L10 - Big Data, Artificial Intelligence & Brain Health + Neurorights
1/9
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
10 Terms
What are the 5 V’s of Big Data? + What do they do? + Give some examples for each
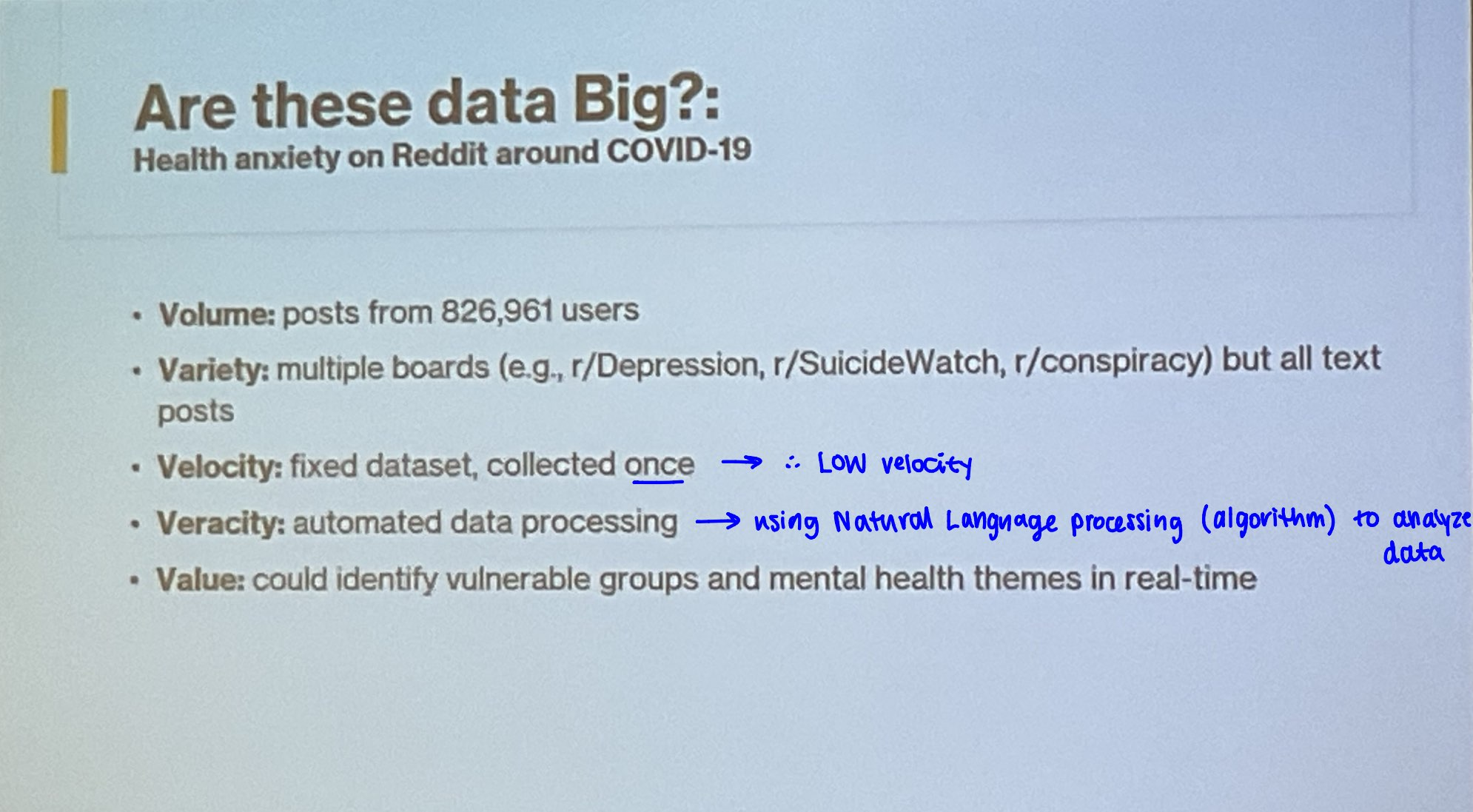
Big data is considered large and continually generated digital datasets & these are the characteristics of complex data
Volume: number of data points / amount of data generated
Costco is a large chain company with multiple stores across the province and generates millions of transactions per day => large dataset of purchases and customer behaviour
Velocity: pace of data generation
MRI has low velocity VS steps counted on IPhone has high velocity
Variety: different types of data (structured/unstructured)
social media data includes videos, photos, comments
Veracity: data quality and accuracy
bots and fake accounts on social media
heart rate measured by Apple watch
Value: potential to create benefits and insights
survey on customer behaviour used to improve future products
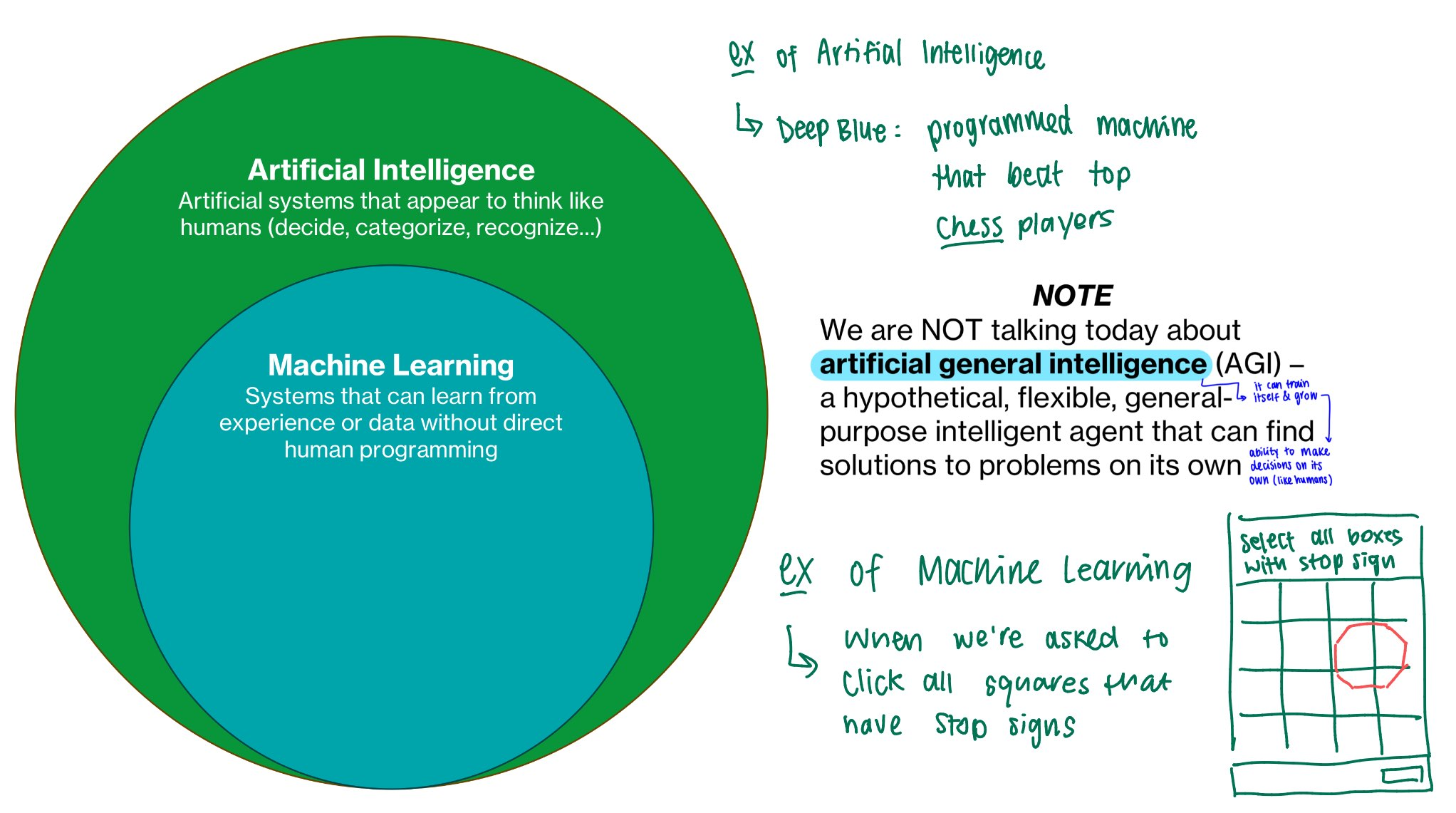
Define artificial intelligence VS machine learning + how does AGI differ from AI
AI = general umbrella term that encompasses machines and computers that have ability to mimic human intelligence (such as analyze data, categorize, recognize)
Machine learning = subset of AI / application of AI that allows systems to learn from experiences and data without human programming and apply what they learn to new data
AGI (artificial general intelligence) = hypothetical agent able to solve problems and make decisions on its own
Define supervised VS unsupervised learning (in machine learning) + give an example for each
Supervised learning = models that are trained on labelled, known data TO predict outcomes => need large volume of data
medical records of patients who do or do not develop dementia
Unsupervised learning = models that learn from unlabelled data TO identify patterns => need huge processing power
all reddit posts containing the word “dementia”
What are some applications of AI in neuroscience? (5)
Risk prediction => predict disease diagnosis using brain scans
NSCI303 : trained machine learning to identify MRI data of healthy brain VS ones that have Alzheimer’s Disease
LABELLED
Clinical decision making => identify disease region using intracranial EEG and surgically remove it
trained machine learning model uses features of intracranial EEG output to identify origin of seizure
UNLABELLED
Neurotech => control limb movement with neural activity
trained machine learning model to map neural activity and limb movement
Brain modelling => understanding how brains represent space
PSYC370 : trained machine learning model to “navigate space” to act like entorhinal cortex “grid cells”
Diagnosis & prognostication => sort data and determine what disorder someone has based on behaviours + what would happen next
trained machine learning model to triage neurological illnesses on head CTs and radiology annotations
LABELLED
What are some ethical issues of AI in neuroscience?
Beneficence & Autonomy
culpability : responsibility based on intention, knowledge or control => if neurosurgery robot makes an error, is it the surgeon's or the robot’s fault
moral accountability : duty to explain one’s reasons and actions => AI has found that someone will have a said disorder in the future but doctors (humans) may not be able to explain the diagnosis
future access to present data : personal preference and emotional states could be at risk => anonymous data that is no longer anonymous because future AI models could potentially reveal someone’s identity by looking at their past memories
Justice
cultural under-representation in AI model research
downplaying data of women & ethnic minorities
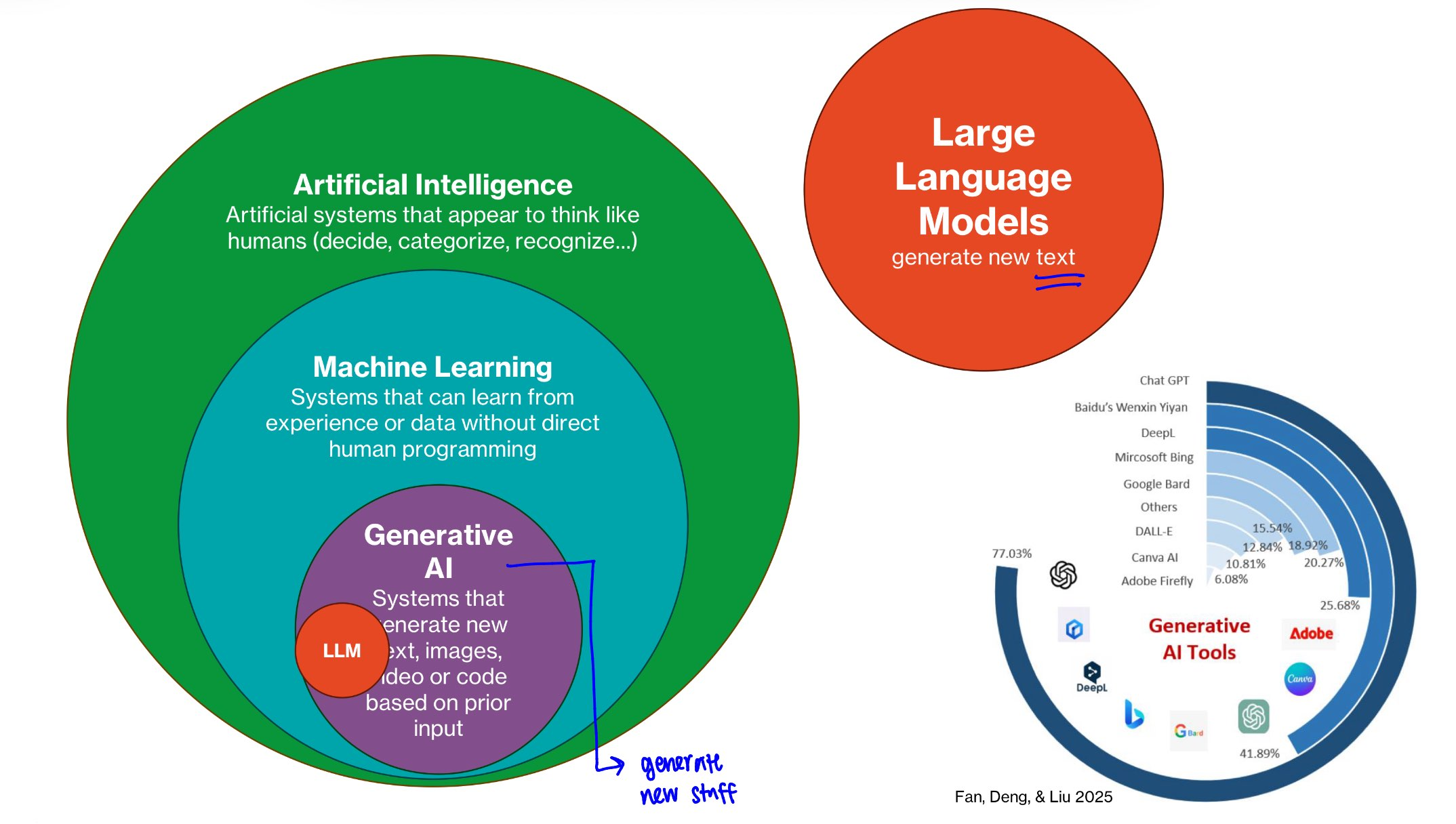
What are LLMs?
What type of data is used to train LLMs?
Are LLMs designed to match their training data or to be true?
LLMs are Large Language Models, generating new text
Type of data used to train LLMs is large datasets from publicly available information online which can include encyclopedia, wikipedia, personal blogs, books, scientific papers
LLMs outputs are designed to match the training data BUT not necessarily to be true
What are some ethical and/or environmental issues arising from LLMs?
energy consumption
carbon emissions
water consumption for cooling
data privacy (use of information with no consent)
lack of transparency (information from “black box” because it’s hard for humans to understand how AI arrived at certain conclusions)
malicious usage (generate deceptive content)
What is NeuroRights?
New sets of human rights set to protect an individual’s brain data from misuses of neurotechnologies and artificial intelligence
What are the 5 NeuroRights?
Right to personal identity
Right to free will (autonomy)
Right to mental privacy
Right to equal access to mental augmentation
Right to protection from algorithmic bias
How does Neurorights Initiative define personal identity?
What principle guides the Neurorights Initiative in establishing guidelines to regulate neurotech?
Individuals should have ultimate control over their own decision making without manipulation from external neurotechnologies
☹ “ultimate control” will be compromised when policies are put into place
🙂 shared end goal of achieving free will
Based on the principle of justice & guarantee equality of access to all citizens