Kvantitativ metod
1/18
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
19 Terms
Vad är kvantiativ metod och statisk?
data i sifferform
bearbetning matematisk/statistisk
strävar efter generelserbar data
statistisk är ett sätt att bearbeta och analysera numerisk data (data som på något sätt kan uttryckas i siffror)
Det finns två sortes statsik:
beskrivande (deskriptiv) där vi använder statiska mått (medelvärde, frekvenser) för att beskriva en grupps egenskaper.
Inferentiell statistisk där vi använder statiska jämförelser för att dra slutsatser om en populations egenskaper. Med inferentiell statisk kan vi ta reda på skillnad mellan grupper beror på hypotiserad effekt eller om skillnaden beror på slumpfaktorer. Ökar stress presentationsångest tex.
Vad är variabler?
En egenskap, ett beteende, känsla hos personer eller saker som kan variera. Alltså något hos personer eller saker som kan variera - tex kön och lycka.
Samband mellan två variabler (hur stress påverkar ohälsa) kallar man variabeln som vi tror orsakar förändring för den andra variabeln - obereonde variabel. Oberoende och beroende variabel, tänka i samband och olikheter, en variabel påverkar en annan variabel. Hur mycket sömn man får - påverkar hur man är idag. Sömntid tex påverkar = en oberoende variabel.
Kvantitativa variabler är variabler vi kan uttrycka numeriskt , med siffror tex ålder
Kvalitativa variabel, kön. Inget som man använder numeriskt.
vad finns det för skalnivåer?
En variabel ligger alltid på en skalnivå.
Nominalskalnivå, kan bara uttryckas med namn. Kan inte rangordas och inte uttryckas i siffror. Kön: man och kvinna, klassificerar händelser utifrån kategorisering eller namn. kan ej uttrycka på annat vis.
Ordinalskala, möjlighet att rangordna, tex betyg, eller kategorivaiabel, aldrig, sällan, ofta. Nominalskala fast man kan rangordna vilket blir denna. Allt som handlar om upplevelser ligger här, men vid 1-5 – tvingar in respondenter så blir det intervallskala. Svarsalternativ som avgör vilken skalnivå det ligger på, vHII –11 hur upplever du detta?
Intervallskala, siffor, epidestans mellan två skalsteg är steget lika stort. Om man mäter variabel temperatur, skillnad mellan 1-2 är lika stor som 11-12. Så är inte skillnaden i ordnianskala tex vid betyg. Diska. 1-5. Vid siffror
Kvotskala, särskiljer mot intervall är att det finns en absolut nollpunkt. Ålder, grader – kelvin? Finns inga minusgrader. Diska – kan ha diskat noll gånger.
Nominal och ordinal – kvantitativa?
Vad finns det för tabeller för kvalitativa variabler
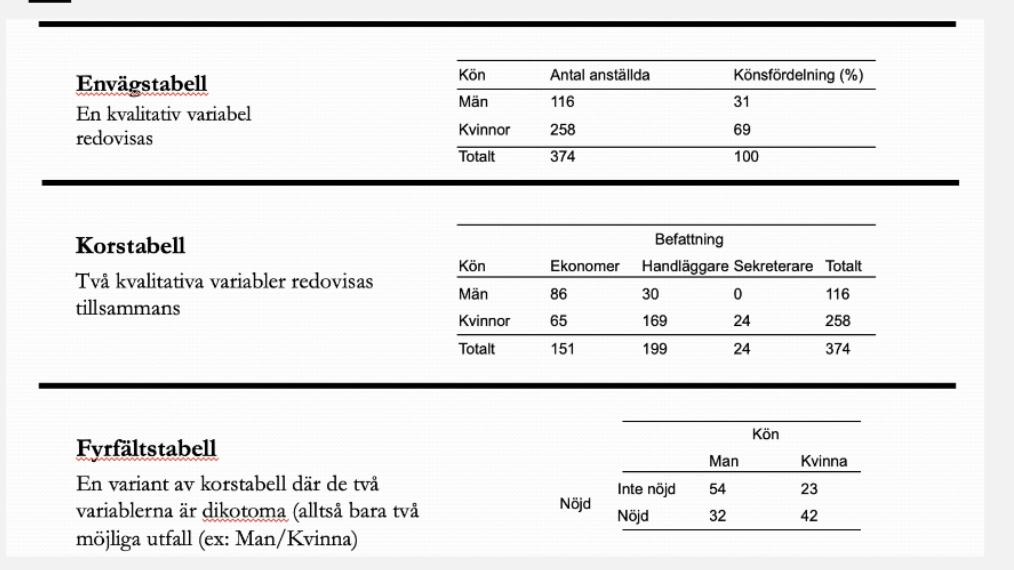
Envägstabell: redovisar en variabel, tex kön, bara en kvalitativ variabel.
Korstabell: två variabler, ett kors. En variabel som är befattning och en som är kön. Hur många olika kateogier de har. Kan vara hur många nivåer som helst.
Fyrfältstabell: en variant av korstabell där de två variablerna är diktoma (alltså bara två möjliga utfall) - tex man/kvinna. fyra fält men två nivåer.
Stapeldiagram: hur många som har fått något. Betyg i skolor. Y och X axel. På y axeln är det frekvens, hur många av något. På x axeln hu många av något. VISAR INTE SIFFROR PÅ BÅDE Y OCH X!
vad räknas som diagram och tabell för kvantitativa data?
När båda våra variabler är kvantifierbara, alltså när x och y både består av siffror:
tex:
frekvenstabell, frekvens uttryckt i siffror och den andra variabeln även i siffror.
stapeldiagram, antal personer och antal erhållna poäng, ser snabbt vad som är den vanligaste poängen.
punktdiagram. varje punkt är en person. Används ofta vid korrelationsanalyser
Vad behöver man tänka på vid användande av tabeller och diagram?
tabellen och diagrammet ska kunna förstås utan att läsa brödtexten. Kan se olika beroende på syfte, akademiskt, medicinskt. Behöver inte alltid se ut som exemplet.
Vad innebär centralmått?
Ett mått som ger oss en indikation av var ett genomsnittligt värde befinner sig för en grupp. Finns tre typer:
typvärde
median
medelvärde
Beskriv typvärde:
Högst frekvens, förekommer flest gånger i en serie av mätningar.
3 – de mätevärde som förekommer flest gånger i gruppen. A
Mått för variablar på nominalskalenivå. Fungerar på samtliga skalnivåer
beskriv median:
De mätvärde som är det mittersta värde i siffror eller de värde som hälften av siffrorna liggen ovanför och hälften av siffrorna ligger nedanför.
Beräknas på olika sätt beroende på om antalet är udda eller jämt.
Mått för variabler vid odinalnivåer funkar också på intervall och kvot. Medianen för jordgubb, rangordna alla som säger 1 osv. Vill ha det mittersta värdet, alltså median
beskriv medelvärde:
Mått för variabler på intervall och kvotskalenivå - kan ENDAST användas på dessa skalnivåer
Beräknas genom summan av alla observationer delat med antalet observationer.
Lägger ihop alla siffror och delar på värdet så man får fram medelvärdet. Påverkas av varje observation, de värde som har minst summerad avvikelse från varje individ. Medelvärde ska alltid användas om man kan använda det.
Vilket centralmått bör vid använda och när?
Typvärde:
Är känsligt för slumpen och kan därför variera mellan olika stickprov. Då man eftersträvar att stickproven ska säga något om en population är utsattheten för slumpen problematisk. Inte ett finkornigt instrument.
En mätning kan även reslutera i mer än ett typvärde, dvs att två värden kan förekomma lika många gånger. Används bara när man inte kan använda något annat alltså median eller medelvärde, ex när vår variabel är mätt på nominalskalenivå. Känsligt för slumpen
Median:
mindre känsligt för slumpen än typvärde men ändå känsligt.
problem med median är att vi inte kan från separata gruppers median beräkna medianen för en större grupp som satts samman av dessa grupper - tex en grupp av 5 och en grupp av 200 - medelvärdet blir inte rätt.???
Medelvärde:
vårt första val om man har en normalfördelad variabel på intervall eller kvotskalenivå.
från medelvärdet kan vi generalsiera våra resultat. Från gruppmedelvärde kan vi uttala oss om populationsmedelvärde.
det är ett väntevärdesriktigt estimat = om man tar medelvärdet av många olika grupper och beräknar medelvärdet av dessa värden så tar varje felaktighet ut varandra. I en grupp fanns någon med hög intelligens och i en annan fanns någon med låg - om ett nytt medelvärde beräknas på dessa gruppers medelvärde så tar felen ut varandra.
Vad innebär spridningsmått?
ett mått som beskriver spridningen i en grupp.
när man vill uttala sig om en grupp vill man dels veta det genomsnittliga värdet för gruppen avseende det vi vill mäta. Men vi vill också veta hur spridning det är i gruppen. Hur överns är deltagarna i gruppen kring sina lyckoskattningar? Hur stor spridning har vi i inkomst?
Spridningsmått och medelvärde
Varje centralmått har ett spridningsmått, men här pratar man bara om medelvärdet. Vilket är:
varians och standradavvikelse.
Varians ränkas ut genom att summera samtliga avvikelser mellan mätvärde och medelvärde. Varians benämns som s2 och standradavvikelse som s.
Vad innebär hypoteser?
antaganden om hur verkligheten ser ut
Vid forskning använder man sig av hypoteser och kallar de för nollhypotes eller alternativhypotes
Nollhypotes = innebär att de inte finns en skillnad, att de inte finns ett samband eller att de inte finns en effekt.
alternativhypotesen är att det finns en skillnad, ett samband eller en effekt.
När man konstruerar hypoteser använder man sig av populationsmått istället för gruppmått. De båda måtten innebär samma sak fast de gäller på olika nivåer. I en population kallar vi medelvärdet för μ (my)
H0= det finns ingen effekt
H1 = det finns en effekt
Signifikanta reslutat
Om sannolikheten att slumpen har orsakat resultatet är stor - behåller vi H0, dvs vi har inte en tillräckligt stor säkerhet att säga att det finns någon effekt = icke signifikant reslutat
Om sannolikheten att slumpen orsakat resultatet är liten förkastar vid H0, alltså det finns en effekt. = signifikant reslutat.
Om sannolikheten att det är slumpen som orsakat en effekt är mer än 5%. För att räkna fram sannolikheten använder man fördelningar.
Frekvensfördelning:
en grund för hypotesprövning
Frekvens = hur många av något, hur vanligt.
Man tittar på om variabelns fördelning är i en normalfördelningsform:
medelvärdet ligger alltid i mitten av normalfördelad variabel och är alltså det vanligaste värdet
Hur kan man se om det är normalfördelat?
klockformat, som en kyrkklocka inte som ett armbandsur
symmetrisk - ser likadan ut på båda sidorna av mitten
Y-axeln benämner alltid antal - alltså en frekvensfördelning
då nomralfördelningskurvan är symmetrisk kan vi alltid hitta samma propetioner av observantioner mellan två punkter på x-axeln.
Ju mer den avviker från 0 desto mer avviker det om 0 är medelvärdet.
Längst ut ligger 5% av alla värden. Medelvärdes skillnad på 2, ca bara 2,5% Blir lika ovanligt om de ligger på - eller på +.
Hela grunden för signifikant testning.
Vad finns det för avvikelser från normalfördelningsform?
Bimodal = två typvärden medan medianen och medelvärdet är detsamma. Med små skillnader kan typvärdet flyttas. Får två typvärden = ställer två frågor i en, en fokuserar på nöjd 3 och andra som fokuserar tillfreds 7. Ser två frågor i en men att man ändå får ut en normalfördelning, gör det inget. Två normalfördelning i en?
Positiv snedfördelning = mest personer som får mer lågt. Majoriteten på vänster sida och en svans mot höger.
Negativ snedfördelning = mest personer får väldigt lågt. Tex att ge högskoleprovet till klass tre elever. Majoritetet har på höger sidan och smalarnar av i en svans mot vänster.
Man vill inte ha detta i gruppen. Ofta visar detta på att det är något fel, att man har ställt fel frågor tex.
Vad innebär samplingsfördelning?
En samplingsfördelning är en frekvensfördelning av en stickprovsegenskap tex medelvärde eller standardavvikelse. Iq är en samplingsfördelning. Gruppmedelvärde. Fördelning av stickprovs..?
Arbetar med detta på grund av tar alltid en normalfördelningsform.
Vill ha normal fördelat i grupp för de ska vara lika i populationen.
I population förusatt att de är sampel, kommer alltid vara normalfördelad?