Principles of Machine Learning
1/50
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
51 Terms
Where are the parameter vectors Theta^k or all classes typically stored in a Softmax model?
They are stored as rows within a parameter matrix denoted as Theta
Define the softmax function (normalized exponential) for estimating the probability p^k
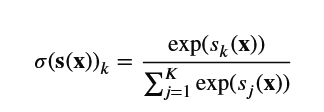
Formula: The prediction function for y^ using scores.
$\hat{y} = \text{argmax}_k \sigma(\mathbf{s}(\mathbf{x}))_k = \text{argmax}_k s_k(\mathbf{x})$.
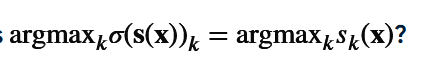
What is the likelihood function $L$ for a single data point in Softmax Regression?
$L = \prod_{k=1}^K p_k^{y_k}$.
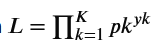
In the cross entropy cost function J(Theta), what does y_k^i represent?
The target probability (usually 1 or 0) that the ith instance belongs to class k
Equation: Cross entropy cost function $J(\boldsymbol{\Theta})$ for $m$ instances.
$J(\boldsymbol{\Theta}) = -\frac{1}{m} \sum_{i=1}^m \sum_{k=1}^K y_k^{(i)} \log(\hat{p}_k^{(i)})$.
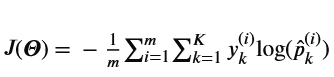
Formula: The gradient vector of the cost function with respect to $\boldsymbol{\theta}^{(k)}$.
$\nabla_{\boldsymbol{\theta}^{(k)}} J(\boldsymbol{\Theta}) = \frac{1}{m} \sum_{i=1}^m (\hat{p}_k^{(i)} - y_k^{(i)}) \mathbf{x}^{(i)}$.
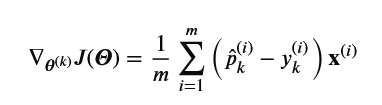
According to the Scikit-Learn example, what probability does the model assign to Iris virginica for a 5cm by 2cm petal?
Approximately 94.2%
In information theory, how many bits are required to encode 8 equally likely options?
3 bits, because 2^3 = 8.