7 - Common network architecture and Transfer Learning
1/62
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
63 Terms
What is object classification?
Predicting a single class label for the entire image.
What is single‑object localisation?
Predicting one object’s class and its bounding box.
What is object detection?
Predicting multiple objects, each with a class label and bounding box
What are the key features of AlexNet?
· First deep CNN to win ImageNet
· ReLU activations
· Dropout
· GPU training
· 5 conv layers + 3 FC layers
What characterises VGG networks?
· Very deep (16–19 layers)
· Only 3×3 convolutions
· Simple, uniform architecture
· Large number of parameters
What characterises GoogLeNet?
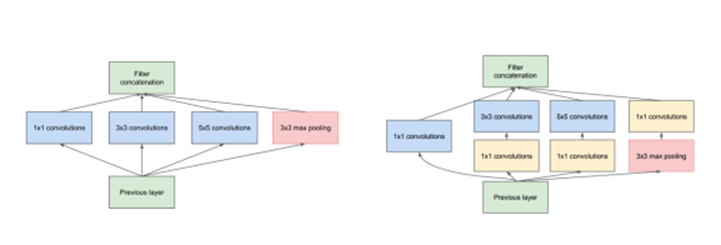
· Uses Inception modules
· Parallel 1×1, 3×3, 5×5 convs + pooling
· 1×1 convs for dimensionality reduction
· Much fewer parameters than VGG
What characterises ResNet?
· Uses residual (skip) connections
· Enables very deep networks (50–152 layers)
· Solves vanishing gradient problem
What does the Inception module do?
Processes input at multiple scales using parallel convs and pooling.
What is the structure of an Inception module?
· 1×1 conv
· 3×3 conv
· 5×5 conv
· Max pooling
Outputs concatenated.
Why does the Inception module work well?
· Multi‑scale feature extraction
· 1×1 conv reduces computation
· Efficient and expressive
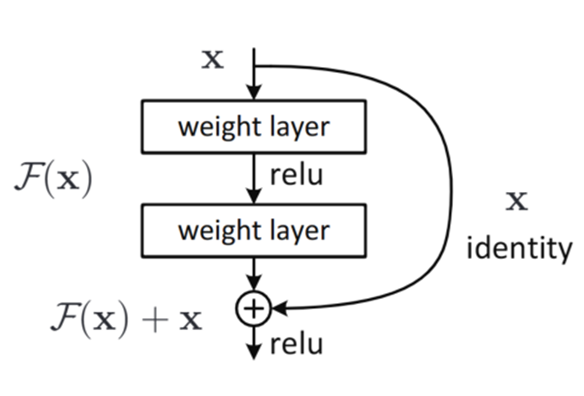
What is a residual module?
A block where the input is added to the output: y = F(x) + x
Why use residual connections?
· Prevent vanishing gradients
· Make optimisation easier
· Enable very deep networks
What does a residual block learn?
The residual (difference) rather than the full mapping.
What is the Fast R‑CNN pipeline?
1. Compute shared conv feature map
2. Region proposals (Selective Search)
3. RoI Pooling
4. FC layers
5. Outputs: class scores + bounding box regression
Why is Fast R‑CNN faster than R‑CNN?
The image is processed once, not per region
Why use 1×1 convolutions in Inception?
Dimensionality reduction → fewer parameters → cheaper computation
What problem do skip connections solve?
Vanishing gradients in deep networks
Which architecture uses multi‑scale processing?
GoogLeNet (Inception)
Which architecture emphasises depth?
VGG and ResNet
Which architecture emphasises width/multi‑branching?
GoogLeNet
Top-1 Accuracy
model only correct if the highest probability class matches the ground truth
Top-5 Accuracy
model is correct if ground truth among the top five canditates
What is the ImageNet dataset?
A large‑scale dataset with ~1.2M training images and 1000 classes, used for benchmarking and pretraining.
Why is ImageNet widely used?
It enables transfer learning and provides a standard benchmark for comparing models.
What is Top‑5 error?
Top‑5 Error = 1−Top‑5 Accuracy
What is global average pooling?
A layer that averages each feature map into a single value, replacing fully‑connected layers.
Why is GAP used in CNNs?
Reduces parameters, prevents overfitting, and simplifies architecture
What are auxiliary classifiers in GoogLeNet?
Extra classifiers attached to intermediate layers to help gradient flow and regularise training
Are auxiliary classifiers used during inference?
No — only the main classifier is used
What is naive Inception?
Parallel 1×1, 3×3, 5×5 convs + pooling, without dimensionality reduction
Why is naive Inception inefficient?
3×3 and 5×5 convolutions are computationally expensive
How does reduced Inception improve efficiency?
Uses 1×1 convolutions to reduce channel depth before expensive convolutions.
Why do 1×1 convolutions reduce cost?
They reduce the number of input channels, lowering the number of multiplications
Why are 5×5 convolutions expensive?
Cost scales with K² ; 5×5 has 25× more multiplications than 1×1.
What is the Fréchet Inception Distance?
A metric that compares real and generated images by measuring the distance between their feature distributions.
What does FID evaluate?
Image quality and diversity in generative models.
How is FID computed?
Extract features using an Inception network, then compute the Fréchet distance between real and generated feature distributions.
How FID works
Pass real + generated images through Inception‑v3
Extract 2048‑dimensional features (GAP layer)
Compute distance between their means + covariances
Lower FID = better quality + diversity
Why FID is used
· Captures realism
· Captures diversity
· Better than pixel‑wise metrics
How to design a deep learning method
- Preprocessing
- Architecture
- Training Details
Image localisation
- Uses IOU threshold
- Usually 0.5
Mean average precision (mAP)
Area under precision recall curve, precision/recall computed using both correct label and bounding box
Intersection over union
Area of overlap divided by area of union (the whole area)
Precision
TP / (TP+FP)
Recall
TP / (TP+FN)
What does a lower FID score indicate?
More realistic and diverse generated images.
Why deeper networks failed before ResNet
· Vanishing/exploding gradients (solved by normalisation)
· Degradation problem: deeper networks had worse training accuracy
· Not due to overfitting — optimisation difficulty
Why can’t a normal conv+ReLU block learn identity?
ReLU outputs zero for negative inputs → cannot reproduce x for x < 0
What is the key idea of ResNet?
Learn the residual F(x) = H(x) - x
Then output H(x)
Skip connection purpose
· Added to Inception 4a and 4d
· Weighted at 0.3 in the loss
· Provide extra gradient signal
· Reduce vanishing gradients
· Act as regularisers
· Removed at inference
Naive Inception
· Parallel branches: 1×1, 3×3, 5×5 convs + pooling
· All padded to preserve spatial size
· Outputs concatenated
· MaxPool uses 3×3, stride 1, padding 1
Reduced Inception
· Insert 1×1 conv before 3×3 and 5×5 convs
· Reduces channel depth → reduces computation
· Makes Inception efficient
How to train a pre-trained model
- Freeze weights of intermediate layer and train the last one
- Train all layers
- Hybrid, last layer trained first, followed by unfreezing intermediate layers
When to freeze all and just train last
· You have very little data
· Your new task is similar to ImageNet
When to train all layers
· You have lots of data
· Your task is very different from ImageNet
· You can afford longer training
When to do hybrid approach
· You have a moderate amount of data
· Your task is somewhat different from ImageNet
What is transfer learning?
Using a model pretrained on a large dataset (e.g., ImageNet) and adapting it to a new task with limited data
Why ImageNet models transfer well
Early layers learn general features (edges, textures), which are useful for many tasks
Why use Transfer Learning?
· Faster training
· Better performance with small datasets
· Pretrained models learn general features (edges, textures, shapes)
· Reduces overfitting
When transfer learning is most useful
When the target dataset is small or expensive to label
Residual module diagram
Inception vs naïve inception