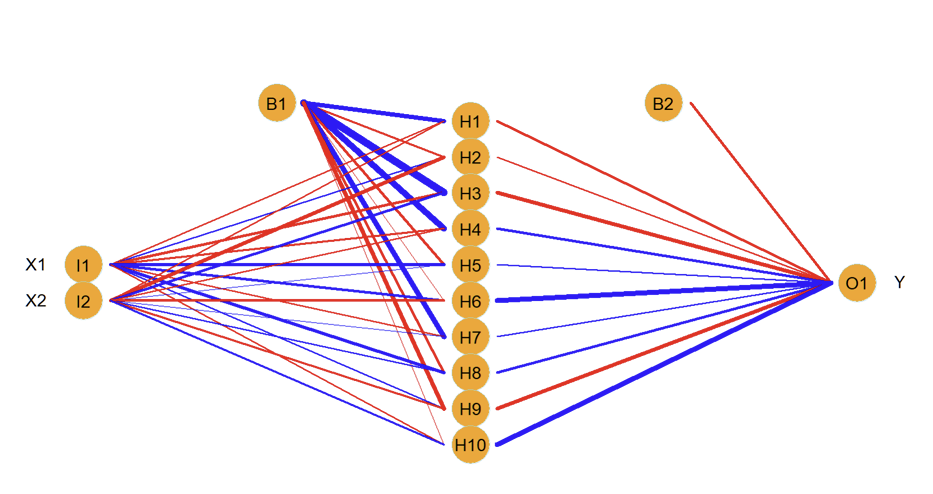
What are the biases in this example?
Output layer also has a bias

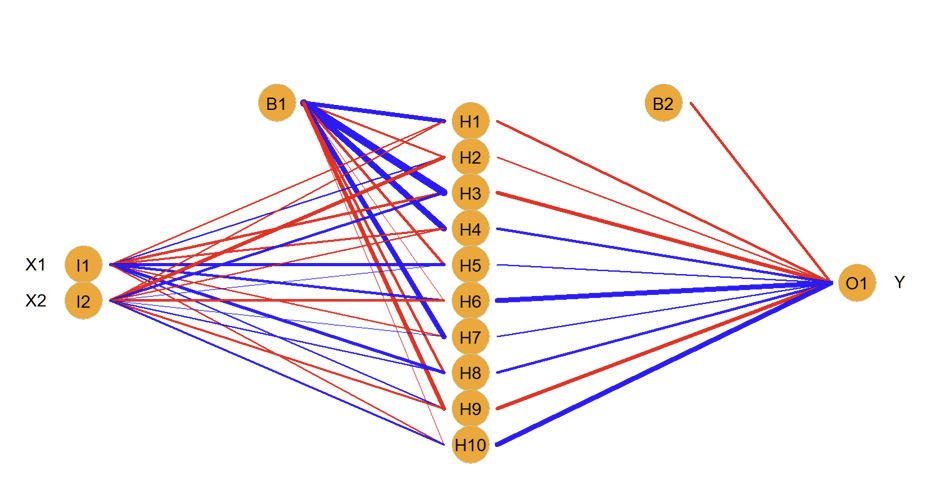
How many parameters are there and what do the different colours represent?


What does this tell us about the NN?
Overfitting
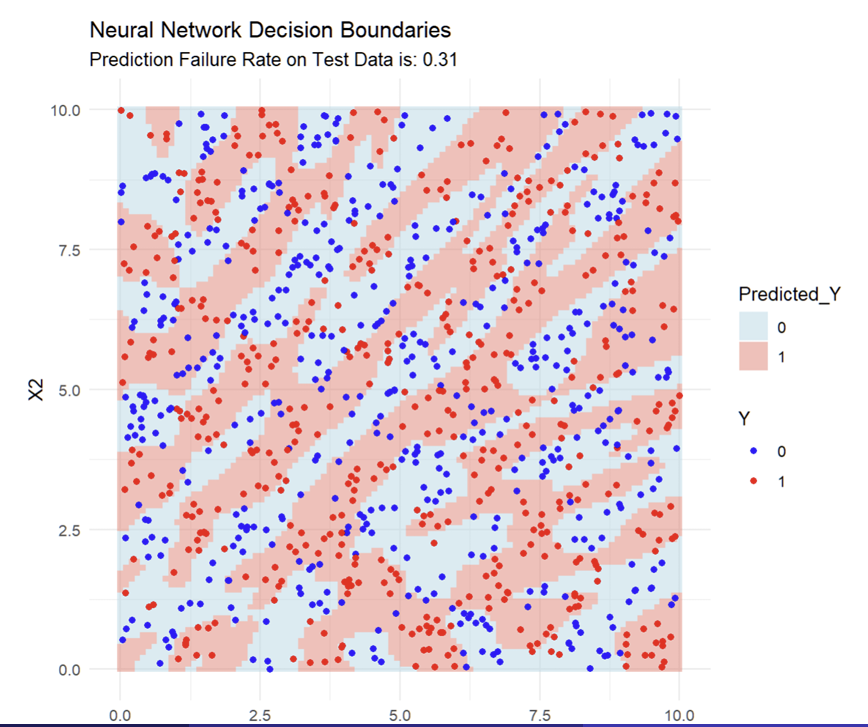
What do the fitted Decision Boundaries look like?
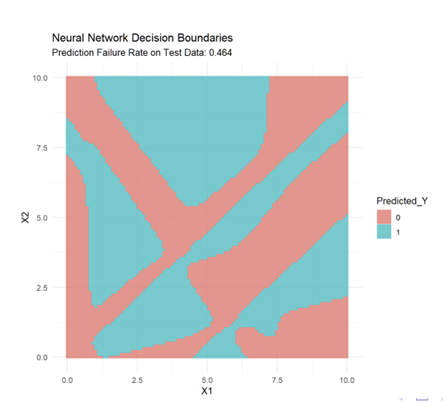
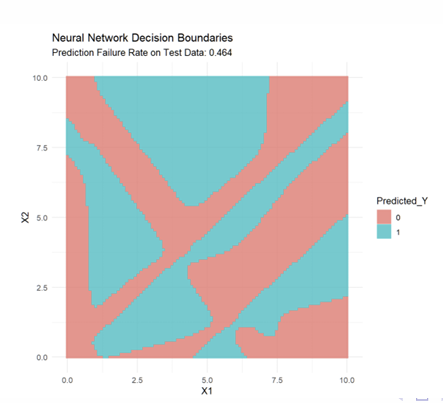
What do the fitted Decision Boundaries look like when combined with the data?
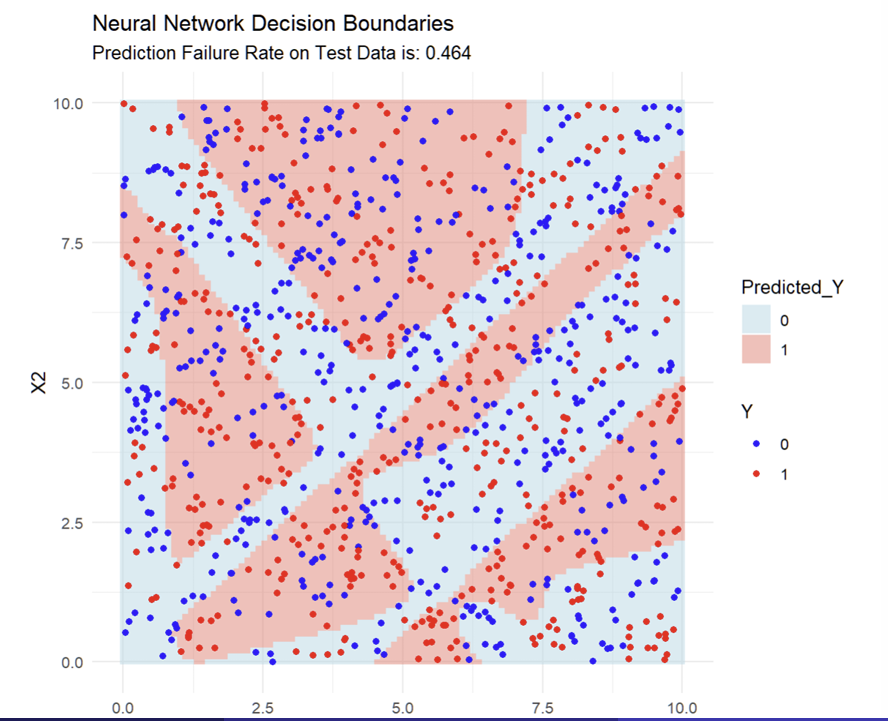
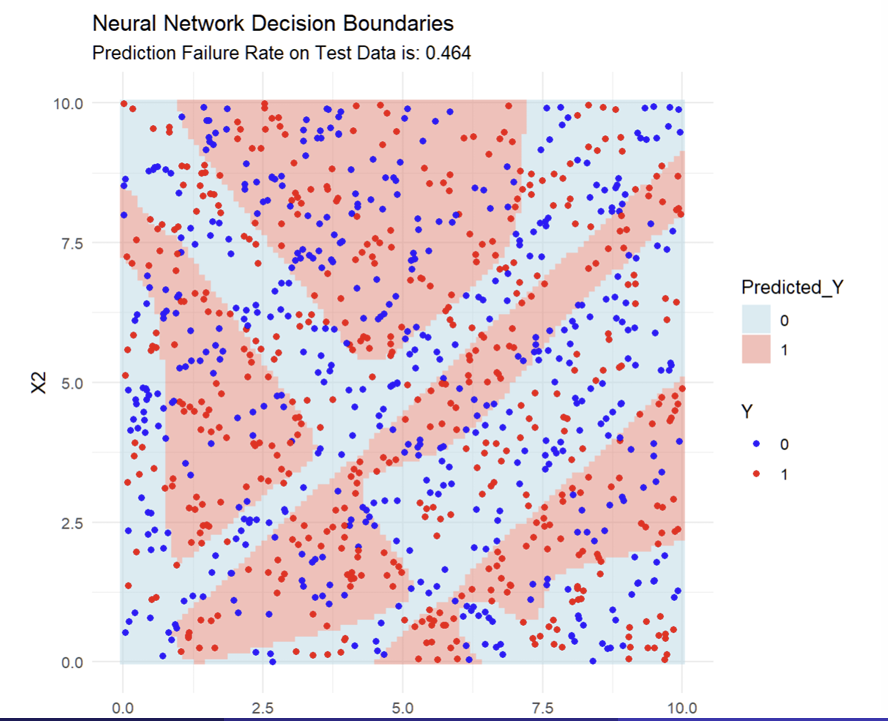
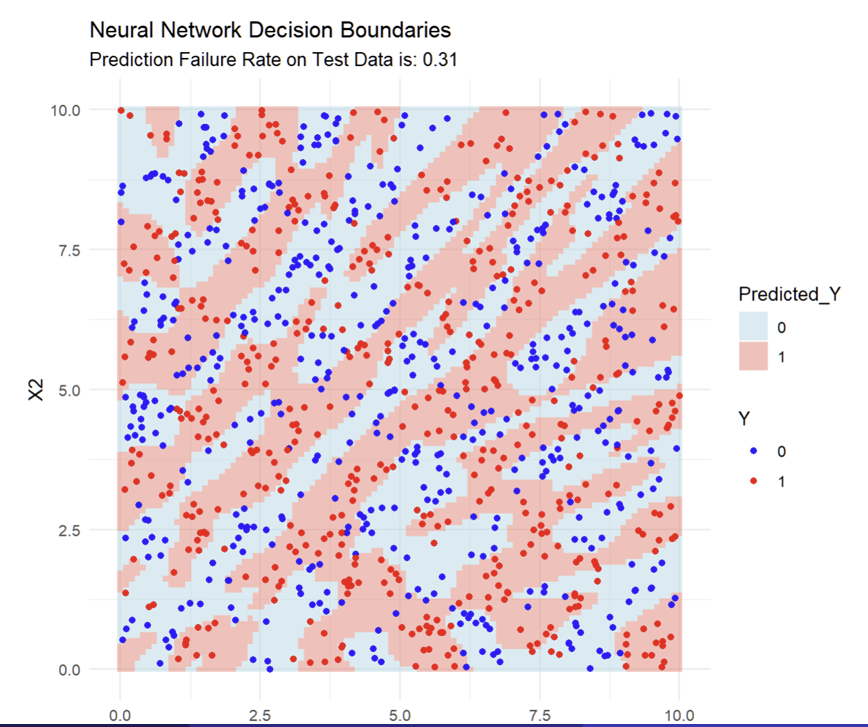
What does each dot represent in the image?
Every blue dot in the pink zone, and every red dot in the blue zone is a prediction error
What happens in this example when we increase the network to 50 units?


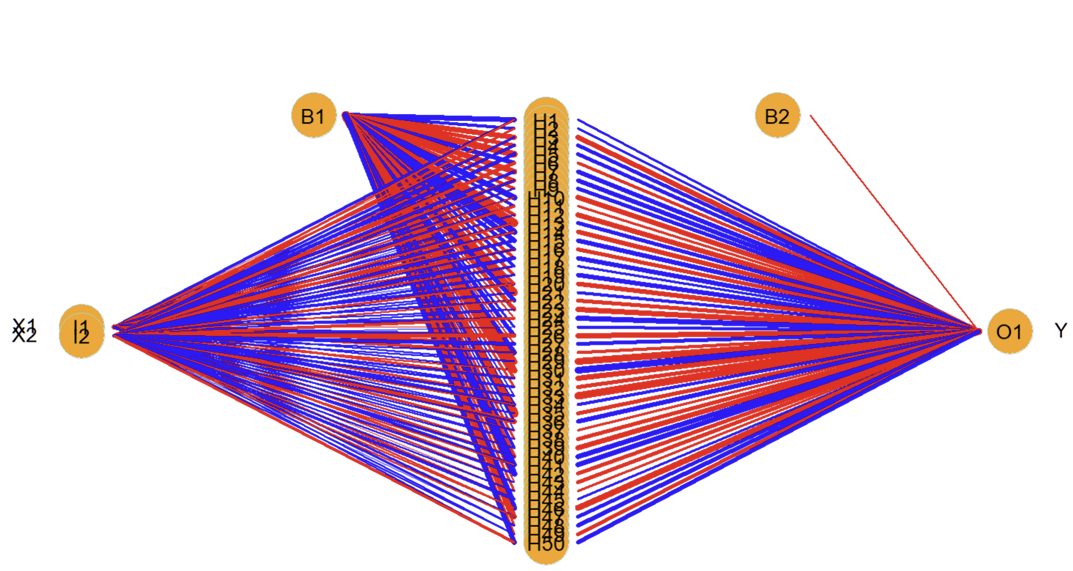
What does the estimated NN for 50 units look like?
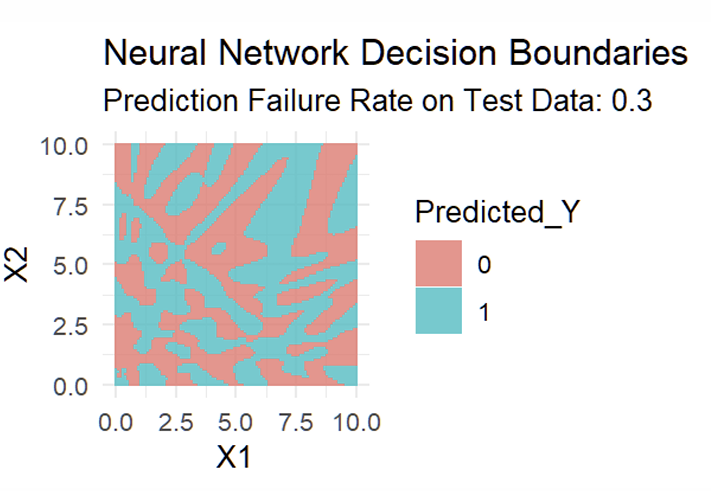
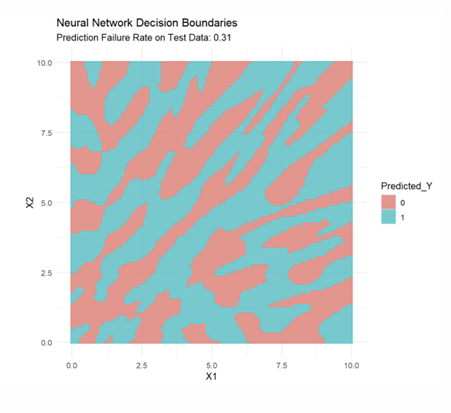
What do the fitted Decision Boundaries now look like?
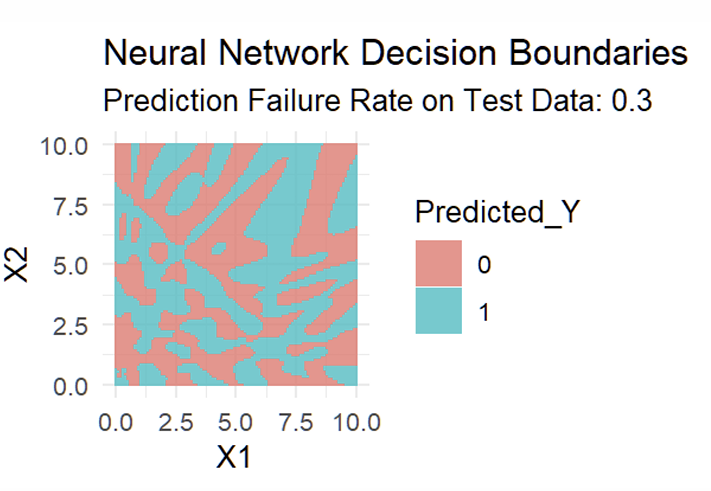
What do the more complex fitted Decision Boundaries with the data look like?
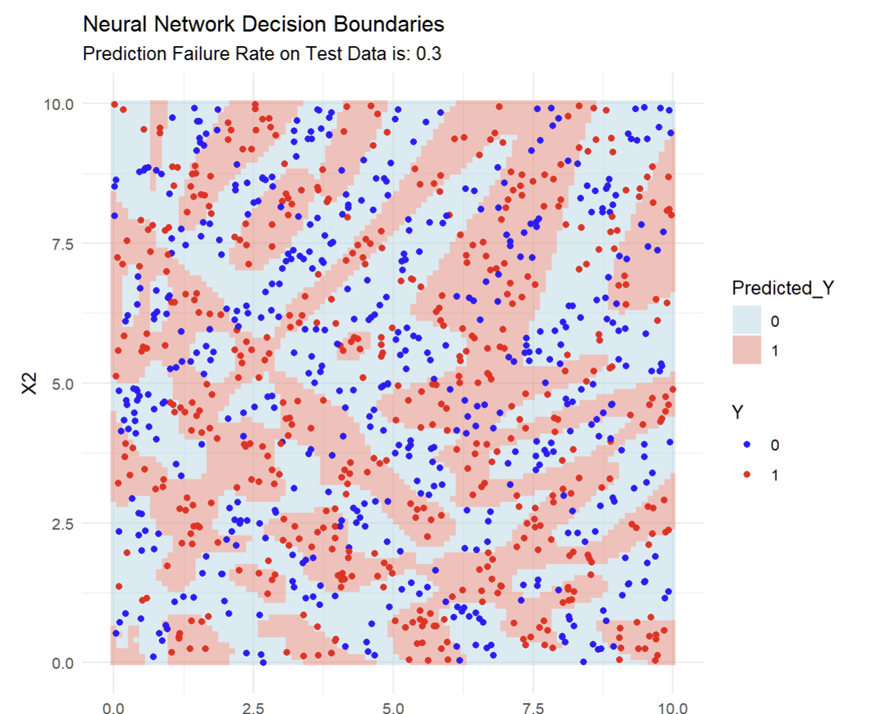
What happens when we increase the size of the network to 200 units?

What does the estimated NN look like for 200 units?
What do the fitted Decision boundaries now look like?
The fitted Decision Boundaries now capture the checkerboard very well
What do the new fitted Decision Boundaries with the data look like?
How did the NN achieve this?
Trained to minimise a loss function

What is the resulting loss function?
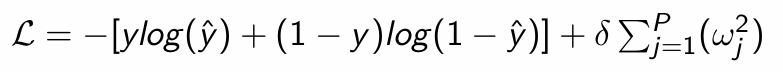
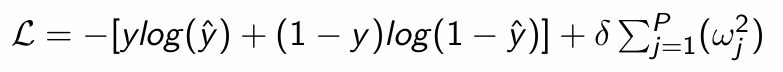
What does this simplify to if δ = 0?
Loss function simplifies to the Binary Cross-Entropy Loss function (similar logic to the entropy index)
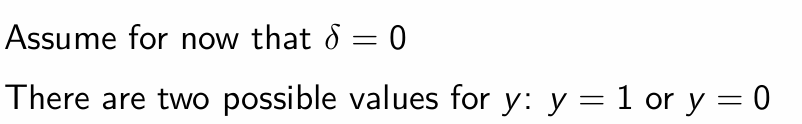
If y = 1, what is the loss function equal to?


And what do these results tell us?

If y = 0, what is the loss function equal to?

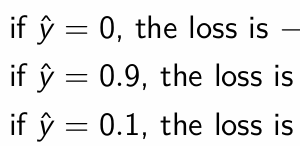
And what do the results tell us?

Therefore, what is the conclusion about having δ = 0?

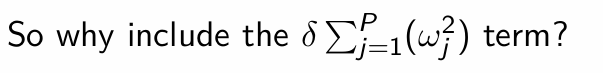


For parameter ωj, what is the optimality conditon?


What is the first step in solving this numerically?


What do we use these parameter values for? What is that process known as?


What do we calculate next and what is this process known as?

How do we calculate the gradient for the Backward Pass?
Using Back Propagation
What is Back Propagation?

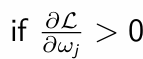
What do we do to the value of ωj?

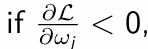
What do we do to the value of ωj?
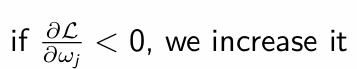
How do we determine the amount by which the value of ωj changes?

Now that the parameter values have been updated, what do we do next?
When does the algorithm stop updating the values of the parameters?
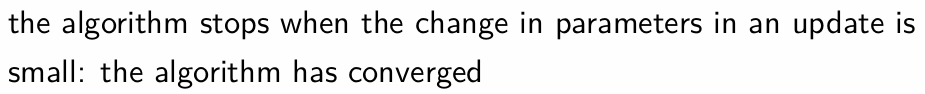

(Example) Why do we need to pre-process this data and how do we do this?

How do we calculate the scaled target variable in the training and test data?
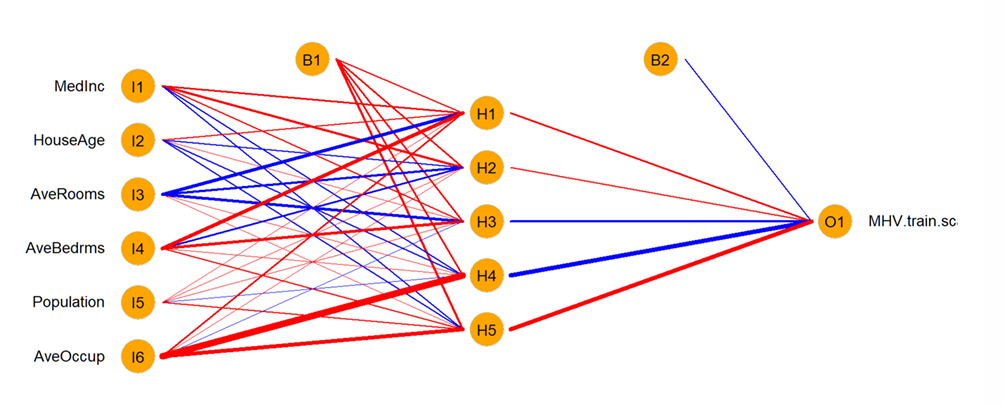
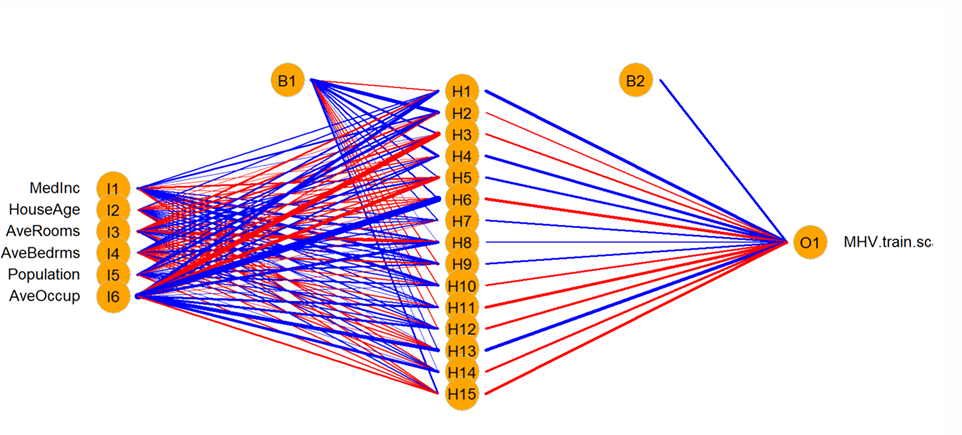
How do we determine the fit of the NN generated across multiple units?


What do the mses tell us?
There is evidence of overfitting the training data for networks with more than 20 units
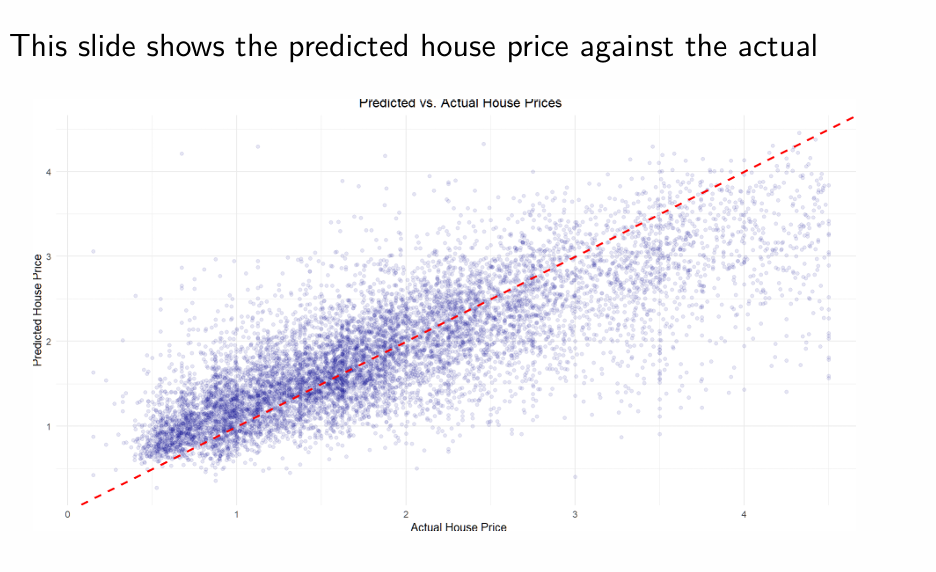
How might the predicted house price against the actual house price look for the chosen training model with 15 units?