Business Analytics udvidet
1/79
Earn XP
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
80 Terms
Forklar begreberne variation og (u)sikkerhed.
Variation handler om spredning i data – hvor meget observationerne afviger fra hinanden (f.eks. målt med varians eller standardafvigelse).
Usikkerhed handler om hvor præcist vi kender noget – f.eks. hvor tæt stikprøvens gennemsnit ligger på populationsgennemsnittet (målt med standardfejl).
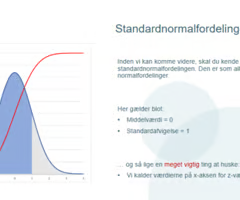
Hvad er standardnormalfordelingen, og hvorfor er den vigtig?
Standardnormalfordelingen er en symmetrisk klokkeformet kurve, hvor:
Middelværdien (gennemsnittet) = 0
Standardafvigelsen = 1
X-aksen måles i z-værdier
Vi bruger standardnormalfordelingen, når vi beregner konfidensintervaller, fordi den beskriver, hvordan værdier er fordelt omkring gennemsnittet. Den gør det muligt at finde sandsynligheder for, at en værdi falder indenfor et bestemt interval.
Lektion 1
Forklar problemstillingen med signal og støj i dataanalyse? Hvad er det, vi taler om, og hvorfor er det vigtigt?
Svar:
Signal er den del af data, der repræsenterer en reel effekt eller sammenhæng, som vi ønsker at forstå.
Støj er tilfældig variation, målefejl eller irrelevante udsving i data.
Hvorfor vigtigt (fakta):
Hvis vi ikke adskiller signal fra støj, risikerer vi:
at se mønstre, som ikke findes (falske konklusioner)
at overse reelle sammenhænge
Faldgrube:
Små datasæt og mange variabler øger risikoen for at forveksle støj med signal.

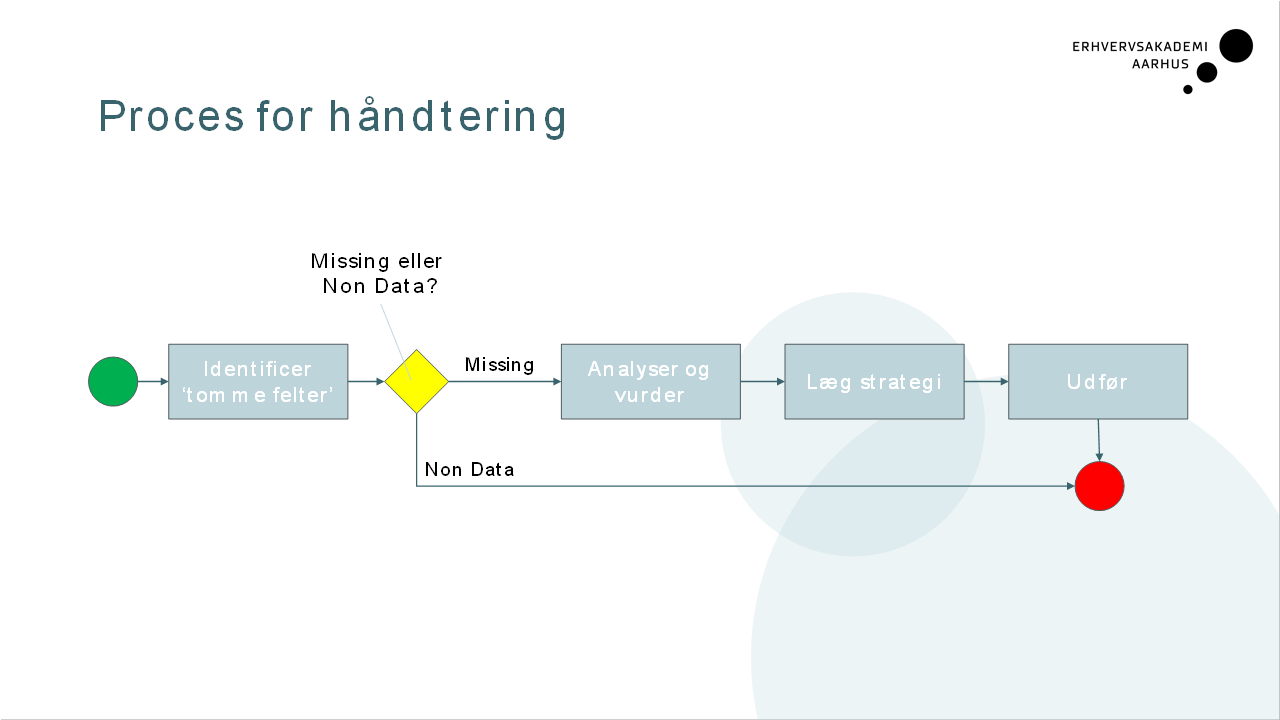
Proces for håndtering
Hvad skal vi gøre med støjen?
Svar:
Reducere støj (bedre data, flere observationer, datarensning)
Modellere støj (statistiske modeller, antagelser om variation)
Kvantificere støj (usikkerhed, konfidensintervaller)
Vigtigt:
Støj må ikke bare fjernes, da man risikerer at fjerne relevant signal.
Hvad er den overordnede idé med konfidensintervaller? Forklar, hvad vi skal bruge dem til, og hvordan kommunikerer vi dem enkelt og intuitivt?
Svar:
Et konfidensinterval angiver et interval af plausible værdier for en ukendt sand parameter (fx en middelværdi).
Intuitiv forklaring:
Hvis vi gentog målingen mange gange, ville fx 95 % af de beregnede intervaller indeholde den sande værdi.
Typisk fejl:
Det er forkert at sige, at der er 95 % sandsynlighed for, at den sande værdi ligger i netop dette interval.
Hvis dine data er normalfordelte, kan du hovedregne på dem ved hjælp af nogle tommelfingerregler. Forklar hvordan!
Den såkaldte 68–95–99,7-regel:
Ca. 68 % af observationerne ligger inden for ±1 standardafvigelse
Ca. 95 % inden for ±2 standardafvigelser
Ca. 99,7 % inden for ±3 standardafvigelser
Anvendelse:
Hurtig vurdering af spredning og ekstreme værdier.
Begrænsning:
Reglen gælder kun, hvis data reelt er normalfordelte.
Hvad er signifikans? Hvordan fastsætter du signifikansniveauet i en analyse?
Signifikans handler om, hvorvidt et observeret resultat er usandsynligt under nulhypotesen.
Signifikansniveauet (α) fastsættes før analysen
Typisk vælges α = 0,05
Fortolkning:
Der accepteres 5 % risiko for en falsk positiv konklusion.
Hvad fortæller p-værdier dig? Hvad har p-værdier og signifikansniveauer med hinanden at gøre?
P-værdien er sandsynligheden for at observere data (eller mere ekstreme data), givet at nulhypotesen er sand
Hvis p ≤ α → resultatet kaldes statistisk signifikant
Kritisk pointe:
P-værdien siger ikke, hvor stor effekten er, eller om den er praktisk vigtig.
Hvad er fidusen ved Pandas, når vi laver dataanalyse?
Pandas gør det muligt at:
arbejde effektivt med tabulære data
filtrere, gruppere og aggregere data let
kombinere datarensning og analyse i samme workflow
Begrænsning:
Pandas laver ikke statistik for dig – korrekt analyse kræver stadig faglige valg og antagelser.
Lektion 2
Hvorfor er missing data et problem?
Missing data kan skjule eller forvridde signalet i analysen. Det kan give bias, forkerte konklusioner eller et mindre datagrundlag
Beskriv processen for håndtering af missing data?

Hvad er non-data?
Non-data er tomme felter, som mangler af en naturlig grund. Det er ikke en fejl. Fx har en kunde uden kundeklub ikke et kundenummer, eller en villa har ikke et etagenummer.
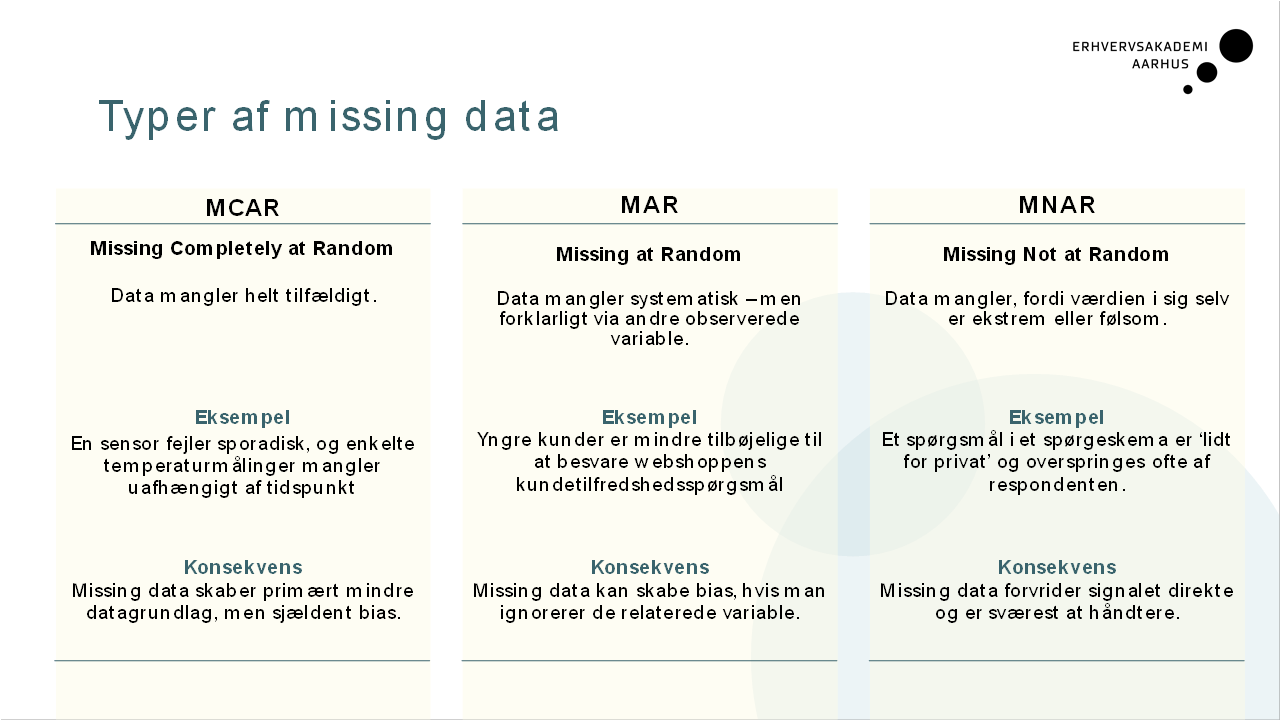
De tre typer missing data?
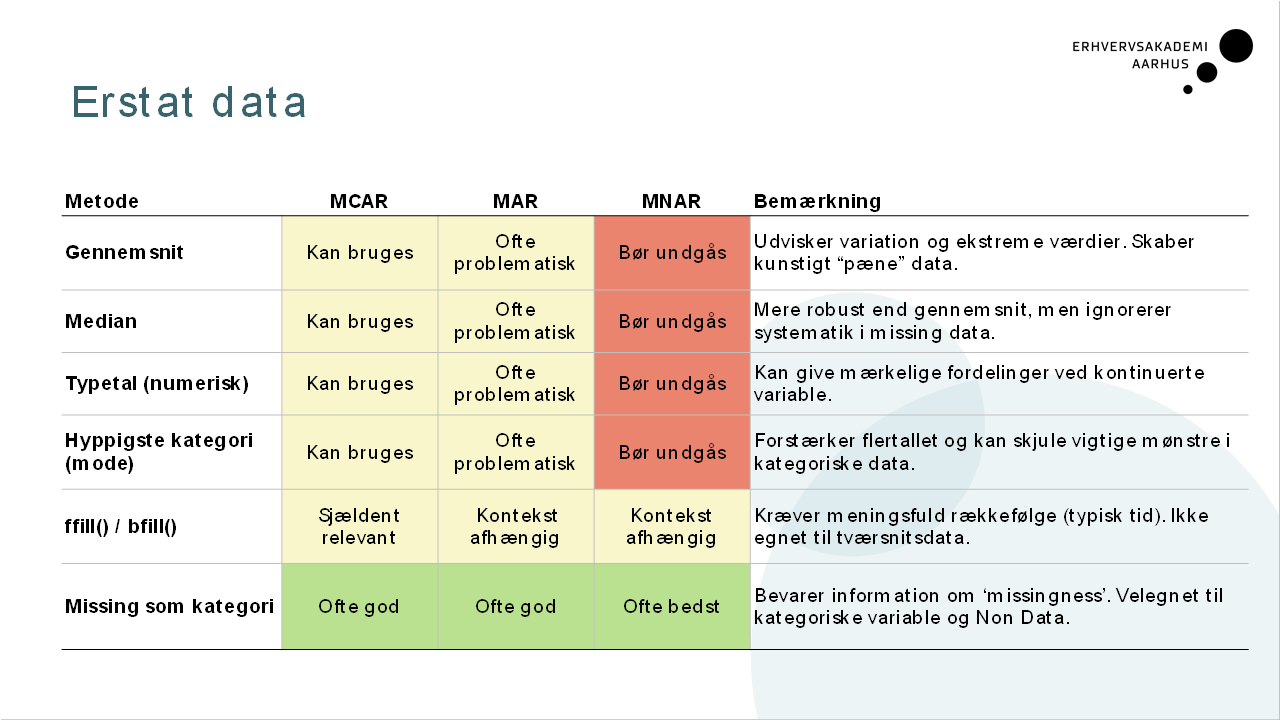
Fem strategier ift til missing data?

Hvordan vælger man impute-metode?
Lektion 3
Forklar beregberne “den sande værdi, “signal” og “støj”. Hvorfor er de vigtige?

Hvad er et konfidensinterval?
Et konfidensinterval er et interval omkring stikprøvegennemsnittet, hvor vi med fx 95 % sikkerhed forventer, at populationsgennemsnittet ligger.
Det tager højde for usikkerhed og spredning.
Normalfordelingsform kan bestemmes af to ting?
Hvordan laver man hovedregning med normalfordeling?

Hvad er fordelingsfunktionen, og hvordan tolker vi den?
Fordelingsfunktionen (CDF)
Viser sandsynligheden for, at en værdi er mindre end eller lig med en bestemt x-værdi:
Fordelingsfunktionen (CDF) - Fordelingsfunktionen (CDF) - Fordelingsfunktionen (CDF) - P(X ≤ x)
🔴 Den røde kurve viser den kumulerede sandsynlighed frem til x.📊 Vi bruger den til at finde sandsynligheder for forskellige værdier og intervaller.
Eksempel: Ved x = -0,5 er den kumulerede sandsynlighed 30 %. Det betyder, at 30 % af observationerne ligger til venstre for -0,5.
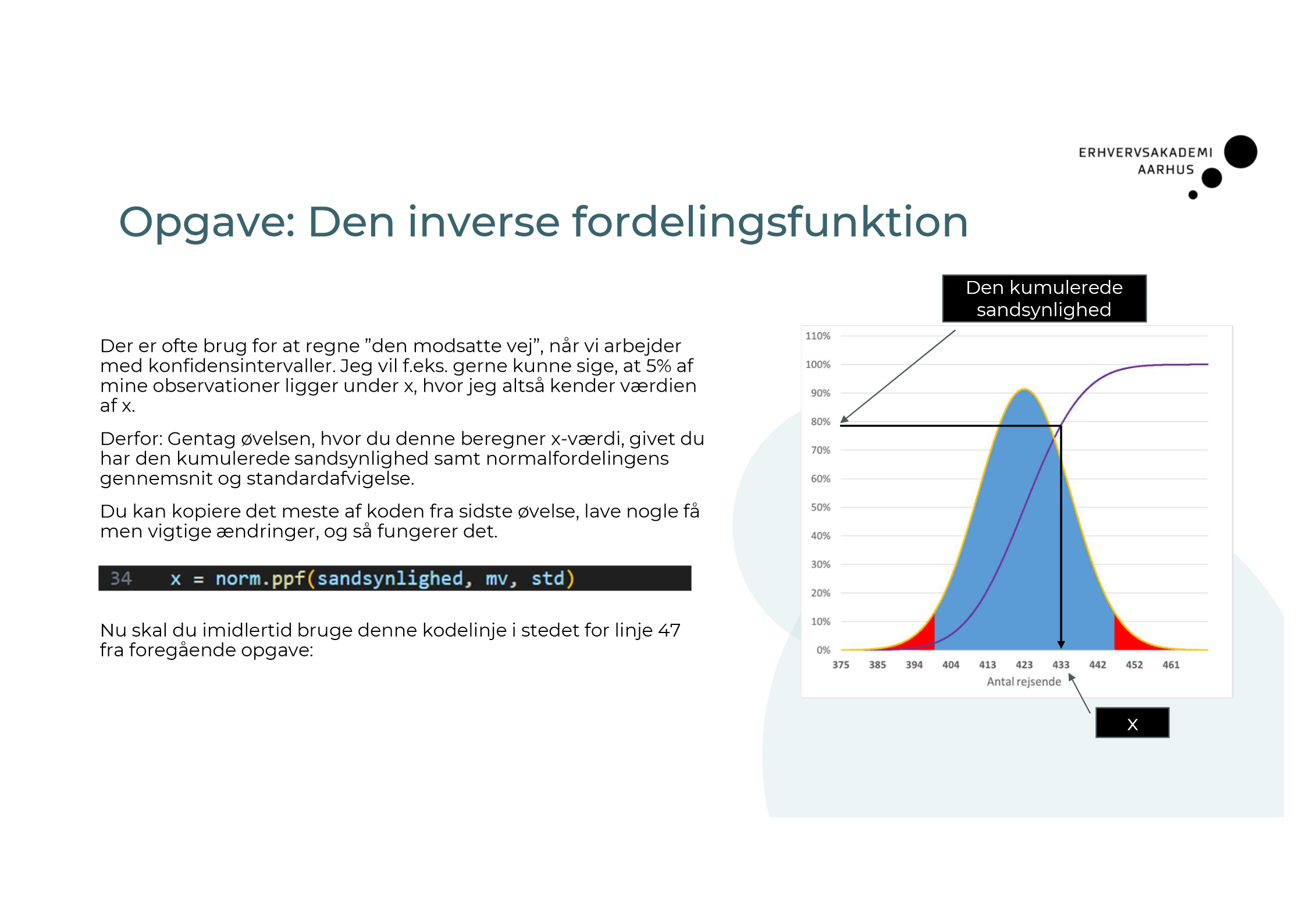
Hvad er den inverse fordelingsfuktion? (kan du koden i pythoon?)
Hvad er SE og grænseværdisætning?

Hvornår skal du anvende standardfejlen? Hvornår skal du anvende std afg? Til hvad? Hvordan? sammenhæng?

Hvad er forskellen på ensidet og et tosidet konfidensinterval? Hvornår bruger du hvad?
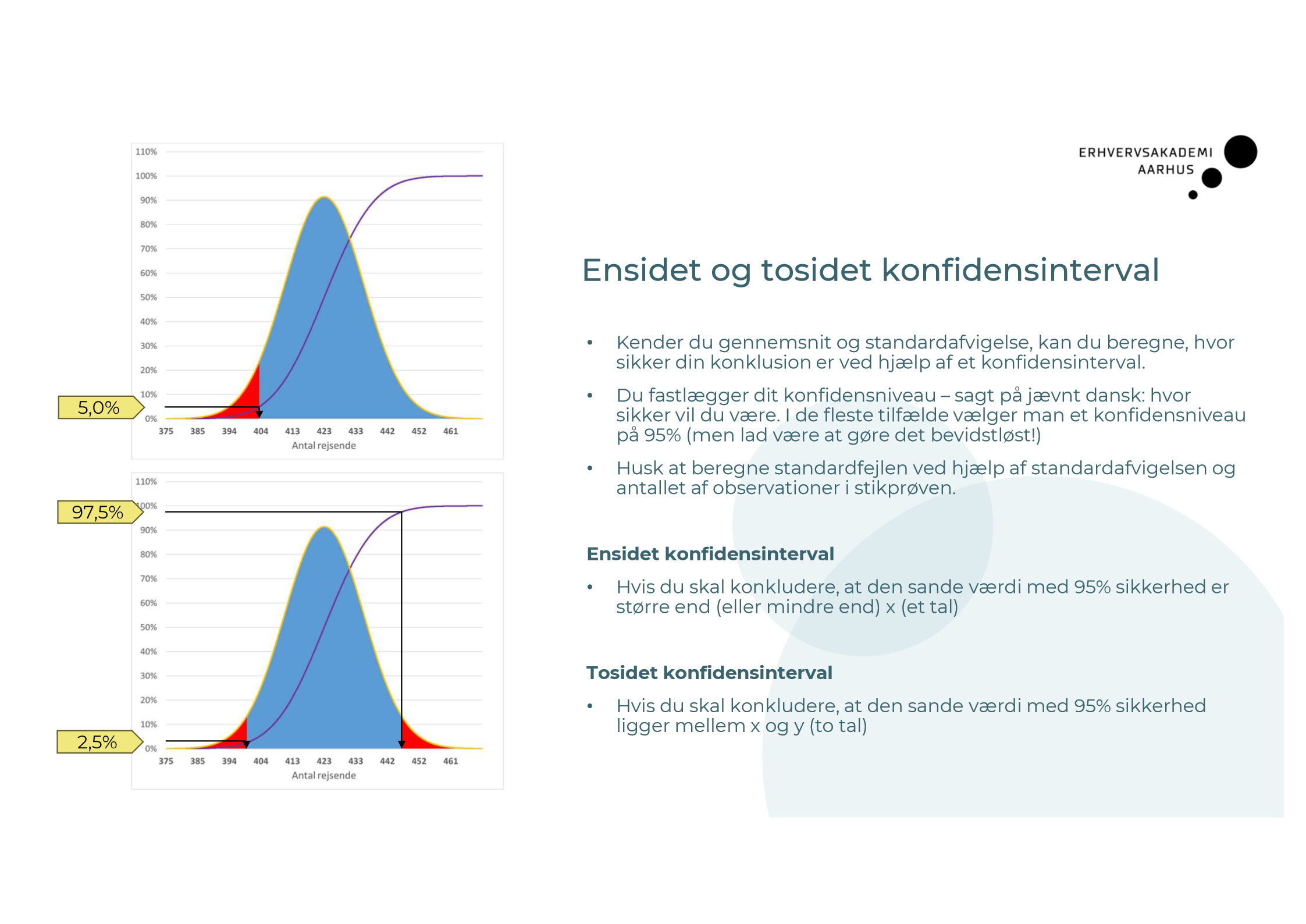
I hvilke tilfælde er det bedre at bootstrappe, fremfor at benytte normalfordeling til beregning af konfodensintervaller

Hvordan bootstrapper man?

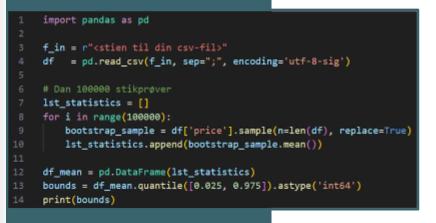
Forklar denne kode

Lektion 4
Forklar begrebet signifikans. Hvad bruger vi signifikans til? Hvordan fastsættes den?

Hvad er en hypotese. Hvordan formuleres den?

Kan vi bekræfte en hypotese? Hvis ikke, hvad kan vi så?

Hvad er en ensidet kontra en tosidet hypotesetest?

Processen for en hypotese test?
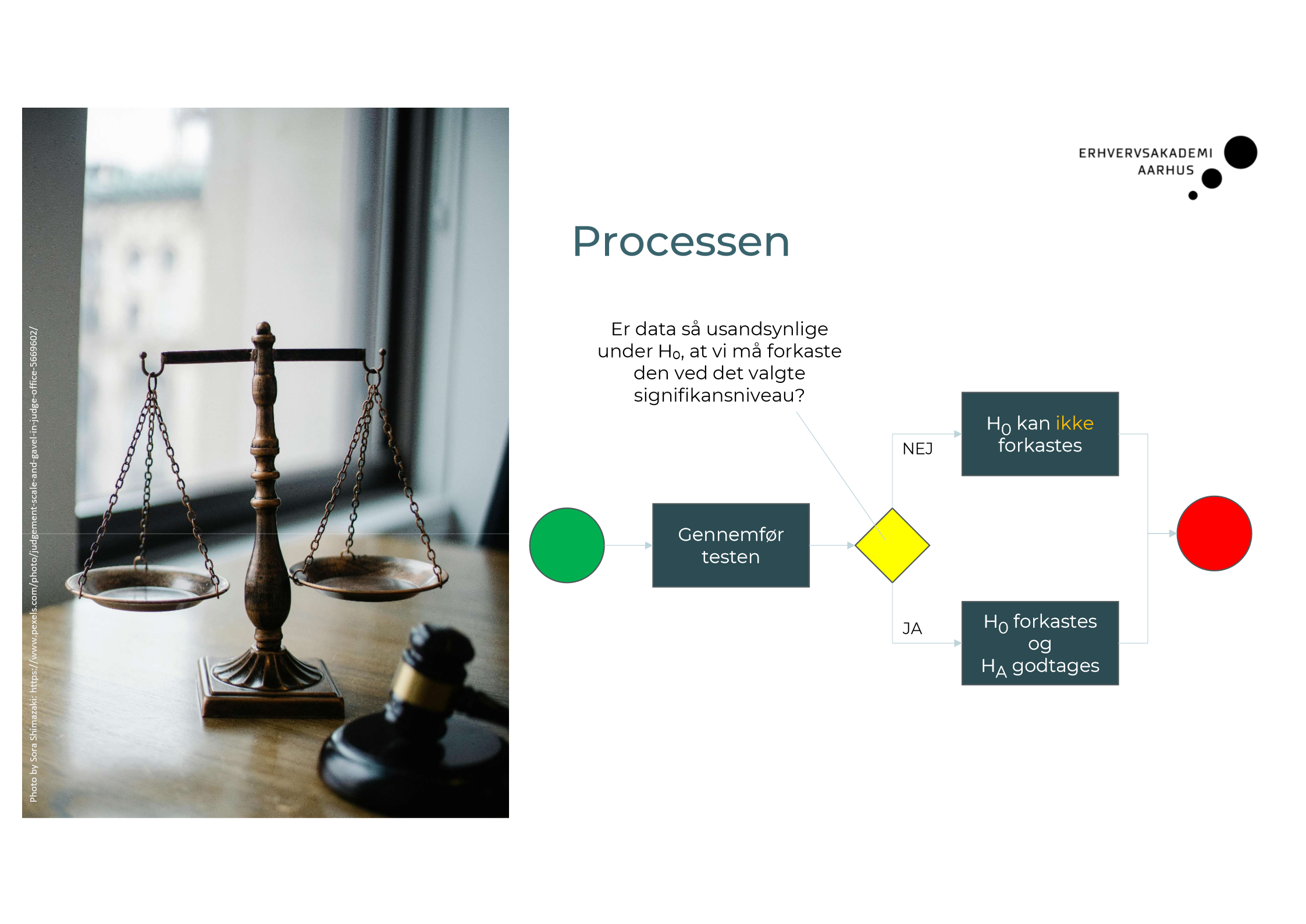
P-værdien er sandsynligheden for at en stikprøve giver den findne eller en mere ekstrem værdi. Hvad ancender vi p-værdien til?
Vi bruger p-værdien til at vurdere, om et resultat er statistisk signifikant.
Den hjælper os med at afgøre, om vi skal forkaste nulhypotesen eller ej.
Kort sagt:
Lav p-værdi = resultatet er usandsynligt ved nulhypotesen → vi kan forkaste H₀.
Hypetesetest har fire udfald. FORKLAR!

Hvad er signifikansniveauet α, og hvad betyder 1 - α?
α (alfa) er den risiko, vi accepterer for at tage fejl – altså sandsynligheden for at konfidensintervallet ikke rammer den sande værdi.
Typisk sætter vi α = 0,05 → 5% risiko.
1 - α er konfidensniveauet, fx 0,95 = 95%. Det er sikkerheden for at vores konfidensinterval dækker den sande værdi.
Så:
Hvis α = 0,05 → konfidensniveau = 95%Hvis α = 0,01 → konfidensniveau = 99%
Lektion 5
Forklar forskellen på at hypoteseteste to stikprøver mod hinanden, fremfor at teste en stikprøve mod den sande værdi.
Når vi tester én stikprøve mod en sand værdi, undersøger vi om stikprøvens gennemsnit afviger fra en kendt/referenceværdi.
Eksempel:
“Er gennemsnittet forskelligt fra 100?”
Når vi tester to stikprøver mod hinanden, undersøger vi om de to gruppers gennemsnit er forskellige fra hinanden.
Eksempel:
“Sælger franske film flere billetter i én periode end i en anden?”
Kort sagt:
Én stikprøve = sammenlignes med en fast værdi.
To stikprøver = sammenlignes med hinanden.
Hvordan beregner man standardfejlen ved hypotesetest af to stikprøver (giv den en skalle – hvor langt kan du komme i forklaringen, inden du kigger i dine noter)?

Hvad er forskellen på en ensidet og en tosidet hypotesetest? I hvilken af de to testtyper er det – alt andet lige – sværest at forkaste H₀?
En ensidet test undersøger kun én retning.
Eksempel:
“Er gennemsnittet større end 100?”
En tosidet test undersøger begge retninger.
Eksempel:
“Er gennemsnittet forskelligt fra 100?”
Sværest at forkaste H₀:
Det er tosidet test, fordi signifikansniveauet deles i to haler.
Kort sagt:
Ensidet = kun større eller mindre.
Tosidet = både større og mindre.
Tosidet er sværest at forkaste H₀.
Hvad vil det sige at “nuljustere” sin stikprøve? Hvordan gør man det?
At nuljustere betyder, at man trækker en bestemt referenceværdi fra alle observationer.
Formel:
xnuljusteret=x−μ0x_{nuljusteret} = x - \mu_0xnuljusteret=x−μ0
Hvor:
xxx = observation
μ0\mu_0μ0 = den værdi vi tester imod
Eksempel:
Hvis vi tester om billetsalget pr. film er 1.000 billetter:
billetsalg−1000billetsalg - 1000billetsalg−1000
Så bliver spørgsmålet:
Ligger gennemsnittet af de nuljusterede værdier omkring 0?
Hvordan gør man?
Vælg referenceværdi, fx 1.000 billetter
Træk værdien fra alle observationer
Test om gennemsnittet af de nye værdier er forskelligt fra 0
Forklar, hvordan vi bootstrapper en hypotesetest på to stikprøver.
Lektion 6
Hvad er kategoriske variable? Hvorfor skal vi anvende en særlige metode til at lave hypotesetest på disse?
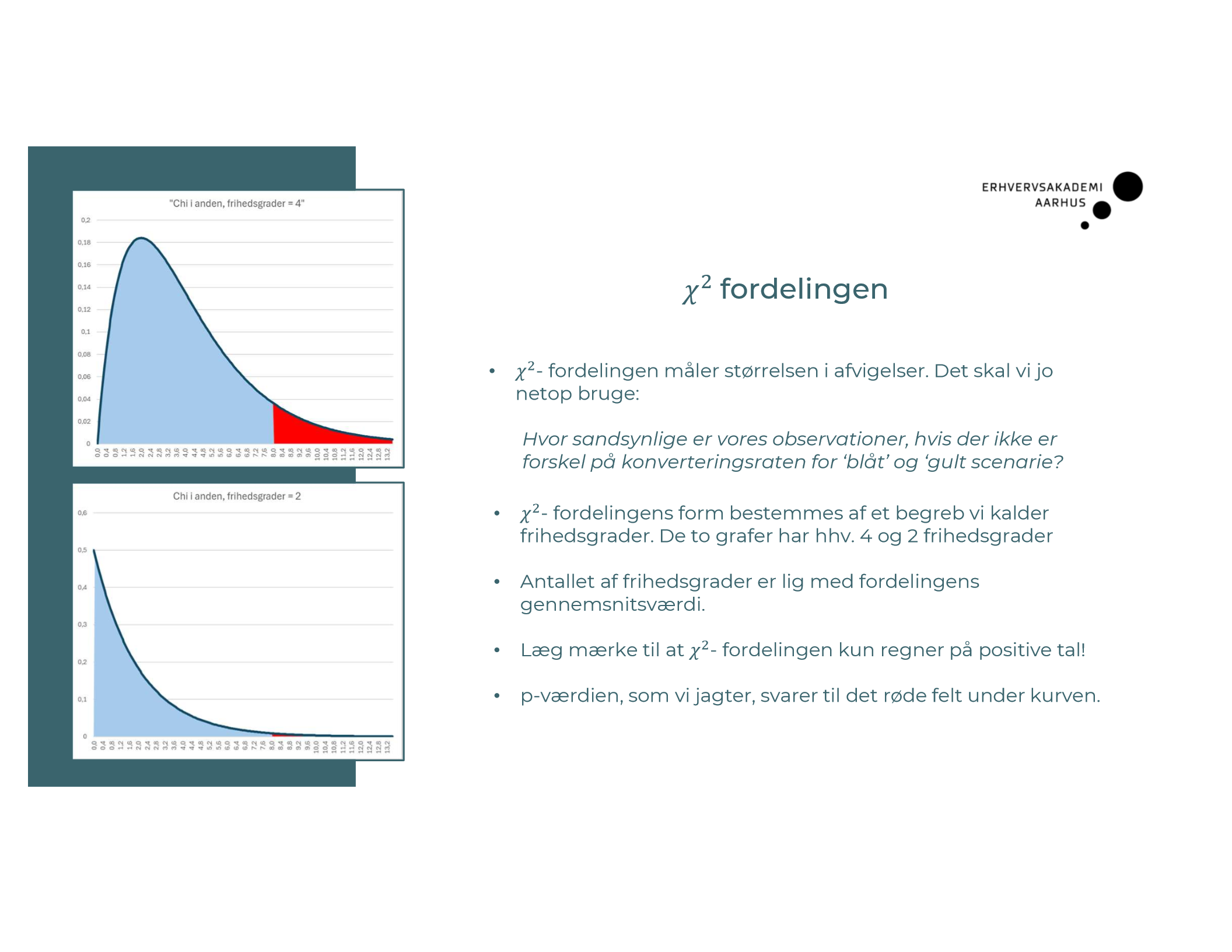
x2 fodeling
Forklar fremgangsmåden i en hypotesetest på kategoriske variable.
Kategoriske variable er data, der opdeler observationer i grupper/kategorier i stedet for tal.
Eksempler:
Censur: Tilladt for alle / 11 år / 15 år
Nationalitet: DAN / FRA / USA
Genre: Drama / Komedie / Dokumentar
Fordi man ikke tester et gennemsnit på samme måde som med talvariable.
Man tester i stedet fordelinger, andele eller sammenhænge mellem kategorier.Typiske metoder:
Chi-i-anden-test: tester om der er sammenhæng mellem to kategoriske variable
Andelstest: tester om en andel er forskellig fra en bestemt værdi
Hvorfor beregner vi “forventede værdier”? Hvad vil det sige, at de er “forventede”.
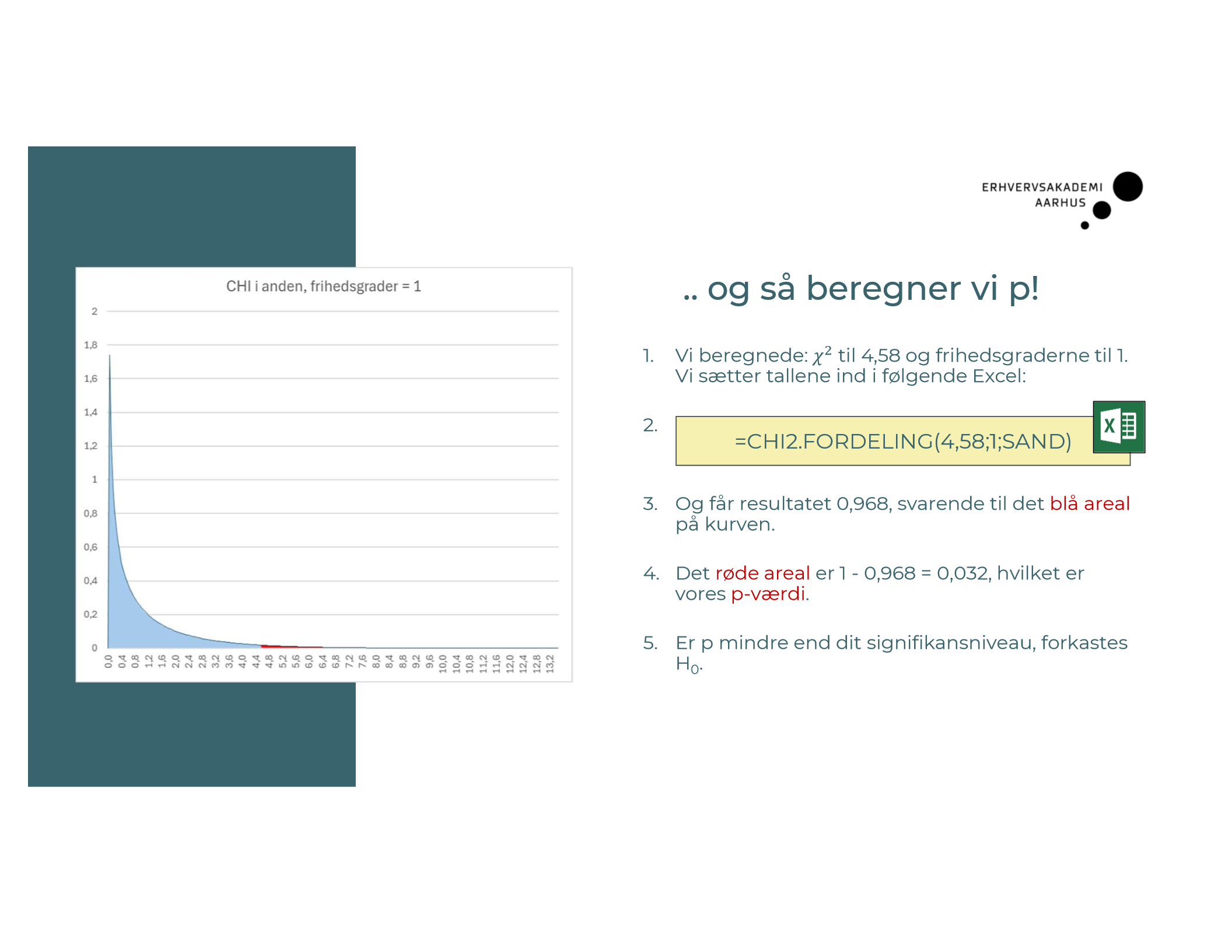
Hvad er “frihedsgrader” i en chi-i-anden-test?
Lektion 7
Nuljustering

Nuljustering af andele

Hvis p-værdien er 0.03 og signifikansniveauet er 0,05, skal du …..
Du skal forkaste nulhypotesen (H₀), fordi p-værdien er mindre end signifikansniveauet.
Hvordan beviser man H₁?
Du gør det ikke!!!
Flashcard
Q: Hvordan beviser man H₁?
A:
Man beviser ikke H₁ i statistik.
Man kan kun forkaste H₀ eller undlade at forkaste den.
Hvis H₀ forkastes, siger vi:
Der er evidens for H₁ (ikke bevis).
Hvad er en krydstabulering? Hvilken kommando i Python kan du bruge til at danne en krydstabulering i en dataframe?
En krydstabulering er en tabel, der viser sammenhængen mellem to kategoriske variable ved at tælle observationer i hver kombination.
Eksempel:
Rygning (ja/nej) vs. Kræft (ja/nej)
Q: Hvilken kommando i Python bruges?
A:
I pandas bruger man:
pd.crosstab(df["variabel1"], df["variabel2"])Eksempel:
pd.crosstab(df["rygning"], df["kraeft"])Kort sagt:
Krydstabel = tæller kombinationer
Python = pd.crosstab()
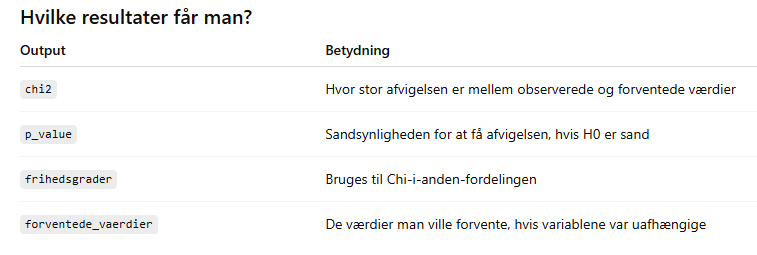
Hvordan laver du en Chi-i-anden-test i Python? Hvilke resultater spytter den ud til dig? Hvordan bruger du dem?
# 2. Lav Chi-i-anden-test
chi2, p_value, frihedsgrader, forventede_vaerdier = chi2_contingency(krydstabel)
En bootstrapped hypotesetest på andele (procenter) er lidt speciel. Forklar, hvad der er specielt ved den?
Lektion 8
Pearson korrelation?

Forklar begreberne korrelation, kausalitet og spuriøse sammenhænge.
Korrelation
To variable bevæger sig sammen.
Eksempel:
Når reklamebudgettet stiger, stiger billetsalget også.
Kausalitet
Den ene variabel forårsager den anden.
Eksempel:
Mere markedsføring kan føre til højere billetsalg.
Spuriøs sammenhæng
To variable ser ud til at hænge sammen, men sammenhængen skyldes en tredje faktor.
Eksempel:
Is-salg og drukneulykker stiger begge om sommeren.
Det betyder ikke, at is giver drukneulykker. Årstiden påvirker begge.
Kort sagt:
Korrelation = de hænger sammen.
Kausalitet = den ene skaber den anden.
Spuriøs = sammenhængen er falsk/misvisende.
Hvorfor er det vigtigt at regne p-værdier på sin korrelation?

Hvad fortæller p-værdien på din korrelationskoefficient dig egentlig?
p-værdien afhænger af to variable. Hvilke? Kan du ligefrem forklare sammenhængen?
Hvad er en forklarende variabel? Hvad er en afhængig variabel?

Forklar R². Hvad kan du bruge den til.

Forklar begreberne slope, intercept og p-værdi, når vi taler simpel regression.
Intercept
Skæringspunktet. Det er den forventede værdi af yyy, når x=0x = 0x=0.
Slope
Hældningen. Den viser, hvor meget yyy forventes at ændre sig, når xxx stiger med 1.
P-værdi
Tester om slope er statistisk forskellig fra 0.
Hvis p-værdien er lav, tyder det på, at xxx har en reel sammenhæng med yyy.
Kort sagt:
Intercept = startværdi.
Slope = ændring pr. x-enhed.
P-værdi = om slope er signifikant.
Hvad mener vi med, at den er “simpel”.

Hvorfor bør du visualisere dine data (fx et scatter plot), inden du går i gang med regressionsanalysen.
Lektion 9
Hvad skal vi bruge multipel regression til?

Forklar
Forklar forskellen på multipel og simpel regression.
Simpel regression
Bruger én forklarende variabel til at forklare yyy.
Eksempel:
billetsalg=intercept+slope⋅antal_visningerbilletsalg = intercept + slope \cdot antal\_visningerbilletsalg=intercept+slope⋅antal_visninger
Multipel regression
Bruger flere forklarende variable til at forklare yyy.
Eksempel:
billetsalg=intercept+alder+censur+premierea˚r+genrebilletsalg = intercept + alder + censur + premiereår + genrebilletsalg=intercept+alder+censur+premierea˚r+genre
Kort sagt:
Simpel regression = én x-variabel.
Multipel regression = flere x-variable.
Pythonkoden til multipel regression er relativt simpel. Hvad er ”den svære kunst” i
at lave en god regressionsanalyse?
1. Valg af variable
Hvilke forklarer faktisk yyy?
Undgå irrelevante eller stærkt korrelerede variable (multikollinearitet)
2. Datakvalitet
Manglende værdier, outliers, fejl i data
Dårligt data = dårlig model
3. Modelantagelser
Lineæritet
Uafhængighed
Konstant varians (homoskedasticitet)
Normalfordelte residualer
4. Fortolkning (det vigtigste)
Hvad betyder koefficienterne i praksis?
Er sammenhængen realistisk eller spuriøs?
5. Kausalitet vs. korrelation
Regression viser sammenhæng – ikke nødvendigvis årsag
Kort sagt:
Koden er let.
Det svære er at tænke rigtigt, vælge rigtigt og tolke rigtigt.
Hvad er multikollinearitet? Hvad er problemet? Hvordan tester du for det?
Multikollinearitet betyder, at to eller flere forklarende variable i en regression hænger for meget sammen.
I vores filmopgave:
Hvis vi bruger både:
PremiereårAntal film pr. år
…kan de være afhængige, fordi antal film netop er beregnet ud fra år.
Eller hvis vi bruger:
CensurMålgruppe
…kan de også overlappe, fordi censur siger noget om målgruppen.
Hvorfor er det et problem?
Modellen får svært ved at afgøre, hvilken variabel der faktisk forklarer billetsalget.
Kort sagt:
Multikollinearitet = forklarende variable forklarer hinanden for meget.
Det kan gøre regressionens resultater ustabile og svære at tolke.

Forklar resuméet af en regressionsanalyse (se næste slide). Hvad kan du
uddrage af information? Hvordan tolker du de forskellige data?
Hvordan indarbejder du en kategorisk variabel i din regressionsanalyse?
Man omdanner den til dummyvariable (0/1-variable).
Eksempel:
Censur: A, 11, 15
→ laves til:
Censur_11 = 1 hvis “11”, ellers 0
Censur_15 = 1 hvis “15”, ellers 0
(Én kategori udelades som reference)
I Python:
pd.get_dummies(df["censur"], drop_first=True)Fortolkning:
Koefficienterne viser forskellen i forhold til referencekategorien.
Kort sagt:
Kategorisk → dummyvariable → ind i regression.
VarianceinflationFactor

Hvad er en residualanalyse? Giv eksempler på, hvad du kan bruge den til
